







目录
代码(预测从点击到转化的概率,需要两个网络,一个是ctr网络(点击为正样本,不点击为负样本),一个是CTCVR网络(下单为正样本,其他为负样本)
GitHub - busesese/ESMM: esmm model by tensorflow keras
范式二:MMoE替换hard parameter sharing (任务之间有差异性) 谷歌 每个任务一个门控网络,共享专家网络,有几个任务就有几个门控网络,门控网络类似于attention机制
范式一:任务序列依赖模型(ESMM,全空间多目标模型) 不同任务之间有相似性 阿里,
在推荐系统中不同任务之间通常存在一种序列依赖关系。例如,电商推荐中的多目标预估经常是CTR和CVR,其中转化这个行为只有在点击发生后才会发生。这种序列依赖关系其实可以被利用,来解决一些任务预估中存在的样本选择偏差(Sample Selection Bias,SSB)和数据稀疏性(Data Sparisity,DS)问题。因此提出Entire Space Multi-Task Model(ESMM)。
简单介绍一下什么是SSB问题和DS问题。SSB问题:后一阶段的模型基于上一阶段采样后的样本子集进行训练,但是最终在全样本空间进行推理,带来严重的泛化性问题。DS问题:后一阶段的模型训练样本通常远小于前一阶段任务。
ESMM模型首次把样本空间分成了三大部分,从曝光到点击再到转化的三步行为链,并引入了浏览转化率(pCTCVR)的概念。我们正常做CVR任务的时候,默认只在点击的空间上来做,认为曝光、点击并转化了就是正样本,曝光、点击并未转化为负样本。如果这样想的话,样本全空间只有点击的样本,而没有考虑到未点击的样本。ESMM论文就提出曝光点击、曝光不点击以及点击之后是否转化所有的这些样本都考虑进来,提出三步的行为链如下公式


模型主要有一个双塔的形式分别构建user和item相关的特征,然后进行embedding和拼接,最终输出到各个task的NN网络中进行学习,整体结构非常简单清晰,这里不一一细说。主要强调几个需要注意和可以优化的点:
- user filed和item filed侧的特征如何融合,图上写的比较模糊,这里我的理解为:分别对user的每个特征进行向量化,例如类别特征直接embedding为一个向量,序列特征需要进行融合成为一个embedding(具体融合可以自己定义实验,如:maxpool,avgpool,sum都可以尝试),然后各个特征embedding在进行element-wise级别的加和操作,可以得到一个用户信息的整体embedding,item相关的信息处理类似,这里我们需要注意的是其中是没有考虑一些numeric特征的,如果有numeric特征我们需要在concatenate layer进行拼接上去
- 模型的训练的实际loss = loss_{ctr} + loss_{ctcvr}论文中加号右半部分写的是loss_{ctr}*loss_{cvr}这个容易让人搞混,因为实际上在整个样本空间上CVR是没有办法进行训练的,所以cvrloss根本计算不了,因为给定的输入数据是全样本空间即曝光数据,所以从曝光到点击的数据是CTR,从曝光到购买的数据是CTCVR这一点需要理解清楚;
- 可以尝试优化的点:1. 序列特征的处理技巧,attention等的加入;2. loss的加权方式需要根据实际训练结果调整,因为不同任务的正负样本不一致,因此每个任务的loss都不一样,如果两个loss数量级差距很大,较大的loss会主导loss的优化,导致数量级较小的那个loss训练不充分;
-
实现这个模型的时候怎么训练,损失函数怎么写,数据怎么构造?
