







Abstract
Retinex模型是低光图像增强的有效工具。它假设观察到的图像可以分解为反射率和照度。大多数现有的基于 Retinex 的方法都为这种高度不适定的分解精心设计了手工约束和参数,在应用于各种场景时可能会受到模型容量的限制。在本文中,我们收集了包含低光/正常光图像对的低光数据集(LOL),并提出了在此数据集上学习的深度 Retinex-Net,包括用于分解的 Decom-Net 和用于照明调整的增强网络。在 Decom-Net 的训练过程中,不存在分解反射率和光照的基本事实。该网络仅在关键约束下进行学习,包括成对的低/正常光图像共享的一致反射率以及照明的平滑度。基于分解,随后通过称为Enhance-Net的增强网络对照明进行亮度增强,并且对于联合去噪,对反射率进行去噪操作。 Retinex-Net 是端到端可训练的,因此学习到的分解本质上有利于亮度调整。大量的实验表明,我们的方法不仅能够实现低光增强的视觉上令人愉悦的质量,而且还提供了图像分解的良好表示。
1 Introduction
图像捕捉中的照明不足会显着降低图像的可见度。丢失的细节和低对比度不仅会导致不愉快的主观感受,还会损害许多为正常光图像设计的计算机视觉系统的性能。造成照明不足的原因有很多,如环境光照不足、摄影器材性能有限、器材配置不当等。为了使隐藏的细节可见,提高当前计算机视觉系统的主观体验和可用性,需要弱光图像增强。
在过去的几十年里,许多研究人员致力于解决低光图像增强问题。人们已经开发了许多技术来提高低光图像的主观和客观质量。直方图均衡(HE)[20]及其变体限制输出图像的直方图以满足一些约束。基于去雾的方法[5]利用光照不足的图像与雾霾环境中的图像之间的逆联系。
另一类低光增强方法建立在 Retinex 理论 [12] 的基础上,该理论假设观察到的彩色图像可以分解为反射率和照明度。单尺度 Retinex(SSR)[11]作为早期尝试,通过高斯滤波器约束照明图平滑。多尺度 Retinex (MSRCR) [10] 通过多尺度高斯滤波器和色彩恢复扩展了 SSR。 [23]提出了一种通过亮度顺序误差测量来保持照明自然度的方法。傅等人[7]提出融合初始光照图的多个推导。 SRIE [7] 使用加权变分模型同时估计反射率和照度。操纵照明后,可以恢复目标结果。另一方面,LIME [9]仅利用结构先验来估计光照,并使用反射作为最终的增强结果。还有基于 Retinex 的联合低光增强和噪声消除方法 [14, 15]。
尽管这些方法在某些情况下可能会产生有希望的结果,但它们仍然受到反射率和照明分解模型能力的限制。设计可应用于各种场景的良好工作约束的图像分解是很困难的。此外,对光照图的操作也是手工制作的,这些方法的性能通常依赖于仔细的参数调整。
随着深度神经网络的快速发展,CNN已广泛应用于低级图像处理,包括超分辨率[6,24,26,27],除雨[16,21,25]等。洛尔等人[17]使用堆叠稀疏去噪自动编码器来同时进行低光增强和降噪(LLNet),但是没有考虑低光图片的性质。
