





A64FX 是为超级计算机 Fugaku 开发的处理器。在半导体芯片方面,采用了台积电的7纳米 CMOS 工艺技术。为了实现更高的密度,CPU 芯片互联采用了 TofuD和 PCI Express 控制器,并在封装中集成了高带宽 3D 堆叠内存。A64FX采用 Arm 架构,在继承富士通成熟的高性能微架构的同时,改善了软件开发环境。此外,作为 Arm 有限公司的主要合作伙伴,我们还致力于可扩展矢量扩展(SVE)的具体化,其成果已被采用。本文概述了 A64FX,并介绍了其高性能微体系结构、实现高密度封装的架构以及低功耗设计。
导言
A64FX是为超级计算机 Fugaku(以下简称 Fugaku)开发的处理器。Fugaku 拥有 158,976个处理器。这些处理器要求高性能、高密度封装和低功耗。本文是对设计的主要概述。
添加图片注释,不超过 140 字(可选)
A64FX概览和Arm架构的采用
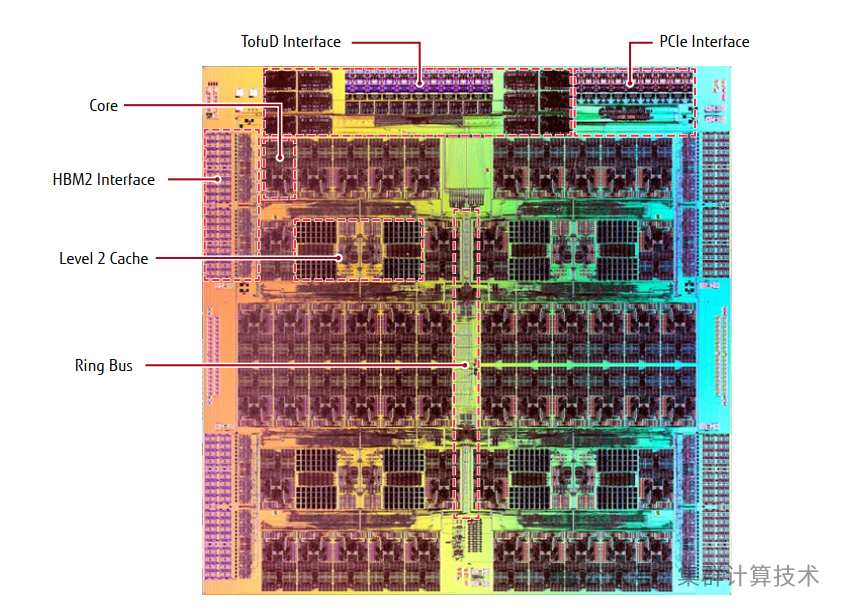
A64FX是在富士通公司公司开发的处理器的微架构基础上进行开发,目的是为了实现更高速的应用程序执行能力。下图是A64FX CPU的框图。
添加图片注释,不超过 140 字(可选)
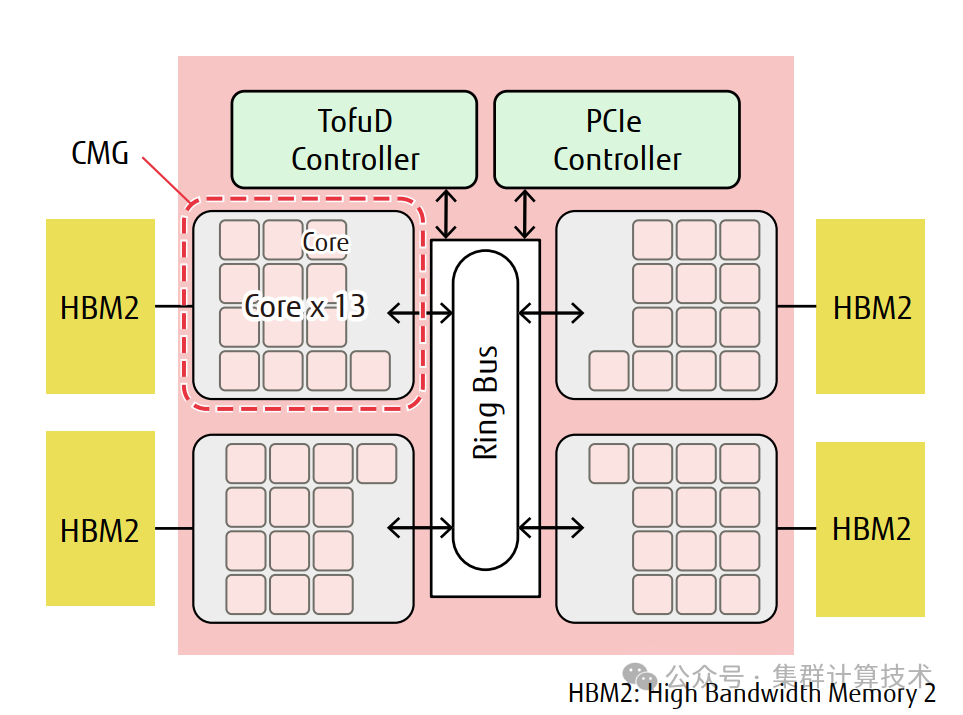
其中有四个核心内存组(CMG),每个核心内存组由13个内核(12个用作计算内核,1个用作辅助内核)、二级缓存和内存控制器组成,并使用芯片上的环形总线网络(NoC)将它们与 Tofu InterconnectD(以下简称 TofuD)[4]接口和 PCl Express(Pcle)接口连接起来。
A64FX采用Arm架构,通过与富士通合作,发展了可扩展矢量扩展(SVE)规范,该规范能够高速执行包括科学计算和人工智能在内的高性能计算应用。
高性能微架构
微架构概述
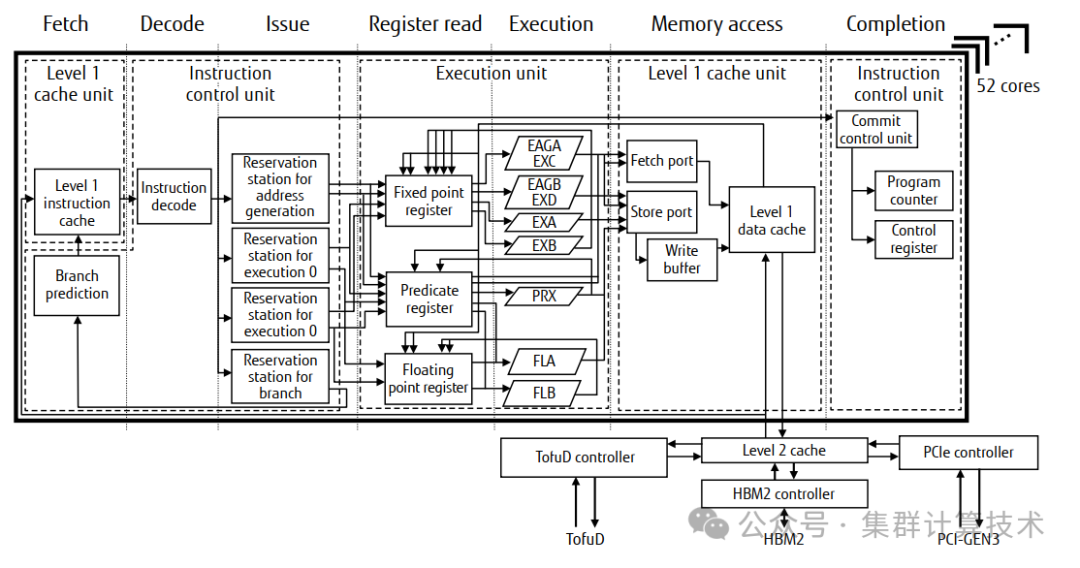
下图显示了A64FX的流水线,一个核心由指令控制单元、执行单元和一级缓存单元组成。指令控制单元执行指令提取、指令解码、指令乱序处理控制和指令完成控制。
