







什么是机器学习
利用计算机从历史数据中找出规律,并把这些规律用到对未来不确定性场景的决策
确定性:太阳
不确定性:公司业绩销量
如何解决?规律?从历史数据中挖出来的
1.主体是计算机----机器学习
主体是人----数据分析,效果依赖于人的经验知识水平
机器学习可以看作是框架,算法
2.数据:历史数据
3.规律:从数据中寻找规律,机器学习算法找出的结果规律
算法找出一个数学函数,数学公式
规律落实到程序中:机器学习系统自动生成
从数据中寻找规律
概率论(基石)和统计学
统计学:运算能力的限制,依赖于采样,(样本计算平均值,反作用于整体),描述统计,验证结论是否靠谱(假设检验)
机器学习:单机,集群,不需要抽样,对全量数据处理找规律
预测温度变化,
观察数据,可视化展示发现规律,直观感受(上下波动,总体上升)、
量化做计算比较,用模型刻画(拟合)规律:函数---函数曲线:正确的反应变化特征,寻找模型
维度增高(上百维),无法可视化发现规律,只能用数学模型
函数曲线拟合
机器学习发展的原动力
从历史书籍中找出规律,把这些规律用到对未来自动做出决定
用数据代替专家(网站推荐,业务逻辑,专家根据经验定义规则;用数据告诉规律)
经济驱动,数据变现(大数据概念的出现)
业务系统发展的历史
基于专家经验(运营产品头脑风暴)
基于统计----分维度统计(业务报表)OLAP分析,数据仓库,维度指标,定义规则
机器学习----在线学习
离线机器学习:p处理,晚上根据之前数据跑算法,模型,上线,第二天使用;再生成新模型
存在的问题:电商,双十一大量下单,消费模式与之前不同,离线模式推荐可能很不适合,用当天消费者的行为实时训练模型来推荐
在线学习:在线实时调整模型,用模型对消者指导(电商,百度)
机器学习典型应用
1.关联规则(啤酒和尿布)
购物篮分析:同时购买:捆绑销售,调整货架位置等
算法:关联规则,典型的数据挖掘算法
2.聚类
用户细分精准营销
移动套餐:品牌和用户定位(全球通,动感地带,神州行)
聚类:用户消费数据,运行算法,为用户分类,分析共同的消费特征,业务人员推品牌
3.朴素贝叶斯算法,决策树
垃圾邮件识别
决策树
信用卡欺诈(信贷风险识别(是否放贷:还款能力达不到,是否骗贷))
4.ctr预估和协同过滤
互联网广告,搜索引擎
搜索词条显示顺序
ctr预估,点击率预估,评估用户可能点击的概率排序-----线性逻辑回归
推荐系统
协同过滤
组合购买,
5.自然语言处理,图像识别,图像识别
情感分析,文本,评论
实体识别,提取文章中的人名地名企业名时间,提取文章主干
图像识别
深度学习
6.others
语音识别
个性化医疗
情感分析
人脸识别
