










lifeifei老师团队在发布了Visual Genome数据集后,又在Scene Graph Generation做的新的创新
关于Scene Graph Generation就不再赘述,在上一篇neural motif介绍过,neural motif比这篇晚一些,效果也好一些
Image to Scene Graph现状
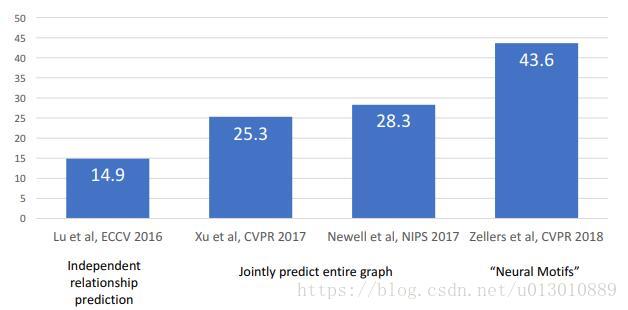
- Lu et al: Visual Relationship Detection with Language Priors
- Xu et al: Scene Graph Generation by Iterative Message Passing
- Newell et al: Pixels to Graphs by Associative Embedding
- Zellers et al: Neural Motifs: Scene Graph Parsing with Global Context
图片来源于CVPR2018 Visual Recognition and Beyond Scene Graphs for Recognition and Generation - Justin Johnson
框架
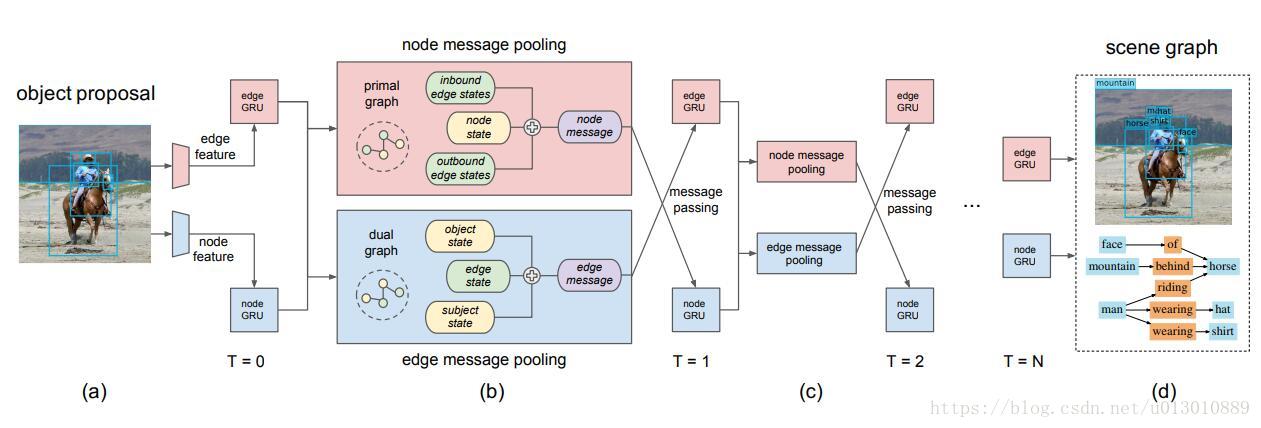
因为Scene Graph本身就已经不是单独地去识别物体,本文想通过message passing 更好地利用上下文来预测物体和它们之间的关系。
(a)
edge feature: 主语和宾语box的并集组成rel-rois,去特征图上扣
node feature: 检测出的所有rois,去特征图上扣
然后把edge feature(#num_rels, feature_dim)和node feature(#num_rois, feature_dim)送入GRU得到初步融合了一些context的edge feature(#num_rels, hidden_dim)和node feature(#num_rois, hidden_dim)
(b)
核心的message passing过程
本文观察到由于scene graph独特的结构使得消息传递是二分的结构,node集合和edge集合是没有交流的,而且由于它特殊的结构,我们还不用使用全连接,不用使node去和edge集合每个元素相连,反之edge也不用和node集合每个元素相连,那么怎么办呢?
我们注意到edge其实就是relation,只需要把主语node特征和宾语node特征连过来,再和自身的hidden state进行融合,而node其实就是物体,我们只要把和该物体有关的edge/relation连过来,包括inbound(入界,即作为宾语的edge特征)和outbound(出界,即作为主语的edge特征),然后再和自身的hidden state进行融合
# vertext: 点 (#num_rois, feature_dim)
vert_unary = self.get_output('vert_unary')
# edge: 边 (#num_rels, feature_dim)
edge_unary = self.get_output('edge_unary')
