







注:本博客只是供大家学习爬虫,如有违规,侵犯到了任何人的利益,请联系我,会立马删除博客内容。
一、数据分析
本次实验随便在链家上找到一个小区,搜二手房源信息。
打开F12进行页面数据分析,在首页,我们需要检查我们所需要爬的字段是否是通过js加载出来的,还要分析一共有多少页,以便爬取所有页的数据进行保存。
经分析得出,我们需要爬的字段可以直接用xpath去获取。
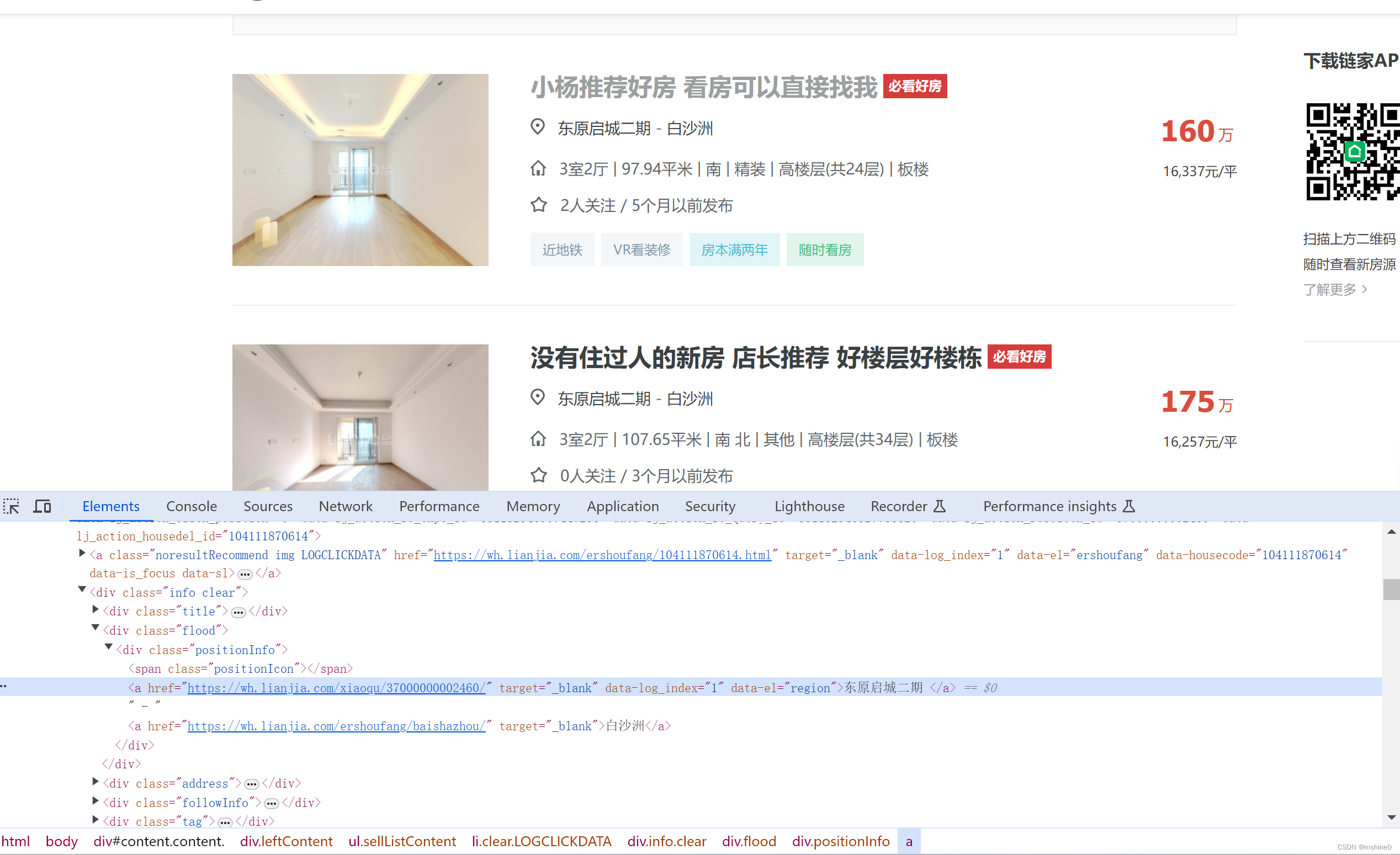
总页数经过页面分析,发现是通过js加载出来的。
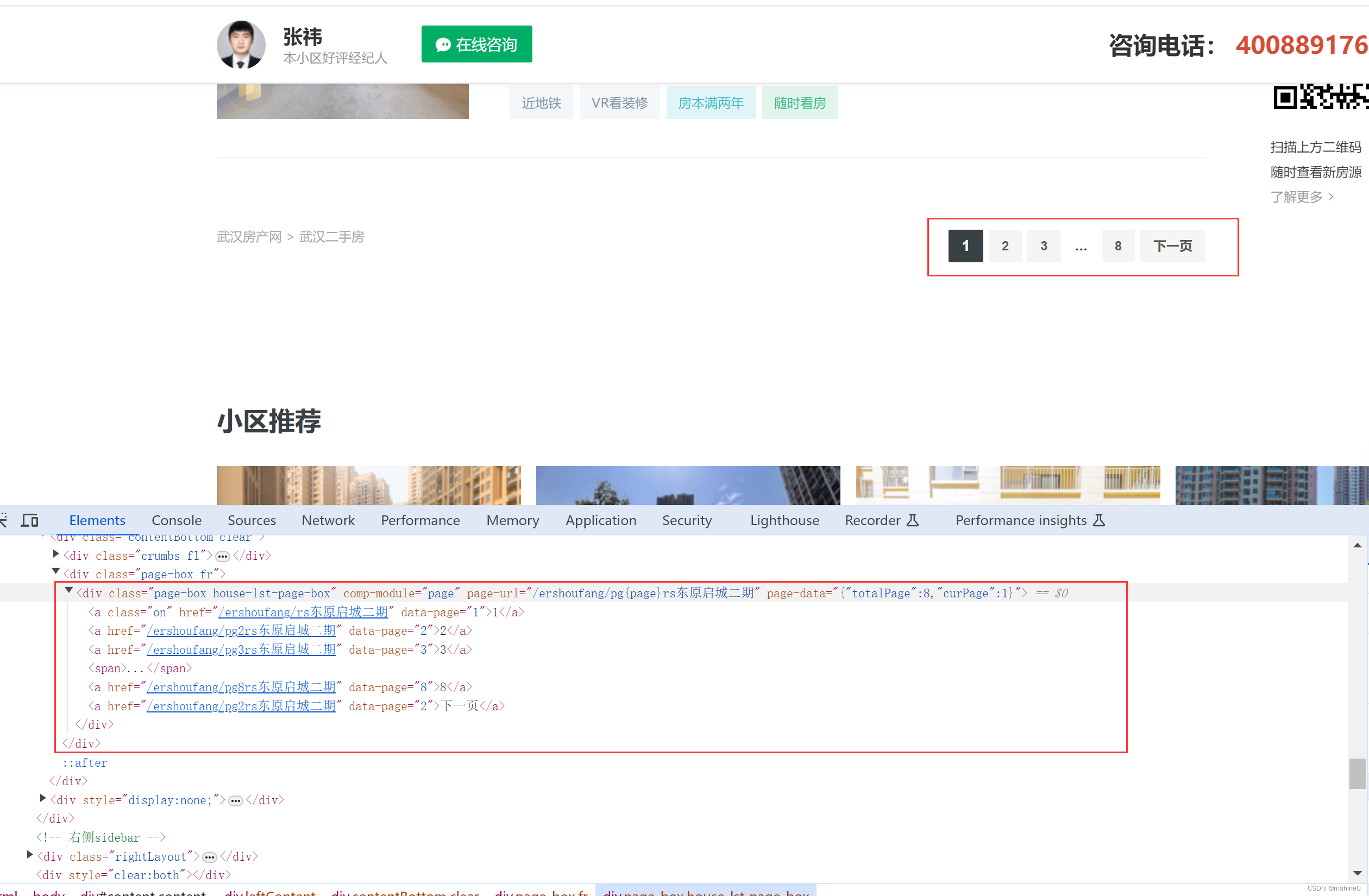
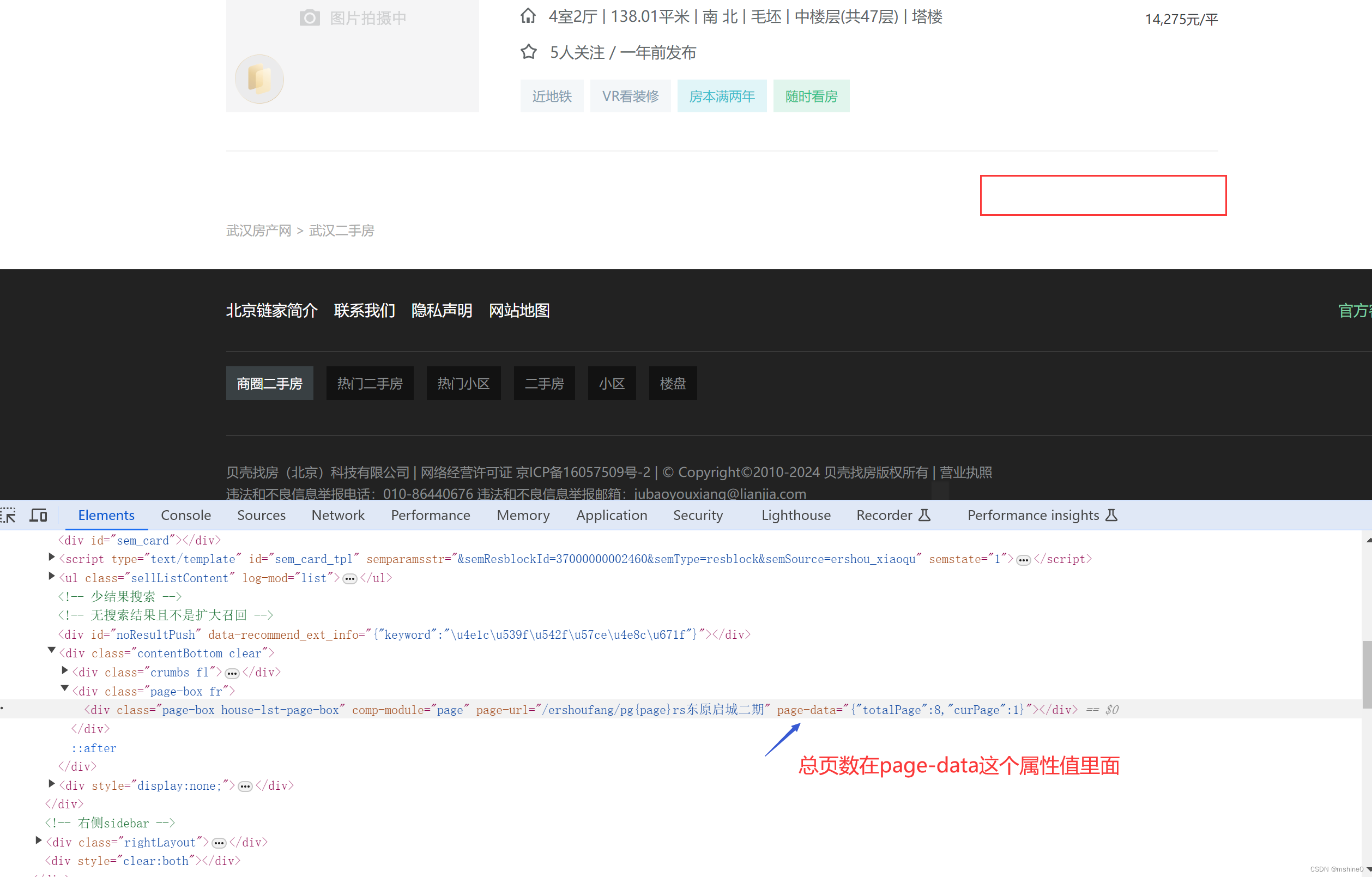
禁用浏览器加载javascript,刷新网页,发现总页数在当前div标签下的page-data属性值里面。那我们直接通过xpath获取当前标签了去取属性值就可以了,不用大费周折的去分析js代码了。
二、代码
全代码如下:
# 链家东原启城二期二手房
from lxml import etree
import requests
import pandas as pd
# 获取一页的数据
def one_page(page):
name = '东原启城二期'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36',
