







 本文详细介绍了如何搭建Scrapy-Redis分布式爬虫,包括背景、环境配置、工作原理、运行流程及环境安装与代码编写。通过对比scrapy和Scrapy-redis的架构,阐述了Scrapy-Redis如何利用Redis实现分布式策略,强调了Master和Slaver的角色以及任务调度。文章还提及了可能存在的效率和存储空间问题。
本文详细介绍了如何搭建Scrapy-Redis分布式爬虫,包括背景、环境配置、工作原理、运行流程及环境安装与代码编写。通过对比scrapy和Scrapy-redis的架构,阐述了Scrapy-Redis如何利用Redis实现分布式策略,强调了Master和Slaver的角色以及任务调度。文章还提及了可能存在的效率和存储空间问题。
scrapy-redis分布式爬虫的搭建过程(理论篇)
1. 背景
- Scrapy 是一个通用的爬虫框架,但是不支持分布式,Scrapy-redis是为了更方便地实现Scrapy分布式爬取,而提供了一些以redis为基础的组件(仅有组件)。
2. 环境
- 系统:win7
- scrapy-redis
- redis 3.0.5
- python 3.6.1
3. 原理
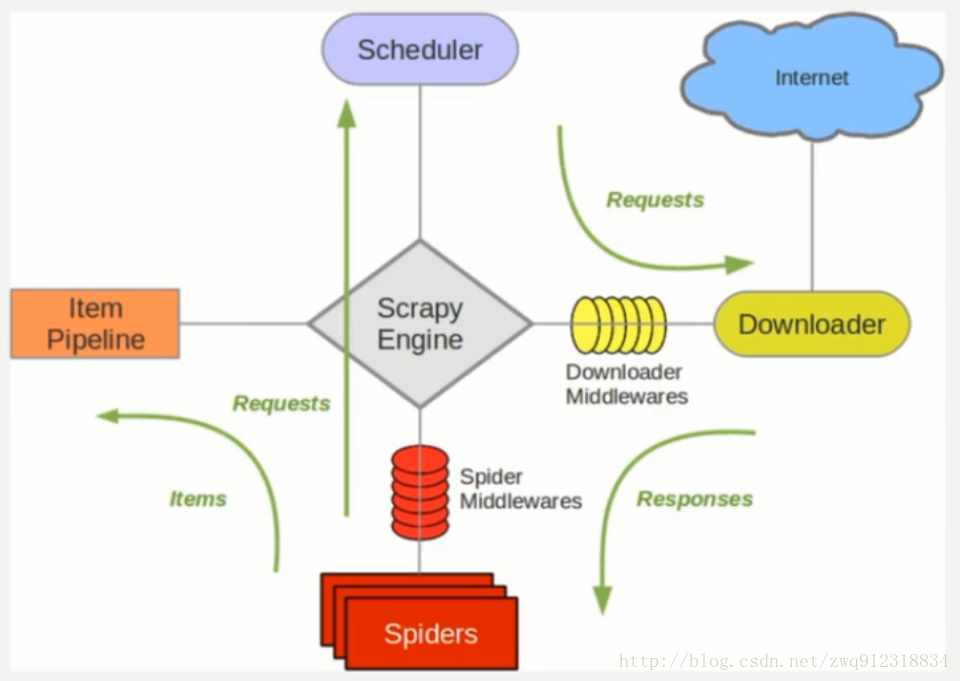
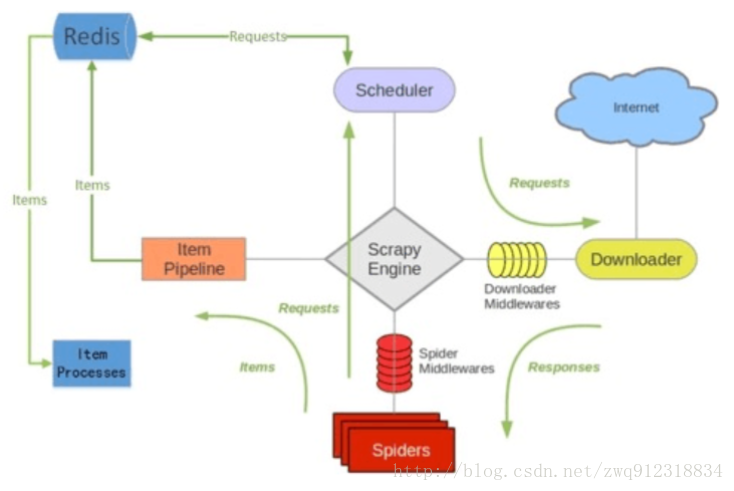
