







面试机器学习岗位或者算法岗位,经常会被问到一些机器学习算法,其中还有很多细节性的知识。在面试中接触到的LR模型是最多的,为什么?大概原因是LR在公司中用的比较多,这时你可能会问了,这个算法不是很简单吗,性能一般是比不上集成学习算法的。对的,确实是这样,但是公司做应用时不仅仅需要考虑性能,还得考虑效率,简单高效很重要。
1.之前听其他面试者说,遇到过写LR中损失函数的推导,也就是从概率一般式 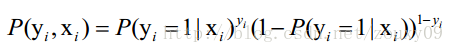
 在机器学习面试中,LR模型因其实际应用广泛而常被问及。面试问题包括:LR损失函数的推导,为什么使用似然函数,线性模型的局限,L1和L2正则化的意义以及如何降低模型复杂度,L1正则化为何产生稀疏解,以及L1正则化求解方法等。理解这些细节对于在实际工作中应用LR模型至关重要。
在机器学习面试中,LR模型因其实际应用广泛而常被问及。面试问题包括:LR损失函数的推导,为什么使用似然函数,线性模型的局限,L1和L2正则化的意义以及如何降低模型复杂度,L1正则化为何产生稀疏解,以及L1正则化求解方法等。理解这些细节对于在实际工作中应用LR模型至关重要。
面试机器学习岗位或者算法岗位,经常会被问到一些机器学习算法,其中还有很多细节性的知识。在面试中接触到的LR模型是最多的,为什么?大概原因是LR在公司中用的比较多,这时你可能会问了,这个算法不是很简单吗,性能一般是比不上集成学习算法的。对的,确实是这样,但是公司做应用时不仅仅需要考虑性能,还得考虑效率,简单高效很重要。
1.之前听其他面试者说,遇到过写LR中损失函数的推导,也就是从概率一般式
 1159
1159

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章





