'Cookie': 'your cookie'
}
url = f'https://wh.lianjia.com/ershoufang/pg{page}rs' + name
res = requests.get(url=url, headers=headers)
page_info = etree.HTML(res.content)
info_list = page_info.xpath('//*[@id="content"]/div[1]/ul/li')
df_one = []
for i in info_list:
title = i.xpath('./div[1]/div[2]/div[1]/a[1]/text()')[0] # 小区名
page_url = i.xpath('./a[1]/@href')[0] # 房源详情页url
house_type = i.xpath('./div[1]/div[3]/div[1]/text()')[0].split('|')[0] # 户型
area = i.xpath('./div[1]/div[3]/div[1]/text()')[0].split('|')[1] # 面积
floor = i.xpath('./div[1]/div[3]/div[1]/text()')[0].split('|')[4] # 楼层
follow = i.xpath('./div[1]/div[4]/text()')[0].split('/')[0] # 关注
publish = i.xpath('./div[1]/div[4]/text()')[0].split('/')[1] # 发布时间
total_price = i.xpath('./div[1]/div[6]/div[1]/span/text()')[0] + '万' #总价
unit_price = i.xpath('./div[1]/div[6]/div[2]/span/text()')[0] # 单价
df_first = pd.DataFrame([{
'小区名': title,
'面积': area,
'户型': house_type,
'楼层': floor,
'发布时间': publish,
'关注人数': follow,
'总价': total_price,
'单价': unit_price,
'房源详情': page_url,
}])
df_one.append(df_first)
page_num = page_info.xpath('//*[@id="content"]/div[1]/div[7]/div[2]/div/@page-data')[0].split(',')[0].split(':')[1] # 获取总页数
