







/*---------------------------------------------------------------
任务过程:创建26个字母哈夫曼树,及其编码和译码
1、建立哈夫曼树
2、从每个叶结点回溯到root的路径,并记录路径,则为哈夫曼编码
3、查表方式获得每个字符的哈夫曼编码
-----------------------------------------------------------------*/
#include<stdio.h>
#include<stdlib.h>
//----------------------定义结点数据---------------
#define N_LEAVE 26 //N个权值,则有N个叶结点,树共2N-1个结点
#define N_NODE (26*2-1)
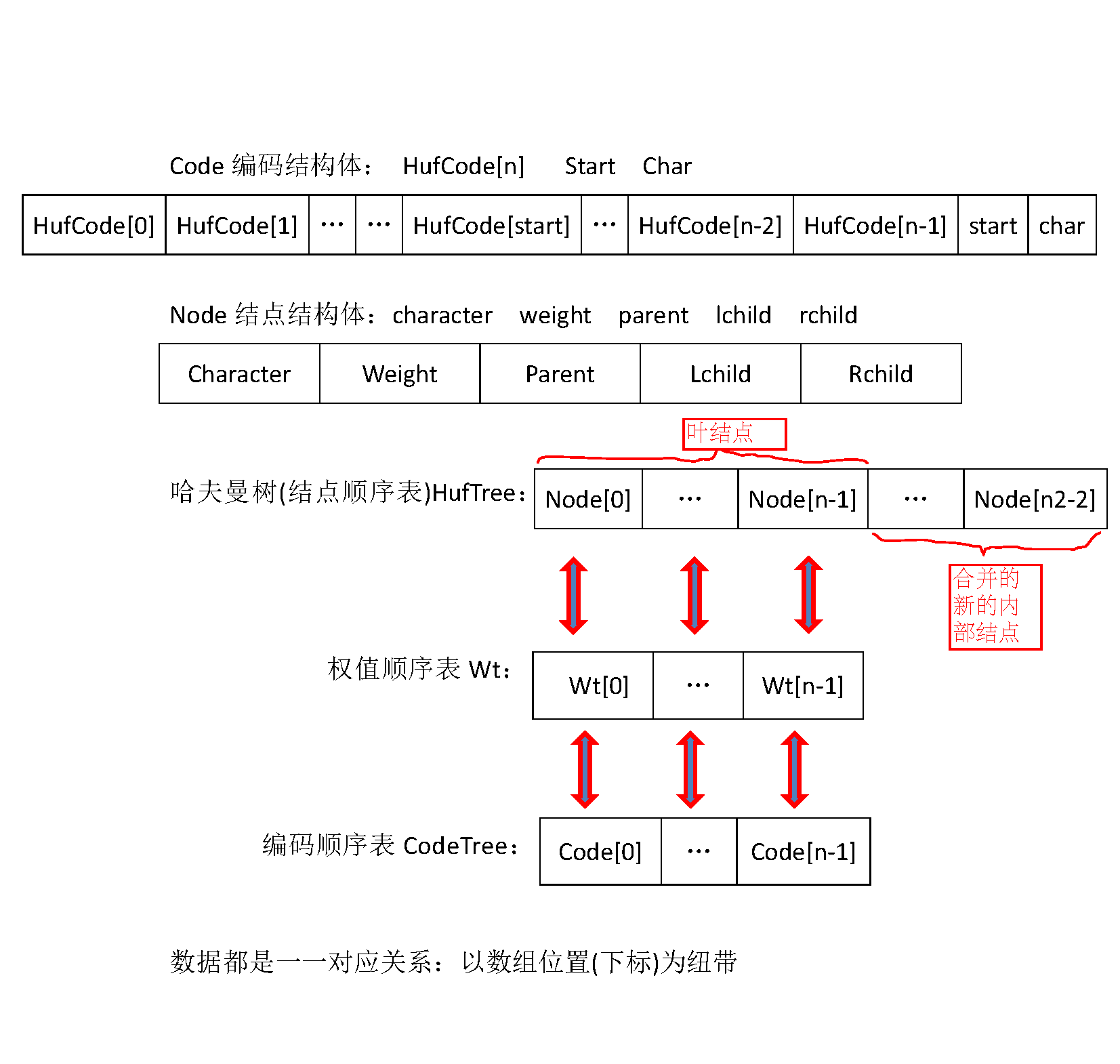
typedef struct _Node
{
char character;
float weight;
int lchild;
int rchild;
int parent;
}Node,*pNode;
typedef struct _Code
{
int HufCode[N_LEAVE]; //叶节点最长编码位数应该为树的最长路径
int Start; //编码起始位(相对编码数组)
char Char; //编码的字符值
}Code,*pCode;
//--------------------------------------------------
//----------------------构造哈夫曼树----------------
void Huffman(Node Ht[],float Wt[])
{
int i,j,x1,x2;
float min1,min2;
//初始化结点数组Ht
for(i=0;i<N_NODE;i++)
{
Ht[i].parent = -1;
Ht[i].lchild = -1;
Ht[i].rchild = -1;
if(i<N_LEAVE)
{
Ht[i].weight = Wt[i];
Ht[i].character = i+65; //A-Z的ASCii码
}
else
{
Ht[i].weight = 0;
Ht[i].character = '?'; //生成的中间结点字符值标记为'?'
