







今天参考了《高性能MySQL》与几篇博文,总结一下我个人的对覆盖索引的理解。
首先,覆盖索引并不是一种新的数据结构,它的意思是在查询的时候,利用到的索引已经完全包含需要查询字段的情况,在这种情况下,查询结果直接就是索引的值,并不需要再利用索引回表查询了。
继续拿sakila数据库(MySQL安装好后自带的一个demo数据库)来举例,比如
EXPLAIN SELECT actor_id FROM actor WHERE actor_id = 1;

这里最主要看Extra,它的值为Using index,它在这句查询中含义就是直接访问actor_id这个索引就足已获取到所需要的数据,不需要再通过索引回表查询了。
因为我们使用actor_id(它在actor表里是主键)索引来查字段actor_id,索引的值就是actor_id的值,所以可以说:actor_id在当前查询充当着覆盖索引这个角色。
覆盖索引的好处:
1.索引一般都会远比它所指向的数据行小,如果只需读取索引,那MySQL就能够大大的减少数据访问量。这对缓存的负载也非常重要,因为这种情况下响应时间大部分花费在数据的拷贝上。此外对于I/O密集型(可简单理解为在input和output上花费了大多时间的应用)也有帮助,因为索引比数据更小,可以更快的传入内存中。
2.索引是按照列值来存储的(这里指的是B-Tree索引,并且在单个页内),所以对于I/O密集型的范围查询会比随机从磁盘读取每一行数据的I/O要少得多。
3.一些存储引擎如MyISAM在内存中只缓存索引,数据则依赖于操作系统来缓存,因此要访问数据需要一次系统调用,这可能会影响性能。
4.由于存储引擎InnoDB有聚簇索引(也叫聚集索引),覆盖索引对InnoDB特别有用。InnoDB的二级索引(也成辅助索引)在叶子结点中保存了行的主键值,所以如果二级索引能够覆盖查询,则可以避免对主键索引的二次查询。
对于第4条好处,我们可以在举例子来理清一下,还是actor表:
EXPLAIN SELECT actor_id, last_name FROM actor WHERE last_name = 'HOPPER';
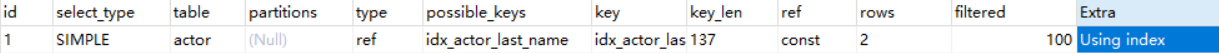
可以看到,我们这次查询了actor_id和last_name两个字段,但条件只用了last_name这个二级索引,Extra的值却也是为Using index。原因是二级索引的叶子结点中会有主键索引(actor_id)值,所以可以理解为这次查询是利用actor_id和last_name这两个索引来查询actor_id和last_name这两个字段,因此它们在这个查询中充当了覆盖索引。
关于覆盖索引就讲这么多了,可能读我这篇文章的人依旧会一脸的懵,在我看来,这主要是因为对数据结构以及一些硬件方面的不熟悉造成的。这里来分享大牛的一篇文章,在看懂索引之前我也是一脸懵啊,相信看完这篇文章再回来就会比较易懂了吧:MySQL索引背后的数据结构及算法原理















 2473
2473

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