# (#num_rois, hidder_dim)
vert_factor = self._vert_rnn_forward(vert_unary, reuse=False)
# (#num_rels, hidder_dim)
edge_factor = self._edge_rnn_forward(edge_unary, reuse=False)
for i in xrange(self.n_iter):
reuse = i > 0
# compute edge states edge状态融合
# 或用hard就是直接取max或者mean
# 或用soft就是算权重,类似attention
edge_ctx = self._compute_edge_context(vert_factor, edge_factor, reuse=reuse)
edge_factor = self._edge_rnn_forward(edge_ctx, reuse=True)
# compute vert states
vert_ctx = self._compute_vert_context(edge_factor, vert_factor, reuse=reuse)
vert_factor = self._vert_rnn_forward(vert_ctx, reuse=True)
vert_in = vert_factor
edge_in = edge_factoradaptively weighted message pooling functions即soft更新
mi是node的更新,mij是edge的更新,v1,v1,w1,w2是可学习的参数,它们是融合的权重。
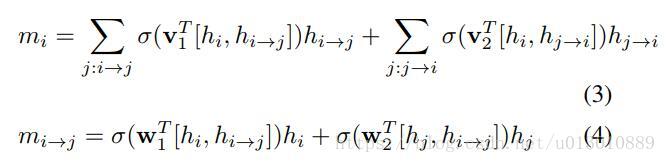
将上述公式与下式对比,可以看到用了类似于concat attention的机制
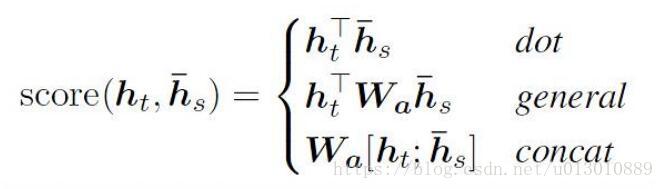
(c)(d)
迭代message passing过程,最后输出物体和关系
评价指标和实验
- predicate classification (PREDCLS): given a ground truth set of boxes and labels, predict edge labels,
- scene graph classification (SGCLS): given ground truth boxes, predict box labels and edge label
- scene graph detection(SGDET): predict boxes, box labels, and edge labels.
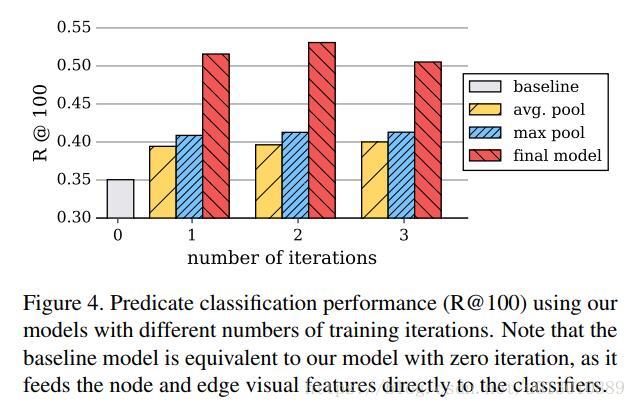
baseline就是0次迭代,只有(a)(d)两步,没有message passing
可以看到随着迭代次数的增加,predcls在增加,而且本文提出的动态权重调整的融合策略比两个naive的融合如avg/max要很多














 640
640











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









