1 鸢尾花数据集背景
鸢尾花数据集是原则20世纪30年代的经典数据集。它是用统计进行分类的鼻祖。
sklearn包不仅囊括很多机器学习的算法,也自带了许多经典的数据集,鸢尾花数据集就是其中之一。
导入的方法很简单,不过我比较好奇它是如何来存储这些数据的,于是我决定去背后看一看
| 1 2 3 | from sklearn.datasets import load_iris
data = load_iris()
|
找到sklearn包的路径,发现包可不少,不过现在扔在一边,以后再来探索,我现在要找到是datasets文件夹。
文件夹里没有找到load_iris()这个函数在哪,只是在__init__文件里,发现了这么一行
| 1 | from .base import load_iris
|
2 数据的内容
不出我料数据没有存储在程序文件里,而是用csv格式保存着,单独放在了data文件夹里
| 1 2 3 4 5 6 | 150,4,setosa,versicolor,virginica
5.1,3.5,1.4,0.2,0 #花萼长度,花萼宽度,花瓣长度,花瓣宽度
4.9,3.0,1.4,0.2,0
4.7,3.2,1.3,0.2,0
4.6,3.1,1.5,0.2,0
5.0,3.6,1.4,0.2,0
|
第一行首先记录了样本数目150,特征数目4
现在是时候来详细介绍一下数据了:
数据包含三种鸢尾花的四个特征,分别是花萼长度(cm)、花萼宽度(cm)、花瓣长度(cm)、花瓣宽度(cm),这些形态特征在过去被用来识别物种。时至今日,我们已经可以通过基因签名来识别这些分类了。
三种鸢尾花分别是

