







这篇文件谈不上真正意义的原创作品,但是在调试的时候还是赤膊上阵,花了不少功夫,最终成功运行worldcount。
基于IntelliJ IDEA开发Spark的Maven项目——Scala语言
1、Maven管理项目在JavaEE普遍使用,开发Spark项目也不例外,而Scala语言开发Spark项目的首选。因此需要构建Maven-Scala项目来开发Spark项目,本文采用的工具是IntelliJ IDEA 2016,IDEA工具越来越被大家认可,开发Java, Python ,scala 支持都非常好
下载链接 : https://www.jetbrains.com/idea/download/
安装直接下一步即可
2、安装scala插件,File->Settings->Editor->Plugins,搜索scala即可安装
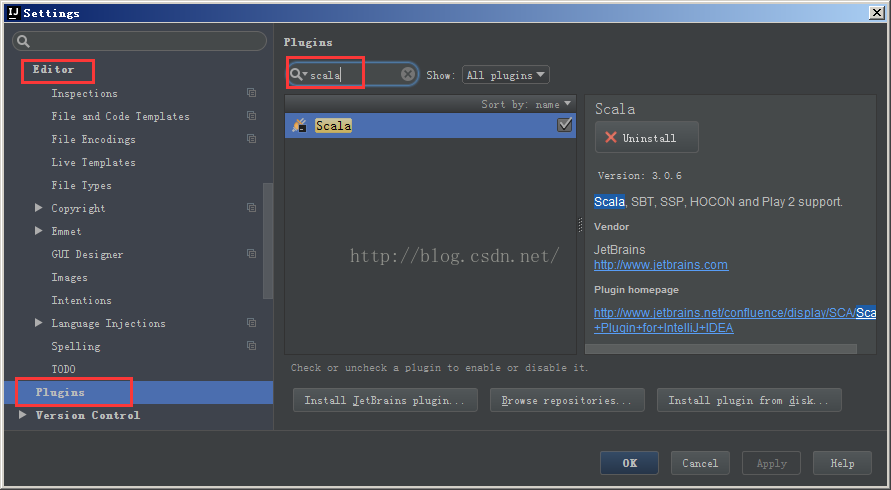
可能由于网络的原因下载不了(第一次转的确失败了,由于是下班就没继续,第二天又重试ok),可以采取离线安装的方式,例如:

提示下载失败后,根据提示的地址下载离线安装包 http://plugins.jetbrains.com/files/631/24825/python-145.86.zip
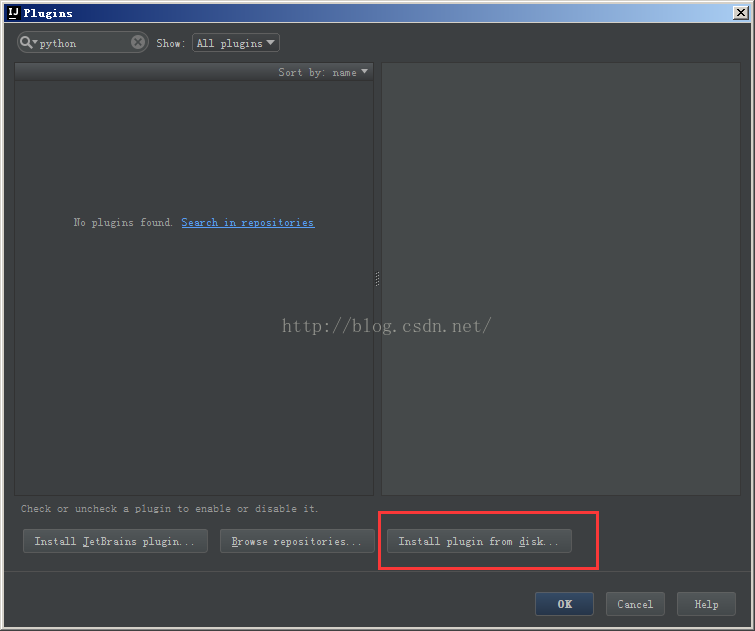
在界面选择离线安装即可:
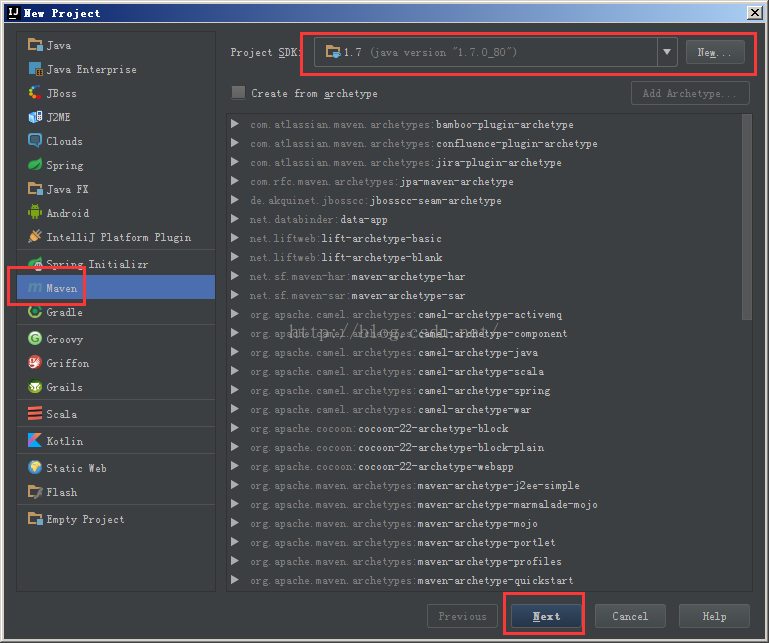
3、创建Maven工程,File->New Project->Maven
选择相应的JDK版本,直接下一步
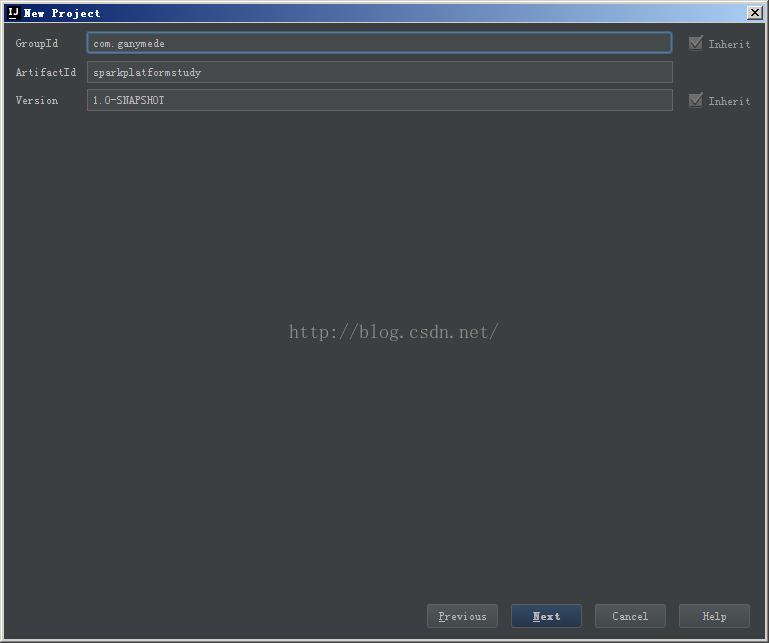
设定Maven项目的GroupId及ArifactId
