










这是研究生生涯在saliency方向上迈出的第一步,即看的第一篇论文,更是写的第一篇阅读笔记,希望大家多多包涵,更欢迎大家批评指正。
Learning video saliency from human gaze using candidate selection_CVPR2013
目录
-----------------------------------------
1 动机
2 方法
3 实验
4 贡献点
——————————————————————————————————————————————————————————————————————————————
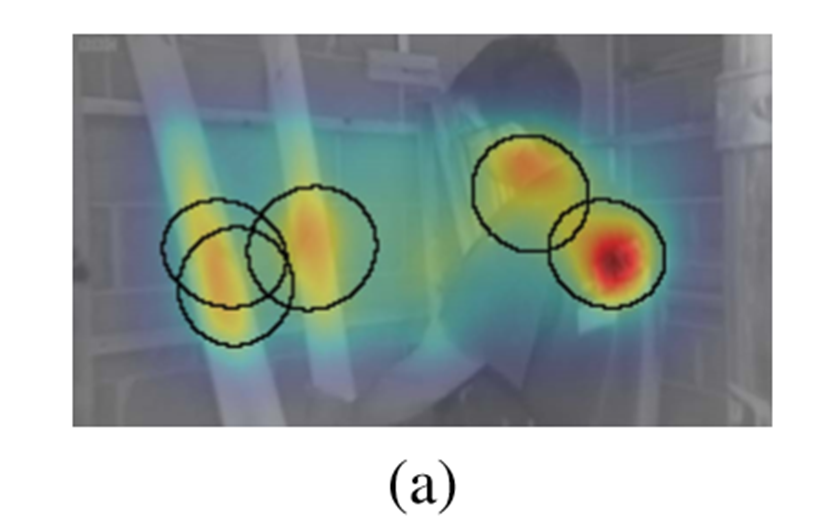
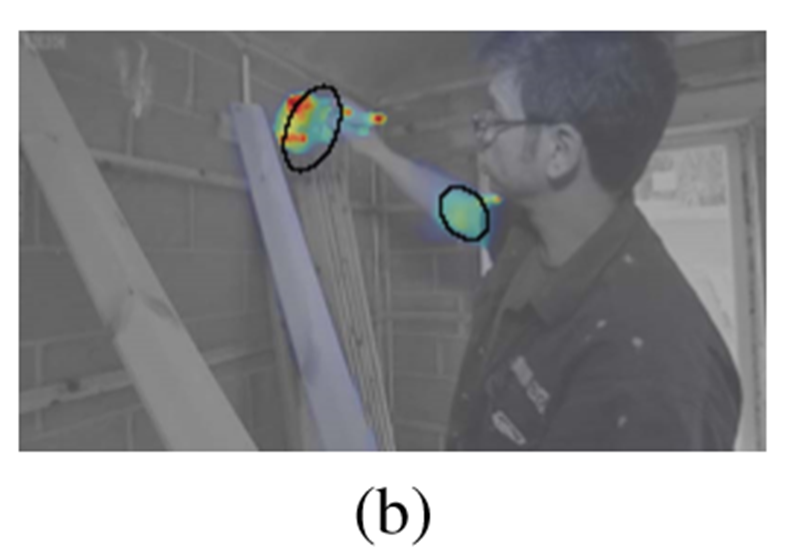
图像显著性和视频显著性的不同,图(a)是图像显著性热度图,图(b)是视频中一帧的显著性热度图,可以看出视频显著性更紧密,更集中在单个对象上,而图像显著性涵盖几个有趣的位置。
·Predicting where people look in video is relevant in many applications.
预测人眼注视视频中的位置在很多应用中息息相关。比如广告视频需要牢牢抓住受众眼球;在视频剪辑种,可以更平滑地处理镜头转换;还比如视频压缩和关键帧选择等。
·Most previous saliency modeling methods calculate a saliency value for every pixel.
过去大多数显著性建模的方法是对每一个像素的显著性值进行计算,本文选择一部分进行计算,降低计算量。

