







ABSTRACT
在不同处理系统,应用,图,运行环境下,分区策略选择的问题。没有单个的策略适用于所有环境,实验表明分区策略取决于(1)输入图的度数分布(2)应用程序的类型和持续时间(3)集群大小。
1. INTRODUCTION
现在有各种各样的图,其规模很大,故出现了一些图处理系统,可以编写vertex-program。但在处理大图之前,首先需要对图进行划分。
划分对接下来的计算步骤会产生巨大的影响。为了避免沟通成本一些系统采用“顶点最少”策略。但是如果对沟通成本估计过高,反过来,中间结果补全会耗费更长的时间。除了顶点复制的问题,还需要考虑负载均衡的问题。
图划分操作本身需要快速且有效率。现实世界中的图大多遵循幂律分布,因此有人采用顶点分割的分区技术。

本文的主要贡献:
- 对比三个图处理系统(PowerGraph, GraphX, PowerLyra)中的分区策略。
- 对每个系统提供经验规则帮助开发者找到合适的分区策略。
- 将PowerGraph和GraphX中的分区策略引入到PowerLyra.
- 对比所有系统的所有分区策略,并讨论结果。
分区策略取决于三个要素:(1)输入图的度数分布(2)应用程序的类型和持续时间(3)集群大小。结果表明不同分区策略对处理时间,资源利用率影响很大。
2. SUMMARY OF RESULTS
对于PowerGraph,我们发现对具有低度分布和大直径的图(如路网),基于启发式的策略(即HDRF和Oblivious)表现(ingress&computation)更好。对于重尾分布的图如(社交网络),Grid复制率较低,且ingress时间更短。但是对于幂律分布的图(如UK-web),两个启发式策略得到更高质量的分区(lower replication factors)但ingress时间更长。因此对于幂律图Grid适合短期运行的任务,HDRF/Oblivious适合长期运行的工作。
对于PowerLyra,对于natural的应用程序,混合策略的效果较好。
Natural applications are defined as applications which Gather from one direction and Scatter in the other.
对于GraphX,不同分区策略分区所用时间差不多。Canonical Random works well with low degree graphs, and 2D edge partitioning with power-law graphs.
最后将所有的分区策略在PowerLyra中实现时,决策树并不改变,非对称随机性比随机性更差,最后发现CPU利用率并不适合作为性能的指标。
3. BACKGROUND
3.1 The GAS Decomposition
Pregel模型是以顶点为中心的计算模型,将计算步骤分为多个超步。顶点见通讯通过传递信息的方式实现,被用于Giraph和GraphX系统中。
Gather-Apply-Scatter(GAS)和pregel模型类似是以顶点为中心的计算模型。顶点计算被划分为迭代,每次迭代都包含Gather, Apply and Sactter步骤。Gather——收集相邻边和邻居的信息,并用交换关联聚合器聚合。Apply——接受收集和聚合的数据,更新本地状态。Scatter——使用更新的状态出发相邻顶点值更新并激活它们进行下一次迭代。
3.2 Edge Cuts and Vertex Cuts
切分边缘适用于具有很多低度节点的图。
切分节点适用于具有一些高度节点的图。
(貌似两个环境并不互斥?)
3.3 Graph Applications
3.3.1 PageRank
对图中的顶点进行排序的算法。
3.3.2 Weakly Connected Components
用标签传播识别图形中所有弱连接的组件。
3.3.3 K-Core Decomposition
找到至少为k度节点组成的子图。
3.3.4 SSSP
Single Source Shortest Path.
3.3.5 Simple Coloring
给所有顶点着色,使相邻顶点不具有相同颜色。
4. EXPERIMENTAL METHODOLOGY
4.1 Clusters

