







一直在做ocr识别的相关工作。由于兴趣及工作需要,研究优化了下tesseract识别引擎的各个模块。发现关于tesseract引擎国内的资料,对于代码及原理的介绍相对较少,大部分都是应用类的文章,我将看过的代码结合自己的理解介绍识别的各个模块,与大家一起交流学习。
先看下训练时我这边提取到的数字1的MF特征(该特征我是理解为笔画直线中点的坐标,该直线长度及角度等,字提取轮廓后其实就是一条条直线了)
mf 5
0.022858083 0.32230198 0.37753356 0 0 0
-0.16590869 0.11053124 0.42354149 0.25 0 0
-0.25303182 -0.20042329 0.26402926 0.13528861 0 0
-0.064265043 -0.29960707 0.55177981 0.5 0 0
0.21162486 0.011347458 0.62190902 0.75 0 0
X y len dir . . .
下面来看MF特征是如何得到的:
首先定义一些方向的sign 值
Left 0 down 32 right 64 up 96
leftdown 16 downright 48 rightup 80 upleft 112 类似对应45度 刚好8个方向
1:二值化提取出轮廓

轮廓点集 <x,y,dir>由46个点组成
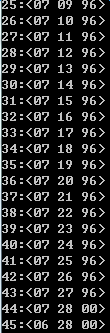
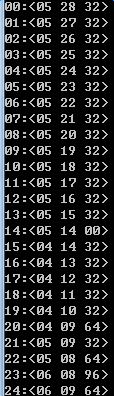
2:去掉同一条直线上的点,以及将直线变平滑(如90度角处理成45度&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3129
3129











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









