







注:本博客只是供大家学习爬虫,如有违规,侵犯到了任何人的利益,请联系我,会立马删除博客内容。
一、数据分析
根据自己的需求,进行数据筛选,打开F12查看数据包。
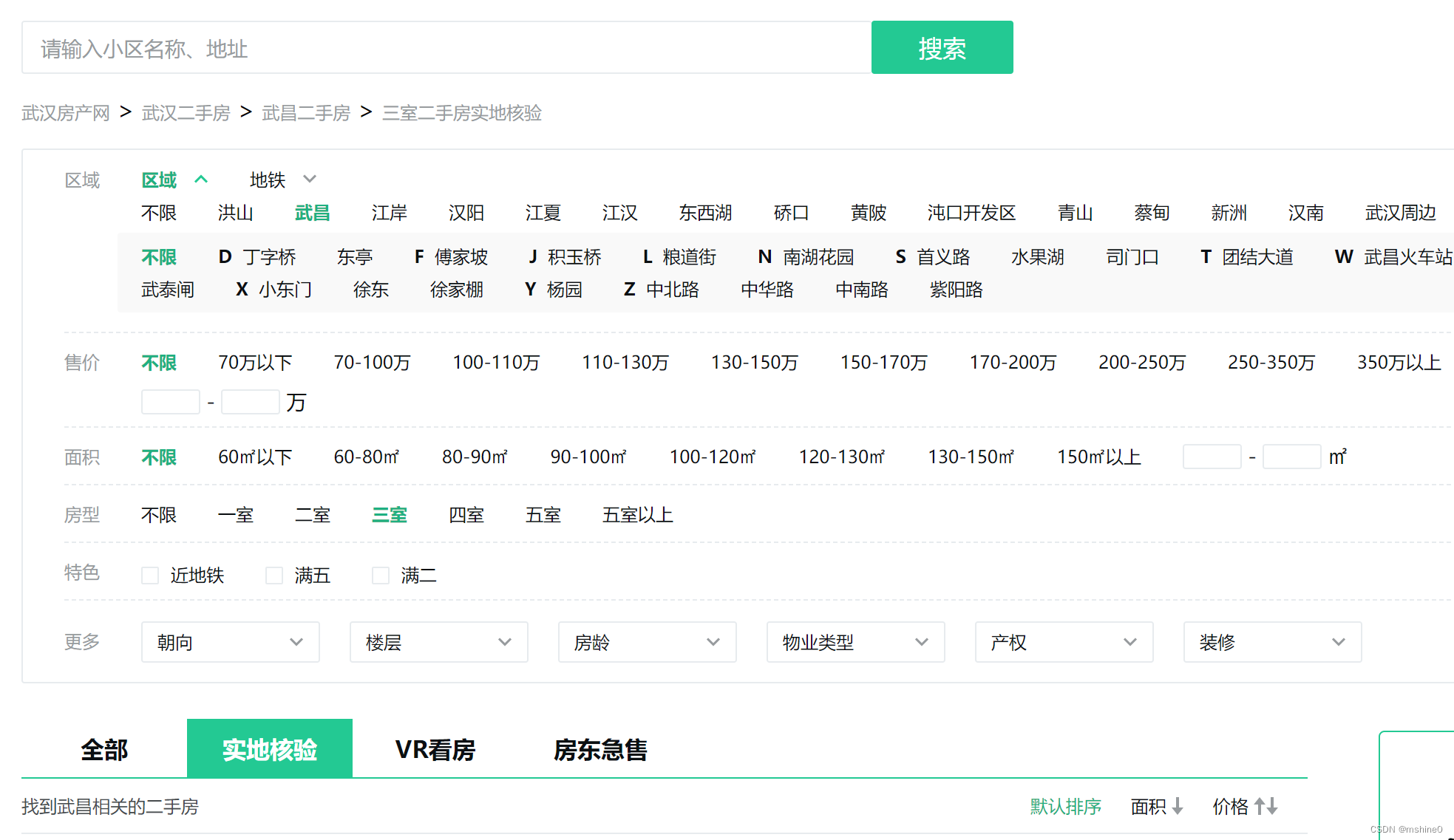
本次实验爬取的字段有:小区名、小区地址、户型、面积、均价、总价。通过数据分析,发现我们需要的这些字段并不是通过ajax请求返回的,所以我们使用xpath来获取我们需要的数据。
首页的所有房源信息的数据分析完成后,需要再分析一共有多少页,以便获取所有页的房源数据。查看页面源码,看到在一个隐藏的<'li>标签中有总页数。
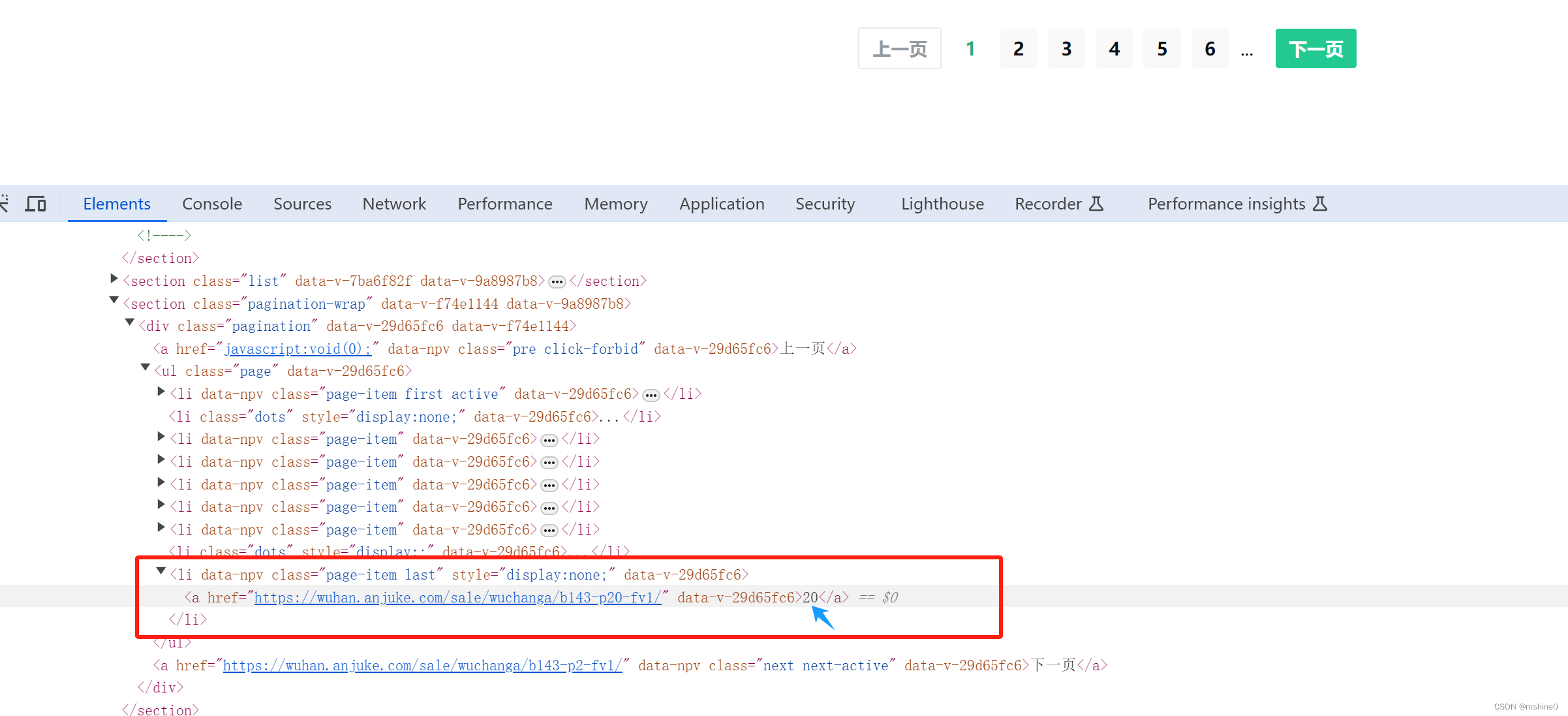
通过xpath获取总页数
total_page_num = page_info.xpath('//*[@id="esfMain"]/section/section[3]/section[1]/section[4]/div/ul/li[9]/a[1]/text()')[0]
二、代码
全代码如下:
# 武昌二手房,三室
import requests
from lxml import etree
import pandas as pd
def one_page(page):
url = f'https://wuhan.anjuke.com/sale/wuchanga/b143-p{page}-fv1/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36',
'Referer': 'https://wuhan.anjuke.com/sale/wuchanga/p9-fv1/',
'Cookie': 'your cookie'
}
res = requests.get(url=url, headers=headers).content.decode()
