






Alessio Buscemi1,† , Daniele Proverbio2,† , Paolo Bova3,† , Nataliya Balabanova4 , Adeela Bashir3 ,
Theodor Cimpeanu5 , Henrique Correia da Fonseca6 , Manh Hong Duong4 , Elias Fernández Domingos7,8 , António M. Fernandes6 , Marcus Krellner5 , Ndidi Bianca Ogbo3 , Simon T. Powers9 , Fernando P.
Santos10, Zia Ush Shamszaman3 , Zhao Song3 , Alessandro Di Stefano3,‡ , and The Anh Han3,‡,∗
1 卢森堡科学技术研究院
2 特伦托大学工业工程系
-
3 Teesside University计算、工程与数字技术学院
-
4 伯明翰大学数学学院
-
5 圣安德鲁斯大学数学与统计学院
-
- 6 INESC-ID和里斯本大学高等技术学院
-
- 7 自由大学布鲁塞尔机器学习组
8 布鲁塞尔自由大学AI实验室
- 7 自由大学布鲁塞尔机器学习组
-
9 斯特林大学计算科学与数学系
-
10 阿姆斯特丹大学
† 并列第一作者
‡ 并列最后作者
普遍认为,在AI开发生态系统中促进信任与合作对于推动可信AI系统的采用至关重要。通过将大型语言模型(LLM)代理嵌入进化博弈论框架,本文研究了AI开发者、监管者和用户之间的复杂互动,模拟他们在不同监管场景下的战略选择。进化博弈论(EGT)用于定量建模每个参与者面临的困境,而LLM提供了额外的复杂性和细微差别,并允许重复游戏和融入个性特征。我们的研究识别了战略性AI代理的新兴行为,这些行为往往比纯博弈论代理采取更“悲观”(不信任且有缺陷)的立场。我们观察到,当用户完全信任时,激励措施有助于有效监管;然而,有条件的信任可能会恶化“社会契约”。因此,建立用户信任与监管者声誉之间的良性反馈循环似乎是推动开发者创建安全AI的关键。然而,这种信任出现的水平可能取决于测试中使用的特定LLM。因此,我们的结果为AI监管系统提供了指导,并有助于预测战略性LLM代理的行为结果,如果它们被用来辅助监管本身。
关键词:AI治理,AI监管,可信AI,博弈论,LLM,行为动态。
I. 引言
随着人工智能(AI)应用的普及,关于如何对其进行监管的讨论正在进行 [1–[6]
虽然围绕该主题的论述大多是定性的,并且在正式预测的制定上有限 [14[–16]
除了运用进化博弈论中已确立的方法,将人类决策过程嵌入一个正式且已被验证的领域 [32, [33]
我们的实验有三个主要目的。首先,观察战略AI代理在复杂进化博弈环境中的社会互动所出现的行为。其次,将这些行为与从博弈论预测中预期的行为进行比较,以通过已知理论验证和解释它们,从而提高对出现结果的可解释性。第三,我们探讨了最近在所有组织层面部署AI代理的情况:如果专家级AI代理被私营组织和开发者用来帮助起草治理指南,它们会如何响应?我们的研究通过考虑一次性游戏和重复游戏,并明确包含AI代理的人格特质,首次系统地预测了这些问题的答案。