}
}
//控制n-1次结点的结合(若有n个叶结点)
for(i=1;i<=N_LEAVE-1;i++)
{
min1 = min2 = 100; //min1、min2记录当前最小、次小权值
x1 = x2 = 0; //x1、x2记录当前最小次小权值结点的位置(数组标号)
for(j=0;j<N_LEAVE-1+i;j++) //在[0-j]范围内找最小次小权值结点
{
if(Ht[j].parent == -1 && Ht[j].weight<min1 ) //parent元素的判断是为了排除已结合过的结点,结合过的结点parent有正值
{
min2 = min1; //当前结点权值小于最小值,所以当前结点变成最小权值结点,原最小结点变成原来的次小结点
x2 = x1;
min1 = Ht[j].weight;
x1 = j;
}
else
{
if( Ht[j].parent == -1 && Ht[j].weight<min2 ) //当前结点权值大于最小值,小于次小值,则取代次小结点
{
min2 = Ht[j].weight;
x2 = j;
}
}
}
//将找到的最小、次小权值结点结合成树,为其父结点赋值,可见该哈夫曼树的根节点应该是Ht数组最后一个结点Ht[N_NODE-1]
Ht[x1].parent = N_LEAVE-1+i;
Ht[x2].parent = N_LEAVE-1+i;
Ht[N_LEAVE-1+i].weight = Ht[x1].weight + Ht[x2].weight;
Ht[N_LEAVE-1+i].lchild = x1;
Ht[N_LEAVE-1+i].rchild = x2;
}
}
//--------------------------------------------------
//---获取并保存每个叶节点的哈夫曼编码供解码时查询---
/*
void Code_Ht(Node Ht[],Code Hc[])
{
int i;
//依次每个叶结点(在哈夫曼结点数组的最前面的空间中)寻找双亲直到root,记录路径,路径就是哈夫曼编码
for(i=0;i<N_LEAVE;i++)
{
Hc[i].Char = Ht[i].character;
Hc[i].Start = N_LEAVE-1; //默认编码起点为编码数组最后一位
while(Ht[i].parent != -1 ) //Ht[i]为root结点退出循环,说明已经回溯到了根结点
{
if(Ht[Ht[i].parent].lchild == i)
Hc[i].HufCode[Hc[i].Start] = 0; //默认编码为左0右1
if(Ht[Ht[i].parent].rchild == i)
Hc[i].HufCode[Hc[i].Start] = 1;
Hc[i].Start--;
i = Ht[i].parent;
}
}
}
*/
void Code_Ht(Node Ht[],Code Hc[])
{
int i,d,p,j;
Code x;
//依次每个叶结点(在哈夫曼结点数组的最前面的空间中)寻找双亲直到root,记录路径,路径就是哈夫曼编码
for(i=0;i<N_LEAVE;i++)
{
x.Char = Ht[i].character;
x.Start = N_LEAVE-1; //默认编码起点为编码数组最后一位
d = i;
p = Ht[i].parent;
while( 1 )
{
if(Ht[p].lchild == d)
x.HufCode[x.Start] = 0; //默认编码为左0右1
else if(Ht[p].rchild == d)
x.HufCode[x.Start] = 1;
else
printf("ERROR!");
d = p;
p = Ht[d].parent;
if(p == -1) break; //Ht[i]为root结点退出循环,说明已经回溯到了根结点
x.Start--;
}