为了克服这些困难,我们提出了一种数据驱动的 Retinex 分解方法。构建了一个集成图像分解和连续增强操作的深度网络,称为 Retinex-Net。首先,使用子网络 Decom-Net 将观察到的图像分割为与照明无关的反射率和结构感知的平滑照明。 Decom-Net 的学习有两个约束。首先,低光/正常光图像具有相同的反射率。其次,照明图应该平滑但保留主要结构,这是通过结构感知的总变化损失获得的。然后,另一个增强网络调整照明图以保持大区域的一致性,同时通过多尺度串联定制局部分布。由于噪声在黑暗区域通常更大,甚至在增强过程中被放大,因此引入了反射率去噪。为了训练这样的网络,我们构建了来自真实摄影的低/正常光图像对和来自 RAW 数据集的合成图像的数据集。大量的实验表明,我们的方法不仅在低光增强中实现了令人愉悦的视觉质量,而且还提供了良好的图像分解表示。我们的工作贡献总结如下:
• 我们使用在真实场景中捕获的配对低光/正常光图像构建了一个大规模数据集。据了解,这是在弱光增强领域的首次尝试。
• 我们构建了基于Retinex 模型的深度学习图像分解。分解网络与连续的低光增强网络进行端到端训练,因此该框架本质上擅长光照条件调整。
• 我们提出了一种用于深度图像分解的结构感知总变分约束。通过减轻梯度强的地方的总变化的影响,该约束成功地平滑了照明图并保留了主要结构。
2 Retinex-Net for Low-Light Enhancement
经典的 Retinex 理论模拟了人类的色彩感知。它假设观察到的图像可以分解为两个组成部分:反射率和照明度。设S代表源图像,则可以表示为

其中 R 代表反射率,I 代表照明度,◦ 代表逐元素乘法。反射率描述了捕获物体的内在属性,在任何亮度条件下都被认为是一致的。照度代表物体上的各种亮度。在低光图像上,通常会出现黑暗和照明分布不平衡的情况。
受 Retinex 理论的启发,我们设计了一个深度 Retinex-Net 来联合执行反射/照明分解和低光增强。网络由分解、调整、重构三个步骤组成。在分解步骤中,Retinex-Net 通过 Decom-Net 将输入图像分解为 R 和 I。它在训练阶段采用成对的低光/正常光图像,而在测试阶段仅将低光图像作为输入。在低/正常光图像共享相同反射率和照明平滑度的限制下,Decom-Net 学习以数据驱动的方式提取不同照明图像之间的一致 R。在调整步骤中,使用增强网络来照亮照明图。 Enhance-Net采用编码器-解码器的总体框架。多尺度串联用于保持大区域中照明与上下文信息的全局一致性,同时通过集中注意力调整局部分布。此外,如果需要,可以从反射率中消除经常出现在弱光条件下的放大噪声。然后,我们在重建阶段通过逐元素乘法组合调整后的照明和反射率。
2.1 Data-Driven Image Decomposition
分解观察到的图像的一种方法是直接在低光输入图像上利用精心设计的约束来估计反射率和照明。由于方程(1)的不适定性很高,因此设计适合各种场景的合适约束函数并不容易。因此,我们尝试以数据驱动的方式解决这个问题。
