







 本文深入探讨了机器学习中噪声和误差的影响。介绍了噪声产生的原因,如标记错误和输入错误,并讨论了目标分布的概念,帮助理解如何在有噪声的数据中建立有效的学习目标。接着,文章详细阐述了两种误差衡量方法——0/1错误和平方错误,并通过实例解释了它们在分类和回归任务中的应用。最后,提出了误差加权的概念,强调在不同场景下,错误类型的不同成本可能导致不同的优化策略。
本文深入探讨了机器学习中噪声和误差的影响。介绍了噪声产生的原因,如标记错误和输入错误,并讨论了目标分布的概念,帮助理解如何在有噪声的数据中建立有效的学习目标。接着,文章详细阐述了两种误差衡量方法——0/1错误和平方错误,并通过实例解释了它们在分类和回归任务中的应用。最后,提出了误差加权的概念,强调在不同场景下,错误类型的不同成本可能导致不同的优化策略。
噪声与误差
噪音(Noise)
实际应用中的数据基本都是有干扰的,还是用信用卡发放问题举例子:

噪声产生原因:
- 标记错误:应该发卡的客户标记成不发卡,或者两个数据相同的客户一个发卡一个不发卡;
- 输入错误:用户的数据本身就有错误,例如年收入少写一个0、性别写反了什么的。
目标分布(Target Distribution)
上述两个原因导致数据信息不精准,产生噪声数据。那机器学习算法应该如何处理噪声的数据呢?
以那个从罐子里拿球的实验为例:
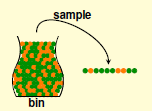
之前我们规定凡是 h(x)≠f(x) 的数据(小球),就把他漆成橘色,否则绿色。橘色小球在所有小球中占据的比重就是错误率。
但是现在有干扰了,一条数据可能有
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