这里我们可以看到主任务是CVR任务,副任务是CTR任务,实际生产的数据是用户曝光数据,点击数据和转化数据,那么曝光和点击数据可以构造副任务的CTR模型,曝光和转化数据(转化必点击)构造的是CTCVR任务,模型的输出有3个,CTR模型输出预测的pCTR,CVR模型输出预测的pCVR,联合模型输出预测的pCTCVR=pCTR*pCVR,由于CVR模型的输出标签不好直接构造,因此这里损失函数loss = ctr的损失函数 + ctcvr的损失函数,因为pctcvr=pctr*pcvr所以loss中也充分利用到CVR模型的参数
这就是浏览转化率公式,并提出了上图所示的网络模型,一个双塔模型,它们是共享底层Embedding的,只是上面的不一样,一个用来预测CVR,这个可以在全样本空间上进行训练,另一个是用来预测CTR,CTR是一个辅助任务。最后的pCTCVR可以在全样本空间中训练。ESMM模型是一个双塔、双任务的模式在全样本空间上进行训练。这样训练的好处可以解决两个问题:一是,样本选择的问题,CVR是在点击的基础上进行训练,训练集只有点击的,实际数据可能有曝光点击和曝光未点击的数据,我们往往把曝光未点击的数据给忽略了,这样就造成了样本选择偏差,训练集和实际数据分布不一致的情况。二是,解决数据稀疏的问题。因为我们现在在全样本空间上进行训练,不是只在点击的样本上进行训练,所以样本就多了很多,所有样本可以进行辅助更新CVR网络中的Embedding,这样Embedding向量就会训练的更加充分。ESMM还提出子网络MLP可以替换,为我们提供了一种可扩展的多任务模型架构。
ESMM是一种较为通用的任务序列依赖关系建模的方法,除此之外,阿里的论文《Deep Bayesian Multi-Target Learning for Recommender Systems》中提出DBMTL模型 、《Entire Space Multi-Task Modeling via Post-Click Behavior Decomposition for Conversion Rate Prediction》中提出 模型,这些工作都属于任务序列依赖这一模式。
代码(预测从点击到转化的概率,需要两个网络,一个是ctr网络(点击为正样本,不点击为负样本),一个是CTCVR网络(下单为正样本,其他为负样本)
代码:这个代码太好懂了,感谢分享
GitHub - busesese/ESMM: esmm model by tensorflow keras
ESMM模型有两个主要的特点:
- 在整个样本空间建模。区别与传统的CVR预估方法通常使用“点击->成交”事情的日志来构建训练样本,ESMM模型使用“展现->点击->成交”事情的日志来构建训练样本。