在训练阶段,Decom-Net 每次都会接收成对的低光/正常光图像,并在低光图像和正常光图像共享的指导下学习低光及其相应的正常光图像的分解相同的反射率。请注意,虽然分解是使用成对数据进行训练的,但它可以在测试阶段单独分解低光输入。在训练过程中,不需要提供反射率和光照的真实情况。仅将反射率的一致性和照明图的平滑度等必要的知识作为损失函数嵌入到网络中。因此,我们的网络的分解是从配对的低/正常光图像中自动学习的,并且本质上适合描绘不同光照条件下图像之间的光变化。
需要注意的是,虽然该问题在形式上可能与本征图像分解相似,但本质上是不同的。在我们的任务中,我们不需要准确地获得实际的本征图像,而是需要一个良好的光调整表示。因此,我们让网络学习找到低光图像与其相应的增强结果之间的一致成分。
如图1所示,Decom-Net以低光图像Slow和正常光图像Snormal作为输入,然后分别估计Slow的反射率Rlow和照度Ilow,以及Snormal的Rnormal和Inormal。它首先使用 3×3 卷积层从输入图像中提取特征。然后,使用多个以整流线性单元(ReLU)作为激活函数的 3×3 卷积层将 RGB 图像映射为反射率和照明度。 3×3卷积层从特征空间投影R和I,并使用sigmoid函数将R和I约束在[0, 1]范围内。
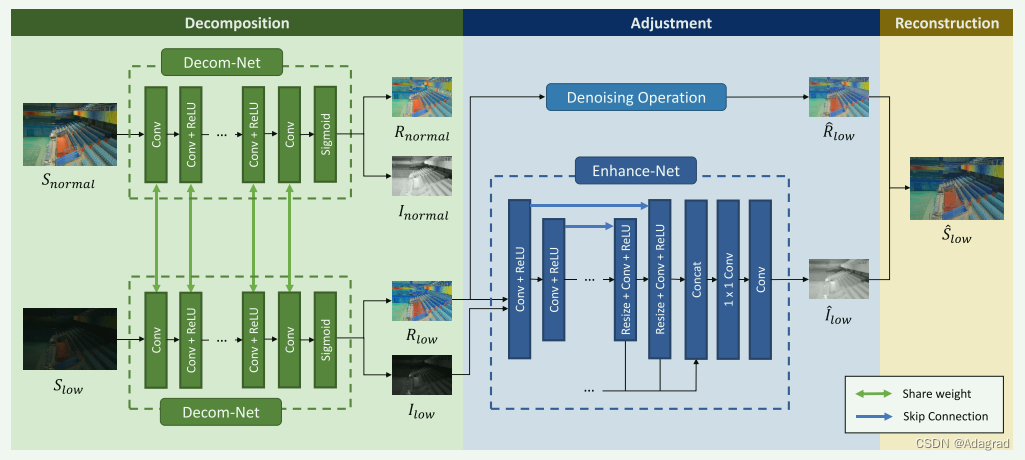
Figure 1: Retinex-Net 的拟议框架。增强过程分为分解、调整和重构三个步骤。在分解步骤中,子网络 Decom-Net 将输入图像分解为反射率和照明度。在接下来的调整步骤中,基于增强网络的编码器-解码器使照明变亮。引入多尺度串联来从多尺度角度调整照明。反射率上的噪声也在此步骤中被去除。最后,我们重建调整后的光照和反射率以获得增强的结果。
损失L由三项组成:重建损失Lrecon、不变反射率损失Lir和照明平滑度损失Lis:

其中λir和λis表示平衡反射率一致性和光照平滑度的系数。
基于Rlow和Rhigh都可以用相应的光照图重建图像的假设,重建损失Lrecon可表述为:

 引入不变反射率损耗Lir来约束反射率的一致性:
引入不变反射率损耗Lir来约束反射率的一致性:

照明平滑度损失Lis将在下面的部分中详细描述。
2.2 Structure-Aware Smoothness Loss
正如[9]中提到的,光照图的一个基本假设是局部一致性和结构感知。换句话说,一个好的光照贴图解决方案应该在纹理细节上是平滑的,同时仍能保留整体结构边界。
全变差最小化(TV)[2],它最小化整个图像的梯度,通常用作各种图像恢复任务的平滑先验。然而,在图像具有较强结构或亮度变化剧烈的区域,直接使用 TV 作为损失函数会失败。这是由于无论该区域是文本细节还是强边界,照明图的梯度都会均匀减小。换句话说,TV损失是结构失明。照明模糊,反射率上留下强烈的黑色边缘,如图 2 所示。
为了使损失了解图像结构,原始TV函数用反射图的梯度进行加权。最终的 Lis 表述为:
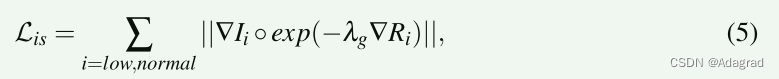
其中∇表示梯度,包括∇h(水平)和∇v(垂直),λg表示平衡结构感知强度的系数。通过权重 exp(−λg∇Ri),Lis 放松了反射率梯度陡峭的地方(换句话说,图像结构所在的位置以及照明应该不连续的地方)对平滑度的约束。