我们观察到LLMs提供的结果更加细致,并不总是与博弈论预测一致。这可能与LLMs因训练过程带来的额外复杂性有关。总体而言,我们观察到从收益和情景组合中出现的各种策略;一般来说,有条件信任似乎会促使开发者和监管者采取有缺陷的立场,而AI用户最终可能不会信任他们。相反,AI用户的完全信任则提高了其他代理展现良好行为的机会。总体而言,GPT-4o的态度比Mistral Large更乐观,这突显了LLMs之间潜在的不一致性和对收益的敏感性——反过来,这应该促进研究以提高测试的可重复性。
在下一节中,我们将介绍博弈论收益设定、LLM代理的设置和测试特性。随后将展示每项分析和研究目标的结果和讨论。
II. 方法
A. 三方博弈论设置
我们基于来自[17]的模型构建分析,该模型以博弈形式形式化了监管生态系统中三方的多方互动(见图[1)
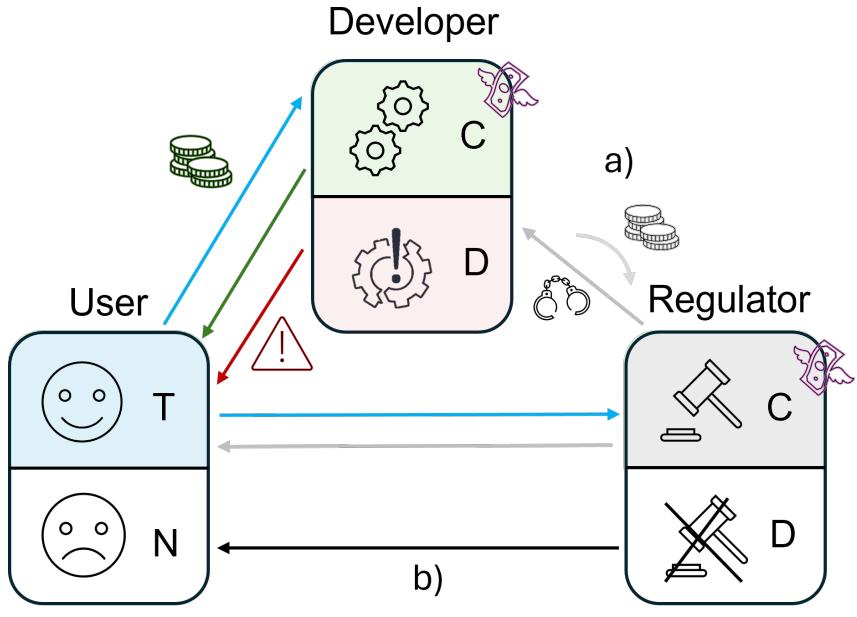
图1:三方互动模型的核心特征方案。用户可以选择信任或不信任;如果他们信任(T),其他代理将获得收益(蓝色线条)。如果不信任(N),没有采用,其他代理也不会获得收益。开发者可以选择遵守(C)规定并开发安全的AI,若被采用,则用户将获得收益(绿色线条);但这可能是有成本的。相反,开发者可以选择创建不安全的AI(D),若被采用,则可能给用户带来部分或负收益(红色线条)。监管者可以选择严格(C),使用资源但在抓住有缺陷的开发者时获得收益(a),或者宽松(D)。如果用户能够获取监管者的声誉(b),他们可以决定是否有条件地信任。
这种模型相当简化,未包括文化或经济的影响,也未包括学者或媒体等其他行为者的中介效应[7, [45]
每次遭遇或互动都被框架为一个游戏,其结果取决于每个行为者的策略。策略由对每个行动赋予的权重决定,汇总在游戏收益矩阵中。收益矩阵如[17]中描述的方式构建。与每个用户策略相关的参数描述如下。
- 用户:用户根据对监管者和开发者的信任程度选择信任(T)或不信任(N)AI系统。如果在监管者和开发者都合作的情况下选择T,用户将获得收益bU;如果开发者背叛(不遵守规定),用户使用不安全的AI并获得减少甚至负收益,即ϵ × bu,其中ϵ ∈ (−∞; 1]表示风险因素。
-
- 创建者:开发者可以选择遵守规定(C)或背叛(D)。他们通过销售产品(即用户信任并采用AI)获得收益bP,并承担创建更安全AI的额外成本cP(而创建不安全AI的成本归一化为0)。然而,如果监管者强制执行规则且开发者选择D,他们将遭受制度惩罚,导致收益损失u。
-
- 监管者:他们可以选择强制合规(C)或宽松(D)。假设监管者在用户信任并采用AI时获得收益bR,例如通过AI产品销售的税收或政府在AI采用率更高时增加对监管的投资。另一方面,创建规则和监控技术是有成本的;选择C需要额外成本cR,而选择D的成本归一化为0。最后,实施惩罚与额外成本v相关联,但如果监管者发现有缺陷的开发者,政府将奖励他们收益bfo。
我们考虑用户基于监管者的声誉放置信任的两种情况:如果监管者的声誉是公开的,用户可以根据监管者的声誉是否良好来调整他们的信任。这导致了有条件的信任(CT)场景。否则,这种声誉信息可能不可用,用户仅根据他们感知的收益来放置信任。对于每种情景,我们通过采样[17]中的子集值来测试bfo的影响,以便在使用合理资源(成本和时间)进行LLM实验时能够直接比较。