- 共享特征表示。两个子任务(CTR预估和CVR预估)之间共享各类实体(产品、品牌、类目、商家等)ID的embedding向量表示。
ESMM模型的损失函数由两部分组成,对应于pCTR 和pCTCVR 两个子任务,其形式如下:
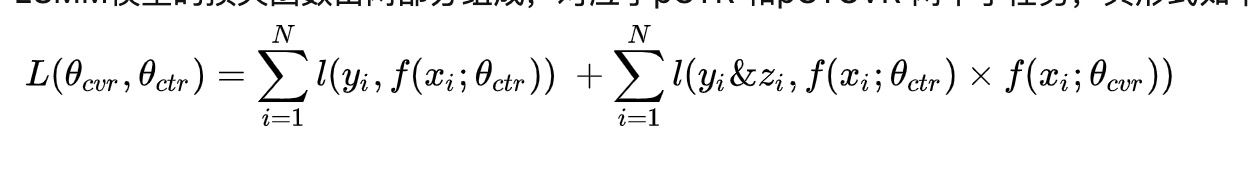
在CTR任务中,有点击行为的展现事件构成的样本标记为正样本,没有点击行为发生的展现事件标记为负样本;在CTCVR任务中,同时有点击和购买行为的展现事件标记为正样本,否则标记为负样本。
范式二:MMoE替换hard parameter sharing (任务之间有差异性) 谷歌 每个任务一个门控网络,共享专家网络,有几个任务就有几个门控网络,门控网络类似于attention机制
阿里团队提出 ESMM 模型利用多任务学习的方法极大地提升了 CVR 预估的性能,同时解决了传统 CVR 模型预估的一些弊病。我们从模型的网络结构可以了解到,ESMM 是典型的 share-bottom 结构,即底层特征共享方式。这种多任务学习共享结构的一大特点是在任务之间都比较相似或者相关性比较大的场景下能带来很好的效果,而对于任务间差异比较大的场景,这种多任务学习共享结构就有点捉襟见肘了。
说到底,多任务学习的本质就是共享表示以及相关任务的相互影响。通常,相似的子任务也拥有比较接近的底层特征,那么在多任务学习中,他们就可以很好地进行底层特征共享;而对于不相似的子任务,他们的底层表示差异很大,在进行参数共享时很有可能会互相冲突或噪声太多,导致多任务学习的模型效果不佳。
实际的应用场景中,我们可能不止有像 CTR、CVR 这样的非常相关的子任务,还会遇到子任务间关系没那么紧密的多任务学习场景,而且很多情况下,你很难判断任务在数据层面是否是相似的。所以多任务学习如何在相关性不高的任务上获得好效果是一件很有挑战性也很有实际意义的事,这也是本小节所提到的模型 “MMoE” 主要解决的问题。
其实在 MMoE之前,已经有一些其他结构来解决这个问题了,比如两个任务的参数不共用,而是对不同任务的参数增加 L2 范数的限制;或者对每个任务分别学习一套隐层然后学习所有隐层的组合。这些结构和 Shared-Bottom 结构相比,其构成的模型会针对每个任务添加更多参数以适应任务间差异,虽然能够带来一定的效果提升,但是增加了更多的参数也就意味着需要更大的数据样本来训练模型,而且这些方法会使模型变得更复杂,也不利于在真实生产环境中部署使用。相关内容在MMoE论文中的“2.1 Multi-task Learning in DNNs”小节中有提到,想详细了解可以看论文中给出的引用文章。
