





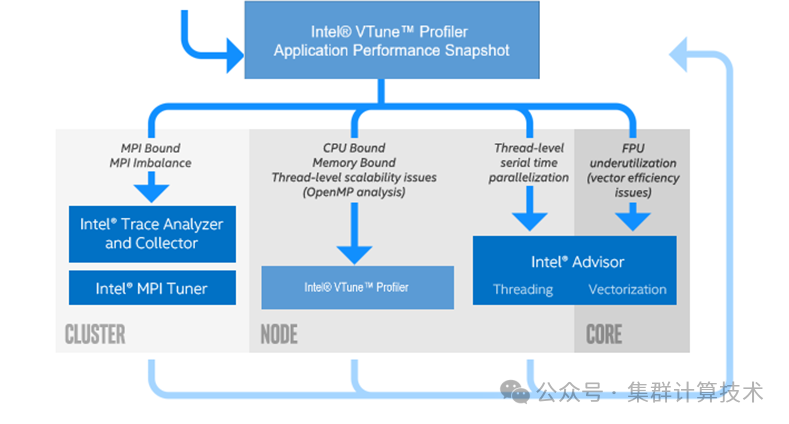
接下来将主要分享如何用Vtune, Advisor以及ITAC进行性能分析,以及在性能分析过程中这三种性能工具的区别与分工。如下图所示,这是在Intel平台对MPI应用进行性能分析的一个基本流程。
添加图片注释,不超过 140 字(可选)
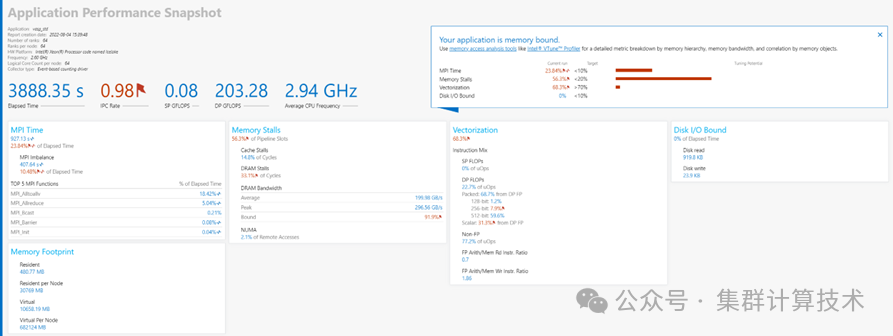
首先通过Application Performance Snapshot(APS,集成于Vtune)对应用的性能表现进行一般性的描述,包括执行时间,平均IPC,CPU 频率,浮点计算能力,向量化比例分析,MPI 耗时分析,Memory相关的stall分析,Disk 读写信息以及内存情况(应用实际内存占用申请的虚拟内存)。并针对上述情况提出分析方向,如下图所示。
添加图片注释,不超过 140 字(可选)
第二步,根据提示分别对多节点的MPI 通信(ITAC),单节点内的程序执行情况(VTUNE,微架构层面分析)以及程序在多线程,向量化分布进行分析(Advisor,代码层面)。本次主要介绍Vtune。
Vtune 介绍
Vtune性能分析工具(Intel VTune Performance Analyzer,本文用VTune表示此工具),是一个用于分析和优化程序性能的工具,可用于系统层面和应用层面性能优化,也可用于针对特定场景的应用优化,比如HPC,云计算和物联网(IoT)等。
支持多种异构环境(CPU,GPU和FPGA),可分析异构环境下的整体性能表现而不局限于异构硬件本身。
支持针对多种编程语言的分析,如SYCL*, C, C++, C#, Fortran, OpenCL™ code, Python*, Google Go* programming language, Java*, .NET, Assembly或者混合多种语言的程序。
支持将性能数据分析与程序源码相结合。
支持功耗分析,避免在优化过程中提升硬件功耗。
VTtune目前收归于Intel oneAPI Base Toolkit。
VTune是一个多功能的性能分析工具,适合在本地节点(PC)上结合本地软硬件信息进行多层次分析。本文的内容来自于Intel Vtune Cookbook和Usr Guide,本文的目标是通过简化复杂使用说明和示例,使之更容易应用与HPC应用得分析之中。
Vtune快速安装
-
下载VTUNE离线安装包(推荐用离线的包),以2022.3版本为例。
wget https://registrationcenter-download.intel.com/akdlm/IRC_NAS/18656/l_oneapi_vtune_p_2022.3.0.195_offline.sh-
安装:(命令行交互模式安装)
./ l_oneapi_vtune_p_2022.3.0.195_offline.sh -a -c-
设置环境变量
方式一:通过设置在vtune所在oneApi toolkit 环境变量,设置Vtune的环境变量
