







hadoop最cool的就是MapReduce了,那么当运行一个MapReduce作业的时候,你有没有想过内部是如何实现的?存储在HDFS上的数据到底是特么的怎样被读取的?HelloWord级别的worldcount程序,是对文本文件一行一行的读的,为此我们需要对我们的文本进行处理,让其老老实实的一行一行的排着队。但是在生产环境中,各种格式的数据文件,恐怕一行一行的排队就满足不了我们的要求了。比如需要夸张的处理100G的excel文件,这个时候就需要自己来定义一个输入格式了。所以,我就想来解决这个问题。
干掉敌人之前,先要弄清楚他的底细,那么我们就从hadoop的源码开始研读。
第一个被研读的对象就是InputFormat。
InputFormat作为hadoop作业的所有的输入格式的抽象基类(与之相对应的hadoop作业的所有的输出格式的抽象基类OutputFormat我等下再来学习),它描述了作业的输入需要满足的规范细节。也就是说,你要实现自己的一个指定输入格式的类,必须满足这个规范,不然游戏就玩不下去了,因为你用的就是hadoop这个平台。
InputFormat这个抽象类的源码内部定义了两个抽象方法:
public abstract List<InputSplit> getSplits(JobContext context) throws IOException,InterruptedException;改方法的主要作用就是将hdfs上要处理的文件分割成许多个InputSplit,这里的InputSplit就是hadoop平台上的逻辑分片,对应的还有物理分片blocks,以后学习HDFS源代码的时候再来讲这个。每一个分片(InputSplit),通过其内部定义的文件路径,起始位置,偏移量三个位置来唯一确定。
public abstract RecordReader<K,V> createRecordReader(InputSplit split,TaskAttemptContext context) throws IOException,InterruptedException; 该方法就是为指定的InputSplit创建记录读取器(后面我们将实现自己的RecordReader),通过记录读取器从输入分片中读取键值对,然后将键值对交给Map来处理。看到这里,我想我们应该一些什么。
当hadoop运行MapReduce作业的时候需要依赖InputFormat来完成以下几方面的工作:
- 检查作业的输入是否有效;
- 将输入文件分割成多个InputSplit,然后将每个InputSplit分别传给单独的Map进行处理,也就是说有多少个InputSplit就会有多少个Map任务,Number(Map)==Number(InputSplit)
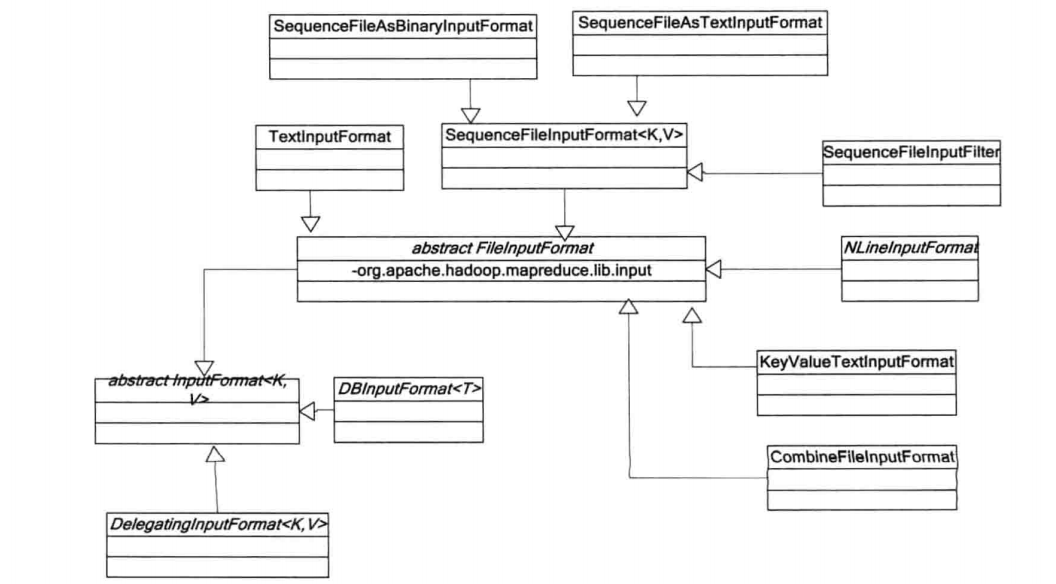
- InputSplit是由一个个记录组成的,所以InputSplit需要提供一个RecordReader的实现,然后通过RecordReader的实现来读取InputFormat中的每一条记录,并将读取的记录交给Map函数来进行处理。以下是hadoop默认为我们提供的InputFormat实现类:

















 893
893

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