我们工作和过去视频显著性方法不同点在于,通过将焦点缩小到一小部分人眼注视的位置上,并且随着时间学习有条件的目光改变。
a.Static candidates indicate the locations that capture attention due to local contrast or uniqueness, irrespective of motion.
静态候选集根据局部对比度和特性进行选择。使用经典的GBVS方法。【the graph-based visual saliency (GBVS)】
b.Motion candidates refelect the areas that are attractive due to the motion between frames.
运动候选集反映了由于帧间运动吸引眼球的区域。方法:计算连续两帧的光流,并应用Difference-of-Gaussians (DoG)高斯差分滤波处理光流。
c.semantic candidates are those that arise from higher-level human visual processing.
语义候选集从更高级别的人类视觉处理中产生。首先根据人类常常观看视频中心点,在帧的中心创建一个恒定大小的中心候选区域。
small detections : create a single candidate at their center.
large detections : create several candidates
four for body detections (head, shoulders and torso)
three for faces (eyes and nose with mouth)
【下图为center_red,face_green,body_blue】

a.Features 特征
特征分类为目的帧特征和帧间特征。本文还试验了源帧特征的使用,但是发现这些特征导致学习过程中的过拟合,因为它们与目的帧特征只有一点点不同。
根据候选集分别计算static ,motion and semantic features。
b.Gaze transitions for training 训练目光运动
把学习问题看成分类问题,是否一个目光转变是从给定帧候选集到目标候选集。
需要(i)选择相关的帧对,eg.Scene cut 以及(ii)标记这些帧之间的正和负目光转变。