source /path/to/intel/oneapi/setvar.sh方式二:设置VTUNE环境变量
Source /path/to/vtune/vtune-vars.sh-
采样驱动的安装
采样驱动是Intel开发的,用于硬件事件采样的工具驱动。与perf的采样方式相比,不依赖内核版本的支持,并且具有更低的采样开销。
此外,没有此驱动Vtune会利用linux系统中的perf进行采样。
需要开启的内核选项,修改对应文件:
CONFIG_MODULES=y
CONFIG_MODULE_UNLOAD=y
CONFIG_PROFILING=y
CONFIG_SMP=y
CONFIG_TRACEPOINTS=y (optional but recommended)
CONFIG_KALLSYMS=y
CONFIG_KPROBES=y
CONFIG_KRETPROBES=y
CONFIG_FRAME_POINTER=y (optional but recommended for Call Stack Mode)
源码目录:
/ath/to/vtune/sepdk/src编译驱动:
./build-driver -ni安装驱动:
./insmod-sep -r -g root(root 用户)设置开机自启动(可选):
./boot-script --install -g root(root 用户)卸载驱动:
./rmmod-sep -sVTUNE QUICK START
为了更好的理解VTUNE的使用方法以及分析的重点,对VTUNE的介绍先从对单个程序的分析优化开始。后续将重点介绍在HPC环境中的使用方法。
本节所用的示例地址以及初始状态的执行情况如下。
/path/to/vtune/latest/samples/en/C++/matrix
cd linux && make icc && cd ..
./matrix
Threads #: 12 OpenMP threads
Matrix size: 2048
Using multiply kernel: multiply1
Freq = 1.649214 GHz
Execution time = 27.953 seconds
MFLOPS: 614.591 mflops
该应用是一个矩阵乘法计算的示例,其中包含了处理器后端访存压力以及向量化优化上的问题,这与HPC应用中常见的优化问题十分相似。工具是辅助解决问题的手段,理解并处理问题本身更为重要。
应用性能快照(APS)
通过应用性能快照(APS)可以对应用的性能表现有一个全面且直观的认识。vtune在此部分有两种命令形式(应用快照模式(APS)和性能快照模式,官方文档中并无明确的说明),两种模式从功能上有两点明显不同:
1、 APS:上包含了omp,MPI以及DiskIO的采样,并针对单独提出Memory Stall 和 Vectorization两部分利用情况(更适合HPC场景)
2、 Performance snapshot:以TMA方法展现了其完整的分析结果,并提供了更丰富的分析建议。
对于单个应用的分析,性能快照模式更有利于快速了解应用的运行状态.
