







Word2vec-tf版实现
word2vec思想
cbow的核心思想是利用上下文单词预测当前单词,skip-gram的核心思想是利用当前中心词预测上下文,HS的核心思想是为每个单词构建一棵huffman树,树上每个节点都拥有对应的隐向量,从而根据路径来计算单词的概率,NG的核心思想是每个单词都对应一个隐向量,然后进行负采样从而构建正负样本来进行预测。
skip-gram
这里主要说一下skip-gram
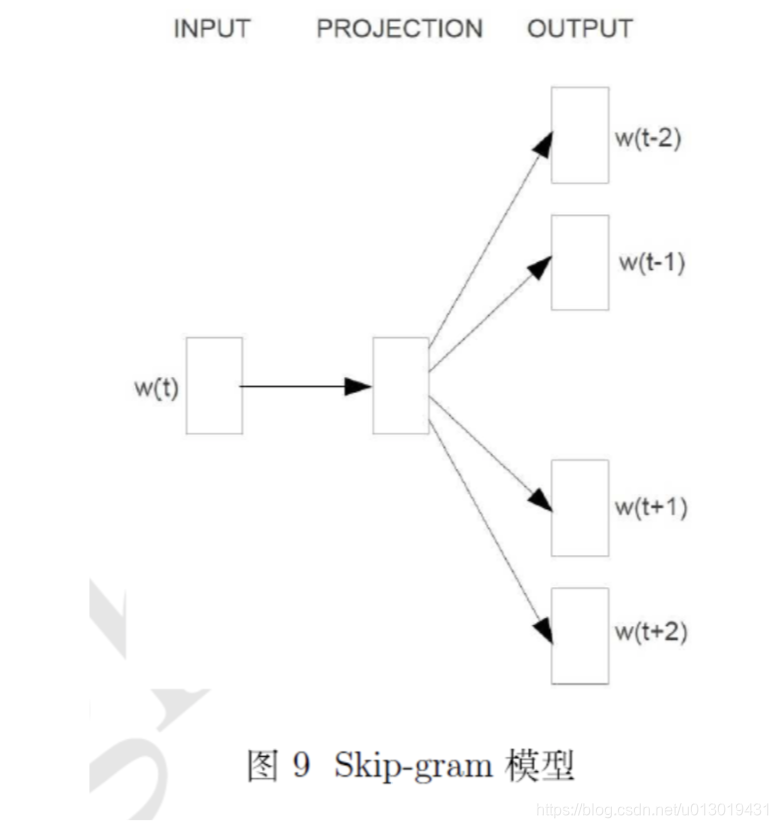
可以看到输入是中心词,输出是其上下窗口的词,我们以Negtive Sampling来说,假设窗口为2,那么这里就会生成四个条正样本,(t,t+2),(t,t+1),(t,t-1),(t,t-2)。
这里有个问题就是,如果采用上述来进行计算,那么四次均是更新t词而不会更新上下文,导致训练较慢,因此作者采用的实际是单个上下文预测中心词,将中心词作为正样本,再进行带权采样获取相应的负样本。
Negative Sampling
负采样的作用是针对每一个中心词都构建多个正样本,然后根据总体的词频来随机选择若干个预料作为负样本,假设负样本为5个,正样本为1个,则可以使用logloss作为损失来进行优化。
Tips
word2vec作者选择的是为每个单词都生成一个隐向量进行学习,而现在看很多的论文都是直接将embedding作为隐向量,而不再生成两份隐向量,因此这里实现也使用embedding作为隐向量的表示。
数据集
从搜狗实验室下载的迷你版新闻预料,下载下来是gbk编码的,需要转为utf-8