c.Learning transition probability 学习转换概率
首先计算每个特征的均值及其跨训练集的标准差。归一化特征。接着训练一个标准的随机森林分类器使用归一化的特征和他们的标签。
得到的最终概率是:Sal(si)是源候选显著性,S是所有源的集合。
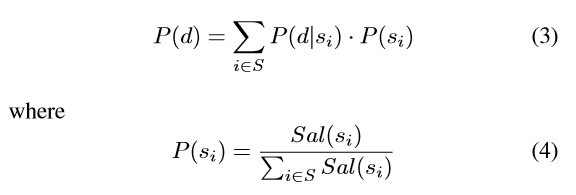
最后,用对应协方差的高斯替换每个候选集,并使用候选集显著性作为权重对它们求和。
DIEM (Dynamic Images and Eye Movements)dataset
CRCNS dataset
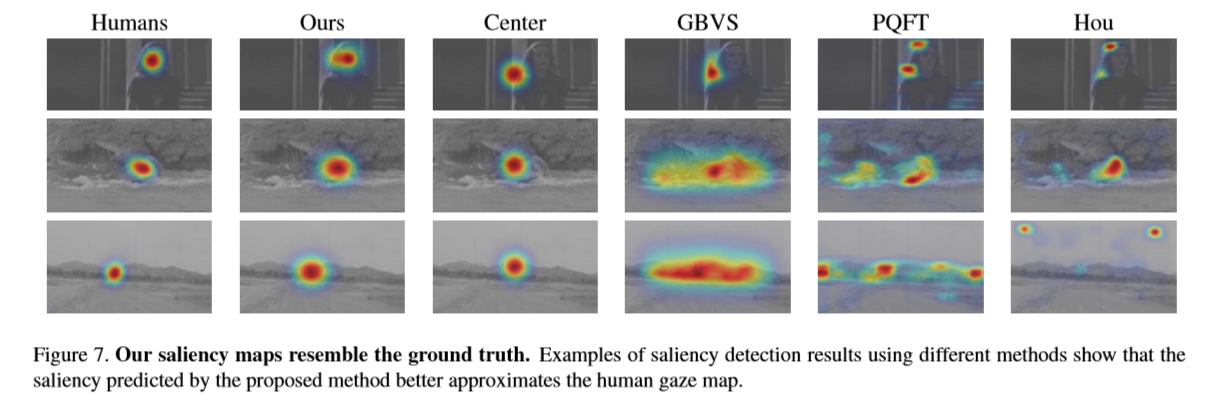
使用了稀疏候选集去对显著图建模
·using candidates boosts the accuracy of the saliency prediction and speeds up the algorithm.
使用候选集提高了显著性预测的准确度并加快了算法速度
·the proposed method accounts for the temporal dimension of the video by learning the probability to shift between saliency locations.
考虑到视频的时间维度,学习显着性位置移动的概率。
Learning video saliency from human gaze using candidate selection_CVPR2013
从人眼目光中使用候选集选择的方式学习视频的显著性
目录
-----------------------------------------
1 动机
2 方法
3 实验
4 贡献点
——————————————————————————————————————————————————————————————————————————————
1 动机
·Image saliency vs. video saliency图像显著性和视频显著性的不同,图(a)是图像显著性热度图,图(b)是视频中一帧的显著性热度图,可以看出视频显著性更紧密,更集中在单个对象上,而图像显著性涵盖几个有趣的位置。
·Predicting where people look in video is relevant in many applications.
预测人眼注视视频中的位置在很多应用中息息相关。比如广告视频需要牢牢抓住受众眼球;在视频剪辑种,可以更平滑地处理镜头转换;还比如视频压缩和关键帧选择等。
·Most previous saliency modeling methods calculate a saliency value for every pixel.
过去大多数显著性建模的方法是对每一个像素的显著性值进行计算,本文选择一部分进行计算,降低计算量。
2 方法
Our work differs from previous video saliency methods by narrowing the focus to a small number of candidate gaze locations, and learning conditional gaze transitions over time.我们工作和过去视频显著性方法不同点在于,通过将焦点缩小到一小部分人眼注视的位置上,并且随着时间学习有条件的目光改变。
2.1 Candidate selection 候选集选择
考虑了三种类型的候选集:a.Static candidates indicate the locations that capture attention due to local contrast or uniqueness, irrespective of motion.
静态候选集根据局部对比度和特性进行选择。使用经典的GBVS方法。【the graph-based visual saliency (GBVS)】
b.Motion candidates refelect the areas that are attractive due to the motion between frames.
运动候选集反映了由于帧间运动吸引眼球的区域。方法:计算连续两帧的光流,并应用Difference-of-Gaussians (DoG)高斯差分滤波处理光流。
c.semantic candidates are those that arise from higher-level human visual processing.
语义候选集从更高级别的人类视觉处理中产生。首先根据人类常常观看视频中心点,在帧的中心创建一个恒定大小的中心候选区域。
small detections : create a single candidate at their center.
large detections : create several candidates
four for body detections (head, shoulders and torso)
three for faces (eyes and nose with mouth)
【下图为center_red,face_green,body_blue】
2.2 Modeling gaze dynamics 目光运动的建模
找到候选集之后,需要从中选择最显著的一个,通过学习转换概率transition probability来实现,其中transition probability是指从源帧中的一个注视位置转换到目的帧中的新注视位置的概率。需要对目光运动进行建模。a.Features 特征
特征分类为目的帧特征和帧间特征。本文还试验了源帧特征的使用,但是发现这些特征导致学习过程中的过拟合,因为它们与目的帧特征只有一点点不同。
根据候选集分别计算static ,motion and semantic features。
b.Gaze transitions for training 训练目光运动
把学习问题看成分类问题,是否一个目光转变是从给定帧候选集到目标候选集。
需要(i)选择相关的帧对,eg.Scene cut 以及(ii)标记这些帧之间的正和负目光转变。
c.Learning transition probability 学习转换概率
首先计算每个特征的均值及其跨训练集的标准差。归一化特征。接着训练一个标准的随机森林分类器使用归一化的特征和他们的标签。
得到的最终概率是:Sal(si)是源候选显著性,S是所有源的集合。
最后,用对应协方差的高斯替换每个候选集,并使用候选集显著性作为权重对它们求和。
3 实验
Dataset :DIEM (Dynamic Images and Eye Movements)dataset
CRCNS dataset
4 贡献点
·The method is substantially different from existing methods and uses a sparse candidate set to model the saliency map.使用了稀疏候选集去对显著图建模
·using candidates boosts the accuracy of the saliency prediction and speeds up the algorithm.
使用候选集提高了显著性预测的准确度并加快了算法速度
·the proposed method accounts for the temporal dimension of the video by learning the probability to shift between saliency locations.
考虑到视频的时间维度,学习显着性位置移动的概率。















 1140
1140











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