3.1. 对比一下scrapy 和 Scrapy-redis 的架构图。
scrapy架构图:
scrapy-redis 架构图:
- 多了一个redis组件,主要影响两个地方:第一个是调度器。第二个是数据的处理。
3.2. Scrapy-Redis分布式策略。
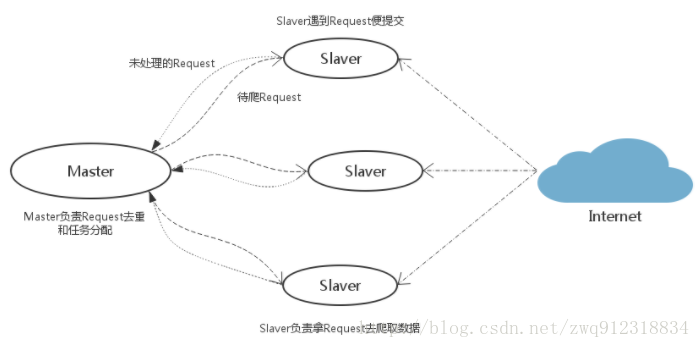
- 作为一个分布式爬虫,是需要有一个Master端(核心服务器)的,在Master端,会搭建一个Redis数据库,用来存储start_urls、request、items。Master的职责是负责url指纹判重,Request的分配,以及数据的存储(一般在Master端会安装一个mongodb用来存储redis中的items)。出了Master之外,还有一个角色就是slaver(爬虫程序执行端),它主要负责执行爬虫程序爬取数据,并将爬取过程中新的Request提交到Master的redis数据库中。
- 如上图,假设我们有四台电脑:A, B, C, D ,其中任意一台电脑都可以作为 Master端 或 Slaver端。整个流程是:
- 首先Slaver端从Master端拿任务(Request、url)进行数据抓取,Slaver抓取数据的同时,产生新任务的Request便提交给 Master 处理;
