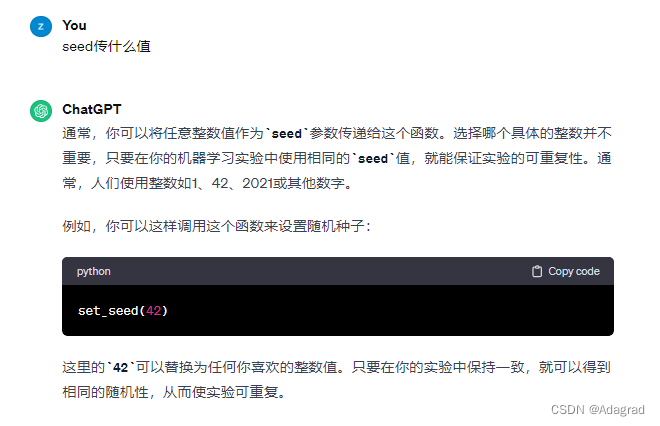
seed
def set_seed(seed):
torch.manual_seed(seed) # 为CPU设置随机种子
torch.cuda.manual_seed(seed) # 为当前GPU设置随机种子
torch.cuda.manual_seed_all(seed) # 为所有GPU设置随机种子
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
random.seed(seed)
numpy.random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)

 filterwarnings
filterwarnings

os.environ["CUDA_VISIBLE_DEVICES"]

torch.set_default_tensor_type

lambda: None

from_numpy、detach
self.transform = lambda x: torch.from_numpy(x).permute(2, 0, 1).type(torch.FloatTensor).div(255)
# 16, 3, 256, 256 -> 16, 256, 256, 3
self.restore = lambda x: x.detach().cpu().mul(255).permute(0, 2, 3, 1).numpy().astype('uint8')

DataLoader
valid_loader = DataLoader(
valid_dataset,
batch_size=opt.valid_batch_size,
shuffle=False,
# 为了泛化, 对验证数据集进行重复采样, 而且还会进行数据增强
sampler=torch.utils.data.RandomSampler(valid_dataset, replacement=True, num_samples=opt.valid_repeat * len(valid_dataset)))

cuda()

optimizer
optimizer = opt.optimizer(filter(lambda p: p.requires_grad, network.parameters()), lr=opt.lr, weight_decay=1e-5)
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=lr_decay)


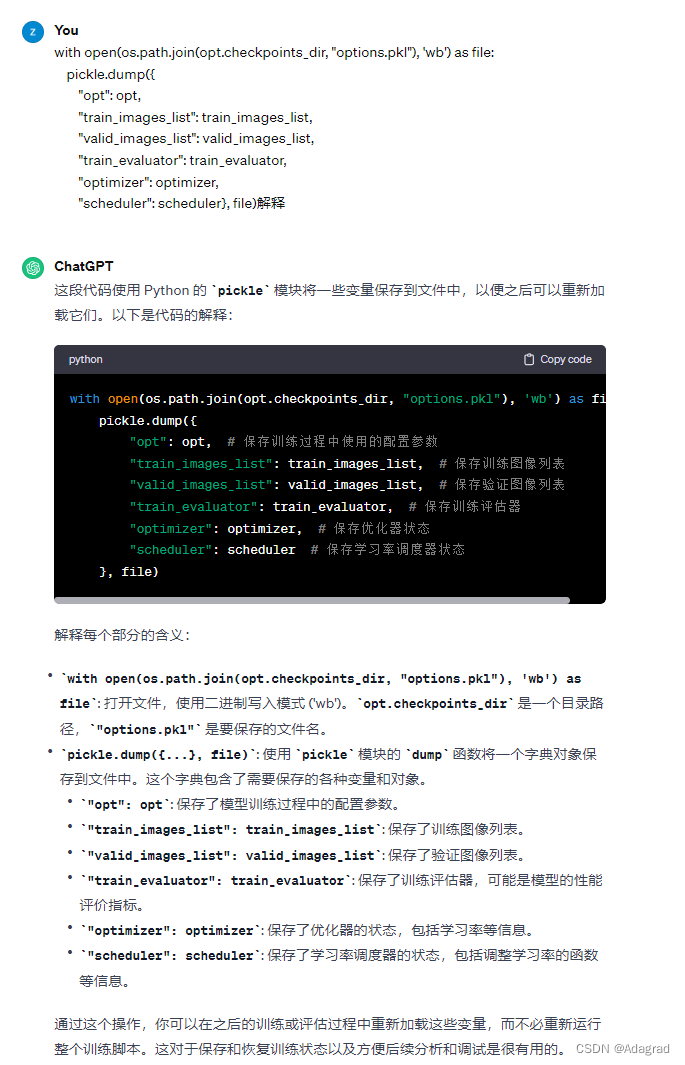
pickle
__enter__、__exit__
class Timer:
def __enter__(self):
self.start = datetime.datetime.now()
def __exit__(self, type, value, trace):
_end = datetime.datetime.now()
print('耗时 : {}'.format(_end - self.start))

train()

optimizer.zero_grad()

optimizer.step()

loss_value.backward()

scheduler.step()

with torch.no_grad()























 418
418











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