执行单元配备有两个定点功能单元(EXA/EXB)、两个用于地址计算和简单定点运算的功能单元(对于地址计算称为EAGA/EAGB,对于定点运算称为EXC/EXD)、两个用于执行SVE指令的浮点单元(FLA/FLB)和一个用于执行预测运算的预测单元(PRX)。这两个浮点单元都具有512位SIMD配置,并且可以在每个周期执行浮点乘法累加操作。因此,每个计算核心每周期能够进行32次双精度浮点运算。并且使用芯片中的所有计算核心每个周期可以执行1,536次双精度浮点运算。对于单精度浮点运算和半精度浮点运算,可执行的运算次数分别是双精度浮点运算次数的两倍和四倍。工作频率为1.8 GHz/2 GHz/2.2 GHz,取决于操作系统配置。
添加图片注释,不超过 140 字(可选)
一级缓存单元处理加载/存储指令。每个核心都有一个64-KiB指令缓存和一个64-KiB数据缓存。数据缓存被配置为能够同时进行两次加载访问,并执行两个64字节的SIMD加载或一个64字节的SIMD存储。
二级缓存单元每个核心内存组CMG(core memory group)有8MiB的统一缓存,由包括辅助核心在内的13个核心共享。
成熟的微架构提升和资源优化
对于A64FX,我们基于大型机器和UNIX服务器采用的高性能,高可靠性的微架构,以及富士通之前开发的K计算机,实现了各种类型的硬件资源优化。
特别是对于重排序缓冲区(ROB)、预留态和队列,这些重要的性能指标。我们采用控制的方式,通过在指令执行时判断队列的释放时间来加速释放。这也确保了指令的执行性能,而不会不必要的增加队列的数量,这些可以通过控制逻辑电路的增加来减少芯片的面积
分支预测电路
我们采用了几种分支预测电路,以便在各种应用中进行最优的分支预测。
例如,使用分段线性算法来执行分支预测的电路,允许高精度分支预测能力,即使是具有复杂指令结构的程序。可以根据长时间的指令执行历史进行分支预测,并且可以实现较高的预测精度。
我们采用了一种能够通过检测一个简单的环路或者其他程序结构来预测分支的电路。通过在程序循环时缓冲循环指令序列,可以停止指令提取单元和其他分支预测电路的运行,从而降低功耗。
