







聚焦以下两点:
① 抽样分布的基本概念
② 举例说明总体数据是正态和非正态时的抽样分布
1. 抽样分布
先说什么是统计量。
1.1统计量:根据样本观测值所得的不含有未知参数的函数。
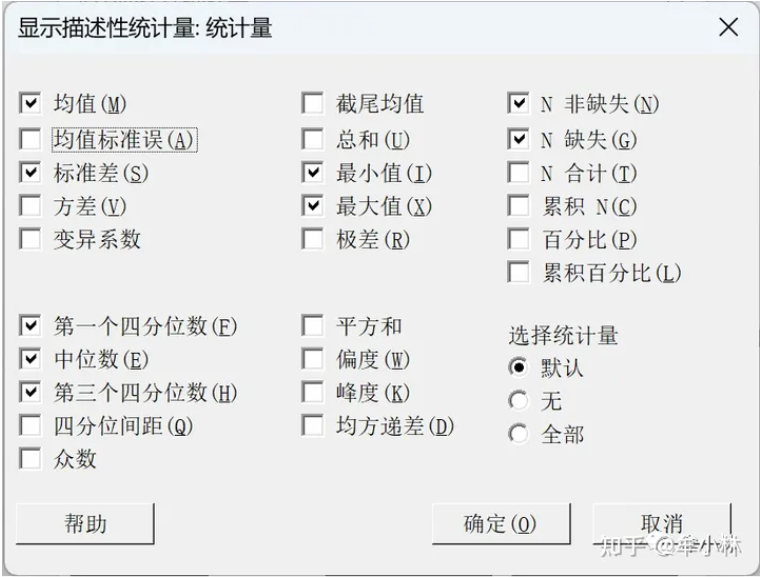
Minitab中,列出了25个统计量,常用的有:均值、均值标准误、标准差、方差、中位数、最大值、最小值、极差等。
1.2抽样分布
统计量的概率分布,称为抽样分布。
常用抽样分布有:正态分布、卡方分布、 t分布等。
2.均值抽样分布
均值的抽样分布是最常见的。
接下来,将举例说明总体数据是正态和非正态的抽样分布,并演示它们如何随着样本量的变化而变化。
2.1总体正态时的均值抽样分布
还是研究长沙男性身高的平均值。先随机测量20位男性的身高,得到其平均值167.8厘米。都知道,如果再随机测量20位男性的身高,其平均值大概率不是167.8厘米,会另外一个均值,如168.3厘米、172.0厘米...
那么,到底要怎么办才能得到相对准确的总体均值呢?一个思路是:找到总体的均值抽样分布。
接下来,随机收集30组样本,每个样本包含20位男性的身高数据。如下图:
注意:为方便展示,1-21组的数据隐藏。
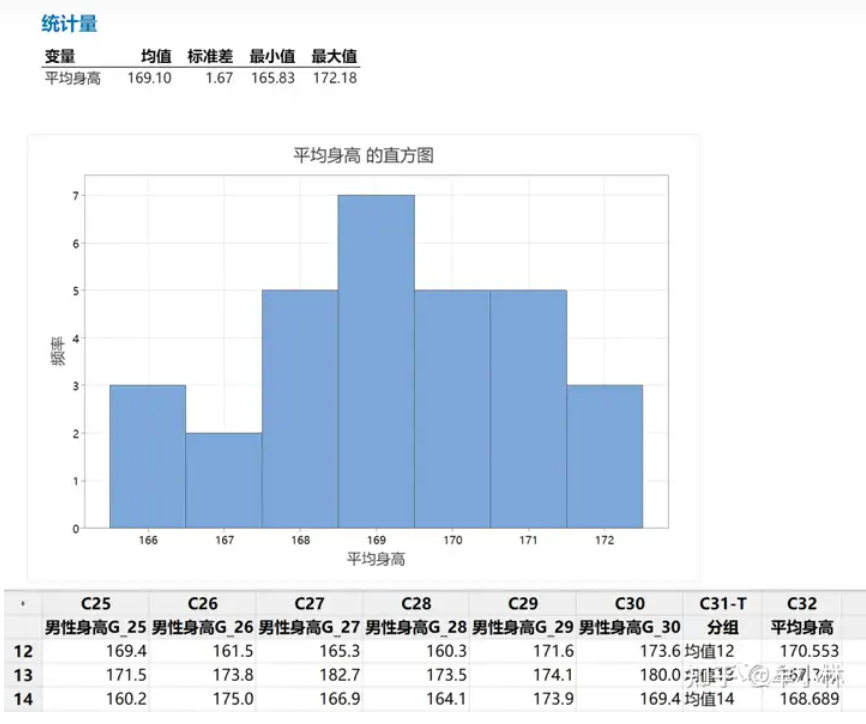
然后,求出每个样本的均值,共得到30个均值。如下。
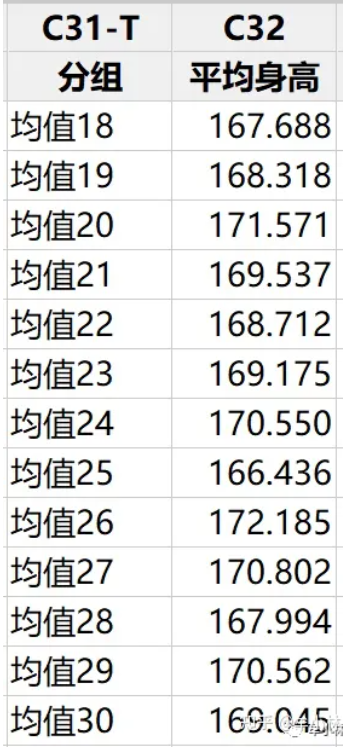
注:第1-17组样本的样本均值隐藏
将这30个样本均值用直方图展示出来。如下图。可以发现,我们第一次测量的平均值身高为167.8厘米,位于直方图靠左的位置。
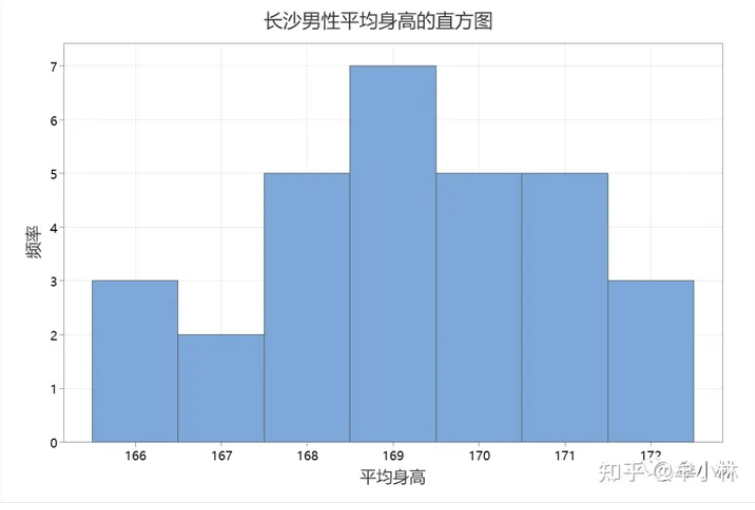
从上图可以看到,尽管抽取的样本都是来自同一个总体,但是每个样本的身高均值是变化的。但,基本处于[165.83,172.18]的范围内。如果我们发现样本的均值不在这个范围,这是不寻常的。
长沙男性身高的总体参数,是不知道,只能去估计。但,在Minitab中生成模拟数据的时候,其实是假设总体服从正态分布N(169.10,7.27^2)的。我们可以先假设不知道这个数据,接下来可以用样本数据去推断出来。
当总体服从正态分布时,其抽样分布也将服从正态分布。并且,其均值和标准差有如下关系。
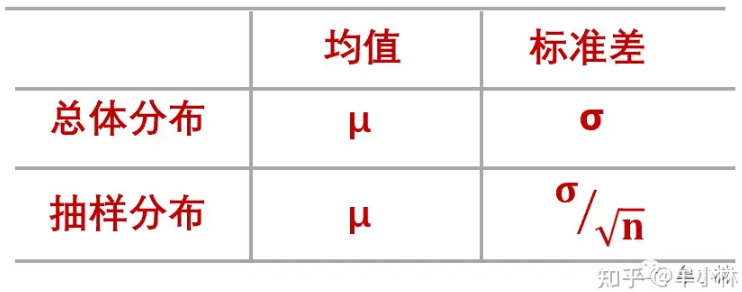
