





本周分享SC24演讲来自橡树岭国家实验室&DOE《Scaling Deep Learning on AMD GPUs》

Frontier Supercomputer
系统概览
-
EF(ExaFlops)峰值双精度浮点性能
-
9408个节点
-
9.2PB内存和37PB节点本地存储
-
716PB中心级存储
-
4000平方英尺的占地面积
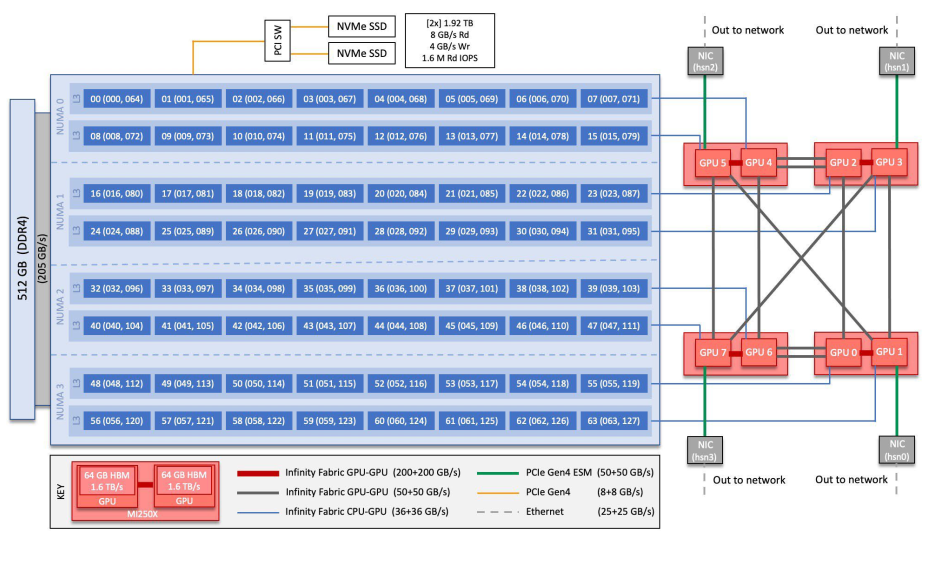
Frontier 节点信息
-
1个64核心AMD HPC优化型EPYC CPU和512GB DDR4内存。
-
4个AMD Radeon Instinct MI250X GPU(gfx90a),每个GPU由2个图形计算芯片(GCDs)组成。
-
GPU间通过全互联的无线Fabric互联,主机到GPU通过PCIe Gen4连接,带宽为36+36GB/s
-
2个NVMe SSD,每个1.9TB
-
Silingshot互联,带宽为25+25GB/s.
深度学习软件栈比较
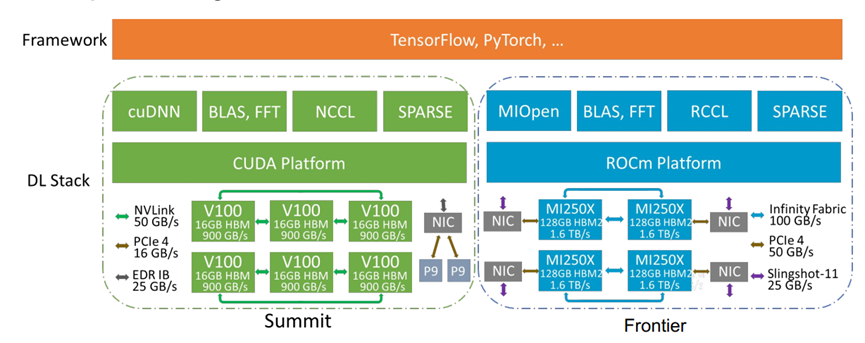
图中展示了Summit和Frontier的深度学习硬件架构,框架层方面都适用TensorFlow,PyTorch等深度学习框架,软件栈方面,Frontier采用MIOpen深度学习优化库,专为AMD GPU设计,以优化CNN的性能,同时提供BLAS,FFT基础线性代数库和快速傅里叶变换等数学库;RCCL是ROCm平台提供GPU集体通信支持。