







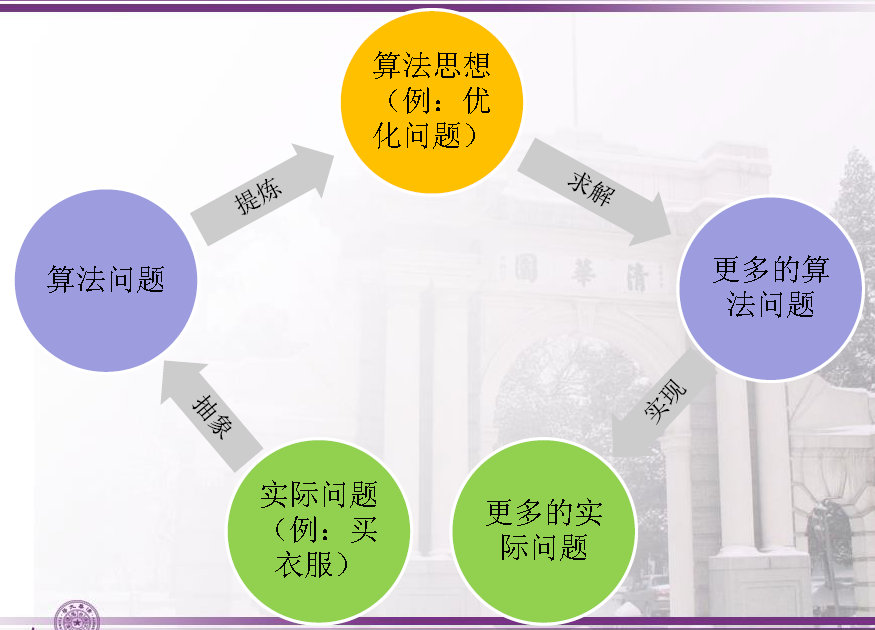
一、 指导思想
1. 核心是分析算法复杂性的方法:基础算法+分析;
2. 解决问题的思路是关键:方法 + 分析 + 应用;
3. 算法无止境: 提升,数学很重要;
4. 算法的应用:系统结构、内存访问、读写操作;
【实例1】:判断n个元素的数组A中是否有某个元素出现超过floor(n/2)次(超过即等于一半或者一半以上), 写出伪代码并分析算法复杂度。
算法一: 比较每个元素,为每个元素计数,复杂度O(n*n)
算法二: 先排序,然后一次扫描计数,复杂度O(n*logn)
算法三: 分治,分两段分别找,合并时扫描计数,算法复杂度O(n*logn)
将数组分为两段,递归地检查每段是否存在某个元素的出现次数大于(n/2):如果两段都存在这样的数,当两者相等时,那么这个数就是所求的数。如果两段所求的结果不相等,那么就分别检查这两个数是否就是我们所求的元素。
代码:
#include <iostream>
#include <fstream>
#include <string>
#include <map>
using namespace std;
int algo(int *A, int low, int high)
{
if(low == high)
return A[low];
int mid = (low + high)/2;
int a1 = algo(A, low, mid);
int a2 = algo(A, mid+1, high);
if(a1 == a2 && a1 != -1)
return a1;
int cnt1 = 0, cnt2 = 0;
for(int i = low; i <= high; i++)
{
if(A[i] == a1)
cnt1++;
if(A[i] == a2)
cnt2++;
}
if(cnt1 >= (high-low+2)/2)
return a1;
if(cnt2 >= (high-low+2)/2)
return a2;
//cout<<"[logic error]"<<endl;
return -1;
}
int main(int argc, char* argv[])
{
int n, A[100];
cin>>n;
for(int i = 1; i <= n; i++)
cin>>A[i];
cout<<"using algo:"<<algo(A, 1, n)<<endl;
return 0;
}
算法四:分治,分两段,只在其中之一找。算法复杂度为O(n)。查找的时候只从一段找,对于值相同的数字尽量都放在同一个段里面。如果存在某个数出现次数超过一半,那么经过part算法之后,必然是存在于较长的一段里面。我们只需要选择较长的一段判断是否存在这样的数。无合并的过程。
int part(int *A, int low, int high)
{
int tmp = A[low];
int i = low, j = high;
//if(A[i] == A[j])
//return 0;
while(i <= j)
{
while(A[j] > tmp)--j;
A[i] = A[j];
while(A[i] <= tmp)++i;
A[j] = A[i];
}
A[j] = tmp;
return j;//返回位置信息
}
int find(int *A, int n)
{
int low = 1, high = n;
while(low < high && high - low > (n+1)/2)
{
int x = part(A, low, high);
if(high - x >= (n+1)/2)
low = x+1;
else if(high - x < (n+1)/2)
high = x;
}
int cnt = 0;
int tmp = A[low];
for(int i = low+1; i <= high; i++)
if(tmp == A[i])
cnt++;
if(cnt >= (n+1)/2)
return tmp;
else
return -1;
}
算法五:利用中位数算法,先找到中位数,再扫描判别中位数的出现次数是否超过一半。如果有超过一半的元素,那么这个元素也一定是中位数。算法复杂度为O(n);
int findK(int *A, int low, int high, int k)
{