测试命令:
aps a.out生成报告:
aps –report ./aps_result_***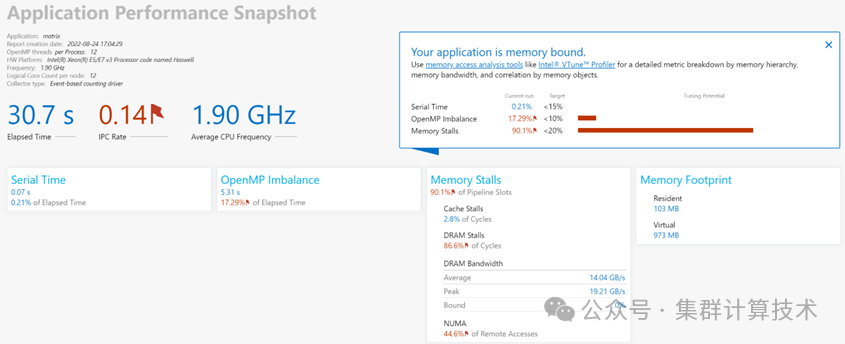
添加图片注释,不超过 140 字(可选)
微架构快照模式
测试命令:
vtune -collect performance-snapshot -r <result_dir>../matrix生成报告:
vtune/vtune-gui –report summary -r <result_dir>也可将result_dir 复制到个人电脑处用vtune打开,如下图所示
添加图片注释,不超过 140 字(可选)
应用的性能主要受到处理器后端STALL的影响,而且主要来自DRAM上访存延迟的影响,并伴有一定的跨节点访存。
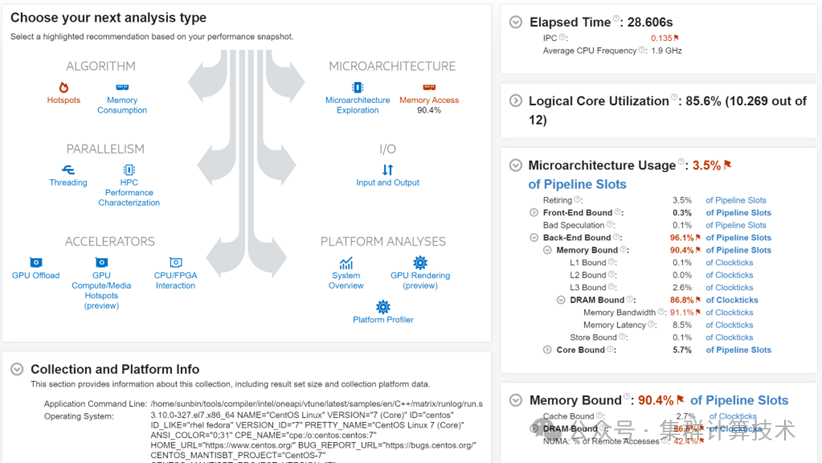
通过performance snapshot可知应用性能瓶颈主要来自访存延迟。进一步做Memory Access 分析: (产生的性能数据比较多)
测试方式:访存相关的分析会产生大量采样文件,一般通过“-d“选取少量的时间进行采样,也可以设置延迟开启“-start-paused”。
vtune -collect memory-access \ -start-paused 延迟采样;
-knob analyze-mem-objects=true \ -d 采样时间;
a.out
生成报告:
vtune -report summary -report-knob show-issues=false -r or vtune-gui通过vtune查看最耗时的函数调用和Memory Bound比例最高的函数调用。
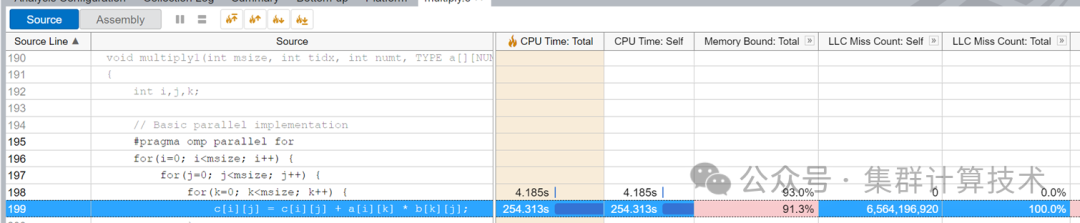
添加图片注释,不超过 140 字(可选)
优化一:循环内部访存优化
通过上述的分析发现跨数组或循环体访问,可替换J/k
for(i=tidx; i<msize; i=i+numt) {
for(k=0; k<msize; k++) {
for(j=0; j<msize; j++) {
c[i][j] = c[i][j] + a[i][k] * b[k][j];