SPARSE是用于稀疏矩阵运算的库。硬件层面使用AMD的MI250X GPU,每个GPU有128GB的HBM2内存和1.6 TB/s的内存带宽。通过Infinity Fabric(100 GB/s)和PCIe 4(50 GB/s)以及Slingshot-11(25 GB/s)进行GPU之间的连接和通信。
Frontier上的分布式策略
数据并行:
-
PyTorch DDP, TensorFlow Multiworker Mirrorred strategy
-
Horovod
模型并行:
-
PyTorch FSDP
-
DeepSpeed-Megatron 3D并行
分布式训练:FSDP(Fully Sharded Data Parallel)
FSDP(完全分片数据并行)与ZeRO类似,通信大小是DDP的1.5倍
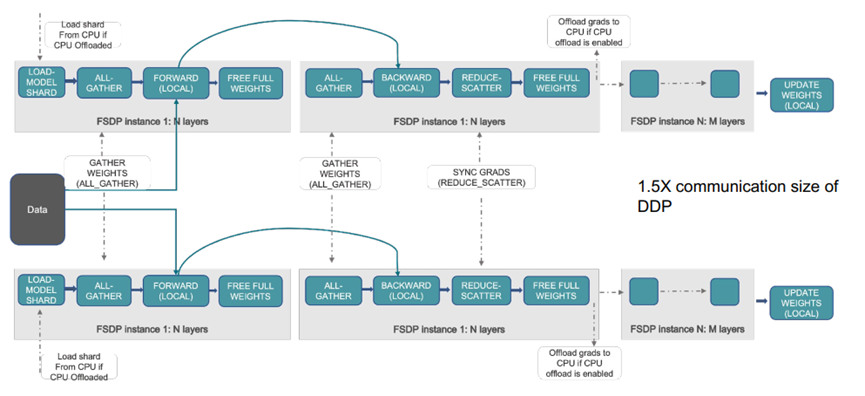
数据被分割并加载到每个FSDP实例中,如果启用了CPU卸载,就从CPU加载分片。在每个FSDP实例中进行本地前向传播(Forward),因为每个实例只处理模型的一部分,因此只是用部分权重。前向传播完成后,释放不再需要的完整权重,以节省内存。在反向传播(Backward)之前,通过All-Gather操作收集所有分片梯度,以便每个实例都有完整的梯度信息。在每个FSDP实例中进行反向传播。使用Reduce_Scatter操作同步梯度,然后更新权重。如果启动了CPU卸载,梯度会被卸载到CPU上。
