







 《数据挖掘导论》 学习笔记本文主要是在学习《数据挖掘导论(完整版)》中第1章至第2章的学习笔记,主要用来梳理思路,并没有多少思考,我尽量会在后期多弥补这方面的不足。
《数据挖掘导论》 学习笔记本文主要是在学习《数据挖掘导论(完整版)》中第1章至第2章的学习笔记,主要用来梳理思路,并没有多少思考,我尽量会在后期多弥补这方面的不足。
本文主要是在学习《数据挖掘导论(完整版)》中的学习笔记,主要用来梳理思路,并没有多少思考,我尽量会在后期多弥补这方面的不足。
第1章 绪论
1.1 什么是数据挖掘
KDD: K nowledge D iscovery in D atabase
过程如下:
其中,数据预处理包括如下几部分:
- 特征选择
- 维归约
- 规范化
- 选择数据子集
后处理包括如下及部分:
- 模式过滤
- 可视化
- 模式表达
1.2 数据挖掘要解决的问题
- 可伸缩:着眼于数据量剧烈增长的问题
- 高维性:对象拥有数量不少的属性
- 异种数据和复杂数据:数据来源广泛,且结构复杂(XML格式,文本格式,流格式等)
- 数据的所有权与分布:分布式数据处理
- 非传统的分析:数据挖掘要求自动产生和评估假设,并且数据挖掘数据集多是时机性样本,而非随机性样本
1.4 数据挖掘任务
数据挖掘主要有如下两大类任务:
- 预测任务:根据某些属性来预测另外一些属性的值。其中,用来做预测的属性被称为说明性属性(explanatory variable)或自变量(independent variable),被预测的属性被称为目标变量(target variable)或因变量(dependent variable)
描述任务:导入数据中的潜在的模式,如 相关、趋势、聚类和异常等。更详细的说,有如下几大任务:
预测建模(predictive modeling):以自变量为因变量建立模型,从而使得因变量的预测值与实际值误差越小越好。其中,针对离散性变量的称为分类(classification),针对连续性变量的称为回归(regression)
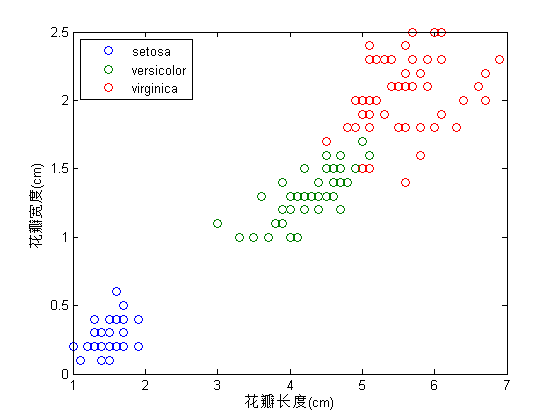
下例为鸢尾花分类,数据集见 Iris_dataset,以下为matlab代码:%% 鸢尾花分类 clear all; close all; clc; %% 载入数据 % data各列分别为 花萼长度,花萼宽度,花瓣长度,花瓣宽度,种类 load iris_dataset; %% 画图 % 花瓣长度 花瓣宽度 与 种类 type1 = data(data(:, 5) == 1, 3:4); type2 = data(data(:, 5) == 2, 3:4); type3 = data(data(:, 5) == 3, 3:4); plot(type1(:, 1), type1(:, 2), 'o', type2(:, 1), type2(:, 2), 'o', type3(:, 1), type3(:, 2), 'o'); xlabel('花瓣长度(cm)'); ylabel('花瓣宽度(cm)'); legend(unique(classes), 'Location', 'NorthWest');- 关联分析(association analysis):用来发现描述数据中强相关的模式
- 聚类分析(cluster analysis) :旨在发现紧密相关的对象群,使得同一簇中的对象尽可能相似,不同簇之间的对象则尽可能相异
- 异常检测(anomaly analysis):识别其属性值明显不同于其他数据的对象,这样对象被称为异常值(anomaly) 或离群点(outlier)
第2章 数据
2.1 数据类型
数据集通常可以看为数据对象的集合。数据对象有时也可以称为记录、点、向量、模式、事件、案例、样本、观测或实体。数据对象由一组刻画对象基本特性的属性描述。属性又可称为变量、特性、字段、特征或者维。
2.1.1 属性和度量
我们给出如下定义:
- 属性(attribute):是对象的性质或特征
- 测量标度(measurement scale):将数值或符号值与对象的属性相关联的规则(函数),如清点教室中的座位数等。
属性的值往往有如下几种性质:
1. 相异性
2. 序
3. 加法
4. 乘法
根据这些性质,可将属性分为四种类型:标称(nominal)、序数(ordinal)、区间(interval)和比率(ratio)
| 属性类型 | 描述 | 例子 | 操作 |
|---|---|---|---|
| 标称 | 标称属性只是用来区别不同对象的 | 邮政编码、学号 | 众数、熵、列联相关、 χ2 检验 |
| 序数 | 序数属性可以确定对象的顺序 | 治疗效果、矿石硬度 | 中值、百分数、秩相关、游程检验、符号检验 |
| 区间 | 区间属性之间的差有意义,即有测量单位 | 日历日期、摄氏度等 | 均值、标准差、皮尔逊相关、 t 和
|
| 比率 | 比率属性的差与比值都有意义 | 绝对温度、质量、长度 | 几何平均、调和平均、百分比变差 |
属性类型可以通过不改变属性的变换来描述,即允许的变换(permissible transformation)
| 属性类型 | 允许的变换 |
|---|---|
| 标称 | 任何一对一的变换 |
| 序数 | 值的保序变换,NewValue = f (OldValue),其中