其中:μ和σ是总体的均值和标准差。n是每次取样的大小。
对于上表,需要注意的是,
① 总体分布和抽样分布的中心是一致的。
② 对于标准差而言,抽样分布的标准差除了与总体标准差有关外,还与每次取样的样本数量n有关,其值是总体标准差的1/√n倍。
也就是说,抽样分布不是唯一的,具体取决于样本大小。样本数量一变,抽样分布就变了。
再回到上面身高的例子。坡子街男性身高服从正态分布N(169.10,7.27^2),这是事先不知道的。当使用样本数量N=20去抽样时,得到均值的抽样分布以μ=169.10为中心,均值标准误为1.67。根据这个标准误可以推断出总体的标准差为:1.67*√20=7.46。与总体的标准差7.27,比较接近了。
增大样本量,会怎么样?
接下来,同样在总体的正态分布N(169.10,7.27^2)下,取50万个样本,每个样本大小为20。
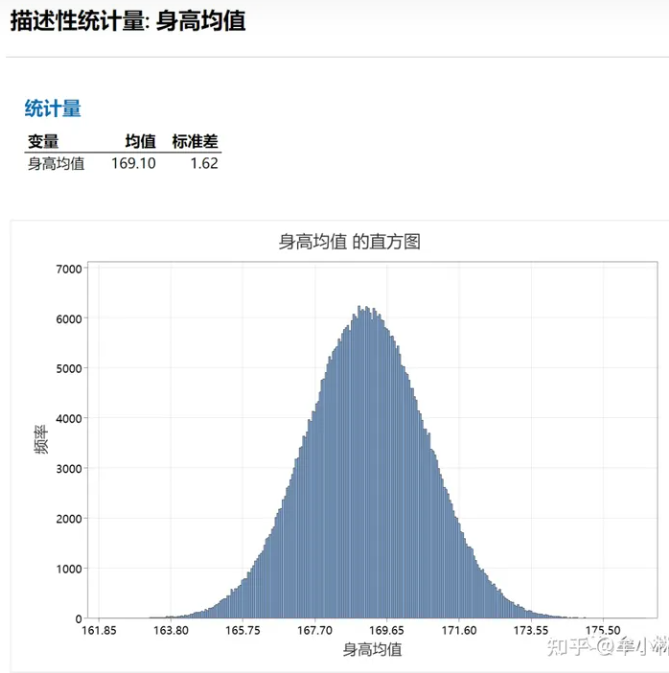
然后,再计算出抽样分布的均值和标准误差,那么均值应该是接近理论值169.10,均值标准误差接近其理论值1.625=7.27/√20。
求出「身高均值」的均值和均值标准误分别为:169.1,1.62。与理论值几乎一致。仿真结果如下:
将抽次抽样的数量由20调整到80,会怎么样
抽样分布的均值标准误是总体分布标准差的1⁄√n倍。这说明每次抽样的数量增加,抽样分布的标准误会减小,从图形上看,会更紧密地向均值中心聚集。
再次仿真下。同样是50万个样本,但每个样本的数量不是20个人,而是每组80个人。按照理论值计算,此时均值标准误会由1.62减半至0.81。看看是不是这样。
仿真结果如下:标准差为0.814与0.81很接近。
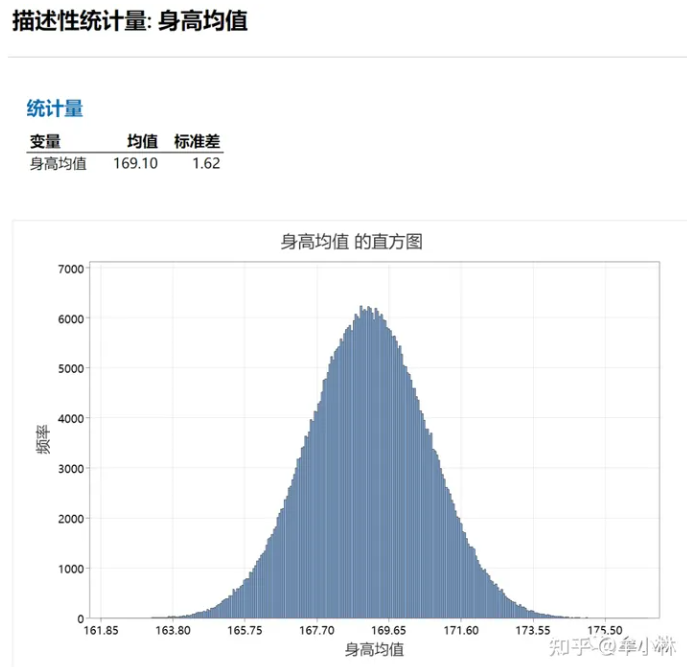
可以发现:
① 若要标准误减半,每次抽样的样本数量要增加4倍。
② 随着样本数量的增加,样本均值会越来越靠近总体均值。也就是说,更大的样本量会产生更精确的估计。
2.2总体非正态时的均值抽样分布
上面演示的,总体都服从正态分布,抽样分布也服从正态分布。如果总体不是正态分布,而是偏态的,那么其抽样分布会是什么样?
假设身高总体服从自由度为2的卡方分布。自由度小的时候,其形状是右偏的。在Minitab中,生成10万个自由度为2的卡方分布数据,其直方图如下所示。
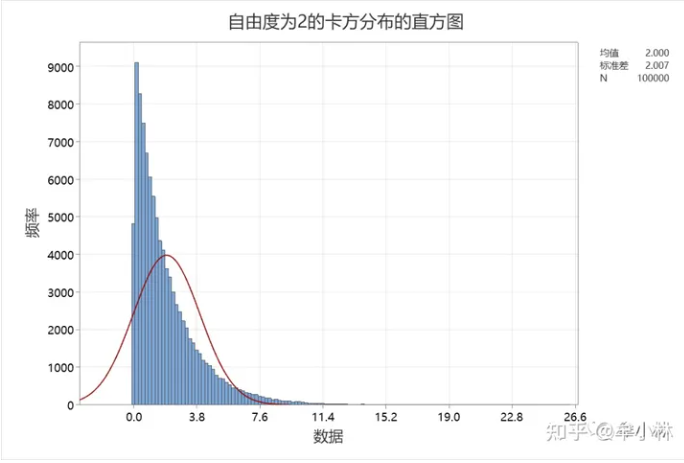