自动驾驶
智慧机器人
私人虚拟助理
手势控制
视频内容自动识别
机器实时翻译
数据分析和机器学习的区别
1.数据特点:
交易数据(电商网站:用户下单;银行:用户存取款;电信:用户打电话发信息;跟钱有关的数据)vs行为数据(用户的搜索历史,点击浏览历史,评论)
少量数据vs海量数据
采样分析(交易数据:要求数据的一致性,用户转账,事务来保证)vs全量分析(行为数据:多一批少一批都无所谓(点击数据),不会影响整体分析,提取用户特征)
NOSQL数据库 Not Only SQL数据库,只能用来处理行为数据,分布式,CAP理论(保证吞吐量的前提下对一致性打折扣)
交易型数据:一定用于关系型数据库
2.解决业务问题不同
OLAP(报告历史发生的事)vs预测未来发生的事
过去两年那些用户拖欠贷款vs哪些用户可能会有坏账风险
3.技术手段和方法不同
分析方法:用户驱动(分析师分析)(交互式分析)(数据维度和属性受限)(OLAP工具)(成熟落伍)vs数据驱动(自动进行知识发现)(计算机算法自动计算给出结果)(大量维度属性)(发展阶段,部分已经成熟流行:推荐系统,点击预估)
4.参与者和受众不同
数据分析师(分析师能力决定结果)vs数据+算法(数据质量决定结果)
算法效果差异不悬殊,关键数据质量
服务用户不同:公司高层vs具体用户,个体(推荐产品)
机器学习常见算法和分类
算法分类:
1.对样本数据训练
有监督:训练数据中已经给出每一个样本类别(分类问题:提前打好标签),根据已知的y训练参数:分类算法和回归算法,模型目标训练出的y与已知的尽可能接近
无监督:训练数据没有y,聚类,提前不知道几类
半监督:强化学习,训练越来越好
2.对要解决的问题分类
分类与回归
聚类
标注:文本切分,标注动词形容词名词
3.根据算法的本质*****非常重要(两个算法的本质区别)
分类问题,训练数据模型的方法不同
生成模型:陪审团:给出属于各个类的概率,概率小不意味着不是该类别(模棱两可)
判别模型:法官给出结果:直接有一个函数,数据丢进去,给出类别(武断)
常见算法
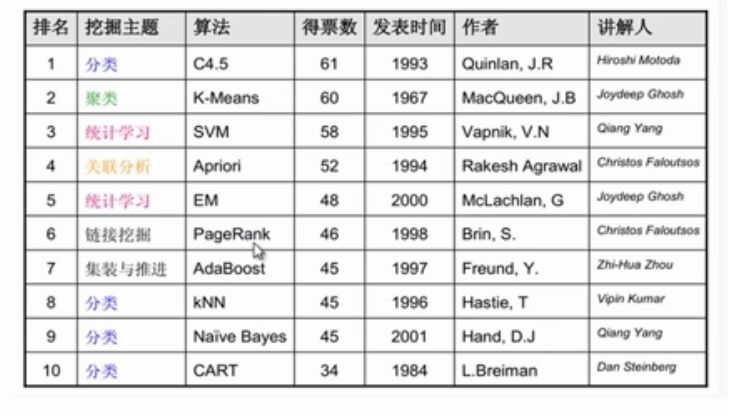
1.决策树
分类 C4.5
CART(不再使用)
2.聚类Kmeans,无监督
3.分类,回归SVM(I曾经推崇的最好的算法),基础统计学习,数学理论****必考,推过程,应用问题,分类问题
4.关联分析Apriori(淘汰的算法,代价高,多次访问数据库,解决频繁项集挖掘),FP-growth,推荐系统解决的就是关联规则的
5.EM算法,统计学习,不是为了解决某一类问题,一个算法的框架
6.PageRank,链接挖掘