for(j=x.Start;j<=N_LEAVE-1;j++)
{
Hc[i].HufCode[j] = x.HufCode[j];
}
Hc[i].Start = x.Start;
Hc[i].Char = x.Char;
}
}
//输出每个字符的的哈夫曼编码
void PrintCode(Code Hc[])
{
int i,j;
for(i=0;i<N_LEAVE;i++)
{
for(j=Hc[i].Start;j<N_LEAVE;j++)
{
printf("%d",Hc[i].HufCode[j]);
}
printf("%5c\n",Hc[i].Char);
}
}
//查询字符的编码
void FindCode(Code Hc[])
{
int i,j;
char x;
printf("\n请输入一个大写字母:");
scanf("%c",&x);
getchar();
for(i=0;i<N_LEAVE;i++)
{
if( x == Hc[i].Char )
{
printf("字符%c的哈夫曼编码是:",x);
for(j=Hc[i].Start;j<N_LEAVE;j++)
{
printf("%d",Hc[i].HufCode[j]);
}
putchar('\n');
getchar();
return ;
}
}
}
//--------------------------------------------------
//---------------------主函数-----------------------
int main()
{
Node HufTree[N_NODE]; //存放所有结点数据
Code HCode[N_LEAVE];
float Wt[N_LEAVE] = {0.0856,0.0139,0.0297,0.0378,0.1304,0.0289,0.0199,0.0528,0.0627,
0.0013,0.0042,0.0339,0.0249,0.0707,0.0797,0.0199,0.0012,0.0677,
0.0607,0.1045,0.0249,0.0092,0.0149,0.0017,0.0199,0.0008}; //存放叶结点权值
Huffman(HufTree,Wt);
Code_Ht(HufTree,HCode);
PrintCode(HCode);
FindCode(HCode);
return 0;
}
总结:
1、学习方法:我决定学习算法要先模仿,后创造,站在前人的肩膀上,没有知识累积的创造和探索是在走歪路。因为在研究这个算法的时候,我看书没有看代码,在理解了原理之后就开始自己编写函数,结果代码又乱又长,而且没能实现。后来,理解了书本的算法,觉得很精彩,突然想到,我自己从头创造的话,是不是在探索前人已经挖地三尺的地方,所以觉得理解,运用就可以了,总之,自己一直在探索,学习内容也是,学习方法也是。
2、数据结构。本程序中的Code、Node都采用了顺序存储,而结构体中的指针全部都是整形,是元素的数组下标。之前我自己设计的时候,没能灵活运用数组,舍本逐末,在结构体中设置的指针是指针类型数据。Node中的parent指针设置很巧妙,不仅作为编码时回溯到root的路径指针,同时也是Huffman算法中创造新结点时,排除下一次查找最小次小权值结点时剔除本次已被合并成小二叉树的两个当前最小次小结点的标志。
3、Code_Ht算法时,我企图省略中间Code结构x,将两步和为一步,结果造成了非法内存访问。
4、Huffman算法中控制N-1次结点合并的部分很精妙,min1、min2、x1、x2的使用结合parent标志元素的使用使算法简单精巧。附1:26个字母使用频率表
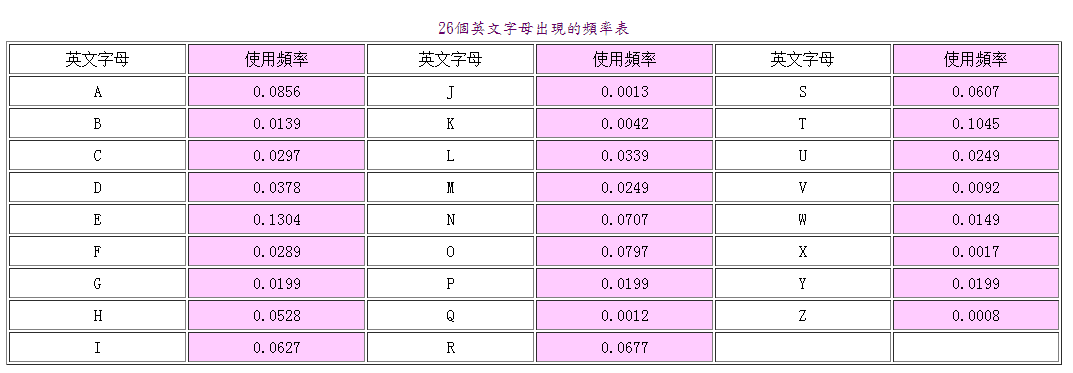
附2:本程序数据结构图示















 770
770

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