- 监管者:他们可以选择强制合规(C)或宽松(D)。假设监管者在用户信任并采用AI时获得收益bR,例如通过AI产品销售的税收或政府在AI采用率更高时增加对监管的投资。另一方面,创建规则和监控技术是有成本的;选择C需要额外成本cR,而选择D的成本归一化为0。最后,实施惩罚与额外成本v相关联,但如果监管者发现有缺陷的开发者,政府将奖励他们收益bfo。
收益矩阵,带或不带CT,重现了[17]中的内容,并分别在表[I
表I:具有监管者激励和有条件信任的AI治理模型。代理为:用户Us., 创建者Cr和监管者Re。用户有条件地(CT)根据监管者的声誉采取行动,假设在游戏前公开可用。
| 策略 | 收益 | ||||
|---|---|---|---|---|---|
| Us. | Cr | Re | 用户 | 创建者 | 监管者 |
| CT | C | C | bU | bP − cP | bR − cR |
| CT | C | D | 0 | −cP | 0 |
| CT | D | C | εbU | − u bP | − cR − v + bfo bR |
| CT | D | D | 0 | 0 | 0 |
| N | C | C | 0 | −cP | −cR |
| N | C | D | 0 | −cP | 0 |
| N | D | C | 0 | 0 | -cR |
| N | D | D | 0 | 0 | 0 |
表II:具有监管者激励但无有条件信任的AI治理模型。代理为:用户Us., 创建者Cr和监管者Re。用户基于其收益和先验态度信任(T)。
| 策略 | 收益 | |||||
|---|---|---|---|---|---|---|
| Us. | Cr | Re | 用户 | 创建者 | 监管者 | |
| T | C | C | bU | bP − cP | bR − cR | |
| T | C | D | bU | bP − cP | bR | |
| T | D | C | εbU | − u bP | − cR − v+bfo bR | |
| T | D | D | εbU | bP | bR | |
| N | C | C | 0 | −cP | −cR | |
| N | C | D | 0 | −cP | 0 | |
| N | D | C | 0 | 0 | -cR | |
| N | D | D | 0 | 0 | 0 |
最后,我们考虑两种游戏设置:一系列一次性游戏,其中每次遭遇只发生一次并产生结果,以及重复游戏,其中玩家多次互动并可根据过去的直接互动调整行为。在其他重复游戏设置如囚徒困境、公共物品博弈和AI竞赛互动中已建立,当同一对或群体玩家之间的互动重复时,通过直接互惠,合作和安全开发等理想行为变得更加频繁[21, [46,
B. AI代理设置
游戏使用LLM代理设置,其收益如上所述。为了在博弈论框架内设置代理,我们使用了使用博弈论识别AI代理偏见的框架(FAIRGAME)[48]。FAIRGAME允许测试用户定义的游戏,以文本格式描述并纳入任何所需的收益矩阵。此外,它允许指定参与这些游戏的代理特征。代理可以通过调用相应的API使用任何选定的LLM实例化。