创建项目的工程名称,点击完成即可
创建Maven工程完毕,默认是Java的,没关系后面我们再添加scala与spark的依赖
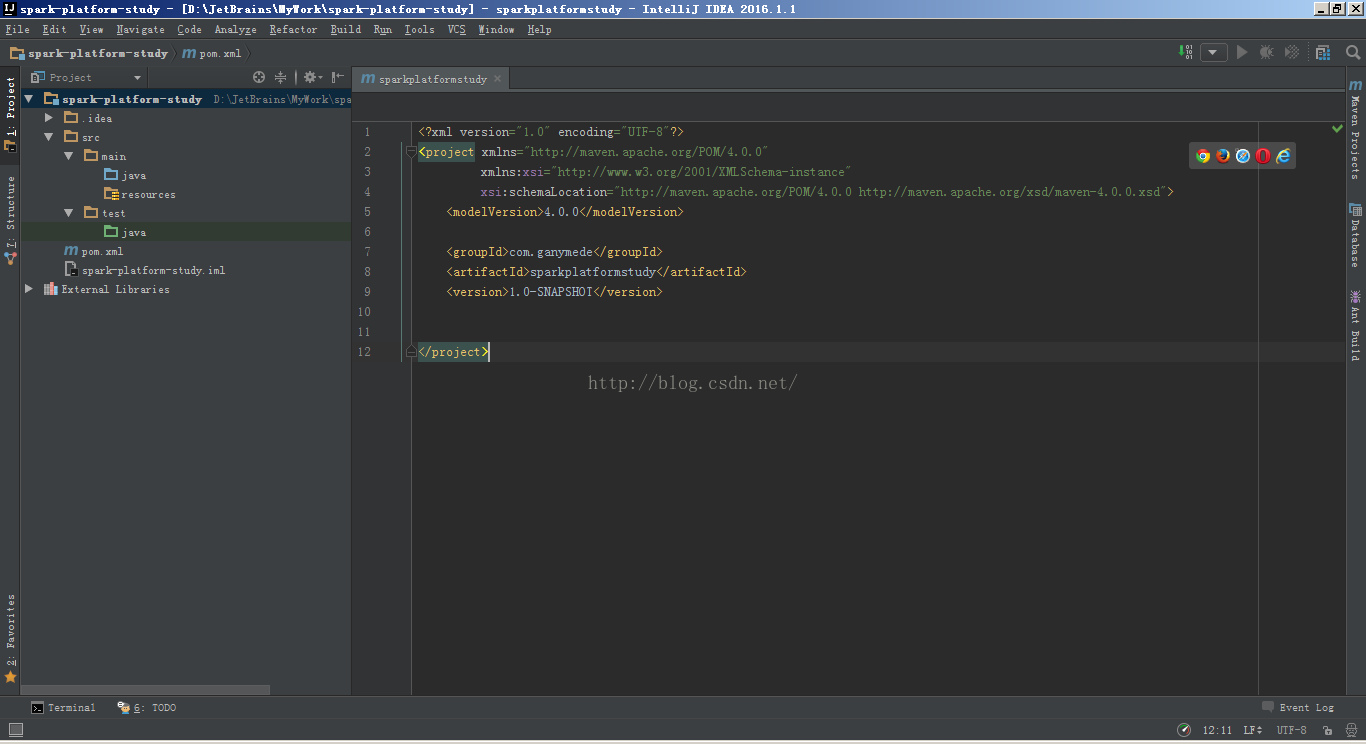
4、修改Maven项目的pom.xml文件,增加scala与spark的依赖
- <?xml version="1.0" encoding="UTF-8"?>
- <project xmlns="http://maven.apache.org/POM/4.0.0"
- xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
- xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
- <modelVersion>4.0.0</modelVersion>
- <groupId>com.ganymede</groupId>
- <artifactId>sparkplatformstudy</artifactId>
- <version>1.0-SNAPSHOT</version>
- <properties>
- <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
- <spark.version>1.6.0</spark.version>
- <scala.version>2.10</scala.version>
- <hadoop.version>2.6.0</hadoop.version>
- </properties>
- <dependencies>
- <dependency>
- <groupId>org.apache.spark</groupId>