尽管 LIME [9] 也考虑在加权TV约束的照明图中保留图像结构,但我们认为这两种方法是不同的。对于 LIME,总变化约束由初始照明图加权,该图是 R、G 和 B 通道中每个像素的最大强度。相反,我们的结构感知平滑度损失是通过反射率来加权的。 LIME 中使用的静态初始估计可能无法像反射率那样描述图像结构,因为反射率被假定为图像的物理属性。由于我们的 Decom-Net 是使用大规模数据进行离线训练的,因此可以在训练阶段同时更新光照和权重(反射率)。
2.3 Multi-Scale Illumination Adjustment
照明增强网络采用编码器-解码器架构的总体框架。为了从层次角度调整照明,我们引入了多尺度串联,如图 1 所示。
编码器-解码器架构获取大区域的上下文信息。输入图像被连续下采样到小尺度,这样网络就可以了解大尺度的光照分布。这给网络带来了自适应调整的能力。利用大规模照明信息,上采样块重建局部照明分布。通过逐元素求和,从下采样块到其相应的镜像上采样块引入跳跃连接,这强制网络学习残差。
为了分层调整照明,即保持全局照明的一致性,同时调整不同的局部照明分布,引入了多尺度串联。如果有 M 个逐步上采样块,每个块提取一个 C 通道特征图,我们通过最近邻插值在不同尺度上调整这些特征的大小到最终尺度,并将它们连接到一个 C×M 通道特征图。然后,通过 1×1 卷积层,连接的特征被缩减为 C 个通道。接下来是 3×3 卷积层来重建照明图 。
下采样块由步幅为 2 的卷积层和 ReLU 组成。在上采样块中,使用了调整大小卷积层。正如[19]中所演示的,它可以避免伪影的棋盘图案。调整大小卷积层由最近邻插值操作、步幅为 1 的卷积层和 ReLU 组成。
Enhance-Net 的损失函数 L 由重建损失 Lrecon 和照明平滑度损失 Lis 组成。 Lrecon 的意思是产生法线光 ,即

Lis 与式(5)相同,只是 通过 Rlow 的梯度图进行加权。
2.4 Denoising on Reflectance
在分解步骤中,对网络施加了几个约束,其中之一是光照图的结构感知平滑度。当估计的照明图平滑时,细节都保留在反射率上,包括增强的噪声。因此,我们可以在用照明图重建输出图像之前对反射率进行去噪方法。鉴于分解过程中暗区的噪声会根据亮度强度而放大,因此我们应该使用与照明相关的去噪方法。我们的实现在第 4 节中进行了描述。

3 Dataset
尽管低光增强问题已经研究了几十年,但据我们所知,当前公开的数据集没有提供在真实场景中捕获的配对低光/正常光图像。一些低光增强作品使用高动态范围(HDR)数据集作为替代方案,例如 MEF 数据集 [18]。然而,这些数据集规模较小,包含的场景也有限。因此,它们不能用于训练深度网络。为了使从大规模数据集中学习低光增强网络变得容易,我们构建了一个由两类组成的新网络:真实摄影对和来自原始图像的合成对。第一个捕获了真实案例中的退化特征和属性。第二个在数据增强、场景和对象多样化方面发挥作用。
3.1 Dataset Captured in Real Scenes