int tmp = A[low];
int i = high, j = low;
while(i <= j)
{
while(i <= j && A[i] >= tmp)--i;
A[j] = A[i];
while(i <= j && A[j] <= tmp)++j;
A[i] = A[j];
}
A[i] = tmp;
if(high - i + 1 == k)
return A[i];
else if(high - i + 1 > k)
return findK(A, i+1, high, k);
else if(high - i + 1 < k)
return findK(A, low, i-1, k-high+i-1);
}
int find(int *A, int n)
{
int tmp = findK(A, 1, n, (n+1)/2);
int cnt = 0;
for(int i = 1; i <= n; i++)
if(A[i] == tmp)
cnt++;
if(cnt >= (n+1)/2)
return tmp;
else
return -1;
}
算法六:moore and boyer
第一遍扫描的时候,如果存在总数超过一半的元素,那么最后剩下的这个元素必定为这个元素;
第二遍扫描的时候就统计这个元素出现的次数,如果超过一半,那么就是这个元素,如果这个元素次数不超过一半,那么就不存在这样的元素。
code:
int find(int *A, int n)
{
int p = 0, cnt = 0;
for(i = 1; i <= n; i++)
if(p == A[i])
cnt++;
else if(cnt > 0)
cnt--;
else if(cnt == 0){
cnt++;
p = A[i];
}
cnt = 0;
if(cnt > 0)
{
for(i = 1; i <= n; i++)
if(p == A[i])
cnt++;
if(cnt > n/2)
return p;
}
return -1;
}二、 算法的应用:
1. 算法是求解某个问题的长度有限的指令序列,每条指令都是确定的、简单的、机械的和可知性的。
2. 对于不同的解决方案,分析算法的复杂度。
3. 排序算法考虑的因素:待排数据项数,已经排好的程度,可能的取值范围,采用的存储设备类型。
多项式计算:变元个数、次幂、系数范围等。
4. 评价算法:正确性、简单性、时间复杂性、空间复杂性、是否最优。
5. 时间复杂性归结为操作次数,具体操作次数与问题规模有关
6. 算法效率的比较:
【实例二】多项式乘法的效率
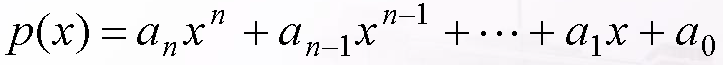
方法一:
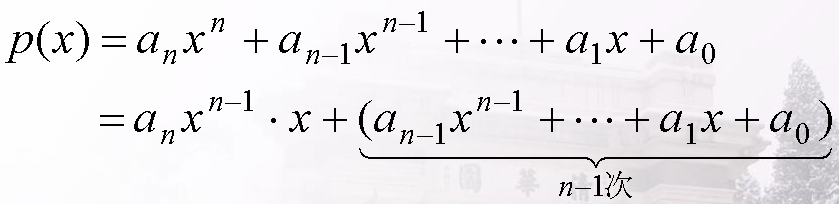
复杂度分析:f(n) = f(n-1) + 2, f(0) = 0, f(1) = 2
f(n) = 2n;
code:
p = a0;
tmp = 1;
for i = 1 to n
tmp = tmp*x;
p = p + ai*x;
end
print p;方法二:
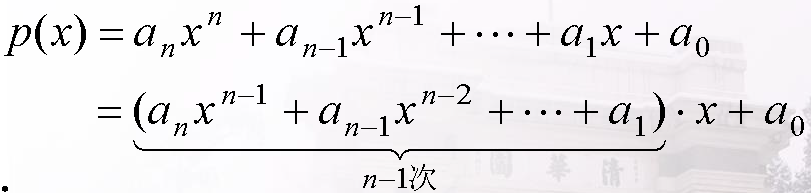
复杂度分析:f(n) = f(n-1) + 1; f(1) = 1;
f(n) = n;
code:
p = an;
for i = 1 to n;
p = p*x + a(n-i)
end
print p;三、 基本概念
1. 正确性:如果一个算对每一个输入实例都能输出正确的结果并停止,则称算法是正确的。
不正确的算法并不都是没用的:近似算法、模拟算法。
2. 可计算性:从理论上判断什么样的问题可以给出算法并利用计算机求解,什么样的问题不可以,属于可计算性理论的研究范围。
3. 算法分析:对一个算法所需要的资源进行预测,如内存、带宽、硬件、时间。
4. 计算模型:哥德尔的递归函数、丘奇的伽马演算、波斯特的波斯特机、图灵的图灵机、RAM模型。
在可解层次上,这些模型都是等效的。
5. 单处理器随机存取模型(RAM模型)
1)指令顺序执行;
2)算数指令、数据移动指令、控制指令;
3)数据类型:整数类型、浮点实数类型;
4)不考虑存储层次建模:高速缓存和虚拟内存;















 437
437











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