通信量:FSDP在前向传播后需要All_Gather操作来收集权重,在反向传播后需要进行Reduce_Scatter操作来同步梯度。
分布式训练:DeepSpeed-Megatron 3D并行
-
分片数据并行-ZeRo,共享优化器状态,梯度和参数
-
流水线并行-层放置+微批量
-
张量并行
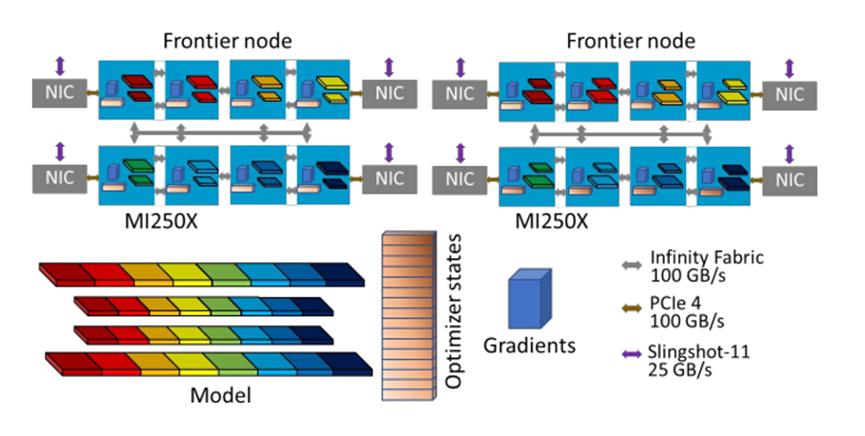
每个节点包括多个MI250X,这个GPU是通过100GB/s的Infinity Fabric连接,每个节点通过PCIe4(棕色箭头)连接配备了NIC网络接口卡,使用Slingshot-11进行节点间通信。在实际使用时,模型进行了分片,分布在不同的GPU上,每个GPU负责模型的一部分计算。优化器状态和梯度也在GPU之间通过Infinity Fabric进行,以实现模型的同步更新。
在Frontier训练LLMs
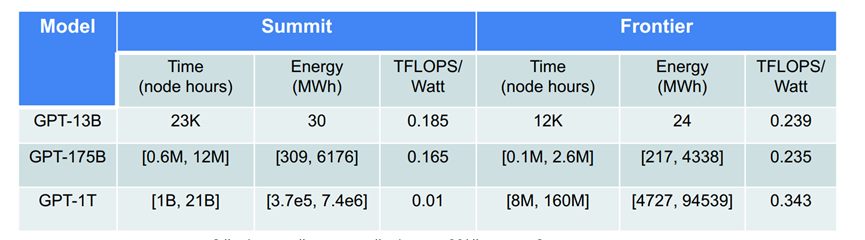
计算资源和能耗统计(与Summit的对比)
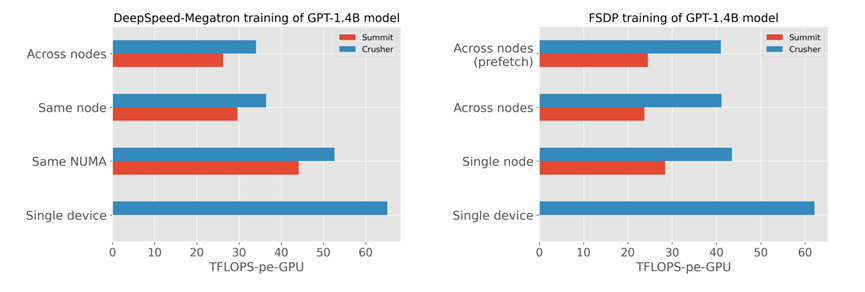