return page_num, df_one
def all_page():
# 存储表
df_all = pd.DataFrame()
total_page_num, _ = one_page(1)
for i in range(int(total_page_num)):
print(f'正在获取第{i+1}页的数据')
_, df_one = one_page(i+1)
# 追加写入表
df_all = df_all._append(df_one, ignore_index=True)
return df_all
df_nianjia = all_page()
df_nianjia.to_excel('东原启城二期.xlsx', index=False)
要爬其它的小区,只需要改代码中的name值就可以了。
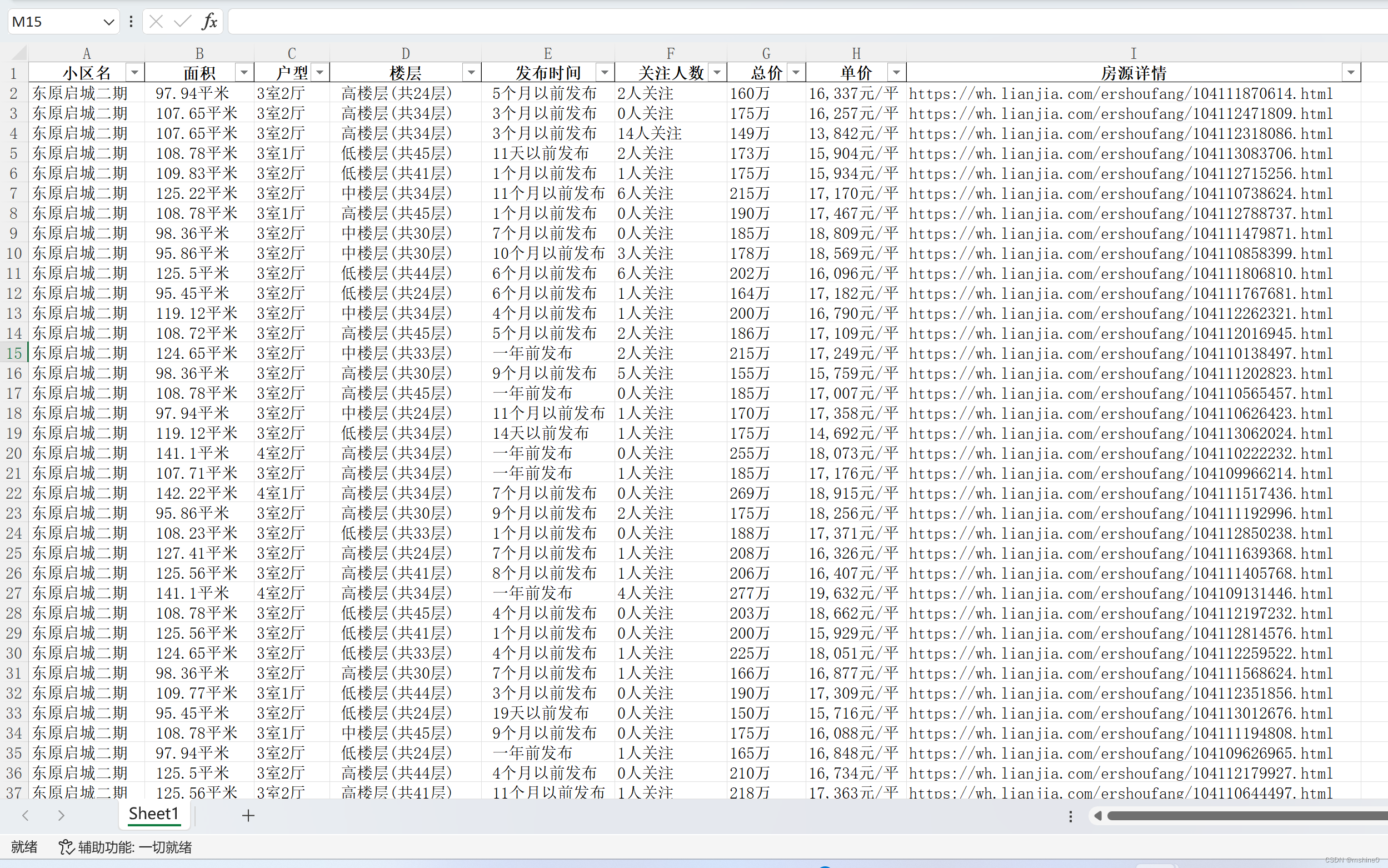
运行结果如下:
如果本篇博客对你有帮助,希望一起探讨更多python编程知识的,可私V:xiaodingdang0814。
欢迎大家点赞、评论、收藏,共同进步。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