虚拟取/存接口电路
加载/存储指令中使用的获取/存储端口是位于流程后期阶段的队列。因此,从释放通知到管理资源的解码器单元,再到释放条目的实际使用,需要几个周期。当资源满时,包括不使用读取/存储端口的指令在内的指令将停止解码,并且需要采取一些措施来处理使用较多读取/存储端口的SVE指令。
为了解决这个问题,我们决定为A64FX提供虚拟取/存端口功能支持,以最小的电路规模提高取/存端口的使用效率,从而提高性能。
以前,指令解码器用于取/存端口资源管理。但在A64FX中,我们为指令解码器分配了比实际取/存端口更多的虚拟取/存端口,并将取/存端口的资源管理分配给了用于基于加载/存储指令的储备站。这样,即使指令解码器使用了所有存取端口,也不会停止指令解码,其效果相当于增加了取存端口条目数。
1级数据高速缓存,支持多种访问模式
为了最大限度地提高512 位SIMD的效率,在向寄存器传输数据的加载指令中保持L1数据高速缓存地访问吞吐量非常重要。当地址不在512位边界上的加载指令按地址顺序依次执行时,跨高速缓存行的访问会在几条指令中发生一次。为了避免这种情况下的性能下降,A64FX的L1高速缓存被配置为允许两个前导端口中的每个端口始终访问两个连续的高速缓存行。因此,即使加载指令跨缓存行访问,每个周期也能保持512位*2的吞吐量。
提高集合加载指令的吞吐性能
集合加载指令从内存中读取不连续的多元数据,并将其写入一个寄存器。虽然数据是不连续的,但在高性能计算应用中,数据具有局部性,正如多个元素访问接近的地址一样。基于这一特点,A64FX采用了一种称为组合收集的加速机制。组合收集机制将收集-加载指令分解为两个元素组成的组,而不是逐个处理元素。当属于同一组的元素在同一128字节边界内访问内存时,只需访问一次高速缓存即可完成处理。因此,与一次处理一个元素相比,吞吐量性能提高了一倍。
预取机制
访问主存储器和低级高速缓存需要大量时间。为了提高程序性能,预取对于隐藏访问时间至关重要。实现预取的方法大致可分为基于软件的方法和硬件的方法。
1) 软件预取
A64FX除支持ARMv8预取指令(即普通预取指令)外,还支持SVE连续预取指令和SVE集合预取指令。因此,多条高速缓存线的预取也可以由一条指令发出。