对于PowerGraph和PowerLyra,在三个集群上进行了实验:(1)9台机器的本地集群,(2)16台机器的EC2集群(3)25台机器的EC2集群。对于GraphX,使用10台机器的本地集群。
4.2 Datasets
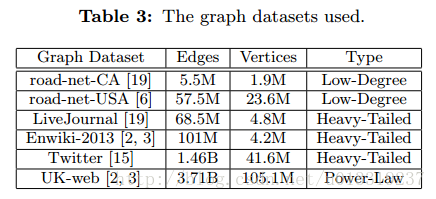
4.3 Metrics
- Ingress time:将图装载入内存的时间
- Computation time:运行特定应用的时间,不包括ingress/partitioning tiome.
- Replication factor:每个顶点的平均镜像数。
- System-wide resource usage:以1s为间隔,测量内存消耗,CPU利用率和网络使用情况。
5. POWERGRAPH
5.1 System Introduction
边缘分割在幂律图中表现不佳,所以采用顶点分割。
5.1.1 Vertex Replication Model
顶点切分会使负载均衡但导致了被切分定点的复制。顶点拷贝的总数和其本身成为顶点的replication factor。
5.1.2 Computation Engine
主要说明GAS的各个步骤在被分割顶点上的实现,以及同步和异步引擎的区别。
5.2 Partition Strategies
5.2.1 Random
对边的hash是它所连接顶点的函数,且不区分方向。随机哈希分区好处有三个:1. 快速。2. 边的分布均匀。3. 高度并行化。但问题在于会产生大量的顶点拷贝。
5.2.2 Oblivious
基于贪心的启发式策略,尽可能降低replication factor。
启发式策略需要为下一个阶段发送先验信息,因此不是并发。同时为了效率,机器之间互相忽视。
5.2.3 Constrained
Constrained partitioning strategies hash edges, but restrict edge placement based on vertex adjacency in order to reduce the replication factor.为每个顶点v附加约束集S(v),然后将边(u,v)置于
S(u)∩S(v)
的分区之一中。
Grid约束是机器v哈希的行和列中所有的机器的集合。
PDS完美差分集生成约束集。
5.2.4 HDRF
High-Degree Replicated First. 和oblivious类似, 但Oblivious只看分区大小,HDRF同时关注顶点的度和分区大小,优先复制高度的节点。
5.3 Experimental Setup
5.4 Experimental Results
5.4.1 Replication Factor and Performance
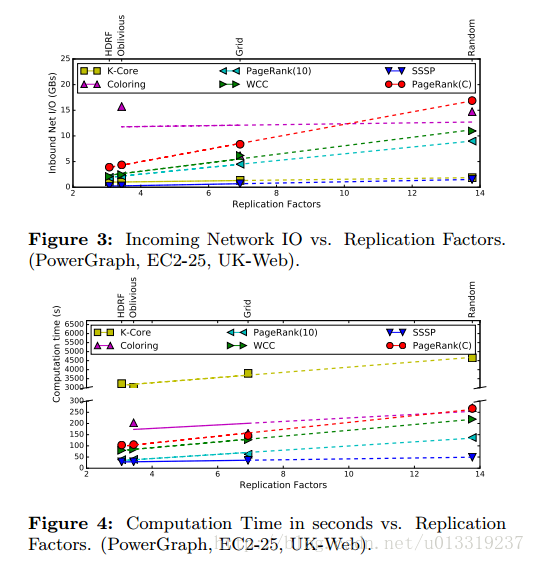
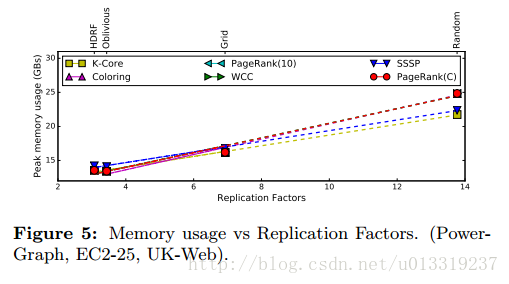
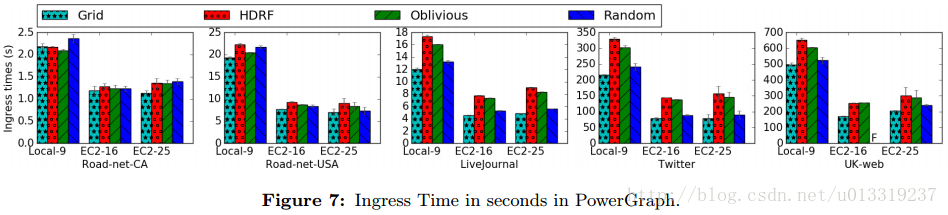
因为着色任务在异步引擎工作,所以有时候会挂起,会花很长时间结束(Oblivious)或者中断(HDRF)。在GAS处理任务时,每一步都与replication factor有关。可以看出replication factor是资源使用的可靠指标,所以用其比较分区策略。图6显示了对于所有图和集群PowerGraph分区策略的replication factor。
