







例:
首先新建表,插入值:
DROP TABLE IF EXISTS table_score_one;
CREATE TABLE table_score_one (
id INT (10) NOT NULL PRIMARY KEY auto_increment,
student_no VARCHAR (10) NOT NULL,
student_name VARCHAR (10) NOT NULL,
class_no VARCHAR (10) NOT NULL,
class_name VARCHAR (10) NOT NULL,
score INT (10) NOT NULL
) DEFAULT CHARSET='utf8';
INSERT INTO `table_score_one` VALUES ('1', '201601', '张三', '0001', '数学', '98');
INSERT INTO `table_score_one` VALUES ('2', '201601', '张三', '0002', '语文', '66');
INSERT INTO `table_score_one` VALUES ('3', '201602', '李四', '0001', '数学', '60');
INSERT INTO `table_score_one` VALUES ('4', '201602', '李四', '0003', '英语', '78');
INSERT INTO `table_score_one` VALUES ('5', '201603', '王五', '0001', '数学', '99');
INSERT INTO `table_score_one` VALUES ('6', '201603', '王五', '0002', '语文', '99');
INSERT INTO `table_score_one` VALUES ('7', '201603', '王五', '0003', '英语', '98');其中auto_increment表示按顺序生成值。默认从1开始。
表如图:
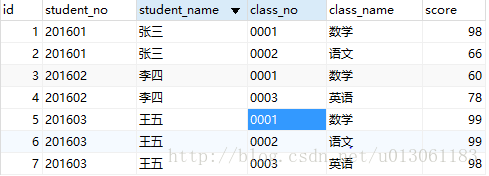
第二步更新值:
update table_score_one set class_name ='数学' , class_no = '0001' where id = 6;如图:
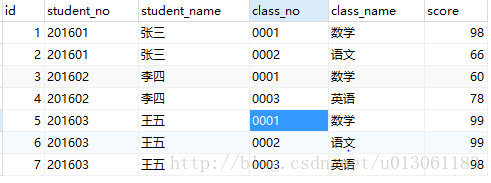
第三步:
把除了id不一样的其余都一样的数据删除。
delete table_test_one where id not in (select min(id) from table_test_one group by student_no, student_name, class_no, class_name, score);上面的语句意思是:先通过根据student_no, student_name, class_no, class_name, score一样的进行分组,查出每组最小的id,这样再把不在查询出的id结果中id删除。
但是这样会有一个错误:
You can’t specify target table ‘table_score_one’ for update in FROM clause
意思是:你不能在同一个sql语句中先查询某些值,在修改这个表。
解决办法:select的结果再通过一个中间表select多一次。
DELETE
FROM
table_score_one
WHERE
id NOT IN (
SELECT
a.min_id
FROM
(
SELECT
min(id) AS min_id
FROM
table_score_one
GROUP BY
student_no,
class_no,
class_name,
score
) a
);要给查出的结果设立别名。
参考:http://blog.csdn.net/u013142781/article/details/50836476















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









