







本文是基于吴恩达老师的《深度学习》第四课第一周习题所做,如果本文在某些知识点上描述得不够透彻的可以参见相关章节的具体讲解,同时极力推荐各位有志从事计算机视觉的朋友观看一下吴恩达老师的《深度学习》课程。
1.卷积神经网络构成
总的来说,卷积神经网络与神经网络的区别是增加了若干个卷积层,而卷积层又可细分为卷积(CONV)和池化(POOL)两部分操作(这两个重要概念稍后会简单的介绍,如果对CNN的基本概念不是特别了解的同学可以学习达叔的《卷积神经网络》课程);然后是全连接层(FC),可与神经网络的隐藏层相对应;最后是softmax层预测输出值y_hat。下图为CNN的结构图。

虽然深度学习框架会让这种复杂的算法实现起来变得容易,但只有自己实现一遍才能更透彻的理解上图中涉及到的计算操作。因此,本文先按照上图卷积神经网络的运算步骤,通过编写函数一步一步来实现CNN模型,最后会使用TensorFlow框架搭建CNN来进行图片分类。
2.第三方库
以下是在编码实现CNN中用到的第三方库。
import numpy as np
import h5py
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = (5.0,4.0)
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
np.random.seed(1)3.前向传播过程
卷积神经网络的前向传播过程包括:填充(padding)、卷积操作(conv)、激活函数(Relu)、池化(pooling)、全连接(FC)、softmax分类,其中激活、全连接、softmax与深层神经网络中的计算方法一致,本文不再赘述,如不了解可参见本人上一篇文章《使用tensorflow搭建深层神经网络》。
3.1 填充(padding)
对输入图像进行卷积操作时,我们会发现一个问题:角落或边缘的像素点被使用的次数相对较少。这样一来在图片识别中会弱化边缘信息。因此我们使用padding操作,在图像原始数据周围填充p层数据,如下图。当填充的数据为0时,我们称之为Zero-padding。除了,能够保留更多有效信息之外,padding操作还可以保证在使用卷积计算前后卷的高和宽不变化。