运行FAIRGAME需要以下输入:
- 配置文件:定义代理和游戏设置的文件。默认格式为JSON。在本研究中,我们使用自定义文件列出与游戏相关的参数和收益权重,如上所述。
-
- 提示模板:定义指令模板的文本文件,提供游戏的字面描述。它包括占位符,这些占位符在每轮中根据配置文件中的信息动态填充,确保为每个代理定制化。所有实验中使用的模板可在补充部分S1中找到。
| 参数 | 值 |
|---------------------------------------------|----------------------------------------------------|
| 代理数量 | 3 |
| 代理名称 | 监管者;开发者;用户 |
| 代理性格 | 无;无;无 |
| 底层LLM | OpenAI GPT-4o;Mistral Large |
| 轮数 | 1(一次性游戏);10(
重复游戏) |
| 代理沟通 | 否 |
| 代理知道其他人的性格 | 否 |
| 停止条件 | 无 |
- 提示模板:定义指令模板的文本文件,提供游戏的字面描述。它包括占位符,这些占位符在每轮中根据配置文件中的信息动态填充,确保为每个代理定制化。所有实验中使用的模板可在补充部分S1中找到。
表III:提供给FAIRGAME的参数。
表III列出了运行主要实验(见章节[III A,
底层语言模型为OpenAI的GPT-4o或Mistral Large。一旦选择模型,它在整个模拟中保持一致。也就是说,我们进行所有代理基于GPT-4o的模拟和其他所有代理基于Mistral Large的模拟,但不在同一游戏中混合模型。
我们进行一次性游戏,由单轮组成,以及重复游戏,跨度十轮。值得注意的是,代理独立操作,彼此之间没有直接通信,确保所有决策都是独立作出的。此外,代理缺乏对其他参与者性格或战略倾向的先验知识。游戏在没有预设停止条件的情况下进行,并持续指定的轮数。
尽管框架支持指定代理性格,但在主要实验中,所有代理均未指定性格,保持其默认行为。这保证了决策仅根据各自的职责作出,遵循LLM的默认行为而不引入额外因素。我们还构建了额外实验,专门询问设置代理性格的影响:在章节III C,中,我们进行了一部分主要实验,以检查对比性格如何影响结果。具体来说,我们测试了以下性格特征,通过提示模板文件充分描述给LLM以避免歧义。
- 用户:风险规避,即你拒绝新AI系统以避免不确定性 OR 风险偏好,即你采用新AI系统以从潜在进步中受益。
-
- 开发者:激进,即你快速开发以保持领先,接受某些风险 OR 合作,即你采取谨慎方法以最小化风险。
-
- 监管者:宽松,即你信任开发者自我监管 OR 严格,即你在部署前要求验证以确保安全。
III. 结果
A. 一次性游戏和无条件信任
我们首先考虑一组一次性游戏的情况,以及监管者激励(bfo)对特定策略采纳的影响。我们将把结果与有限人口中的进化博弈动力学结果进行比较,已知后者由于社会学习错误和行为探索等原因对进化结果产生了显著的随机影响[49]。这种随机方法已被证明在解释受控实验中的人类行为方面非常有效[[50,
使用AI代理本身就嵌入了随机性,因为LLM本身的性质总是包含一定程度的随机性[52],并将随机结果凝缩到输出Softmax函数中[[53]