我们的数据集名为低光配对数据集 (LOL),包含 500 个低光/正常光图像对。据我们所知,LOL 是第一个包含从真实场景中获取的用于低光增强的图像对的数据集。
大多数低光图像是通过改变曝光时间和ISO来收集的,而相机的其他配置是固定的。我们从各种场景捕捉图像,例如房屋、校园、俱乐部、街道。图 3 显示了场景的子集。
由于相机抖动、物体移动和亮度变化可能会导致图像对之间的错位,受[1]的启发,我们使用三步方法来消除数据集中图像对之间的这种错位。实施细节可以在补充文件中找到。这些原始图像被调整为 400×600 大小并转换为便携式网络图形格式。该数据集将公开提供。
3.2 Synthetic Image Pairs from Raw Images
为了使合成图像符合真实暗摄影的特性,我们分析了低光图像的光照分布。我们从公共 MEF [18]、NPE [23]、LIME [9]、DICM [13]、VV 1 和 Fusion [3] 数据集中收集了 270 张低光图像,将图像转换为 YCbCr 通道并计算Y 通道。我们还从 RAISE [4] 中收集 1000 张原始图像作为正常光图像,并计算 YCbCr 中 Y 通道的直方图。图 4 显示了结果。
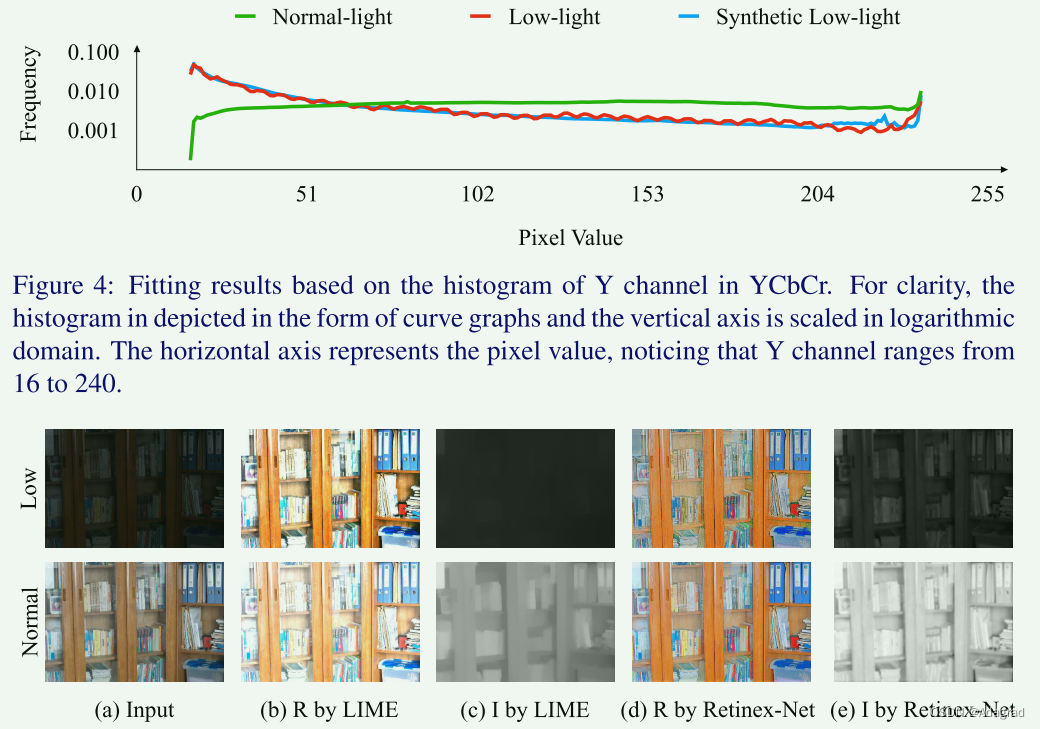
Figure 5: 在 LOL 数据集中的 Bookshelf 上使用我们的 Decom-Net 和 LIME 进行分解的结果。在我们的结果中,除了真实场景中出现的暗区噪声放大之外,低光图像的反射率与正常光图像的反射率相似。
原始图像比转换后的结果包含更多信息。在对原始图像进行操作时,用于生成像素值的所有计算都是在基础数据上一步执行的,从而使结果更加准确。 RAISE [4] 中的 1000 个原始图像用于合成低光图像。使用Adobe Lightroom提供的接口,尝试不同的参数,使Y通道的直方图符合弱光图像的结果。最终参数配置可以在补充材料中找到。如图4所示,合成图像的照度分布与低光图像的照度分布相匹配。最后,我们将这些原始图像的大小调整为 400×600,并将其转换为便携式网络图形格式。
4 Experiments
4.1 Implementation Details
我们在第 2 节中提到的 LOL 数据集。具有 500 个图像对的图 3 被分为 485 对用于训练,另外 15 对用于评估。因此,该网络接受了 485 个真实图像对以及 1000 个合成图像对的训练。整个网络是轻量级的,因为我们凭经验发现它已经足以满足我们的目的。 Decom-Net 采用 5 个卷积层,在 2 个没有 ReLU 的卷积层之间有一个 ReLU 激活。增强网络由 3 个下采样块和 3 个上采样块组成。我们首先训练 Decom-Net 和Enhance-Net,然后使用带有反向传播的随机梯度下降(SGD)对网络进行端到端微调。批量大小设置为 16,补丁大小设置为 96×96。 λir、λis和λg分别设置为0.001、0.1和10。当 时,λi j 设置为 0.001,当 i = j 时,λi j 设置为 1。
4.2 Decomposition Results