padding操作需要使用到numpy中的一个函数:np.pad()。假设我们要填充一个数组a,维度为(5,5,5,5,5),如果我们想要第二个维度的pad=1,第4个维度的pad=3,其余pad=0,那么我们如下使用np.pad()
a = np.pad(a, ((0,0),(1,1),(0,0),(3,3),(0,0)), 'constant', constant_values = (...,...))def zero_pad(X, pad):
X_pad = np.pad(X, ((0,0),(pad,pad),(pad,pad),(0,0)), 'constant')
return X_padx = np.random.randn(4,3,3,2)
x_pad = zero_pad(x, 2)
print('x.shape=',x.shape)
print('x_pad.shape=',x_pad.shape)
print('x[1,1]=',x[1,1])
print('x_pad[1,1]=',x_pad[1,1])x.shape= (4, 3, 3, 2)
x_pad.shape= (4, 7, 7, 2)
x[1,1]= [[ 0.90085595 -0.68372786]
[-0.12289023 -0.93576943]
[-0.26788808 0.53035547]]
x_pad[1,1]= [[0. 0.]
[0. 0.]
[0. 0.]
[0. 0.]
[0. 0.]
[0. 0.]
[0. 0.]]fig, axarr = plt.subplots(1,2)
axarr[0].set_title('x')
axarr[0].imshow(x[0,:,:,0])
axarr[1].set_title('x_pad')
axarr[1].imshow(x_pad[0,:,:,0])
plt.show()
3.2单步卷积(single step of convolution)
在卷积操作中,我们首先需要明确的一个概念是过滤器(核),它是一个通道数与输入图像相同,但高度和宽度为较小奇数(通常为1,3,5,7等,我们可将这个超参数用f表示)的多维数组(f, f, n_c)。在下面动图示例中过滤器是(3,3)的数组np.array([[1,0,1],[0,1,0],[1,0,1]]),其中这9个数字可以事先设定,也可以通过反向传播来学习。设定好过滤器后还需设置步长stride(s),步长即每次移动的像素数,在动图示例中s=1,具体的卷积过程见下图,最后得到一个卷积后的特征矩阵。
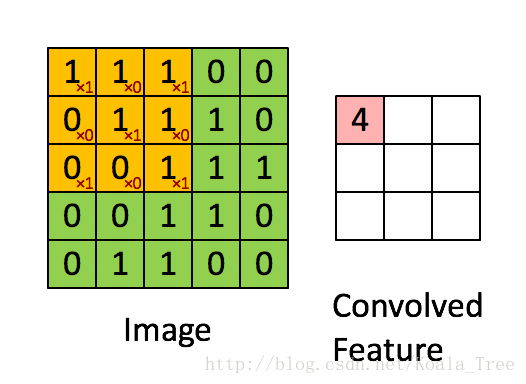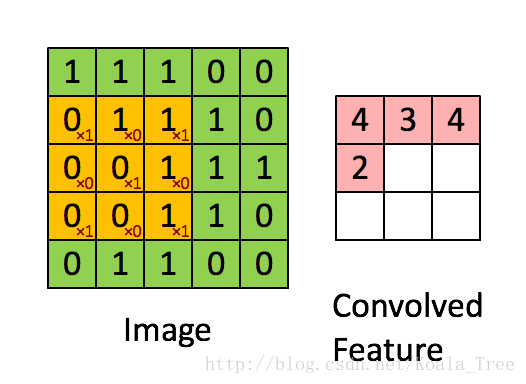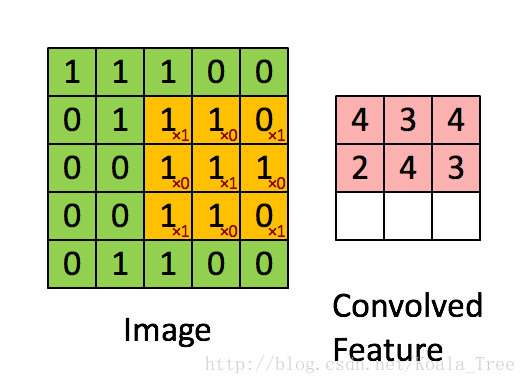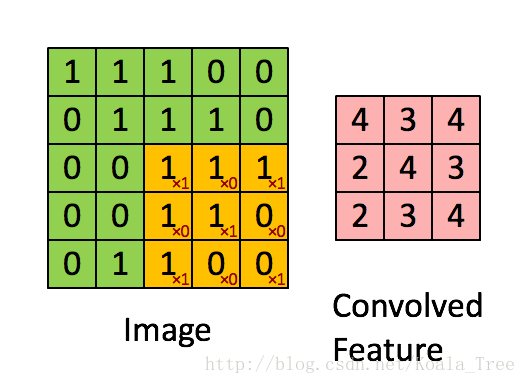
def conv_single_step(a_slice_prev, W, b):
s = a_slice_prev * W
Z = np.sum(s)
Z = Z + b
return Za_slice_prev = np.random.randn(4,4,3)
W = np.random.randn(4,4,3)
b = np.random.randn(1,1,1)
Z = conv_single_step(a_slice_prev, W, b)
print('Z=',Z)Z= [[[-6.99908945]]]3.3 卷积层(convolution layer)
在3.2中给出的例子是只有一个过滤器的情况,在CNN卷积层中过滤器会有多个,此时运算会稍微复杂但原理是一致的,只是输出时要将每个过滤器卷积后的图像叠加在一起输出。
在编写代码前有几个关键点需要说明:
1.如果想从矩阵a_prev(形状为(5,5,3))中截取一个(2,2)的片,我们可以
a_slice_prev = a_prev[0:2,0:2,:]2.a_slice_prev的四角vert_start, vert_end, horiz_start 和 horiz_end的定义如下图所示。

3.卷积操作后输出的矩阵的维度满足以下三个公式:

def conv_forward(A_prev, W, b, hparameters):
(m, n_H_prev, n_W_prev, n_C_prev) = A_prev.shape
(f, f, n_C_prev, n_C) = W.shape
stride = hparameters['stride']
pad = hparameters['pad']
n_H = int((n_H_prev - f + 2*pad) / stride + 1)
n_W = int((n_W_prev - f + 2*pad) / stride + 1)
Z = np.zeros((m, n_H, n_W, n_C))
A_prev_pad = zero_pad(A_prev, pad)
for i in range(m):
a_prev_pad = A_prev_pad[i, :, :, :]
for h in range(n_H):
for w in range(n_W):
for c in range(n_C):
vert_start = stride * h
vert_end = vert_start + f
horiz_start = stride * w
horiz_end = horiz_start + f
a_slice_prev = a_prev_pad[vert_start:vert_end,
horiz_start:horiz_end,:]
Z[i, h, w, c] = con 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3544
3544











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









