







运行效果动图:
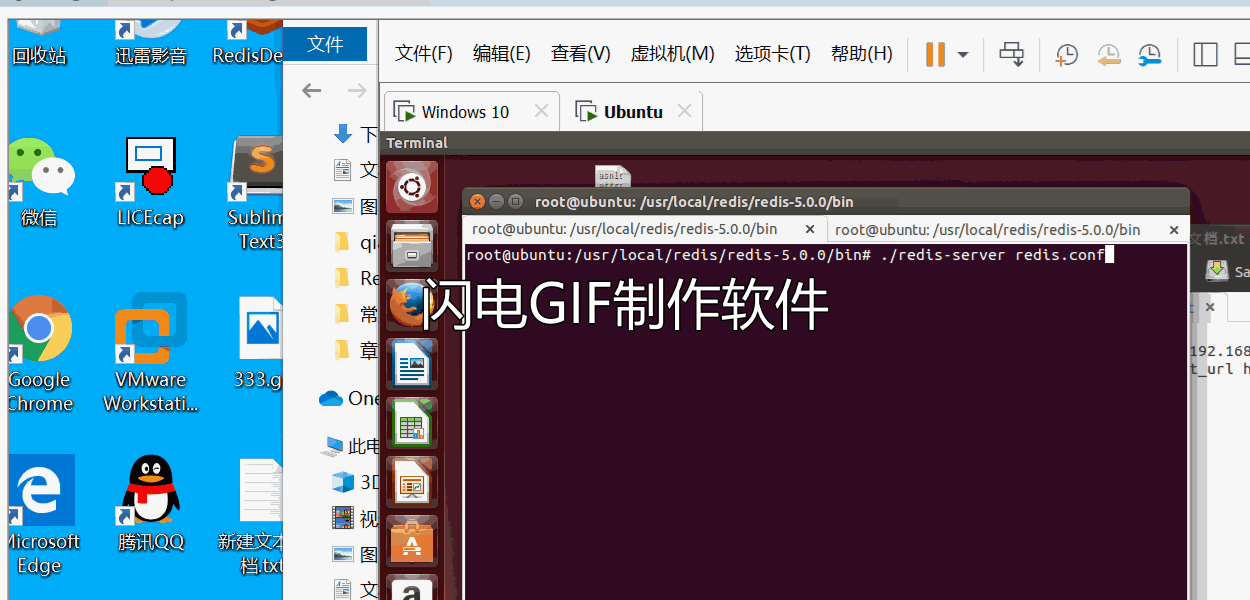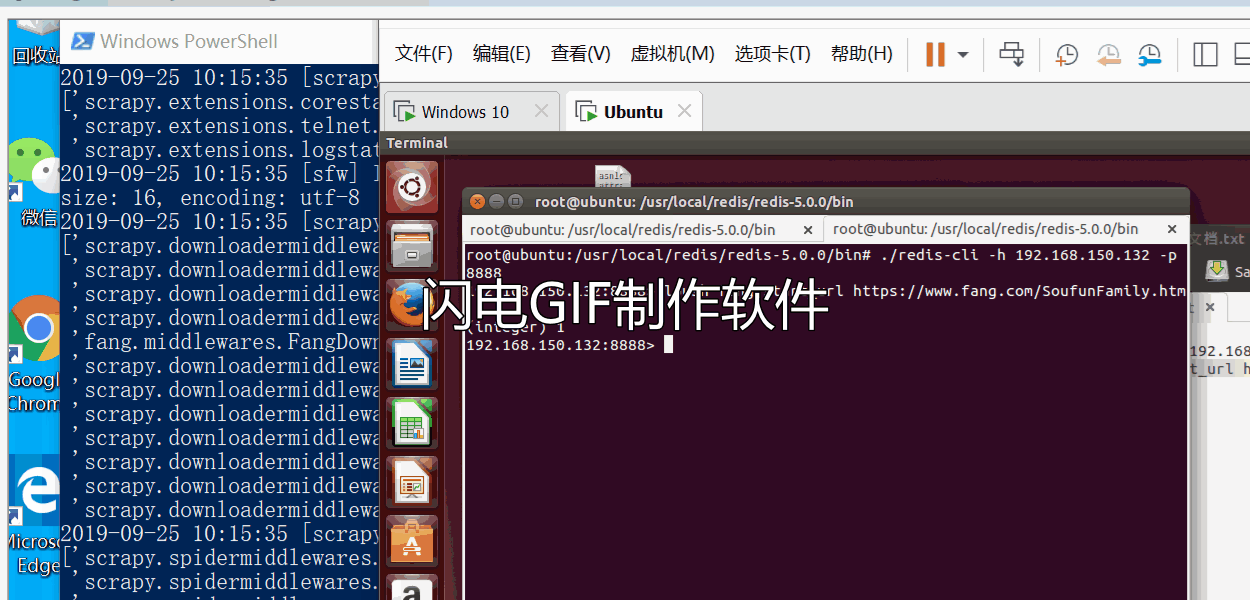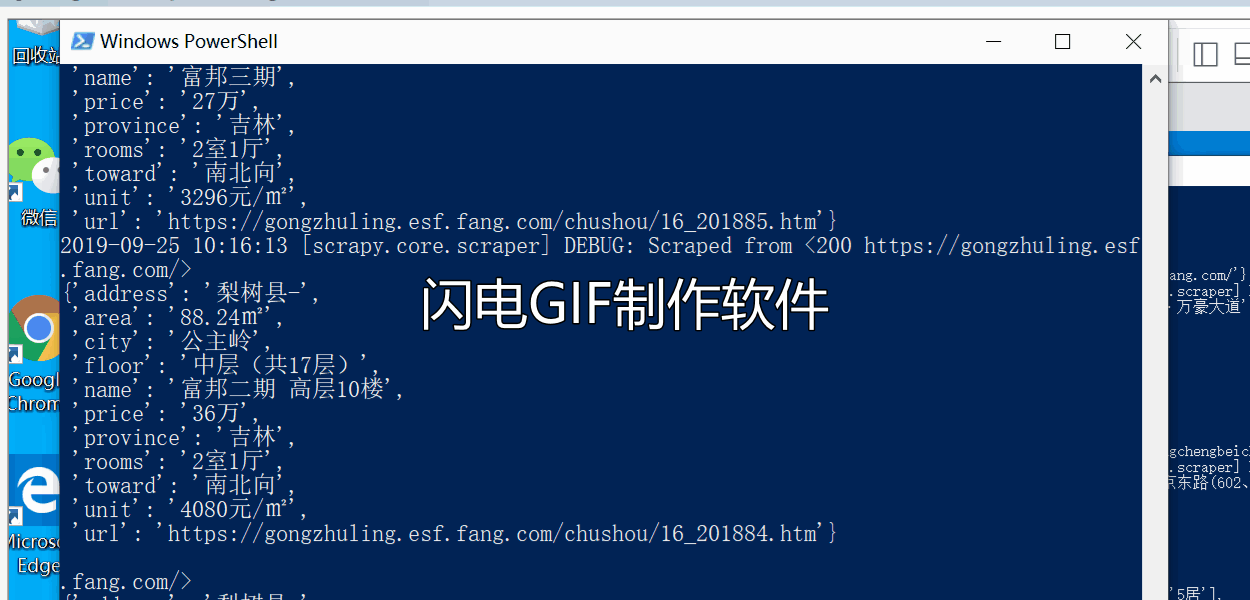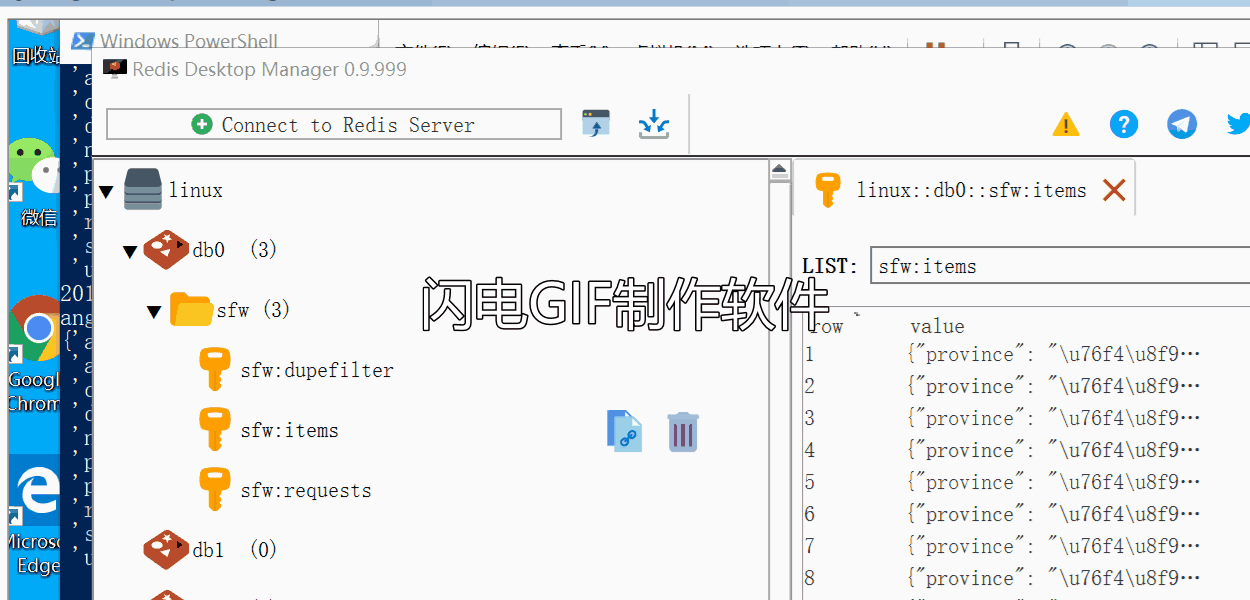
简述:本案例中有一台Linux系统运行Redis服务器,两台Windows系统跑分布式爬虫。爬虫从Redis队列中得到要爬取的URL,同时redis负责队列中URL的去重以及爬虫因某些原因暂停或者终止时,下次开启爬虫自动继续上次未完成的URL继续爬取,不会重头开始爬,当爬虫爬空Redis中的URL时,就会处于等待状态,次数可以设置等待一段时间,如果队列中还是没有新增要爬取的URL就自动关闭爬虫,避免爬虫一直处于等待状态而占用资源。
sfw.py
import scrapy
import re
from fang.items import NewHouseItem, OldHouseItem
from scrapy_redis.spiders import RedisSpider
class SfwSpider(RedisSpider):
name = 'sfw'
allowed_domains = ['fang.com']
# start_urls = ['https://www.fang.com/SoufunFamily.htm']
redis_key = 'fang:start_url'
def parse(self, response):
trs = response.xpath("//div[@class='outCont']//tr")
province = None
for tr in trs:
tds = tr.xpath(".//td[not(@class)]")
province_td = tds[0]
province_text = province_td.xpath(".//text()").get()
province_text = re.sub(r'\s', '', province_text)
if province_text:
province = province_text
if province == '其它':
continue
city_td = tds[1]
city_links = city_td.xpath(".//a")
for city_link in city_links:
city = city_link.xpath(".//text()").get()
city_url = city_link.xpath(".//@href").get()
# print("省份", province)
# print("城市", city)
# print("城市链接", city_url)
url_module = city_url.split("//&# 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1002
1002











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









