







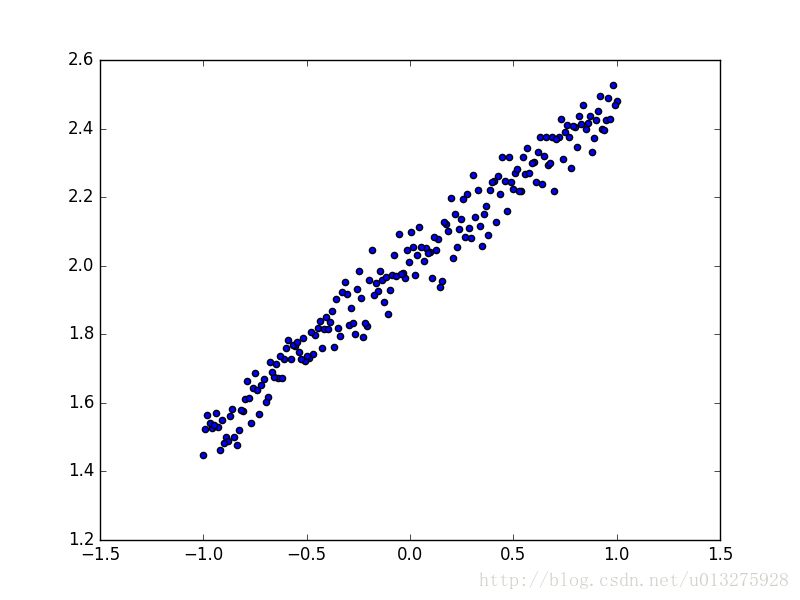
linux平台下运行,使用Keras框架,其中构建神经网络很简单,例子中指构造了一层神经网络
通过深度学习,将图中的点回归成线性模型,学习直线的W和b
#import various of packages
import numpy as np
np.random.seed(1337)
from keras.models import Sequential
from keras.layers import Dense
import matplotlib.pyplot as plt
#create some data
X=np.linspace(-1,1, 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 580
580

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