|
| 区间 | NewValue = a∗ OldValue+ b ,
|
| 比率 | NewValue = a∗ OldValue |
另外根据属性的可能取值,可将属性分为离散的(discrete),连续的(continuous)
对于非对称的属性(asymmetric attribute),出现非零值才重要,考虑如下数据集:每个对象为一个学生,每个属性记录该学生是否选修了某项大学课程
2.1.2 数据集的类型
- 一般特性:维度,稀疏性、分辨率
- 记录数据:事务数据或购物篮数据、数据矩阵、稀疏数据矩阵
- 基于图形的数据:带有对象之间联系的数据(类似图论)、具有图形对象的数据
- 有序数据:时序数据、序列数据、时间序列数据1、空间数据
- 非记录数据
2.2 数据质量
数据挖掘所使用的数据往往是为其他用途收集的,或在收集时没有明确目的的。因而数据的质量往往不高。故数据处理着眼于两方面:(1)数据质量问题的检测与纠正,(2)使用可以容忍低质量数据的算法
2.2.1 测量和数据收集问题
- 测量误差:测量过程中的问题,如系统误差,随机误差等
- 噪声:测量误差的随机部分
- 伪像:数据的确定性失真,如:一组图像在相同的位置出现条纹
- 精度:(同一量的)重复测量值之间的接近程度
- 偏倚:测量值与被测量值之间的系统变差
- 准确度:测量值与实际值之间的接近程度,准确率的一个重要方面是有效数字
- 离群点:离群点与噪音不同,它往往是合法的值,并且可能是人们关注的重点,如:信用卡欺诈、网络进攻等
- 遗漏值:解决方法有 a.删除对象和属性 b.估计遗漏值 c. 在分析时忽略遗漏值
- 不一致的值
- 重复数据:去重复方法解决
2.2.2 关于应用的问题
- 时效性
- 相关性:常见问题有 抽样偏倚2
- 关于数据的背景知识
2.3 数据预处理
数据预处理是为了改善数据挖掘的效果,减少分析时间,降低成本和提高质量。常用技术可以分为两类:(1)选择分析所需要的数据对象, (2)创建/改变属性
2.3.1 聚集
聚集(aggregation) 将两个或多个对象合并成单个对象。考虑如下数据集:一个记录一年中不同日期在不同地区的商店的日销售情况,可以用一个商店事务替换掉该商店的所有事务。
2.3.2 抽样
在数据挖掘中,抽样是因为处理所有数据的费用太高,借助抽样压缩样本量,优化数据挖掘算法的性能。
有效抽样的原理:如果样本是有代表性的,则使用样本与使用整个数据集的效果几乎一样。
常见抽样方法有简单随机抽样,包括有放回抽样、无放回抽样;分层抽样;渐进抽样3。
2.3.3 维归约
当数据集中包含大量特征(属性)时,维归约就愈加显现其好处。其主要的作用是,如果维度较低,许多数据挖掘算法的效果会更好,可以避免维灾难4;并且使得模型更易理解。
维归约的常用方法是使用线性代数技术,将数据从多维空间投影到低维空间,主要技术有 主成分分析(Principal Component Analysis, PCA) 和奇异值分解(Singual Value Decomposition, SVD)。
2.3.4 特征子集选择
通过选择属性集中的部分属性的方法,达到降低维度的目的。当存在冗余特征或不相关特征时,往往并不会损失太多信息,从而也是一种有效的降维方法。由集合论可知, n 个属性有
- 嵌入方法(embedded approach):特征选择作为数据挖掘的一部分存在
- 过滤方法(filter approach):使用某种独立于数据挖掘的方法,在数据挖掘算法运行之前进行特征选择
- 包装方法(wrapper approach):将目标数据挖掘算法作为黑盒,使用类似穷举的方法,但通常并不枚举所有子集
特征子集选择由四部分组成:子集度量评估、控制新的特征子集产生的搜索策略、停止搜索判断和验证过程。过滤方法和包装方法不同在与 子集评估度量 。
另外,除了上述三种特征子集选择的方法,还可以通过 特征加权 来保留或删除特征。
2.3.5 特征创建
常常可以用原有的属性创建新的属性集,更有效地捕获数据集中的重要信息。与之相关的方法有:
- 特征提取(feature extraction):如由相片提取人脸的特征点
- 映射数据到新的空间:如将时间域的变量变换到频率域,参见 傅里叶变换
- 特征构造:由原始属性提取出易于数据挖掘的属性,如根据密度分辨木头金块
2.3.6 离散化和二元化
某些数据挖掘算法只适用于分类属性,此时就需要用到离散化(discretization)或二元化(binarization)
2.3.7 变量变换
变量变换(variable transformation) 是指用于变量的所有值的变换,包括:简单函数变换,标准化(standardization) 或 规范化(normalization)
2.4 相似性和相异性的度量
我们使用邻近度(proximity) 来表示相似度或相异度,对象的邻近度常常是其属性的邻近度的函数。
简单属性的相似度和相异度可以通过下表刻画:
| 属性类型 | 相异度 | 相似度 |
|---|---|---|
| 标称 |
d={
1if(x=y)0if(x≠y)
|
s={
1if(x=y)0if(x≠y)
|
| 序数 |
d=|x−y|
|
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









