







HPC广泛应用于地球科学、生命科学、物理化学材料、工业仿真、油气勘探、人工智能等领域。通常程序执行环境的差异会带来运行效率的差异,更高的运行效率能够帮助用户更快地完成计算任务。
大部分高性能计算领域的程序代码均由C/C++或Fortran编写而成,上述三种语言是更为靠近系统底层的语言,可以通过自底向上的调优更精准地控制程序的行为,获得更高的运行性能。
本文针对HPC应用首先从硬件层面的优化方法——BIOS参数优化展开,后续将持续介绍系统参数优化、编译参数优化、运行时参数优化等多个层面的优化方法。
在硬件层面,BIOS能够控制CPU、内存、硬盘等硬件的基础设置和行为,对BIOS进行适当的调节能够改善整机在特定条件下的性能。
在设置BIOS参数时,用户首先需要了解服务器的硬件配置,包括CPU型号、内存容量和频率、硬盘类型和数量等,以便根据具体硬件特点进行设置调整;需要综合考虑CPU、内存、硬盘、电源等方面的设置,以确保整个系统能够协同工作,提高整体性能。
本文以Intel Sapphire Rapids 6458Q平台为例进行介绍。Intel 6458Q为第四代英特尔至强可扩展处理器,拥有32个内核,支持64线程,最大睿频频率为4.00 GHz,基本频率为3.10GHz。
第四代英特尔至强可扩展处理器采用全新架构,单核性能比上一代产品更高,每路最多配备 60 个核心,比代号Ice Lake(-SP)的第三代至强可扩展处理器高出50%。第四代处理器在内存和I/O子系统方面也做了相应改进,其支持DDR5 内存,单路CPU支持8通道DDR5,速率达到4800MT/s,单/双路节点比上代ICL-SP的8通道DDR4 3200MT/s提高了50%;单路CPU支持80通道的PCIe5.0,单/双路节点比上代ICL-SP的64通道PCIe4.0提高了150%, I/O 得到显著提升;多路系统中CPU之间互联升级到4个UPI2.0,数据速度16GT/s,单/双路节点比上代ICL-SP的3个UPI,数据速度 11.2GT/s高128%。此外,第四代处理器还支持Compute Express Link (CXL),显著提升了整体数据的吞吐量。

CPU相关参数
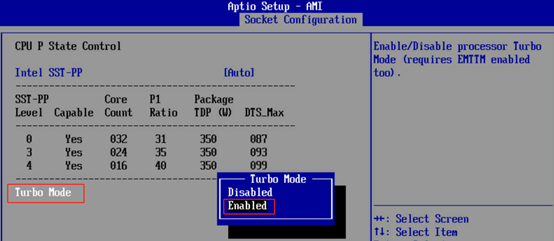
1.Turbo Boost
英特尔睿频加速技术(Intel Turbo Boost Technology)是英特尔2012年起应用处理器的独有功能。当开启睿频加速之后,CPU会根据当前的任务量动态改变处理器时钟频率(主频),从而在执行重任务时发挥最大的性能,轻任务时发挥最大节能优势。一般可以设置为Enable。
2.Hyper Thread
Hyper Thread技术是把一个物理CPU核虚拟成多个逻辑CPU核并允许并行执行指令的功能。它非常适合运行内存IO密集而非计算密集的应用程序,因为IO操作会有更多的等待时间可以被利用。一般关闭该功能。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1410
1410

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