2) 硬件预取
A64FX的硬件预取机制有两种模式:流检测模式和预取注入模式。
在数据流检测模式下,预取是针对顺序访问发出的。它使用一种称为预取队列的特殊机制来监控内存访问,当检测到顺序访问流时,就会按照地址顺序的方式发出预取。
在预取注入模式下,预取时针对与内存访问有一定距离的地址发出的。使用这种模式的程序可以通过在专用预取控制器中提前设置预取地址信息,为分布访问发出预取,以访问一定距离的地址。
高密度架构
为了实现更高的密度,A64FX—一个集成了各种控制单元的SoC—在封装内安装了四个高带宽存储器(HBM2),四个CMGS分别连接到各自的HBM2,以确保低延迟和高带宽。
CMG配置和ccNUMA
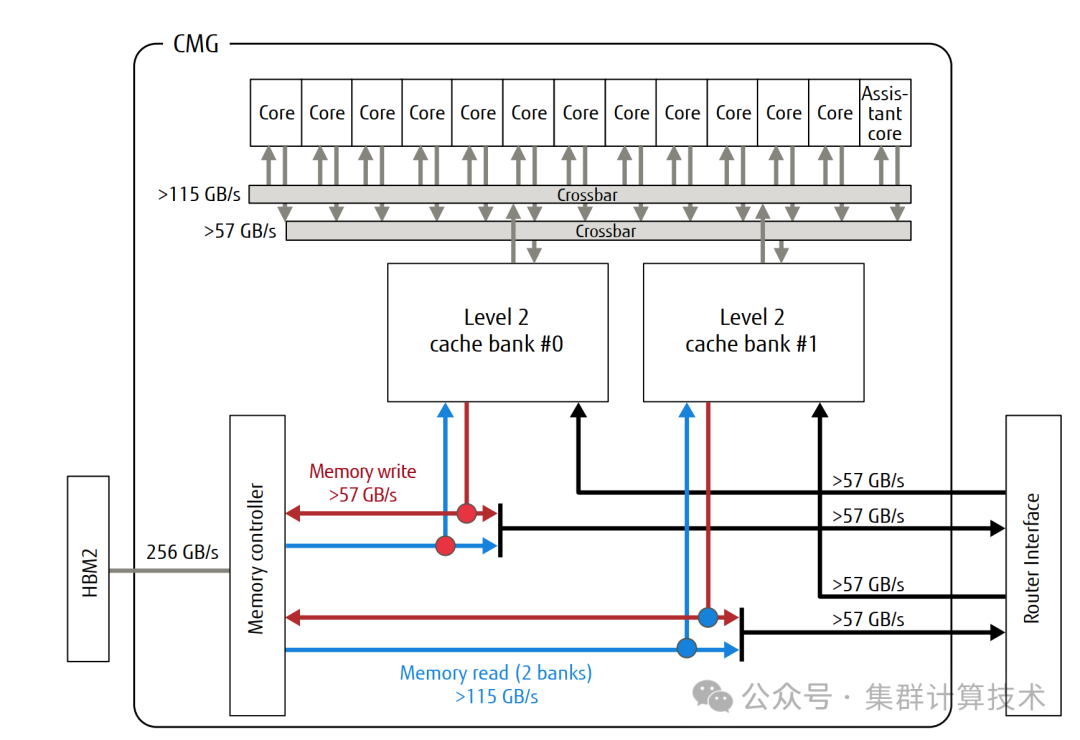
下图显示了CMG(core memory groups)配置和连接图。CMG由13个内核组成,这些内核共享二级缓存和内存控制器组成。
每个CMG的二级缓存容量为8MiB,两个二级缓存组和13个内核由横梁连接。二级缓存的功能是保持整个芯片的缓存一致性,以便软件将CMG视为非统一内存访问(numa)节点。
添加图片注释,不超过 140 字(可选)
A64FX的高度缓存一致性由二级高速缓存流水线集中管理,不使用一般的主代理机制。二级缓存管道由一条管道组成:前半部分称为本地管道,后半部分称为全局管道。用于管理CMG之间高速缓存一致性的目录信息存储在名为TAGD(TAG Directiory)的部分中,并在全局管道中进行访问。如果可以在CMG中关闭一致性管理,则在本地流水线结束时启动对内核的响应;如果不行,则在随后的全局流水线结束时启动CMG之间的一致性管理。这种配置降低了硬件资源要求,实现了低延迟的高速缓存一致性NUMA(ccNUMA)系统。
Soc架构
下图显示了CMG之间的链接。四个CMG、一个TofuD/PCIe控制器和一个中断控制器由两条环形总线和六个环形停止点连接。A64FX还采用专有的NoC拓扑,通过CMG互联路径连接相邻的CMG。环形总线和CMG互联路径的吞吐量均超多115GB/s.