- <artifactId>spark-core_${scala.version}</artifactId>
- <version>${spark.version}</version>
- </dependency>
- <dependency>
- <groupId>org.apache.spark</groupId>
- <artifactId>spark-sql_${scala.version}</artifactId>
- <version>${spark.version}</version>
- </dependency>
- <dependency>
- <groupId>org.apache.spark</groupId>
- <artifactId>spark-hive_${scala.version}</artifactId>
- <version>${spark.version}</version>
- </dependency>
- <dependency>
- <groupId>org.apache.spark</groupId>
- <artifactId>spark-streaming_${scala.version}</artifactId>
- <version>${spark.version}</version>
- </dependency>
- <dependency>
- <groupId>org.apache.hadoop</groupId>
- <artifactId>hadoop-client</artifactId>
- <version>${hadoop.version}</version>
- </dependency>
- <dependency>
- <groupId>org.apache.spark</groupId>
- <artifactId>spark-streaming-kafka_${scala.version}</artifactId>
- <version>${spark.version}</version>
- </dependency>
- <dependency>
- <groupId>org.apache.spark</groupId>
- <artifactId>spark-mllib_${scala.version}</artifactId>
- <version>${spark.version}</version>
- </dependency>
- <dependency>
- <groupId>mysql</groupId>
- <artifactId>mysql-connector-java</artifactId>
- <version>5.1.39</version>
- </dependency>
- <dependency>
- <groupId>junit</groupId>
- <artifactId>junit</artifactId>
- <version>4.12</version>
- </dependency>
- </dependencies>
- <!-- maven官方 http://repo1.maven.org/maven2/ 或 http://repo2.maven.org/maven2/ (延迟低一些) -->
- <repositories>
- <repository>
- <id>central</id>
- <name>Maven Repository Switchboard</name>
- <layout>default</layout>
