







Probabilistic Latent Semantic Indexing(PLSI/PLSA)是常用的话题模型之一,他通过生成模型来模拟文档的产生过程,然后用Maximum likelihood的方法估计模型中未知参数的值,来获取整个生成模型中的参数值,从而构建起整个生成模型。
一、 基本概念
1. SVD奇异值分解:SVD主要用来求低阶近似问题。当给定一个MXN的矩阵C时(其秩为r),我们希望找到一个近似矩阵C‘(其秩不大于k),当k远小于r时,我们称C’为C的低阶近似,设X = C - C'为两个矩阵的差,X的F-范数为:

SVD计算步骤:
a、 给定一个矩阵C,对其奇异值进行分解:C = U ∑ V
b、 构造∑ ‘, 其秩为k,选择将∑ 中奇异值最小的r-k个值置为0,即得到∑ ’
c、 计算C‘ = U ∑’ V
因为特征值大小对矩阵和向量乘法的影响大小成正比,而奇异值和特征值也是成正比,因而选择最小的r-k个奇异值置为0 是合理的。
2. PCA主成分分析:PCA试图在丢失数据信息最少的情况下,对多维的数据进行最优综合简化,对高维的变量空间进行降维处理。
PCA计算步骤:
a、 首先计算训练样本的均值和协方差矩阵:

b、 对协方差矩阵进行特征值分解:
c、 选择前k个最大的特征值对应的特征向量作为主成分分量,这些分量构成特征空间,我们就得到变换矩阵
对任何一条数据X,通过如下变化,将其转化到新的特征空间中的向量y:
3. TF-IDF:
首先介绍TF-term frequency,它用来度量 一个单词在一个文档中出现的频率。由于不同的文档长短不同,为了防止TF偏向于长文件,通常对词频进行归一化处理。
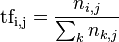
通常一个文档中如果某个词出现的频率较高,可以认为这个文档和这个词的相关性比较高,但是,如果所有的文档都含有这个词&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3174
3174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