分别比较了在两个不同的深度学习训练设置下,GPT-1.4B模型训练的每秒万亿次浮点运算(TFLOP/s)性能。这两个设置是DeepSpeed-Megatron和FSDP(Fully Sharded Data Parallel)。分别是跨节点,单节点,统一nuam下,单个设备。
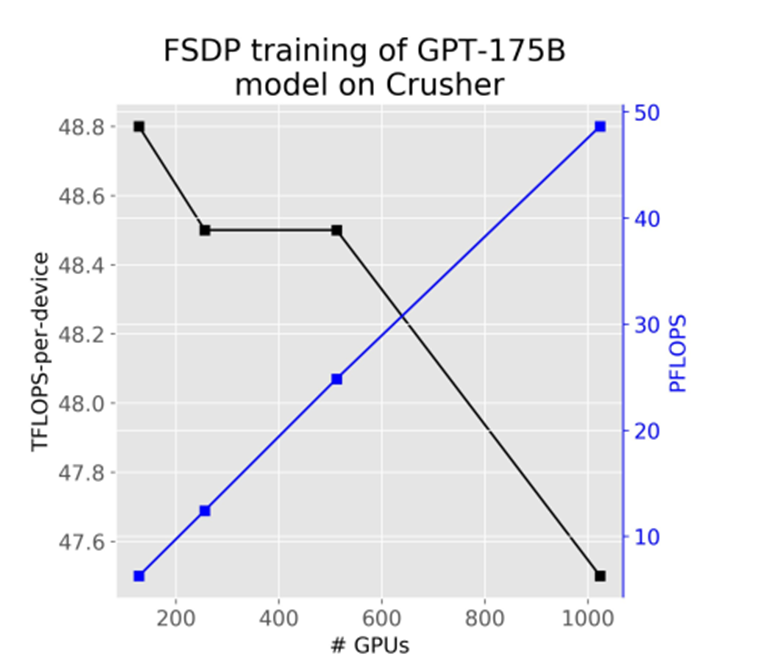
使用rocprof-nvprof进行性能分析
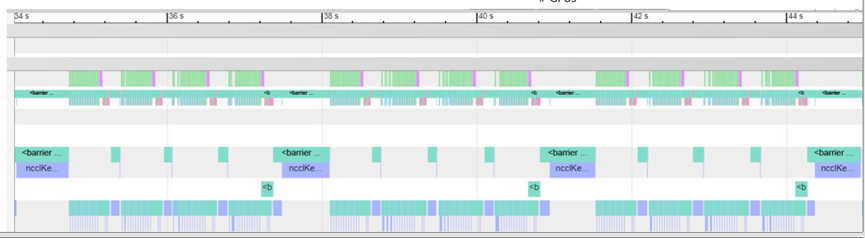
使用OmniTrace-nsight进行追踪
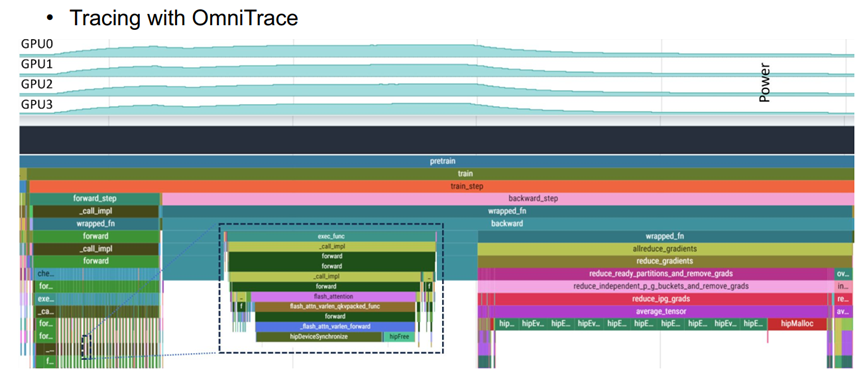
在Frontier用FSDP训练ViTs
-
在Frontier上优化训练性能
-
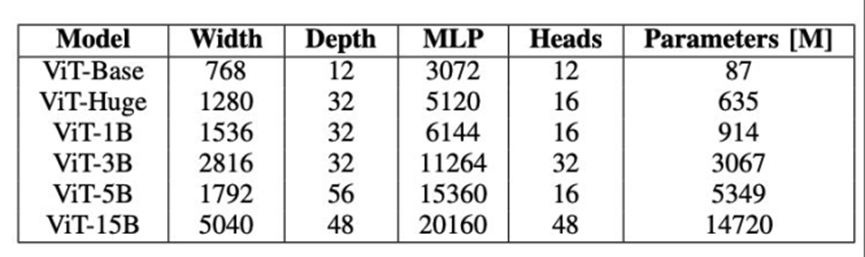
测试了六种不同大小的ViT模型
-
表中前4个可以在一个GCD(半个节点)上测试,ViT-5B模型需要两个GCDs,ViT-15B模型需要四个GCDs。
测试IO或者通信是否是主要的瓶颈
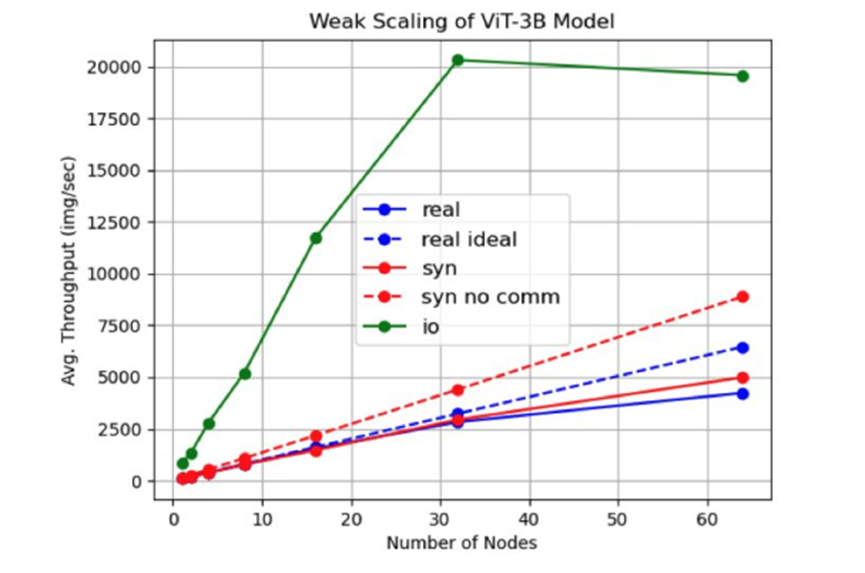
从图中看对于ViT-3B模型来说,多节点情况下性能主要由通信影响,而不是IO。
使用ViT-5B对不同分片选项和通信选项的测试
分片选项:
-
Full shard:完全分片,每个GPU只处理模型的一部分和数据的一部分
-
No shard:不分片
-
Hybrid shard:混合分片
-