- <url>http://repo2.maven.org/maven2</url>
- <snapshots>
- <enabled>false</enabled>
- </snapshots>
- </repository>
- </repositories>
- <build>
- <sourceDirectory>src/main/scala</sourceDirectory>
- <testSourceDirectory>src/test/scala</testSourceDirectory>
- <plugins>
- <plugin>
- <!-- MAVEN 编译使用的JDK版本 -->
- <groupId>org.apache.maven.plugins</groupId>
- <artifactId>maven-compiler-plugin</artifactId>
- <version>3.3</version>
- <configuration>
- <source>1.7</source>
- <target>1.7</target>
- <encoding>UTF-8</encoding>
- </configuration>
- </plugin>
- </plugins>
- </build>
- </project>

5、删除项目的java目录,新建scala并设置源文件夹(没搞懂设置源文件夹什么意思)
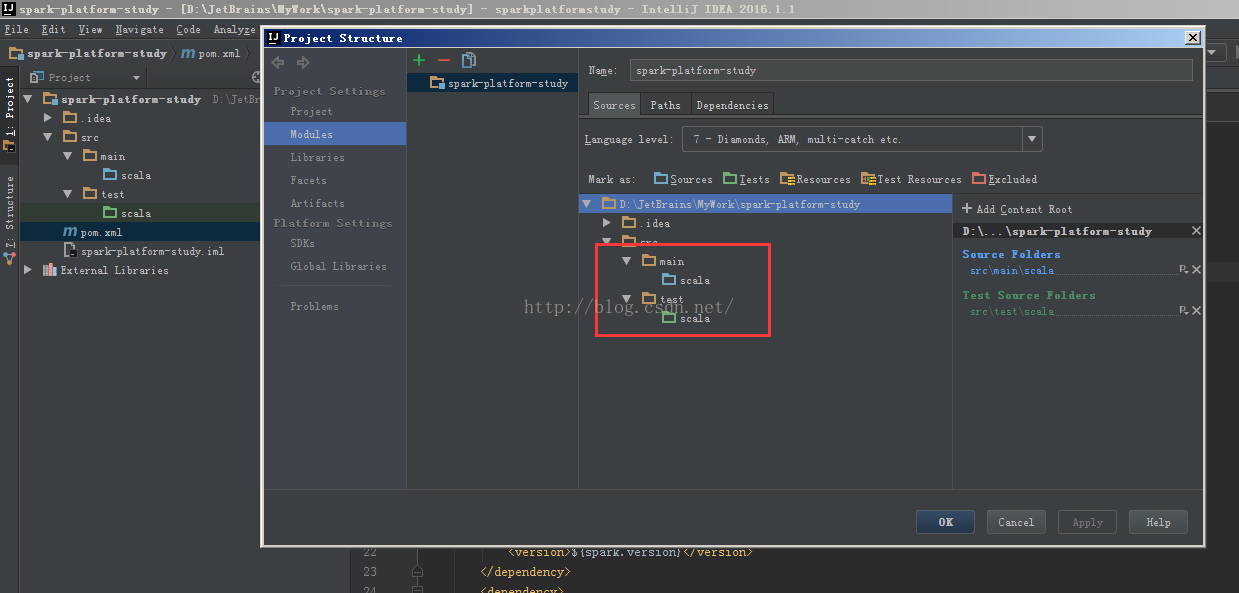
添加scala的SDK(这个地方莫名的花了我很长时间,主要download scala sdk时出的问题)
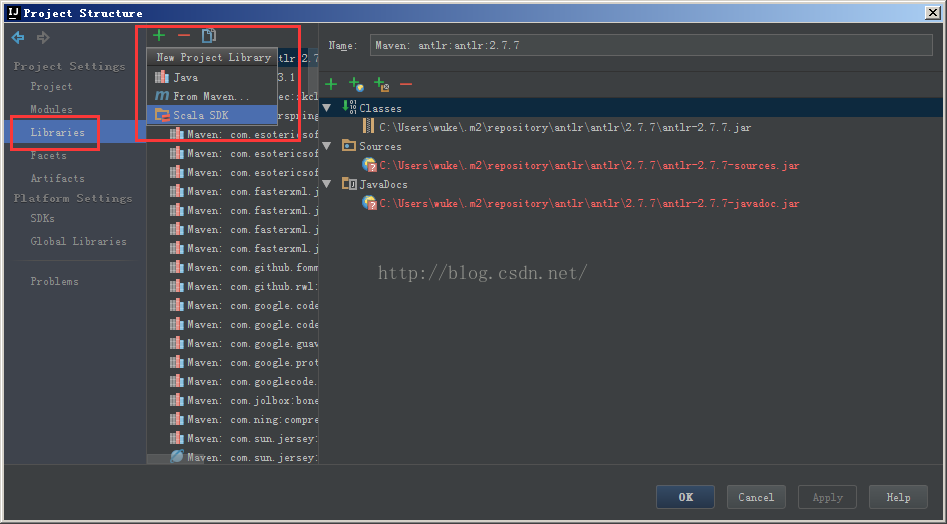