山鸢尾花(Iris Setosa)、

变色鸢尾花(Iris Versicolor)和

维吉尼亚鸢尾花(Iris Virginica)
3 数据可视化
鸢尾花数据集只有150个样本,每个样本只有4个特征,容易将其可视化
上面加载的data变量是一个类似字典的类型,是数据信息的集合,它像字典一样通过键值对来组织信息
值既可以通过data['target']也可以通过data.target来获取,很明显这说明data并不是字典类型
| 1 2 3 4 5 6 7 8 | data.keys()
>>['target_names', 'data', 'target', 'DESCR', 'feature_names']
feature = data['data'] #为numpy.ndarray类型
feature.shape #矩阵的行数和劣势
>> (150L, 4L)
target = data['target']
target.shape
>>(150L,)
|
四个特征是不可能同时在平面图里画出来的,只得运用我们的聪明才智,把它两两一组
| 1 2 3 4 5 6 7 8 9 10 11 | def plot_iris_projection(x_index, y_index):
for t,marker,c in zip(xrange(3),'>ox', 'rgb'):
plt.scatter(data[target==t,x_index],
data[target==t,y_index],
marker=marker,c=c)
plt.xlabel(feature_names[x_index])
plt.ylabel(feature_names[y_index])<br><br>pairs = [(0,1),(0,2),(0,3),(1,2),(1,3),(2,3)]
for i,(x_index,y_index) in enumerate(pairs):
plt.subplot(2,3,i)
plot_iris_projection(x_index, y_index)
plt.show()
|
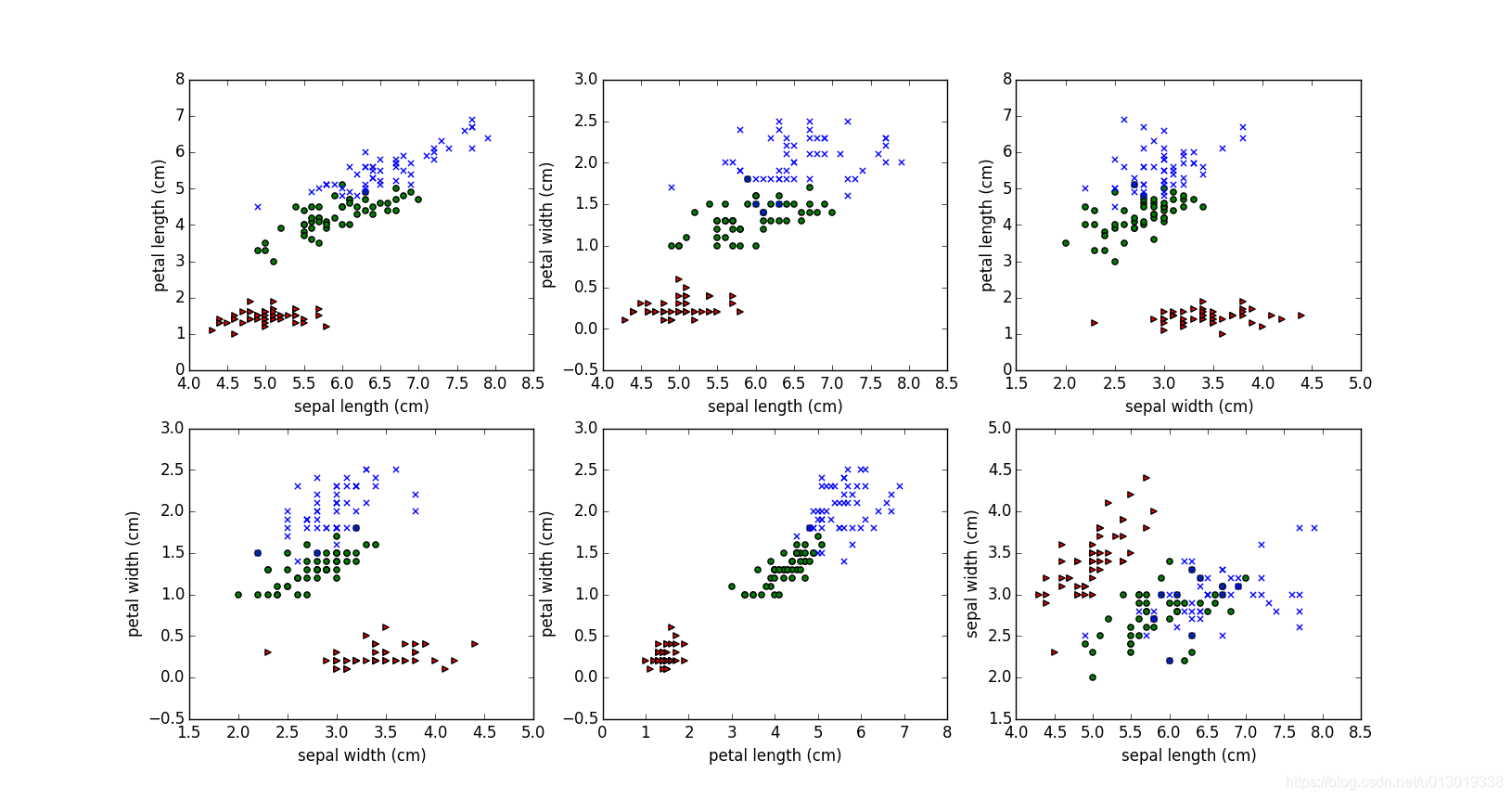
不难发现的是,不论在那两个特征下,山鸢尾花都能很好的和其他两种鸢尾花区分,但是另外两种鸢尾花的特征比较焦灼,如果只有这四个特征,有时人都难以区分。
数据可视化最高只能是三维,matplotlib也能胜任此工作
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | from mpl_toolkits.mplot3d import Axes3D
def plot_iris_projection3d(x_index, y_index, z_index):
fig = plt.figure()
ax = fig.add_subplot(111,projection='3d')
for t,marker,c in zip(xrange(3),'>ox', 'rgb'):
ax.scatter(data[target==t,x_index],
data[target==t,y_index],
data[target==t,z_index],
marker=marker,c=c)
ax.set_xlabel(feature_names[x_index])
ax.set_ylabel(feature_names[y_index])
ax.set_zlabel(feature_names[z_index])
plot_iris_projection3d(1, 2, 3)
plt.show()
|
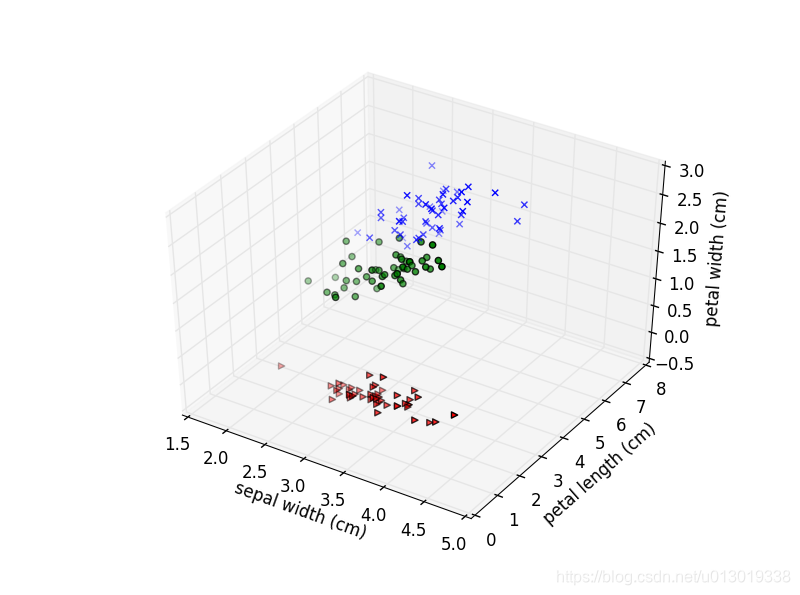








 本文深入探讨了经典的鸢尾花数据集,包括其历史背景、数据存储方式及内容介绍,展示了数据可视化方法,揭示了不同鸢尾花种类间的特征区别。
本文深入探讨了经典的鸢尾花数据集,包括其历史背景、数据存储方式及内容介绍,展示了数据可视化方法,揭示了不同鸢尾花种类间的特征区别。

















 1309
1309

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