执行时间由28s缩短到了1.7s。
通过Memory Access进一步分析,还存在大量的load和store指令。通过循环展开减少循环块访存压力,缓解DRAM bound。
#pragma unroll(8)
for(j=0; j<msize; j++) {
c[i][j] = c[i][j] + a[i][k] * b[k][j];
执行时间缩到到1.5s
优化二:向量化优化
打印编译报告(-qopt-report=3)可知热点函数因内部数据依赖并没有能够进行向量化优化:
[ ../src/multiply.c(270,31) ]
remark #15344: loop was not vectorized: vector dependence prevents vectorization. First dependence is shown below. Use level 5 report for details
用advisor查看该循环的向量化情况。(后续详细介绍)
通过添加向量化关键词来提示编译器进行向量化优化(#pragma ivdep),当前平台可支持到AVX2指令特性,需要在编译选项上增加-xhost
for(i=0; i<msize; i++) {
for(k=0; k<msize; k++) {
#pragma unroll(8)
#pragma ivdep
for(j=0; j<msize; j++) {
c[i][j] = c[i][j] + a[i][k] * b[k][j];
目前对该程序进行访存优化和向量优化,执行时间由28s降至1.3s。最后用MKL计算库程序执行时间不到0.1s。

添加图片注释,不超过 140 字(可选)
VTUNE QUICK START For HPC
为了能够快速上手分析HPC应用,本章将简化设置以便能够快速上手进行性能分析。这部分以命令行模式为主。本次以Lammps为例。
应用性能快照(APS)
快速获取MPI应用的性能快照:
export APS_STAT_LEVEL=5
mpirun -n NUM aps a.out
生成报告:
aps --report ./aps***** | -O(输出可选,默认在本地目录)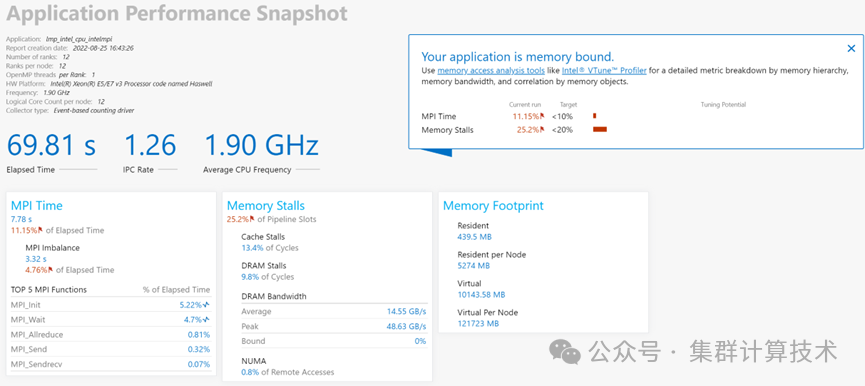
