







本系列将记录一些最近的机器翻译模型,作为笔记,以备日后查看。
1、Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
这篇论文试图解决神经网络机器翻译的一些问题:1、较慢的训练与预测速度,2、解决稀少词的预测3、不能够完全覆盖翻译源句。
整个模型编码层由8层lstm与8层的lstm解码构成,其中加入了注意力机制与残差连接层。

如图,编码层第一层采用双向lstm,尽管大部分的目标句与源句都是从左往右意义对应的,但有一些目标句的词是分散于源句的不同位置,采用双向lstm可以更好的捕获上下文信息。
采用残差连接可以更好的减少深层网络的梯度消失问题,拟合残差同时可以加快收敛。具体做法可以将lstm隐藏层输出与上一层的输入相加。

解码层采用多层lstm。在编码层与解码层之间采用attention机制。为了能够获得更好的并行速度,只采用解码层的第一层隐层输出与编码层最后一层输出进行attention计算获得不同输入的权重,进行加权相加,输入到第一层的下一个输入中。同时,将这写attention的输出输入到上面几层的decoder中。
为了解决oov问题,采用子词单元作为输入,主要采用了word piece model,这是一种基于数据驱动的分割词的算法。一些罕见的实体名称以及数字是直接从源端复制到目标端的,因此在源端与目标端采用相同的wpm模型。同时,对一些仍是oov的词,进一步采用了字符级别的模型,比如一个Miki,在词汇表中不存在,将其转化后成<B>M,<M>i, <M>k, <E>i进行训练,对预测出的出现这些特殊符号的词,可以进行后处理。
训练目标函数采用最大似然估计,该模型也融入了强化学习机制,采用bleu值作为奖励。这个和[2]中mrt的做法是一致的。

最终的损失函数为

训练的时候采用dowpour sgd[3],主要就是数据并行,参数共享,worker进行梯度的计算,server进行异步更新参数。为了提高训练效率,采用的了一些定量的方法。入江lstm的值陷于一定的范围之内,采用8bit乘法进行矩阵相乘等。
预测过程采用beamsearch ,为了解决beamsearch倾向于翻译成更短的句子,采用长度归一项。为了完全覆盖对源句的翻译,在解码过程中采用覆盖率惩罚项。S(y,x)越大,越可以作为候选翻译。

因为pi,j为attention权重,为目标源句中词xi与yj的attention中,我的理解是这样的,xi与所有yj的权重之和小与1的话,xi没有对齐到目标句中,说明解码成y1...yj这个句子的可能性越小,最终对s(y,x)的贡献越小。
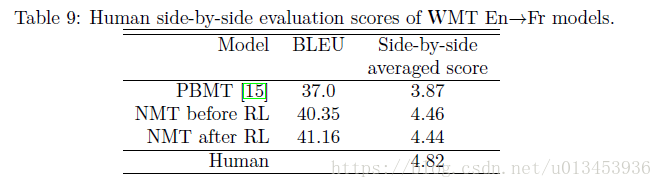
最终测试结果

同时,让人去评价翻译有没有变好,在rl下人的评价并没有变好,原因可能是测试集太小,人对翻译的提高不敏感,以及bleu值与翻译质量的不匹配。
参考文献
[1]Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
[2]Minimum Risk Training for Neural Machine Translation
[3]Large Scale Distributed Deep Networks


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