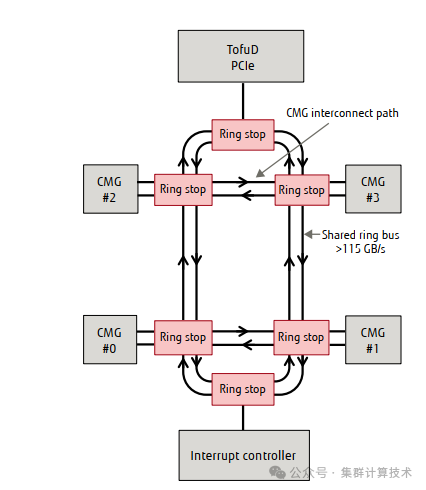
添加图片注释,不超过 140 字(可选)
有了CMG互联路径,就可以避免因与TofuD网络和I/O的数据传输以及来自中断控制器的中断请求等原因而影响环形总线的使用,还实现了与使用crossbar相比,配置的区块间连接数量更少,从而确保了相邻CMG之间的吞吐性能。
HBM2和内存控制器
A64FX使用HBM2,这是一种三位堆叠内存,带宽远高于普通服务器使用的DDR4 DIMMs。专为HBM2开发的内存控制器,CPU芯片和HBM2采用2.5D封装技术集成在一个封装中,以确保低延迟和高达1024GB/s的内存带宽。通过专为HBM2开发的内存控制器,优化了控制方法,以根据HBM2内存的特性最大限度地提升性能,同时确保与大型机相同的高可靠性。
TofuD和PCIe控制器
作为外部输入/输出接口,A64FX有一个通过相互连接CPU实现大规模并行系统的TofuD和一个用于连接I/O设备的PCIe总线。TofuD有20个传输速度为28Gbps的高速串行信号通道,最多可以连接10个CPU,带宽为6.8GB/s,PCIe有16个高速串行信号通道,传输速度为8Gbps,带宽为16GB/s.
下图显示为TofuD的框图。TofuD有六个TNI网络接口,并通过一个网络路由器与10个CPU连接。
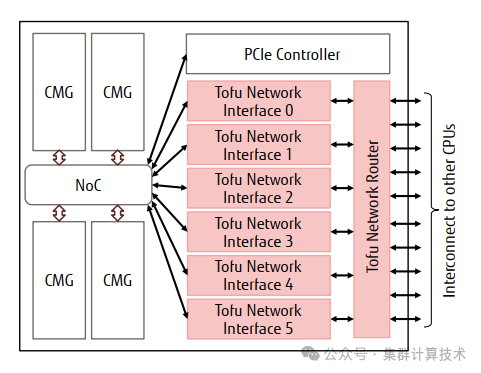
添加图片注释,不超过 140 字(可选)
TofuD的网络与K计算机一样采用6D网状拓扑结构。虽然网络的节点地址在物理上是6D,但用户进程会被赋予虚拟的3D坐标,以便使用传统的通信算法进行3D连接。与K计算机一样,TofuD的通信功能也配备了远程直接内存访问(RBMA)通信和障碍同步通信,前者是用户进程可以直接使用的功能,后者是系统用于IP数据包传输的功能。在RDMA通信类型方面,Tofu2在K计算机之后扩展了原子读-修改-写功能,除了与K计算机相同的put和get功能外,还支持原子的读-修改-写功能。Tofu的RDMA通信有自己的虚拟存储,并直接在各节点操作系统管理的用户进程虚拟地址空间之间传输数据。每次数据传输都会分配一个全局进程ID,并受到保护,只能指向由同一并行程序执行的进程。与传统的Kjisuan和Tofu2相比,TofuD可同时进行更多通信,并增强了容错和障碍同步通信功能。下面将介绍各自的增强功能。
1) 通信带宽增加为原来的两倍
大多数为三位连接而优化的集体通信算法可在三维空间的六个方向上同时通信。然而,传统的网络接口数量为四个,最多只能在四个方向上同时通信。有了TofuD,网络接口的数量增加到6个,这样就可以使用一种通信算法,通过在三维空间的三个方向上同时通信来实现高带宽。同时通信的总带宽从K计算机的20GB/s提高到了40.8GB/s
2) 高容错率
K计算机,可以检测到与相邻节点的每条链路的错误,并重新传输数据。此外,错误检测频率高的链路会被断开。使用Todu2时,断开的连接会在lane减少到1半时自动连接。如果Lane已经减半,则使用不同的lanes重新连接,但没有自动恢复lanes数量的方法。
相比之下,TofuD具有在错误检测频率较高时减少带宽的功能,以及在错误检测频率降低时恢复已减少带宽的功能。具体来说,当错误检测频率较高时,该功能通过两条通道传输相同的数据,同时保持链路以提高容错性。而当错误检测频率较低时,则回复使用通道传输不同数据的模型,以恢复带宽。
3) 六个障碍同步通信
在引入CMGS的同时,还增加了用于障碍同步通信的资源数量,以扩大牵引操作元素的数量。传统上四个网络接口中的一个用于障碍同步通信,而在TofuD中,所有六个网络接口都执行障碍同步通信。传统上,无论数据类型如何,每次障碍同步都只能对一个元素进行收缩操作。但有了TofuD,可以对八个整数元素或三个附带浮点元素进行收缩操作。
低功耗设计
在低功耗方面,从架构层面到设备层面,都采取了各种措施来节省功耗。