MMoE(Multi-gate Mixture-of-Experts) 是 Google 在 2018 年 KDD 上发表的论文《Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts》里提出的,它是一种新颖的多任务学习结构。MMoE 模型刻画了任务相关性,基于共享表示来学习特定任务的函数,避免了明显增加参数的缺点。广义上MMoE方法是Soft parameter sharing的一种。在这篇论文发表前,还有个MoE模型(Mixture-of-Experts),下面先介绍MoE模型。
MoE模型
早在 2017 年,谷歌大脑团队的两位科学家:大名鼎鼎的深度学习之父 Geoffrey Hinto 和 谷歌首席架构师 Jeff Dean 在发表论文《Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer》中提出了 “稀疏门控制的混合专家层”(Sparsely-Gated Mixture-of-Experts layer,MoE),这里的 MoE 是一种特殊的神经网络结构层,结合了专家系统和集成思想在里面。
MoE 由许多 “专家” 组成,每个 “专家” 都有一个简单的前馈神经网络和一个可训练的门控网络(gating network),该门控网络选择 “专家” 的一个稀疏组合来处理每个输入,它可以实现自动分配参数以捕获多个任务可共享的信息或是特定于某个任务的信息,而无需为每个任务添加很多新参数,而且网络的所有部分都可以通过反向传播一起训练。MoE 结构图如下所示: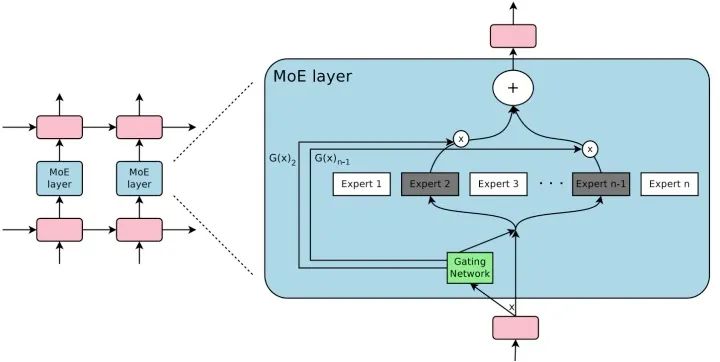 MoE 可以作为一个基本的组成单元,也可以是多个 MoE 结构堆叠在一个大网络中。比如一个 MoE 层可以接受上一层 MoE 层的输出作为输入,其输出作为下一层的输入使用。在谷歌大脑的论文中,MoE 就是作为循环神经网络中的一个循环单元。
MoE 可以作为一个基本的组成单元,也可以是多个 MoE 结构堆叠在一个大网络中。比如一个 MoE 层可以接受上一层 MoE 层的输出作为输入,其输出作为下一层的输入使用。在谷歌大脑的论文中,MoE 就是作为循环神经网络中的一个循环单元。
MoE 神经网络结构有两个非常明显的好处:
(1)实现一种多专家集成的效果。
MoE 的思想是训练多个神经网络(也就是多个专家),每个神经网络(专家)通过门控网络(Gating NetWork)被指定应用于数据集的不同部分,最后再通过门控网络将多个专家的结果进行组合。单个模型往往善于处理一部分数据,不擅长处理另外一部分数据(在这部分数据上犯错多),而多专家系统则很好的解决了这个问题:系统中的每一个神经网络,也就是每一个专家都会有一个擅长的数据区域,在这组区域上该专家就是 “权威”,要比其他专家表现得好。因此多专家系统是单一全局模型或者多个局部模型的一个很好的折中,这样的网络结构能够处理更加复杂的数据分布,在相应的任务中,性能也会有很大的提升。