7.AdaBoost,集装与推进,决策树改进版,分类分类,人脸识别,有监督
8.KNN分类算法,有监督
9.朴素贝叶斯算法,分类
10.流行算法
FP-growth华人发明
逻辑回归,百度Google推荐,搜索结果排序
RF. GBDT,随机森林,决策树算法的改进
推荐算法,电商网站
LDA,文本分析,自然语言处理
Word2Vector,Google文本挖掘
HMM,CRF隐马尔科夫模型,条件随机场
深度学习
机器学习解决问题的框架
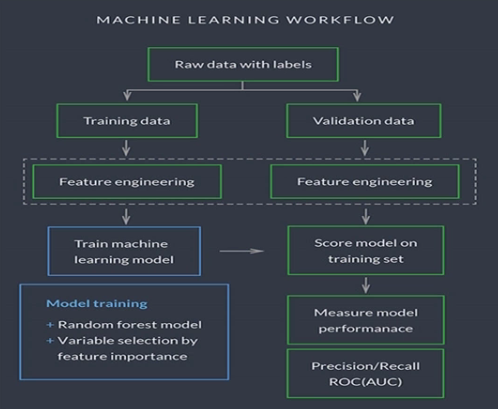
机器学习解决的问题:1,预测(所属分类,数值)(变量是连续型,离散型)2,聚类
解决同一个问题,共同的指导原则和思想
分类问题为例,逻辑回归,svm,随机森林,朴素贝叶斯
区别,共同地方
1.确定目标:
1.1业务需求,解决什么问题,预测产品推荐,预测需求量(滴滴打车天气)
1.2数据,收集历史数据,更精准
1.3特征工程,数据预处理,清晰整合,提取特征(打车需求,天气数据)70%时间精力
2.训练模型
2.1定义模型:回归分类问题,希望得到一个公式,参数是未知的,通过训练数据获得
*2.2定义损失函数:定义预测结果与真实结果的偏差大小,假设得到一个线性回归模型,无法得到精确解,寻找一个近似解,到底哪个模型更适合。针对数据集,只关心绝对值或平方;回归问题:数值预测-真实,分类问题误差评估;评价相似程度(评价模型)
*2.3优化算法:问题如何优化,在损失函数取最小值时,参数是什么;求函数极小值的优化问题;优化问题,凸优化问题,梯度下降等数学问题
3.模型评估
模型是学习的历史经验,验证能否预测未来
3.1交叉验证
3.2效果评估,评估结果报告,指标:准确率,召回率,平均方差
流程:
得到数据raw data with labels 回归分类问题
训练数据 验证数据
特征工程
模型训练结果,迭代,验证
效果评估(调整模型参数,或者特征工程)
机器学习图片识别demo演示
图片按照色彩聚类
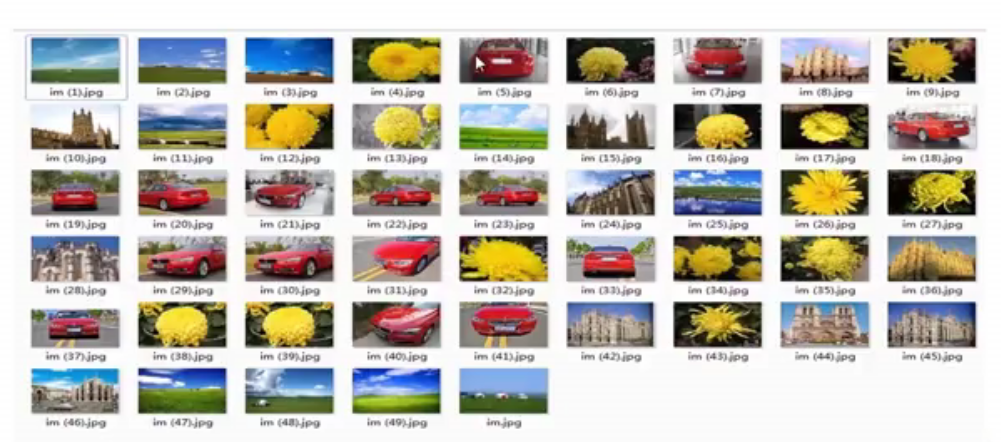
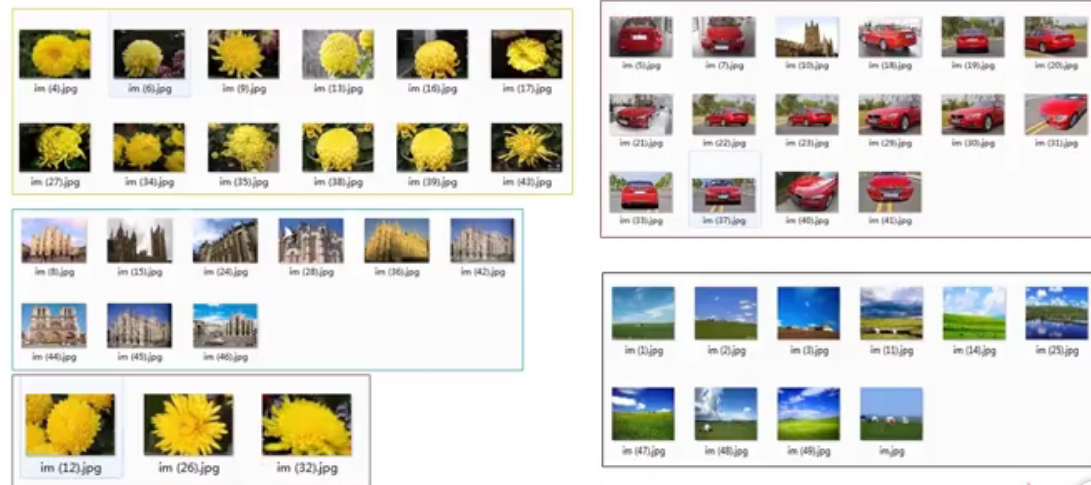
特征工程:图片转换为可以运算的数据流,图片rgb二进制存储转换为可处理的数据格式

rgb转为hls格式(12个数字组成的一个数组或列表或向量),再提取特征
Kmeans聚类,跑结果,调整聚成几类
评价指标,用肉眼观察,看什么时候效果最好















 3421
3421

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