Shard grad op:分梯度操作
通信选项:
-
None:不进行特定的通信优化,每个节点独立地进行前向和反向传播
-
Backward pre:反向传播开始之前进行梯度聚合(All-Gather)操作
-
Backward post:反向传播之后进行梯度聚合
-
Limit all gather: 限制所有聚合操作(如 All-Gather)的通信量。
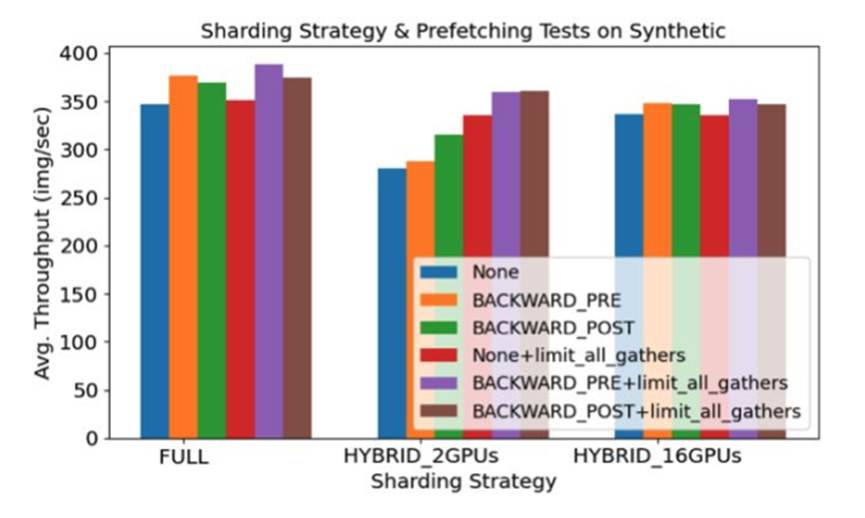
分析了通信优化对分布式训练的吞吐量的影响。在FULL分片策略下,在多GPU设置下,BACKWARD_PRE 和 BACKWARD_POST 的吞吐量略高。在 HYBRID_2GPUs 分片策略下,BACKWARD_PRE 的吞吐量最低,而其他选项的吞量相对接近。在 HYBRID_16GPUs 分片策略下,使用一定的通信优化,都可以提高吞吐量,提高训练效率。
使用FSDP训练不同大小视觉变换器ViT模型的弱扩展性
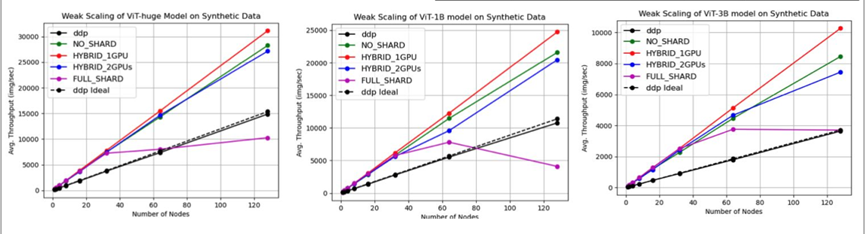
以ViT-huge、ViT-1B 和 ViT-3B 模型(都可以在一个GCD上训练的)在合成数据上的弱扩展性测试结果为例:混合分片策略(HYBRID_1GPU 和 HYBRID_2GPUs)在不同模型和节点数量下表现出较好的扩展性。Full_SHARD在多节点情况下,扩展性降低。因此在多节点训练时选取核时的分片策略又助于提升训练性能