添加图片注释,不超过 140 字(可选)
MPI分析
查看MPI性能指标:aps --report ./aps_result_**** -t。
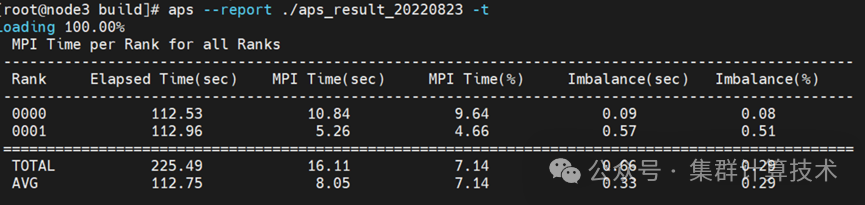
添加图片注释,不超过 140 字(可选)
Performance Snapshot
设置方式:
mpirun -n N vtune --collect performance-snapshot -r <result name> lmp_mpi生成报告:报告有命令行形式也可图形化展示。可将结果目录复制到个人机器上用VTUNE打开.vtune文件,如图9所示。
Vtune/vtune-gui –report summary -r <result name>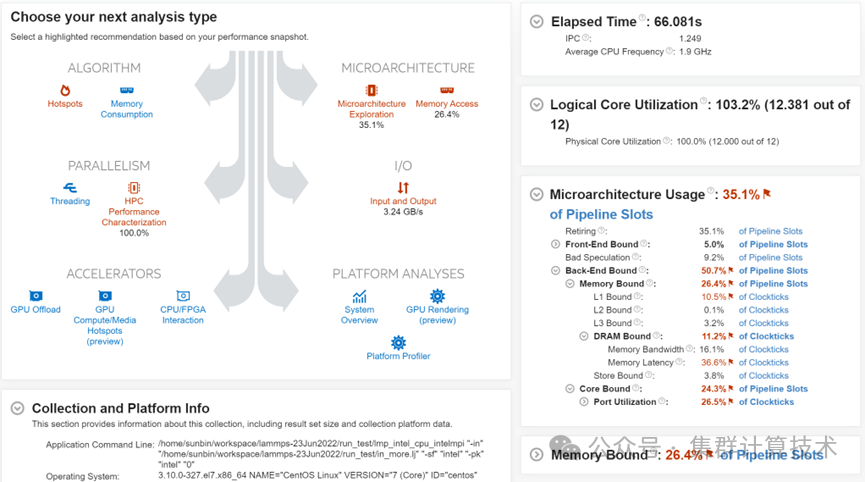
添加图片注释,不超过 140 字(可选)
上面个两种形式的报告都有建议用采用针对HPC应用的分析模式:
mpirun -n N vtune --collect hpc-performance -knob enable-stack-collection=true -knob stack-size=4096 lmp_mpi生成报告:
vtune -report summary -report-knob show-issues=false -r <result> or vtune-gui <result>复制分析文件到本地,总结信息如下图
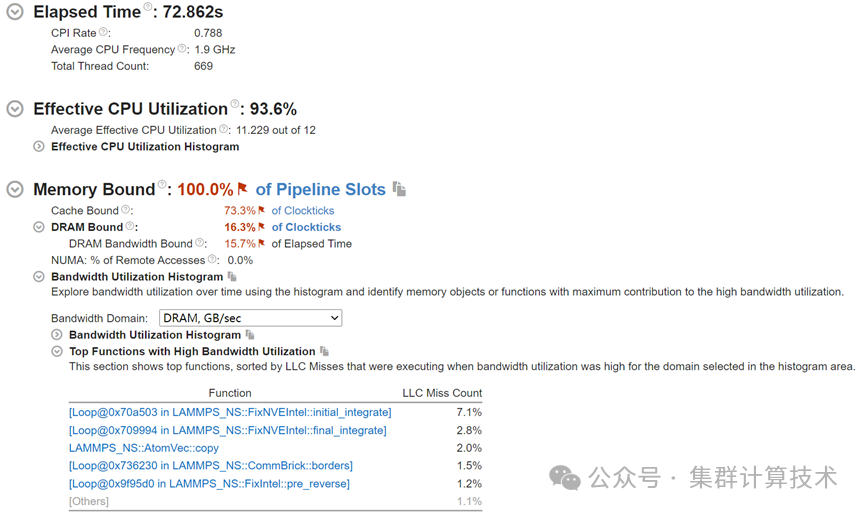
添加图片注释,不超过 140 字(可选)
引用:
-
https://www.intel.com/content/www/us/en/docs/vtune-profiler/user-guide/2023-0/call-stack-mode-002.html
-
https://www.intel.com/content/www/us/en/resources-documentation/developer.html


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