添加scala的SDK成功(要出现系列红框标记)
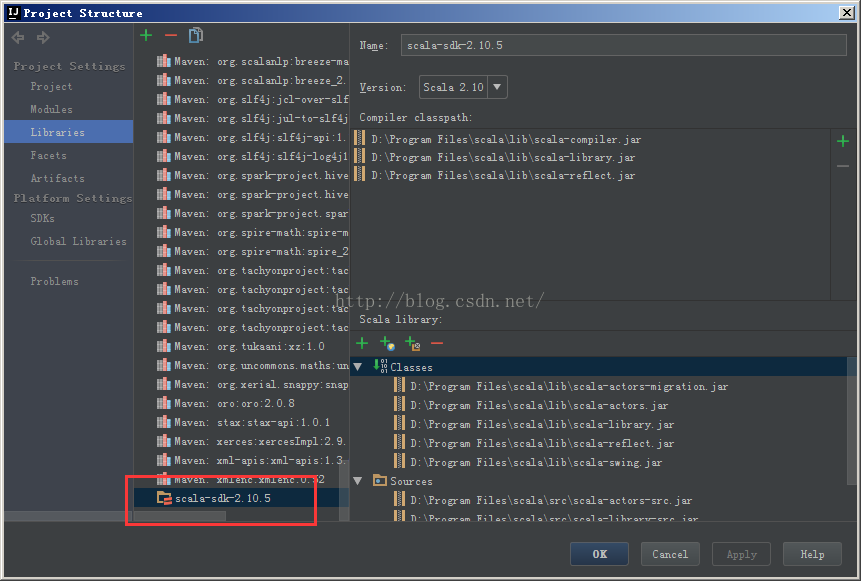
6、开发Spark实例
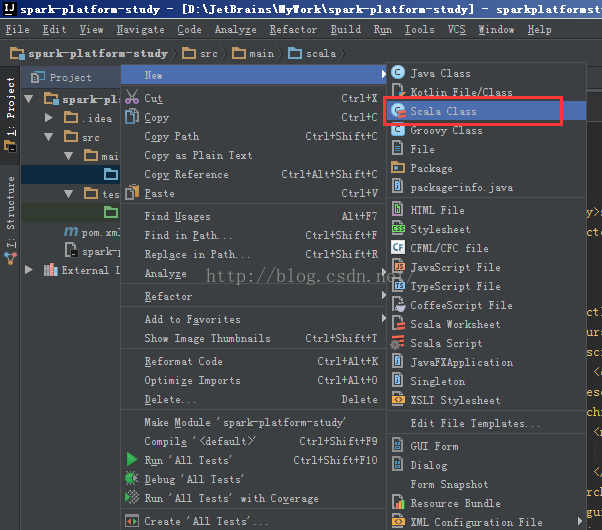
测试案例来自spark官网的mllib例子 http://spark.apache.org/docs/latest/mllib-data-types.html
- import org.apache.spark.{SparkConf, SparkContext}
- /**
- * Created by wuke on 2016/7/5.
- */
- object LoadLibSVMFile extends App{
- import org.apache.spark.mllib.regression.LabeledPoint
- import org.apache.spark.mllib.util.MLUtils
- import org.apache.spark.rdd.RDD
- val conf = new SparkConf().setAppName("LogisticRegressionMail").setMaster("local")
- val sc = new SparkContext(conf)
- val examples: RDD[LabeledPoint] = MLUtils.loadLibSVMFile(sc, "data/mllib/sample_libsvm_data.txt")
- println(examples.first)
- }
测试通过
7、打包编译,线上发布
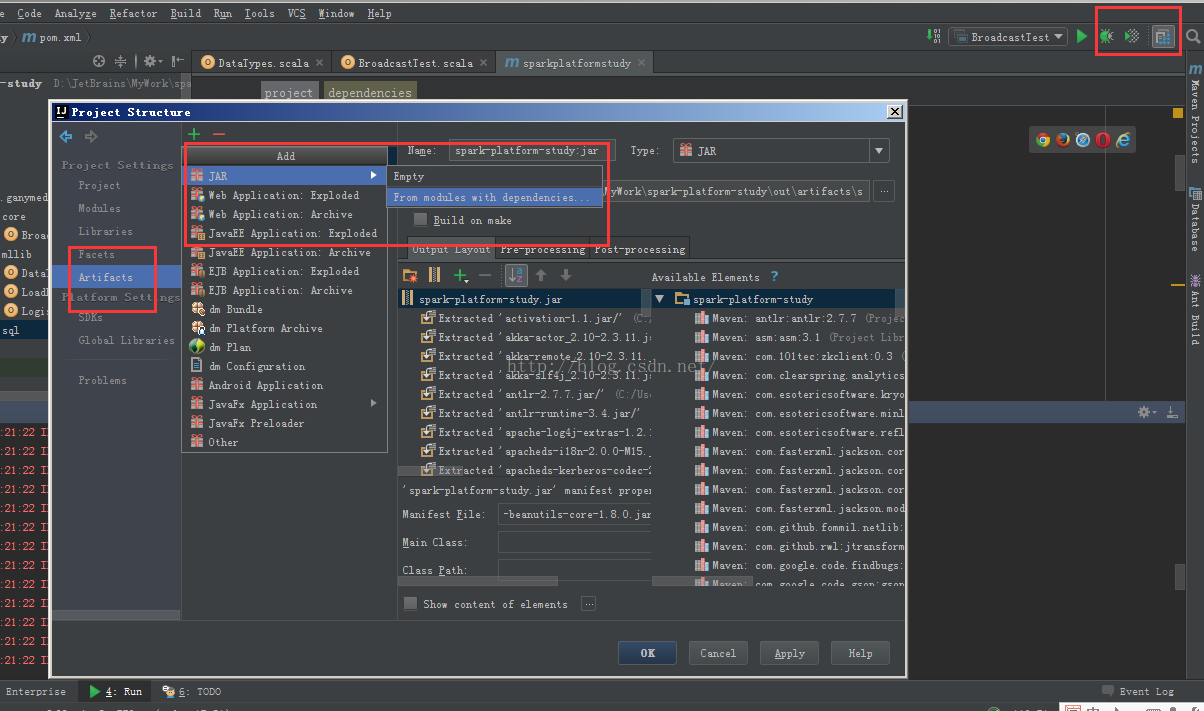