在图 5 中,我们展示了 LOL 数据集评估集中的低/正常光图像对,以及由 Decom-Net 和 LIME 分解的反射率和照明图。补充文件中提供了更多示例。结果表明,我们的 Decom-Net 可以在文本区域和平滑区域中在完全不同的光照条件下从一对图像中提取底层一致的反射率。除了真实场景中暗区噪声被放大之外,低光图像的反射率与正常光图像的反射率相似。另一方面,照明贴图描绘了图像上的亮度和阴影。与我们的结果相比,LIME 在反射率上留下了很多照明信息(参见架子上的阴影)。
4.3 Evaluation
我们在公共 LIME [9]、MEF [18] 和 DICM [13] 数据集的真实场景图像上评估我们的方法。 LIME 包含 10 个测试图像。 MEF 包含 17 个具有多个曝光级别的图像序列。 DICM 使用商用数码相机收集了 69 张图像。我们将我们的 Retinex-Net 与四种最先进的方法进行比较,包括基于去雾的方法 (DeHz) [5]、自然保留增强算法 (NPE) [23]、同时反射率和照明估计算法 (SRIE) [8],以及基于照明图估计(LIME)[9]。

图 6 显示了三幅自然图像的视觉比较。更多结果可以在补充文件中找到。如每个红色矩形所示,我们的方法足够亮化埋藏在暗亮度中的物体而不会过度曝光,这得益于基于学习的图像分解方法和多尺度定制的照明图。与 LIME 相比,我们的结果并没有部分过度曝光(参见《静物画》中的叶子和《房间》中外部的叶子)。与 DeHz 相比,这些物体没有暗边缘,DeHz 受益于加权TV损失项(参见街道上房屋的边缘)。
4.4 Joint Low-Light Enhancement and Denoising
考虑到综合性能,Retinex-Net中采用BM3D[3]作为去噪操作。由于噪声在反射率上放大不均匀,我们使用照明相对策略(参见补充材料)。我们将我们的联合去噪 Retinex-Net 与两种方法进行比较,一种是带有去噪后处理的 LIME,另一种是 JED [22],这是一种最近的联合低光增强和去噪方法。如图 7 所示,Retinex-Net 更好地保留了细节,而 LIME 和 JED 则模糊了边缘。
5 Conclusion
本文提出了一种深度 Retinex 分解方法,该方法可以学习以数据驱动的方式将观察到的图像分解为反射率和光照,而无需分解反射率和光照的基本事实。随后介绍了照明上的光增强和反射率上的去噪操作。分解网络和弱光增强网络是端到端训练的。实验结果表明,我们的方法产生了视觉上令人愉悦的增强结果以及图像分解的良好表示。
代码解读
DecomNet
class DecomNet(nn.Module):
def __init__(self, channel=64, kernel_size=3):
super(DecomNet, self).__init__()
# Shallow feature extraction
self.net1_conv0 = nn.Conv2d(4, channel, kernel_size * 3,
padding=4, padding_mode='replicate')
