







Python 编码问题
python3中,所有的字符串在内存中均是unicode保存
t = 'abc'
上述语句在计算机内部的执行顺序是这样的
- 在内存中创建一个字符串 'abc'
- 在程序栈寄存器中创建一个变量t
- 使得寄存器中的变量t指向'abc' (也就是把字符串'abc'的地址赋给t)
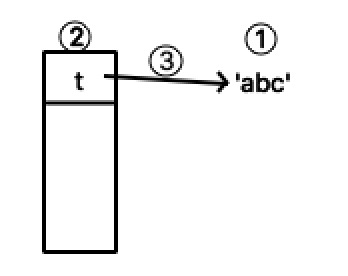
虽然内存中是unicode保存,但是输出到文件中就是utf-8或者GBK等格式了,根据文件的编码类型不同而不同
字符与unicode码的相互转换
字符转十进制unicode码
>>> ord("中") 20013十进制unicode码转字符
>>> chr(20013) '中'
str类型字符串与bytes类型字符串的相互转换
需要注意的是:
1. str类型的字符串在内存中是以unicode形式存在的
2. bytes类型的字符串可以是任意编码,表示形式是在字符串前面加b。例如 b'ABC'即为bytes类型的字符串
转换方法:
str转bytes>>> '中文'.encode('utf-8') b'\xe4\xb8\xad\xe6\x96\x87' >>> '中文'.encode('GBK') b'\xd6\xd0\xce\xc4' >>> '中文'.encode('ascii') --------------------------------------------------------------------------- UnicodeEncodeError Traceback (most recent call last) <ipython-input-12-b318511b2a75> in <module>() ----> 1 '中文'.encode('ascii') UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
第三条语句会报错,因为ascii编码无法解析中文
bytes转str>>>b'\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8') '中文' >>>b'\xd6\xd0\xce\xc4'.decode('GBK') '中文'















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