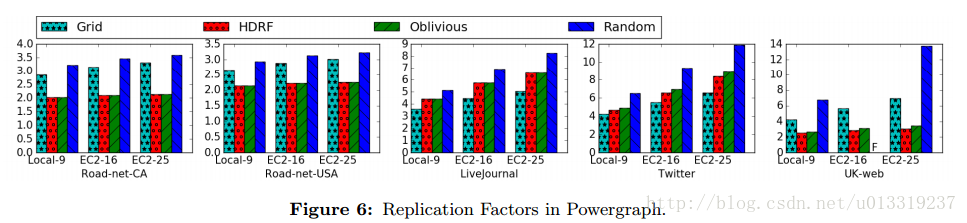
5.4.2 Minimizing Replication Factor
因为LiveJournal和Twitter的低度数据少于UK-web,所以Grid在前两者上面表现最好,而HDRF/Oblivious针对低度图的算法在UK-web表现的最好。所以HRDF/Oblivious适合于幂律图和低度图,Grid适合于重尾图。
5.4.3 Partitioning Quality vs Partitioning Speed
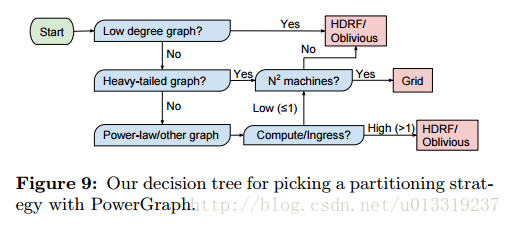
5.4.4 Picking a Strategy
6 POWERLYRA
6.1 System Introduction
PowerLyra一个机遇PowerGraph的图形分析引擎,旨在通过对高度和低度顶点执行差异化处理和分区,进一步解决幂律图中偏斜分布的问题。其作者认为,将顶点切割应用于低度顶点可能会导致高通信和同步成本,对高度顶点应用边缘切割导致负载不平衡和高争用。所以PowerLyra采用混合的方式。提出两种新的策略(1)Hybrid,一种基于随机哈希的策略(2)Hybrid-Ginger,一种基于启发式的策略。
6.2 Partitioning Strategies
包含PowerGraph的策略以及两个混合策略。
6.2.1 Hybrid
Hybrid策略对高度节点实行顶点切分,低度节点实行边切分,并对于有低度目标节点的边哈希目标节点,有高度目标节点的边哈希源节点。
6.2.2 Hybrid-Ginger
和上一个类似但是通过启发式规则比Hybrid中低度节点的复制率更低。
6.3 Experimental Setup
6.4 Experimental Results
7. GRAPHX
7.1 System Introduction
GraphX是基于Apache Spark构建的分布式图形处理框架,可以让用户在利用Spark的数据流功能的情况下执行图形处理。GraphX通过嵌入到Spark中的图形处理API来解决图形计算、复杂的join,以及优化等问题。
GraphX使用Spark中的Resilient Distributed Datasets(RDDs)存储边和点。RDDs通过谱系图进行连接,并支持延迟计算和容错。
7.2 Partitioning Strategies
7.2.1 Random and Canonical Random
两个都哈希顶点ID进行分区,但是Canonical Random对于(u,v)和(v,u)一定分配到同一个分区中,但是Random不一定。这里的Canonical Random类似于5.2.1中的random。
7.2.2 1D Edge Partitioning
哈希源点。和PowerLyra中的6.2.1中Hybrid策略中针对低度节点部分类似。
7.2.3 2D Edge Partitioning
类似5.2.3中PowerGraph中Grid。















 4782
4782

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









