







去年的一段时间,工作非常忙碌,项目的需求一个接着一个,简直让人头皮发麻啊。当然,每次新需求出来上头总需要给一个合理的排期,以便按时按质完成。今年相对去年来说没那么忙碌,于是抽空写了这篇博客,也算是一个小小的总结吧。下面来说一下本人是如何进行新需求开发时间的评估,也算是自己对以前知识的回顾和学以致用的思想。
假设我们软件开发的工时和需求的用例、实体数量、涉及的数据表数量相关,以历史数据为训练样本:
| 需求 | 工时 | 用例数量 | 实体数量 | 数据表数量 |
|---|---|---|---|---|
| A | 424 | 37 | 15 | 25 |
| B | 267 | 20 | 9 | 18 |
| C | 90 | 6 | 4 | 7 |
| D | 331 | 18 | 11 | 16 |
| E | 160 | 12 | 14 | 18 |
| 相关系数 | 0.933597 | 0.650825 | 0.827538 | |
| 显著性 | 0.006244 | 0.006912 | 0.007067 |
那么什么是相关性呢,从直观意义上说,两个变量的相关性是指两个变量关联的紧密程度,数学上可以用相关系数表示。相关系数的计算公式如下:
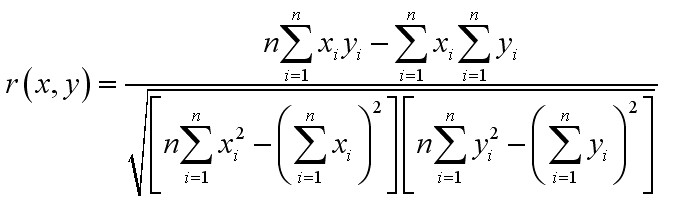
一般来说,|r|大于0.7就有很好的相关性了,而计算结果可以看出,用例数量和工期的相关系数达到了0.93,最为优秀,而数据表数量也达到了0.83,唯有实体数量的相关系数仅为0.65,质量较差,所以首先排除掉。
还有一点要考虑,就是显著性。所谓的显著性就是在偶然情况下得到此结果的概率,如果显著性不足,说明结果不可靠。显著性的计算公式如下:
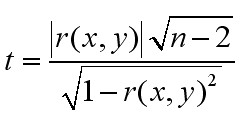
通过相关性和显著性分析,最终确定使用文档中的用例数量作为x,知道了x值,下面就要确定相关函数。这一步最艰难也是最有技术性的,因为相关函数不但和梳理因素相关,还与开发团队和管理方法有关。如果人员变动很大或者管理方法做了很大的调整,历史数据可能就不具备参考价值了,不过如果团队的开发水平和管理方法没有重大的变动,这个函数还是相对稳定的。
在函数选型上,一般会选择线性函数,为了简单起见,我们按照使用线性函数作为预测模型,这样可建立一元线性回归模型如下:
y = a + bx + e;
因为e的数学期望为0,所以只要给出a和b的合理估计,就可以得到y的一个无偏估计。下面我们估计a和b的值。估计方法很多,如曲线拟合法和最小二乘法进行估计。这里我们选取最小二乘法进行估计,有最小二乘法公式:
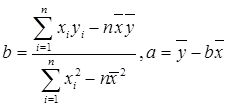
由数据:
| 用例数量 | 37 | 20 | 6 | 18 | 12 |
| 工时 | 424 | 267 | 90 | 331 | 160 |
所以可得需求工时估算的回归方程为:y = 10.65x + 56.31;
有了上面的回归方程,我们就可以轻易的得出新需求的计划工时,从而合理进行排期。
例如新需求有50个用例,代入我们的工时估算回归方程得:
y = 10.65 * 50 + 56.31
= 588.81;
然后再根据参与开发的人数,即可计算该需求的开发周期,制定合理的开发计划。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