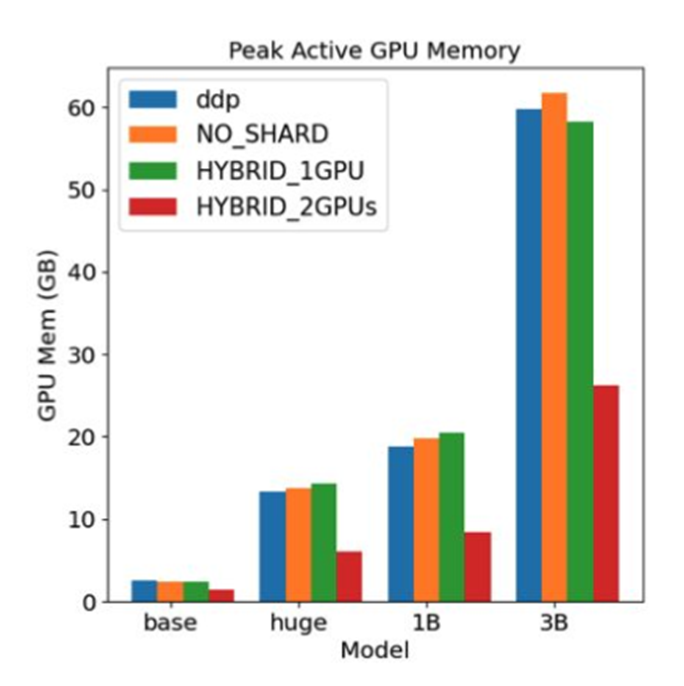
(FSDP)训练视觉变换器(ViT)模型时的内存使用情况
-
随着模型大小的增加,所需的GPU内存也显著增加,这要求在设置及分布式训练策略时需要考虑内存管理。
-
混合分片策略(HYBRID_2GPUs)在内存使用上表现出一定的优势,尤其是在大型模型上。
(5B-15B)在合成数据上的弱扩展性
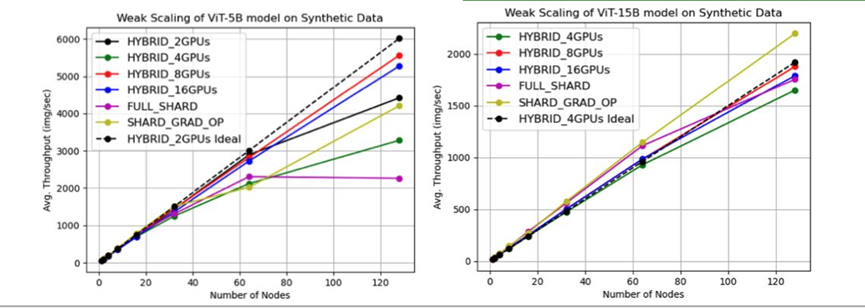
(5B-15B)都需要多个GCDs训练,5B模型在混合分片策略(HYBRID_8GPUs)更接近理想扩展状态。15B模型在分梯度操作分片策略(shard_grad_op)扩展效果最好,但混合分片策略(HYBRID_8GPUs)更接近理想扩展状态。可见多节点测试时,不同的模型选择不同分片策略,可以有效提升并行效率。
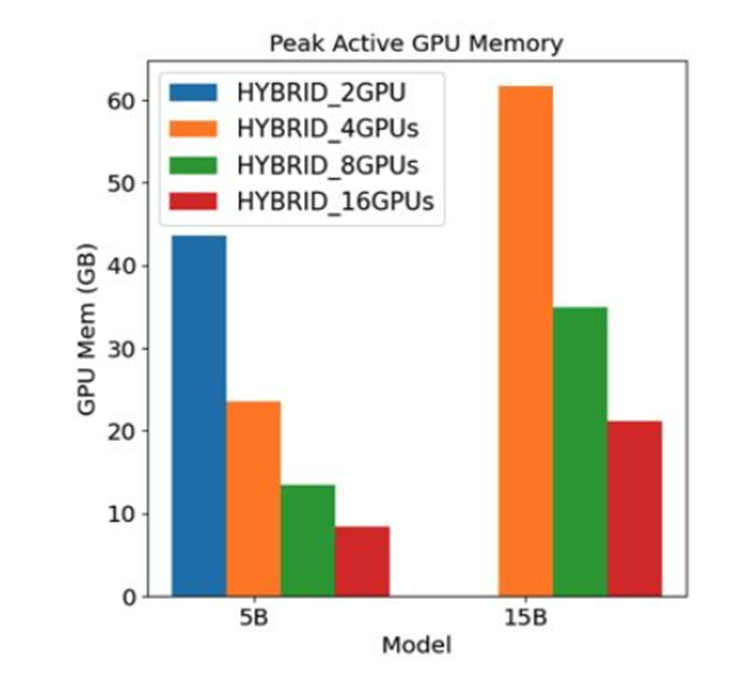
以下是不同分片方式下GPU内存使用情况
总结
-
PyTorch可以直接在Frontier和AMD GPU上工作
-
为了优化性能,需要考虑Frontier的节点拓扑结构
-
不同模型大小可能需要不同策略以获得最佳性能。
本文只做分享,不做任何商业用途


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