page_info = etree.HTML(res)
# 获取单页所有的小区名,小区地址,户型,总价,均价,面积
info_list = page_info.xpath('//*[@id="esfMain"]/section/section[3]/section[1]/section[2]/div')
df_one = []
for i in info_list:
title = i.xpath('./a/div[2]/div[1]/section[1]/div[2]/p[1]/text()')[0] # 小区名
address_list = i.xpath('./a/div[2]/div[1]/section[1]/div[2]/p[2]/span') # 小区地址
address = ''
for j in address_list:
address = address + j.xpath('./text()')[0] + '-'
huxing_list = i.xpath('./a/div[2]/div[1]/section[1]/div[1]/p[1]/span') # 户型
huxing = ''
for j in huxing_list:
huxing = huxing + j.xpath('./text()')[0]
area = i.xpath('./a/div[2]/div[1]/section[1]/div[1]/p[2]/text()')[0].strip() # 面积
total_price = i.xpath('./a/div[2]/div[2]/p[1]/span/text()')[0] + '万' # 总价
unit_price = i.xpath('./a/div[2]/div[2]/p[2]/text()')[0] # 单价
df_first = pd.DataFrame([{
'小区': title,
'地址': address,
'户型': huxing,
'面积': area,
'单价': unit_price,
'总价': total_price,
}])
df_one.append(df_first)
# 获取有一共有多少页
total_page_num = page_info.xpath('//*[@id="esfMain"]/section/section[3]/section[1]/section[4]/div/ul/li[9]/a[1]/text()')[0]
return total_page_num, df_one
total_page_num, _ = one_page(1)
print(total_page_num)
# 获取多页数据
def all_page():
# 存储表
df_all = pd.DataFrame()
for i in range(int(total_page_num)):
print(f'正在打印第{i+1}页的数据')
_, df_one = one_page(i+1)
# 追加写入表
df_all = df_all._append(df_one, ignore_index=True)
return df_all
df_anjuke = all_page()
df_anjuke.to_excel('安居客.xlsx', index=False)
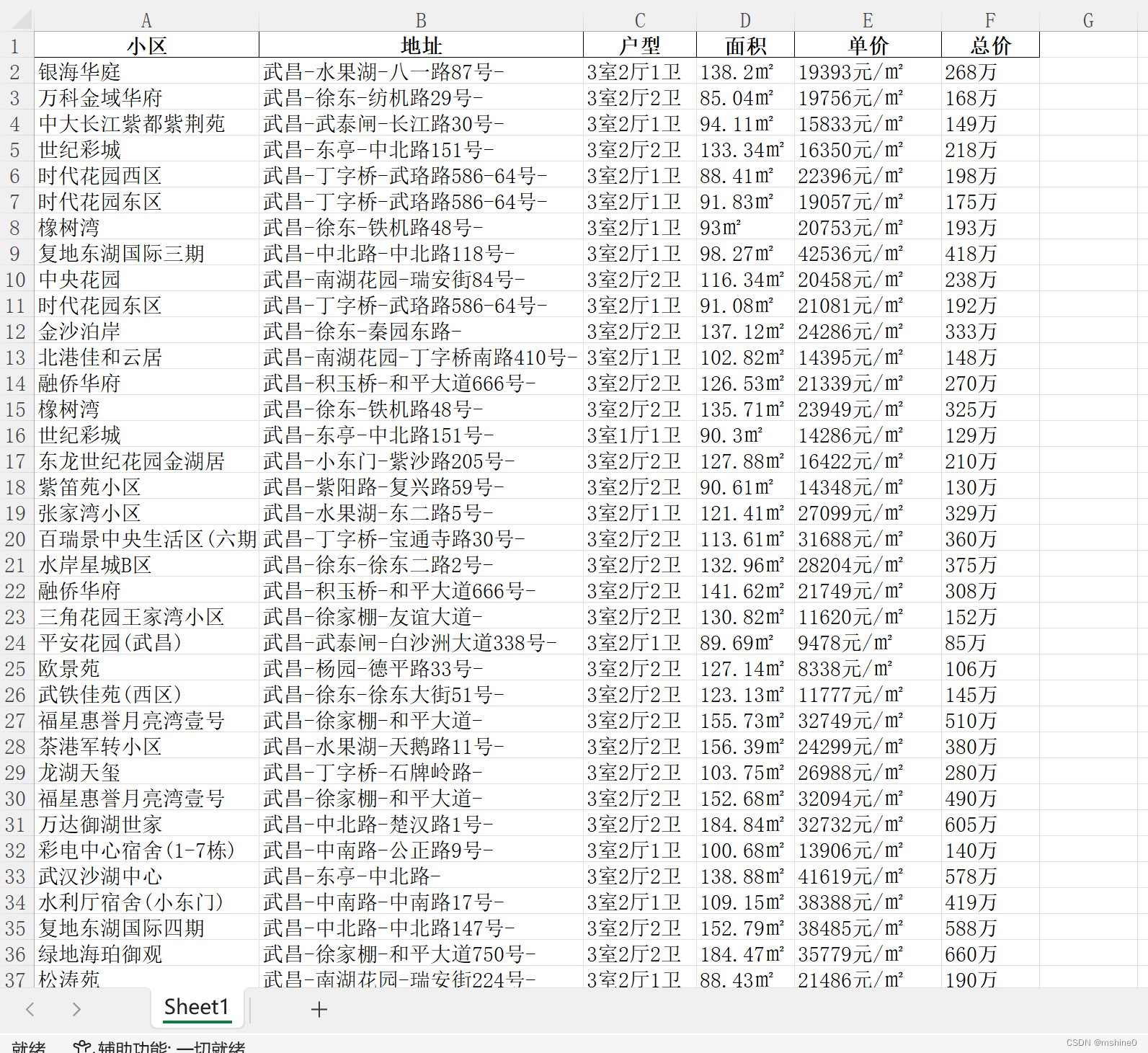
运行结果如下:
如果本篇博客对你有帮助,希望一起探讨更多python编程知识的,可私V:xiaodingdang0814。
欢迎大家点赞、评论、收藏,共同进步。

















 6692
6692

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