- Master端只有一个Redis数据库,负责将未处理的Request去重和任务分配,将处理后的Request加入待爬队列,并且存储爬取的数据。
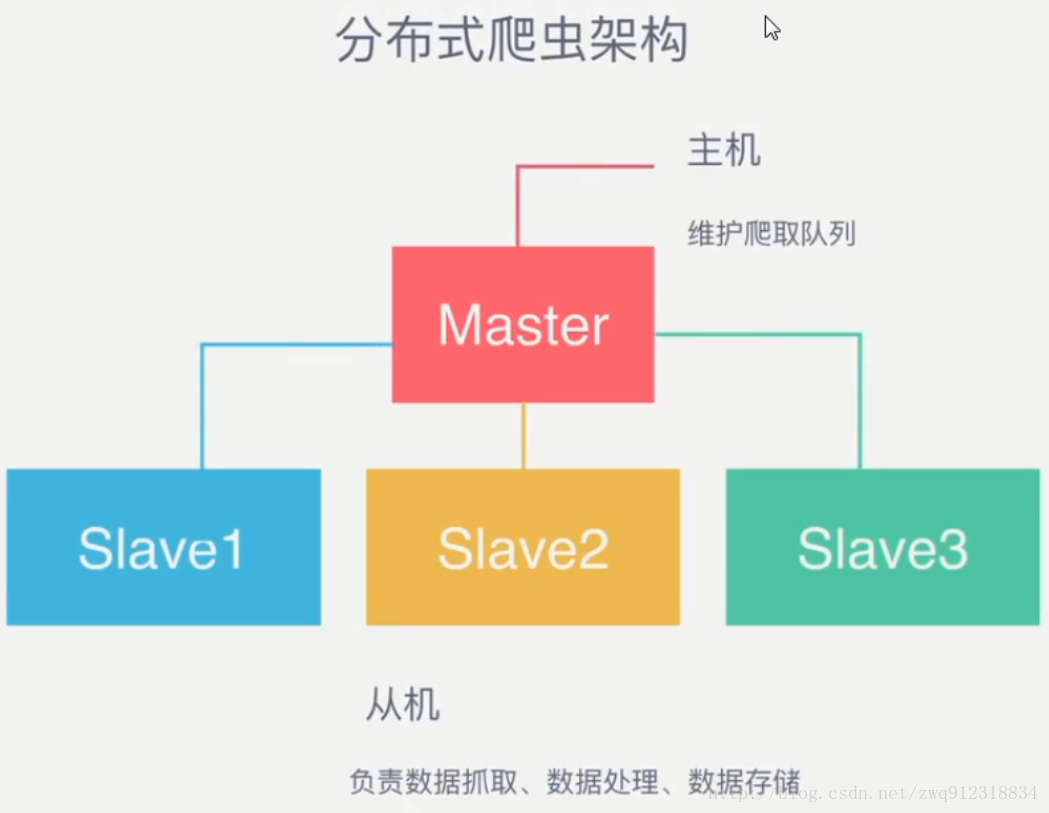
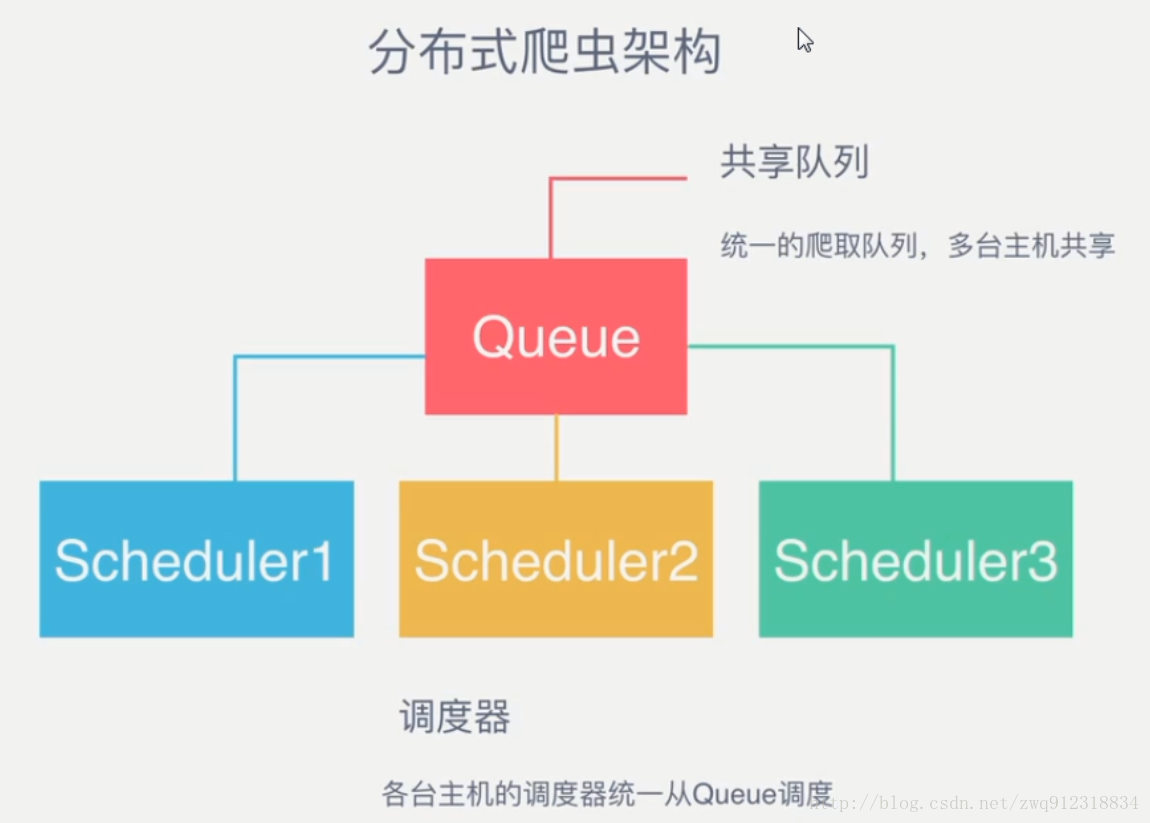
Scrapy-Redis默认使用的就是这种策略,我们实现起来很简单,因为任务调度等工作Scrapy-Redis都已经帮我们做好了,我们只需要继承RedisSpider、指定redis_key就行了。
缺点是,Scrapy-Redis调度的任务是Request对象,里面信息量比较大(不仅包含url,还有callback函数、headers等信息),可能导致的结果就是会降低爬虫速度、而且会占用Redis大量的存储空间,所以如果要保证效率,那么就需要一定硬件水平。
4. 运行流程
- 第一步:在slaver端的爬虫中,指定好 redis_key,并指定好redis数据库的地址,比如:
class MySpider(RedisSpider) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1385
1385

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