(2)只需增加很小的计算力,便能高效地提升模型的性能。
神经网络吸收信息的能力受其参数数量的限制。有人在理论上提出了条件计算(conditional computation)的概念,作为大幅提升模型容量而不会大幅增加计算力需求的一种方法。MoE 就是条件计算的一种实现,并在论文中证实,这种网络结构可实现在计算效率方面只有微小损失情况下,可以显着提高性能。
MMoE模型
有了以上信息,我们就很容易理解为什么要将 MoE 引入多任务学习中了,因为多专家集成的机制刚好可以用来解决多任务间的差异问题,并且还不会带来很大计算损耗。
-
Shared-Bottom Multi-task Model 多任务学习(Multi-Task Learning,MTL)中最经典的 Shared-Bottom DNN 网络结构,如下图所示:
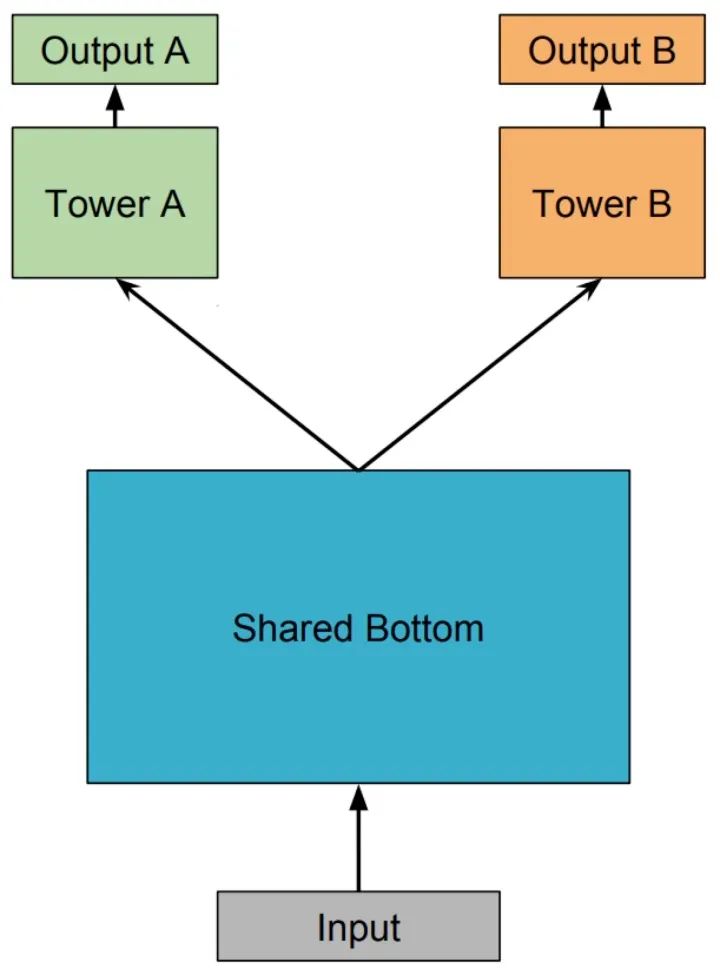
Shared-Bottom 网络通常位于底部,表示为函数 ,多个任务共用这一层。往上,个子任务分别对应一个 tower network,表示为 ,每个子任务的输出 。
-
One-gate MoE model
用一组由专家网络(expert network)组成的神经网络结构来替换掉 Shared-Bottom 部分(函数 ),这里的每个 “专家” 都是一个前馈神经网络,再加上一个门控网络,就构成了 MoE 结构的 MTL 模型。因为只有一个门网络,所以在论文中,为了与 MMoE 对应,也称这种结构为 OMoE(One-gate Mixture-of-Experts),其结构如下图所示:
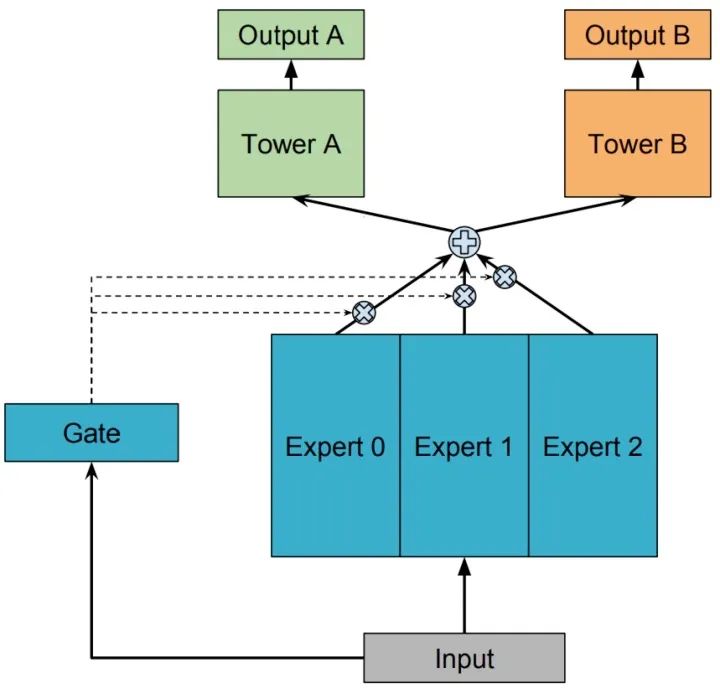
MoE 模型可以形式化表示为:
其中, 是 个expert network(expert network可认为是一个神经网络), 是组合 experts 结果的门控网络(gating network), ,具体来说 产生 个 experts 上的概率分布,最终的输出是所有 experts 的带权加和。显然,MoE 可看做基于多个独立模型的集成方法。这里注意MoE只对应上图中的一部分,我们把得到的带权结果 输入到子任务分别对应的tower network中进行学习。上文中也提到了有些文章将MoE作为一个基本的组成单元,将多个MoE结构堆叠在一个大网络中。比如一个MoE层可以接受上一层MoE层的输出作为输入,其输出作为下一层的输入使用。
-
Multi-gate MoE model
知道了 OMoE 结构,那么 MMoE(Multi-gate Mixture-of-Experts)的结构就很容易猜出来了,通过名字里的 Multi-gate 很容易想到,MMoE 就是在 OMoE 的基础上,用了多个门控网络,其核心思想是将shared-bottom网络中的函数 替换成MoE层,结构如下图所示:
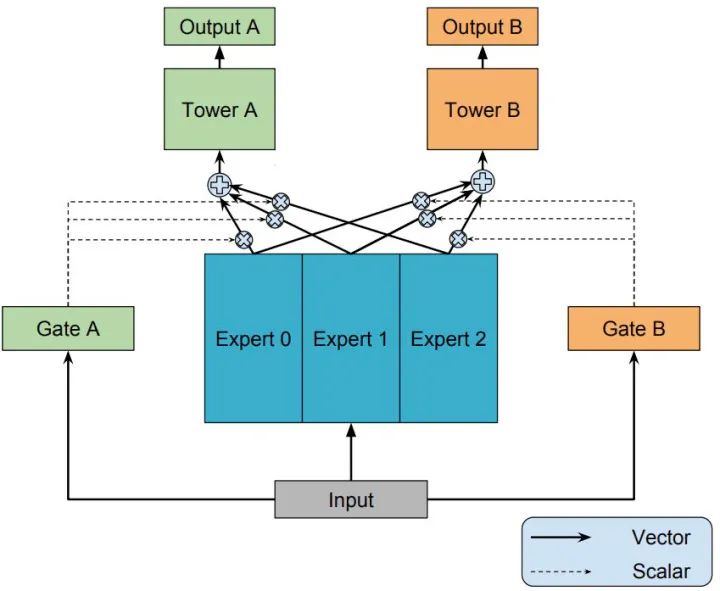
MMoE 可以形式化表达为:
其中, 是第 个任务中组合 experts 结果的门控网络(gating network),注意每一个任务都有一个独立的门控网络。 ,它的输入是 input feature,输出就是所有 Experts 上的权重。 是 个专家(expert)网络。
一方面,因为gating networks通常是轻量级的,而且expert networks是所有任务共用,所以相对于论文中提到的一些baseline方法在计算量和参数量上具有优势。
另一方面,MMoE 其实是 MoE 针对多任务学习的变种和优化,相对于 OMoE 的结构中所有任务共享一个门控网络,MMoE 的结构优化为每个任务都单独使用一个门控网络。这样的改进可以针对不同任务得到不同的 Experts 权重,从而实现对 Experts 的选择性利用,不同任务对应的门控网络可以学习到不同的 Experts 组合模式,因此模型更容易捕捉到子任务间的相关性和差异性。
维度分析:k是任务数

代码
MMOE 多任务学习模型介绍与源码浅析
范式三 腾讯 at RecSys2020最佳长论文 - 多任务学习模型PLE(不同任务在共享Expert上的权重是有较大差异的,其针对不同的任务,能够有效利用共享Expert和独有Expert的信息,每个任务有自己独有的专家网络,并且可以是多层MTL)
无论是MMoE还是ML-MMoE,不同任务在三个Expert上的权重都是接近的,这其实更接近于一种Hard Parameter Sharing的方式,但对于CGC&PLE来说,不同任务在共享Expert上的权重是有较大差异的,其针对不同的任务,能够有效利用共享Expert和独有Expert的信息,这也解释了为什么其能够达到比MMoE更好的训练结果。
单层网络多任务模型,多层网络多任务模型,类似于多隐层,只不过隐层的的基础单元是神经元结点,这个的多层,每层都是一个神经网络


代码
 https://github.com/scalaboy/MutiTaskLearning
https://github.com/scalaboy/MutiTaskLearning参考文献
ESMM
多目标学习在推荐系统中的应用 (本文非常好,里面有很多链接,可以学习)
腾讯 at RecSys2020最佳长论文 - 多任务学习模型PLE














 1839
1839











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