数据预处理
这里就是文本的简单预处理工作,用jieba分词后剔除停用词
def getStopWordSet(filename):
stop_word = set()
with open(filename) as f:
for line in f:
stop_word.add(line.strip())
return stop_word
def getNewList(filename):
stop_word = getStopWordSet('stopword.txt')
news = []
with open(filename) as f:
for line in f:
line = line.replace('<content>','').replace('/<content>','')
line_list = re.split(r'[\s,,.。;;!“]+',line)
if len(line_list) == 0:
continue
for t in line_list:
res = []
w_list = jieba.cut(t.strip())
for word in w_list:
if word not in stop_word:
res.append(word)
if len(res)>3:
news.append(res)
return news
Gensim
gensim是python的一个库,可以方便地对文本序列进行word2vec的训练,这里先用这个版本做一次训练看一下效果。
from gensim.models import Word2Vec
model = Word2Vec(news)
model.most_similar("活动")
'''
[('公益', 0.9305235147476196),
('中', 0.9187203645706177),
('基金', 0.9107365608215332),
('V', 0.9041927456855774),
('服务', 0.9039312601089478),
('详细', 0.9033830165863037),
('基金会', 0.9023610353469849),
('日', 0.8978089094161987),
('元', 0.8960500955581665),
('P', 0.8949539065361023)]
'''
说实话,效果挺烂的…这个主要和语料有关,我用的这个mini版就几千条记录,不过训练速度非常的快。
Tensorflow版
这个就是我自己实现的了,细节处理、速度等方面都是惨遭完爆,写这个的目的纯粹是让自己更加熟悉一下word2vec这个算法,原实现建议还是参考之前发的那篇word2vec源码,里面有许多的细节处理值得学习。
# 首先是NG部分的内容
# 定义一个新的类,保存word、cnt和索引
class vocab:
def __init__(self,word,cnt):
self.word = word
self.cnt = cnt
def addCnt():
self.cnt += 1
def setIndex(index):
self.index = index
# 统计词频
vocab_dict = defaultdict(int)
for new in news:
for word in new:
vocab_dict[word] += 1
# 将所有单词加入到一个统一的列表中
vocab_list = []
for key in vocab_dict.keys():
vocab_list.append(vocab(key,vocab_dict[key]))
# 对单词列表进行排序
vocab_list = sorted(vocab_list,key=lambda x:x.cnt,reverse=True)
# 按词频的高低为每个word赋予索引
for i in range(len(vocab_list)):
vocab_list[i].index = i
# 统计词频的总数量
all_cnt = sum(vocab_dict.values())
# 单词到索引的映射字典
word_index_map = dict()
for i in range(len(vocab_list)):
word_index_map[vocab_list[i].word] = i
def negativeSampling(current_index):
'''
params:
current_index 当前的正样本索引
return:
负采样的索引
ps:这里的负采样很呆,想偷懒直接按个遍历,但是这种效果很差,比较好的方式是直接生成一个随机数然后计算其落在哪个分区直接选择到对应的单词,这也是原作者的实现方案
pss:原作者的按词频采样过程中对每个单词的词频做了3/4次方的校验,可能是出于减少热门单词的负采样概率,我这里也没有做
'''
current_cnt = all_cnt - vocab_list[current_index].cnt
for i in range(len(vocab_list)):
if i == current_index:
continue
random_num = np.random.random_sample()
if random_num <= vocab_list[i].cnt/current_cnt:
return i
else:
current_cnt -= vocab_list[i].cnt
def ng_all(negative_sample,current_index):
'''
params:
negative_sample:负采样数量
current_index:
当前中心词的索引
'''
res = []
for i in range(negative_sample):
res.append(negativeSampling(current_index))
return res
上面部分都是负采样的部分,图方便实现的地方也都有点挫,只能用于简单了解下流程了。
下面是tensorflow的部分,tensorflow部分的实现主要还是基于embedding来做的,逻辑比较简单
'''
这里构建一下训练样本,跑的速度很慢,因为负采样那块写的不好
'''
train_data = []
cnt = 0
for new in news:
if cnt%200 == 0:
print("============{}/{}===============".format(cnt,len(news)))
cnt += 1
for i in range(len(new)):
# 列表,第一个为窗口词,第二个为中心词,第三个为负采样样本,保存的是索引值
tmp = []
tmp.append(word_index_map[new[i]])
for j in range(-window_size,window_size):
if j ==0 :
continue
if (i+j)<0 or (i+j) >= len(new):
continue
ng_list = ng_all(negative_sample,word_index_map[new[i]])
train_data.append((tmp+[word_index_map[new[i+j]]]+ng_list))
'''
train_data[0]
[580, 2128, 267, 2280, 4325]
'''
word_cnt = len(word_index_map.keys())
# define the word2vec structure
embedding_matrix = tf.Variable(tf.random_normal([word_cnt,embedding_size],stddev=0.1))
x = tf.placeholder(dtype=tf.int32,shape=[2+negative_sample])
window_word_index = tf.placeholder(dtype=tf.int32,shape=[1])
w = embedding_matrix[window_word_index[0]]
loss = -tf.log(tf.sigmoid(tf.reduce_sum(tf.multiply(w,embedding_matrix[x[0]]))))
for i in range(negative_sample):
loss = tf.add(loss,-tf.log(1-tf.sigmoid(tf.reduce_sum(tf.multiply(w,embedding_matrix[x[i+2]])))))
loss = loss/(negative_sample+1)
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01).minimize(loss)
sess = tf.InteractiveSession()
init = tf.global_variables_initializer()
sess.run(init)
# train the model
for line in train_data:
sess.run(optimizer,feed_dict={x:np.array(line),window_word_index:np.array(line[0]).reshape(1,)})
这里理论上每一条记录进去只更新窗口词的,但是我这里实现的几个隐向量都来源于embedding矩阵,也就是说其实会同时更新中心词、窗口词、负样本,这里我不晓得怎么才能只更新那一个值,可能每次把除了窗口词外的embedding都通过feed_dict传进来的话就可以了吧。
结果计算
def computeCos(s1,s2):
index1 = word_index_map[s1]
index2 = word_index_map[s2]
embed1 = embedding_m[index1]
embed2 = embedding_m[index2]
return np.dot(embed1,embed2)/(np.linalg.norm(embed1)*np.linalg.norm(embed2))
def getMostSim(s):
tmp = 0.0
word = ''
res = []
for key in word_index_map.keys():
if key == s:
continue
if computeCos(s,key)>tmp:
res.append(key)
tmp = computeCos(s,key)
word = key
print("the most sim key is {},cos is {}".format(word,tmp))
'''
getMostSim("活动")
['事']
效果也挺差的。。。。
'''
总结
- 实现的着实有点挫~比如最小词频未设置,词频过小会导致embedding基本就是随机初始化的状态
- 性能较差,运行很慢,不像gensim的运行速度非常之快
- 未验证我这样的实现是否还能获得word2vec近似的效果,至少速度上是慢的太多了
- 原作者用到了许多训练中的优化,例如利用近似计算优化sigmoid计算,随机抛弃高频词等
- 还是回到那句~主要还是了解下Negative Sampling的流程,其他的还是调包吧。。。。















 709
709

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