架构级节点
通过将计算核心分组并将内存直接连接到每个分组,以及避免跨分组的进程映射,大多数应用操作都可以在CMG中轻松实现。因此,数据的平均传输距离缩短了,从而降低了功耗。
电路级节电
为了支持512位SIMD,对一级数据高速缓存的访问方法进行了审查。由于在大量使用SVE向量的应用程序中,吞吐比延迟更重要。在访问一级数据高速缓存时,SVE加载指令采用了一种可显著降低功耗的方案,但略微增加了延迟。
我们还检查了算术流水线中的数据转发电路,并增加了一个电路,通过减少对功耗较大的寄存器文件的引用来降低功耗。
结论
这篇文章介绍了 A64FX 的高性能、高密度封装和低功耗设计。
开发 A64FX 的目的是大幅提高各种应用的单位功耗性能。富士通公司与日本理化学研究所计算科学中心(RIKEN Center for Computational Science)共同开发了 A64FX。负责处理器开发、系统开发、软件开发、编译器开发和性能评估的不同团队密切合作成功开发出新技术,推动了传统技术的发展,并实现了目标。
我们期待超级计算机"Fugaku"今后能为解决各个领域的问题做出贡献,也期待 A64FX 能被广大软件开发人员所接受,以加速 Dx 的发展
本文仅用作分享,无任何商业用途盈利,如有侵权,请联系作者删除。
引用:
-
Taiwan Semiconductor Manufacturing Company, Ltd
-
RlKEN: Fugaku System Configuration.https://postk-web.r-ccs.riken.jp/spec.html
-
T. Yoshida: Fujitsu High Performance CPU for the Post-KComputer, Hot Chips 30 (2018).https://www.fujitsu.com/jp/lmages!20180821hotchips30.pdf
-
Y. Ajima et al.: The Tofu Interconnect D. lEEE InternationaConference on Cluster Computing, pp.646-654(2018)
-
S. Yamamura: A64FX High Performance CPU Design,Cool chips 22(2019).
-
Y. Ajima: High-dimensional interconnect Technology forthe K Computer and the Supercomputer Fugaku. FujitsuTechnical Review(2020)
-
https://www.fujitsu.com/global/about/resources!publications/technicalreview/topics/article005.html
-
Y. Ajima et al.: Tofu: A 6D Mesh/Torus Interconnect forExascale Computers. lEEE Computer, Vol. 42, No. 11,Pp.36-40 (2009)
-
Y. Ajima et al.: The Tofu Interconnect. lEEE 19th AnnuaSymposium on High Performance Interconnects, pp87-94(2011).
-
Y. Ajima et al.: The Tofu interconnect 2. lEEE 22ndAnnual Symposium on High Performance InterconnectsPp.57-62 (2014).


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