# Activated layers!
self.net1_convs = nn.Sequential(nn.Conv2d(channel, channel, kernel_size,
padding=1, padding_mode='replicate'),
nn.ReLU(),
nn.Conv2d(channel, channel, kernel_size,
padding=1, padding_mode='replicate'),
nn.ReLU(),
nn.Conv2d(channel, channel, kernel_size,
padding=1, padding_mode='replicate'),
nn.ReLU(),
nn.Conv2d(channel, channel, kernel_size,
padding=1, padding_mode='replicate'),
nn.ReLU(),
nn.Conv2d(channel, channel, kernel_size,
padding=1, padding_mode='replicate'),
nn.ReLU())
# Final recon layer
self.net1_recon = nn.Conv2d(channel, 4, kernel_size,
padding=1, padding_mode='replicate')
def forward(self, input_im):
input_max= torch.max(input_im, dim=1, keepdim=True)[0]
input_img= torch.cat((input_max, input_im), dim=1)
feats0 = self.net1_conv0(input_img)
featss = self.net1_convs(feats0)
outs = self.net1_recon(featss)
R = torch.sigmoid(outs[:, 0:3, :, :])
L = torch.sigmoid(outs[:, 3:4, :, :])
return R, L输入是原图加上单通道的max图,共通道个数为4,先后conv、relu,最后sigmoid,得到R、L,R为反射面,L为光照面。
RelightNet
class RelightNet(nn.Module):
def __init__(self, channel=64, kernel_size=3):
super(RelightNet, self).__init__()
self.relu = nn.ReLU()
self.net2_conv0_1 = nn.Conv2d(4, channel, kernel_size,
padding=1, padding_mode='replicate')
self.net2_conv1_1 = nn.Conv2d(channel, channel, kernel_size, stride=2,
padding=1, padding_mode='replicate')
self.net2_conv1_2 = nn.Conv2d(channel, channel, kernel_size, stride=2,
padding=1, padding_mode='replicate')
self.net2_conv1_3 = nn.Conv2d(channel, channel, kernel_size, stride=2,
padding=1, padding_mode='replicate')
self.net2_deconv1_1= nn.Conv2d(channel*2, channel, kernel_size,
padding=1, padding_mode='replicate')
self.net2_deconv1_2= nn.Conv2d(channel*2, channel, kernel_size,
padding=1, padding_mode='replicate')
self.net2_deconv1_3= nn.Conv2d(channel*2, channel, kernel_size,
padding=1, padding_mode='replicate')
self.net2_fusion = nn.Conv2d(channel*3, channel, kernel_size=1,
padding=1, padding_mode='replicate')
self.net2_output = nn.Conv2d(channel, 1, kernel_size=3, padding=0)
def forward(self, input_L, input_R):
input_img = torch.cat((input_R, input_L), dim=1)
out0 = self.net2_conv0_1(input_img)
out1 = self.relu(self.net2_conv1_1(out0))
out2 = self.relu(self.net2_conv1_2(out1))
out3 = self.relu(self.net2_conv1_3(out2))
out3_up = F.interpolate(out3, size=(out2.size()[2], out2.size()[3]))
deconv1 = self.relu(self.net2_deconv1_1(torch.cat((out3_up, out2), dim=1)))
deconv1_up= F.interpolate(deconv1, size=(out1.size()[2], out1.size()[3]))
deconv2 = self.relu(self.net2_deconv1_2(torch.cat((deconv1_up, out1), dim=1)))
deconv2_up= F.interpolate(deconv2, size=(out0.size()[2], out0.size()[3]))
deconv3 = self.relu(self.net2_deconv1_3(torch.cat((deconv2_up, out0), dim=1)))
deconv1_rs= F.interpolate(deconv1, size=(input_R.size()[2], input_R.size()[3]))
deconv2_rs= F.interpolate(deconv2, size=(input_R.size()[2], input_R.size()[3]))
feats_all = torch.cat((deconv1_rs, deconv2_rs, deconv3), dim=1)
feats_fus = self.net2_fusion(feats_all)
output = self.net2_output(feats_fus)
return output整体结构为UNet型,输入是R和L进行cat得到,下采样为conv,维度保持不变,上采样为F.interpolate插值,每次插值后cat跳连下采样conv结果,接一个conv,用于降维度,最后conv得到一维L,表示光照调整后结果。
RetinexNet
class RetinexNet(nn.Module):
def __init__(self):
super(RetinexNet, self).__init__()
self.DecomNet = DecomNet()
self.RelightNet= RelightNet()
