







Centos7+Hadoop3.1.1集群搭建,使用了三台虚拟机。
第一步:前面的虚拟机之间的SSH免密码可以参考下面的博主,写的很好。
https://blog.csdn.net/qq_34646817/article/details/81177155。
我在配置完后,遇到一个很郁闷的问题,centOS7_1登陆另外两台虚拟机需要密码,然而另外两台没有啥问题,一模一样的操作。最终使用ssh-copy-id -i id_rsa.pub "-p 22 root@hostname"把另外两个的公钥弄过来才好,不知道哪里错误。。
jdk的安装可以参考https://www.cnblogs.com/sxdcgaq8080/p/7492426.html。
第一步:centOS7_1虚拟机中,mkdri -p 指令在/opt/下新建了hadoop文件夹,将下载好的Hadoop3.1.1的压缩包mv指令到这个文件夹下面进行解压。- -因为我已经完成了这些操作,直接上图,centos的指令可以多敲一下练习,敲着敲着就记住了!
第二步:在centOS7_1中执行下面指令
mkdir /root/hadoop
mkdir /root/hadoop/tmp
mkdir /root/hadoop/var
mkdir /root/hadoop/dfs
mkdir /root/hadoop/dfs/name
mkdir /root/hadoop/dfs/data
进入到/opt/hadoop/hadoop-3.1.1/etc/hadoop/目录下,修改配置文件
1.首先是vim core-site.xml中把configuration修改如下:记得把hadoop1修改为自己设置hostname.
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop1:9000</value>
</property>
</configuration>2.vim hadoop-env.sh,增加自己的jdk路径如下:
3.vim hdfs-site.xml,修改如下:
<configuration>
<property>
<name>dfs.namenode.http-address</name>
<!-- hserver1 修改为你的机器名或者ip -->
<value>hadoop1:50070</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/root/hadoop/dfs/name</value>
<description>Path on the local filesystem where theNameNode stores the namespace and transactions logs persistently.</description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/root/hadoop/dfs/data</value>
<description>Comma separated list of paths on the localfilesystem of a DataNode where it should store its blocks.</description>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
<description>need not permissions</description>
</property>
</configuration>4.修改vim mapred-site.xml,修改如下:
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>hadoop1:49001</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>/root/hadoop/var</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>5.vim workers,可以添加hadoop1,也可以不添加。看自己需要。
hadoop2
hadoop36.vim yarn-site.xml,修改如下
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop1</value>
</property>
<property>
<description>The address of the applications manager interface in the RM.</description>
<name>yarn.resourcemanager.address</name>
<value>${yarn.resourcemanager.hostname}:8032</value>
</property>
<property>
<description>The address of the scheduler interface.</description>
<name>yarn.resourcemanager.scheduler.address</name>
<value>${yarn.resourcemanager.hostname}:8030</value>
</property>
<property>
<description>The http address of the RM web application.</description>
<name>yarn.resourcemanager.webapp.address</name>
<value>${yarn.resourcemanager.hostname}:8088</value>
</property>
<property>
<description>The https adddress of the RM web application.</description>
<name>yarn.resourcemanager.webapp.https.address</name>
<value>${yarn.resourcemanager.hostname}:8090</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>${yarn.resourcemanager.hostname}:8031</value>
</property>
<property>
<description>The address of the RM admin interface.</description>
<name>yarn.resourcemanager.admin.address</name>
<value>${yarn.resourcemanager.hostname}:8033</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
<discription>每个节点可用内存,单位MB,默认8182MB</discription>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
第三步:将centOS7_1中配置好的文件传给其他两台虚拟机
指令如下scp -r root@hadoop1:/opt/hadoop/hadoop-3.1.1/(这里是源文件的地址) /opt/hadoop/hadoop-3.1.1/(需要复制的虚拟的地址)。
第四部:启动Hadoop
1.转移到cd /opt/hadoop/hadoop-3.1.1/bin,执行./hadoop namenode -format。有下面红框内容就表示成功。
2.cd /opt/hadoop/hadoop-3.1.1/sbin中,执行./start-all.sh,我在这里报错,忘记截图了,解决方法就是
1)在vim start-dfs.sh和vim stop-dfs.sh,在位置在头部空白处插入:
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
2)vim start-yarn.sh 和vim stop-yarn.sh 。位置同上,插入代码
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root3)vim start-all.sh和 vim stop-all.sh,位置同上,插入代码:
TANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root4)执行./start-all.sh
可以输入jps指令查看集群是否启动成功,如nameNode(即我虚拟机当中的CentOS7_1)和DataNode(即我虚拟机当中的CentOS7_2和CentOS7_3)。

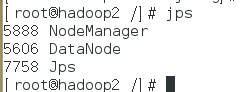
最后的效果图,注意红框里面的,如果没有显示对应的数字,说明配置有问题!!!。
ip地址:50070

ip地址:8088端口

最后附上一下参考:https://blog.csdn.net/weixin_42142630/article/details/81837131
https://blog.csdn.net/secyb/article/details/80170804 https://blog.csdn.net/iflytop/article/details/82413694














 693
693











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