接下来,从Df=2的卡方分布中,随机抽取50万个样本,样本大小分别为5和30。看看会出现什么结果。
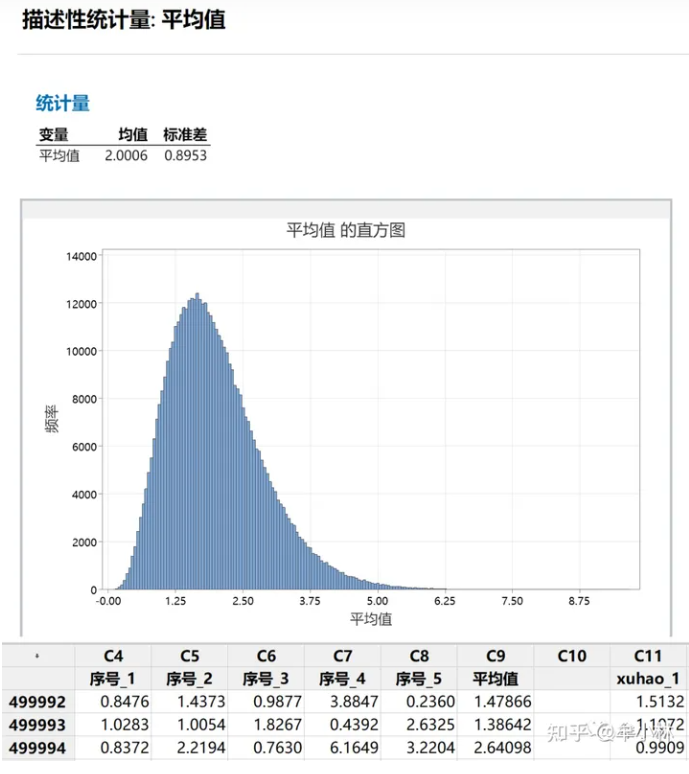
① 样本大小为5时
可以发现:均值为2.0006。这是因为:卡方分布的均值就等于自由度。
均值标准误=0.8953。对比总体分布,现在样本大小为5的抽样分布比较接近正态分布了。
② 当样本大小为30时
均值是2.0001。
但均值标准误=0.3656,比样本大小为5的均值标准误「0.8953」,小了不少。再看抽样分布,可以发现形态非常接近正态分布了。
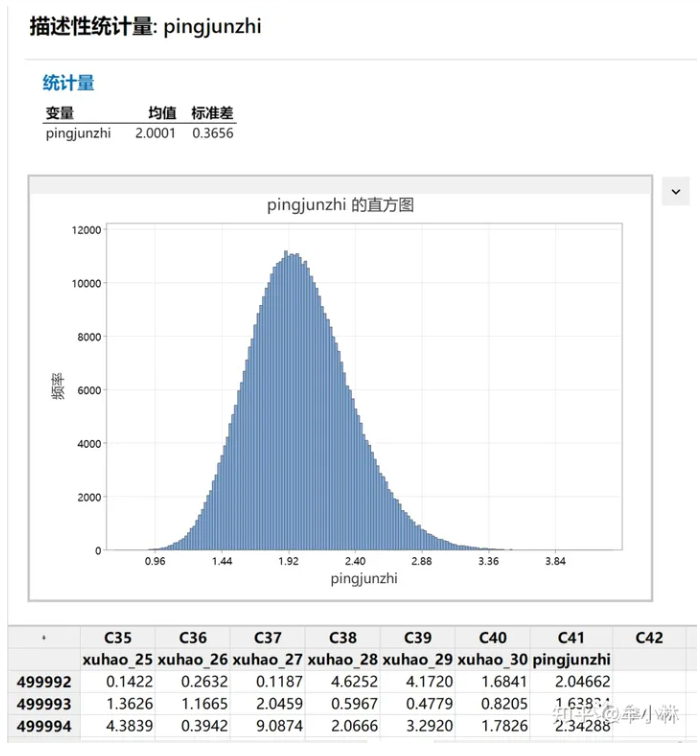
卡方方差=2倍自由度。在这个案例中,方差等于4,标准差就是2。2/√30=0.3651,这是理论值。那么,实际模拟的值是0.3556,和理论值是非常接近的。
可以发现,对于非常正态数据的抽样分布,随着每次抽取样本数量的增加,抽样分布是收敛于正态分布N(μ,σ⁄√n)。对于这个案例,就是收敛于N(2,2/√n)。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