def forward(self, input_low, input_high):
# Forward DecompNet
input_low = Variable(torch.FloatTensor(torch.from_numpy(input_low))).cuda()
input_high= Variable(torch.FloatTensor(torch.from_numpy(input_high))).cuda()
R_low, I_low = self.DecomNet(input_low)
R_high, I_high = self.DecomNet(input_high)
# Forward RelightNet
I_delta = self.RelightNet(I_low, R_low)
# Other variables
I_low_3 = torch.cat((I_low, I_low, I_low), dim=1)
I_high_3 = torch.cat((I_high, I_high, I_high), dim=1)
I_delta_3= torch.cat((I_delta, I_delta, I_delta), dim=1)
# Compute losses
self.recon_loss_low = F.l1_loss(R_low * I_low_3, input_low)
self.recon_loss_high = F.l1_loss(R_high * I_high_3, input_high)
self.recon_loss_mutal_low = F.l1_loss(R_high * I_low_3, input_low)
self.recon_loss_mutal_high = F.l1_loss(R_low * I_high_3, input_high)
self.equal_R_loss = F.l1_loss(R_low, R_high.detach())
self.relight_loss = F.l1_loss(R_low * I_delta_3, input_high)
self.Ismooth_loss_low = self.smooth(I_low, R_low)
self.Ismooth_loss_high = self.smooth(I_high, R_high)
self.Ismooth_loss_delta = self.smooth(I_delta, R_low)
self.loss_Decom = self.recon_loss_low + \
self.recon_loss_high + \
0.001 * self.recon_loss_mutal_low + \
0.001 * self.recon_loss_mutal_high + \
0.1 * self.Ismooth_loss_low + \
0.1 * self.Ismooth_loss_high + \
0.01 * self.equal_R_loss
self.loss_Relight = self.relight_loss + \
3 * self.Ismooth_loss_delta
self.output_R_low = R_low.detach().cpu()
self.output_I_low = I_low_3.detach().cpu()
self.output_I_delta = I_delta_3.detach().cpu()
self.output_S = R_low.detach().cpu() * I_delta_3.detach().cpu()主要讲解loss,
low和high分解的R应该保持一致
self.recon_loss_low = F.l1_loss(R_low * I_low_3, input_low)
self.recon_loss_high = F.l1_loss(R_high * I_high_3, input_high)
self.recon_loss_mutal_low = F.l1_loss(R_high * I_low_3, input_low)
self.recon_loss_mutal_high = F.l1_loss(R_low * I_high_3, input_high)
self.equal_R_loss = F.l1_loss(R_low, R_high.detach())
self.relight_loss = F.l1_loss(R_low * I_delta_3, input_high)
low和high分解的I应该光滑
self.Ismooth_loss_low = self.smooth(I_low, R_low)
self.Ismooth_loss_high = self.smooth(I_high, R_high)
self.Ismooth_loss_delta = self.smooth(I_delta, R_low)
需要注意的是该网络训练过程并非端到端,Decom和Relight分开独立训练
smooth
def gradient(self, input_tensor, direction):
self.smooth_kernel_x = torch.FloatTensor([[0, 0], [-1, 1]]).view((1, 1, 2, 2)).cuda()
self.smooth_kernel_y = torch.transpose(self.smooth_kernel_x, 2, 3)
if direction == "x":
kernel = self.smooth_kernel_x
elif direction == "y":
kernel = self.smooth_kernel_y
grad_out = torch.abs(F.conv2d(input_tensor, kernel,
stride=1, padding=1))
return grad_out
def ave_gradient(self, input_tensor, direction):
return F.avg_pool2d(self.gradient(input_tensor, direction),
kernel_size=3, stride=1, padding=1)
def smooth(self, input_I, input_R):
input_R = 0.299*input_R[:, 0, :, :] + 0.587*input_R[:, 1, :, :] + 0.114*input_R[:, 2, :, :]
input_R = torch.unsqueeze(input_R, dim=1)
return torch.mean(self.gradient(input_I, "x") * torch.exp(-10 * self.ave_gradient(input_R, "x")) +
self.gradient(input_I, "y") * torch.exp(-10 * self.ave_gradient(input_R, "y")))input_R先转灰度图,input_I计算梯度map,区分x和y方向,梯度权重和input_R梯度相关,对input_R先进行求梯度,然后做3x3均值,exp表示input_R梯度越小,权重越大,这样input_I小梯度越平滑,反之越不光滑,即文中的光照结构感知loss,avg_pool2d可能是为了避免噪声影响?

















 81
81

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