注意选择依赖包
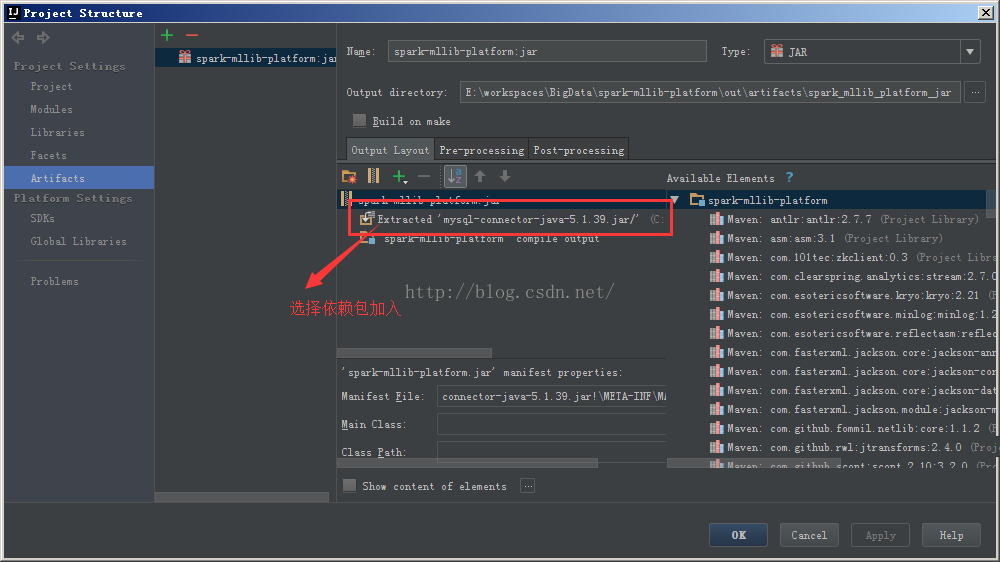
项目搭建完成后,运行报错:Failed to locate the winutils binary in the hadoop binary path java.io.IOException: Could not locate executable null \bin\winutils.exe in the Hadoop binaries。大概的意思就是说找不到hadoop的环境变量,因此有查了一通,最后解决办法是这样的:
1、下载hadoop包,我下载的hadoop-2.7.3.tar.gz,加压后放到c盘
2、下载spark包,我下载的是spark-2.0.0-bin-hadoop2.7(这里指明了hadoop的版本),解压放到C盘;
3、下载hadoop在windows下运行的插件包,我已经分享到云盘上,http://pan.baidu.com/s/1kU5q0Ub,将所有内容拷贝到hadoop下的bin目录下
4、配置hadoop和spark环境变量,主要是home和path。
5、重启(应该可以不用重启)
下面是截图配置完成后的截图信息:

环境变量:

windows下插件

再次运行:

到此windows下spark开发环境搭建基本ok。
感谢一下博主提供的宝贵经验
http://www.cnblogs.com/davidwang456/p/5032766.html
http://www.cnblogs.com/eczhou/p/5216918.html















 107
107

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