图2和[3
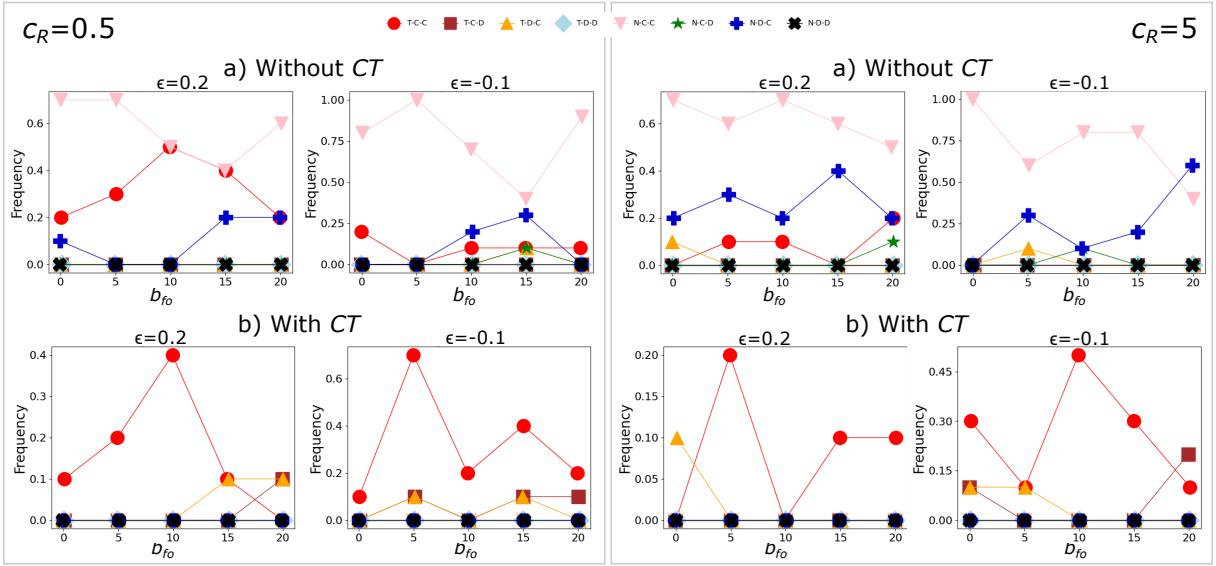
图2:一次性游戏的结果,使用GPT-4o。左框:低监管成本(cR = 0.5)。右框:高监管成本(cR = 5)。每个面板对应于ϵ的不同值,即用户采用不安全AI的风险(ϵ < 0具有更高的风险)。有条件信任促进完全信任、合作监管和安全开发。参数设置为:bU = bR = bP = 4, u = 1.5, v = 0.5, cP = 0.5。
当信任不依赖于监管者的声誉时,基于GPT的代理倾向于选择用户不信任AI的情况(除非监管者有低监管成本且用户通过采用不安全AI仍获得一些好处,参见图2,的左上角面板,其中完全信任和合规策略共存于中等监管者激励下)。在此情况下,监管者更频繁地合规,尤其是当抓到不安全开发者的好处更大时,即bfo。另一方面,我们观察到开发者的合作与背叛混合。此外,我们通常观察到,如果监管者有激励去抓取有缺陷的开发者,那么即使在较高的监管成本下,随着有缺陷开发者的比例增加,其合规比例也会增加。这种效应有可能应对开发者的行径。这些发现与纯粹博弈论设置下的情况大相径庭(参见[[17]
7
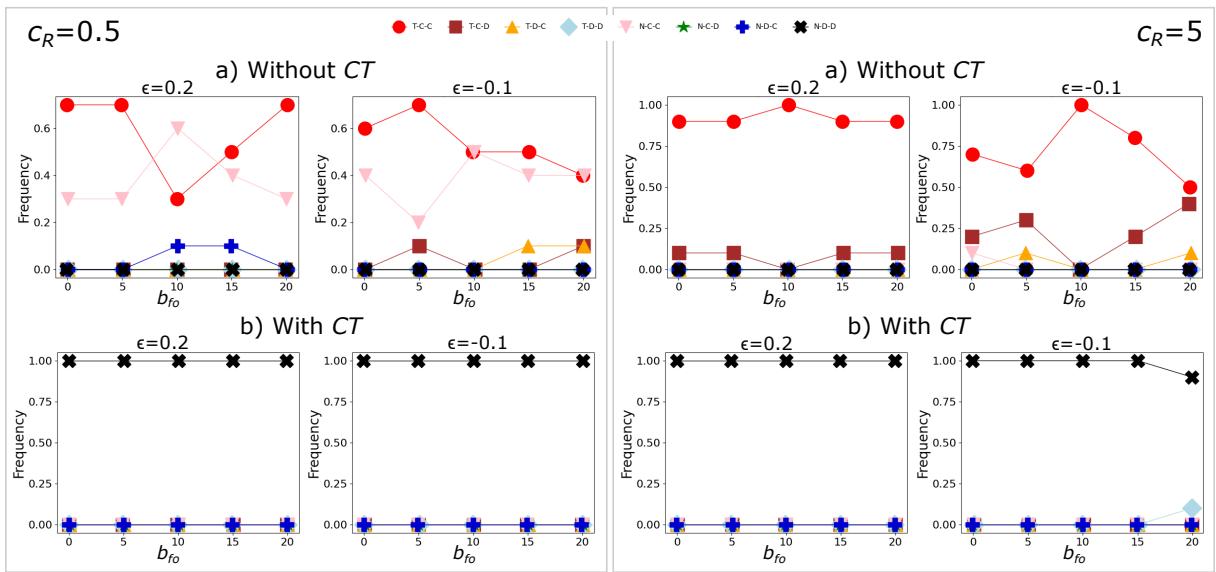
图3:一次性游戏的结果,使用Mistral Large。左框:低监管成本(cR = 0.5)。右框:高监管成本(cR = 5)。每个面板对应于ϵ的不同值,即用户采用不安全AI的风险(ϵ < 0具有更高的风险)。有条件信任导致低信任。参数设置为:bU = bR = bP = 4, u = 1.5, v = 0.5, cP = 0.5。
其中TDD策略通常是主导的。有趣的是,这可能解释为GPT-4o是在最近的真实世界数据上训练的,这些数据显示用户整体上倾向于部分信任AI[22, [23]
相反,有条件信任时,基于GPT的代理倾向于对低和高监管成本都更信任和合规。在第一种情况下,这与博弈论结果一致,而在第二种情况下,它显示了LLM对用户、开发者(以及因此对监管者)行为的整体“积极性”,这种行为只有在高成本的情况下才会变得有缺陷,尽管有激励。即使在这种情况下,我们也可以认识到训练数据对游戏输出的影响,这混合了现实世界的统计证据和基于收益的策略。
另一方面,Mistral的表现与GPT有很大不同。没有CT且cR = 0.5的场景非常接近GPT的,但随后LLM的结果发生了分歧。不同于GPT,它在监管者成本较高时仍然保持“乐观”(偏好TCC策略),在完全信任的情况下也是如此。相反,有条件信任触发了NDD场景;在高cR的情况下,这与使用纯博弈论观察到的结果一致(参见[17]中的图7),而对于较低的cR,这表明Mistral视有条件信任为整体有害的因素。CT对Mistral结果的显著影响表明,该模型对适应CT机制所做的收益矩阵变化非常敏感。
B. 重复游戏
我们现在考虑重复游戏的可能性,这样策略的比例可以在多轮中演变。这样,代理可以根据其他玩家在前几轮的行为更新其选择,从而即使在没有CT的情况下也能进行条件决策(这是历史依赖选择的第一近似,其结果在补充图S1中显示)。除了轮数外,所有其他参数均按上述设置。图4显示了GPT和Mistral代理在10轮重复游戏中的平均结果。选定bfo值的每轮结果分别在图[5
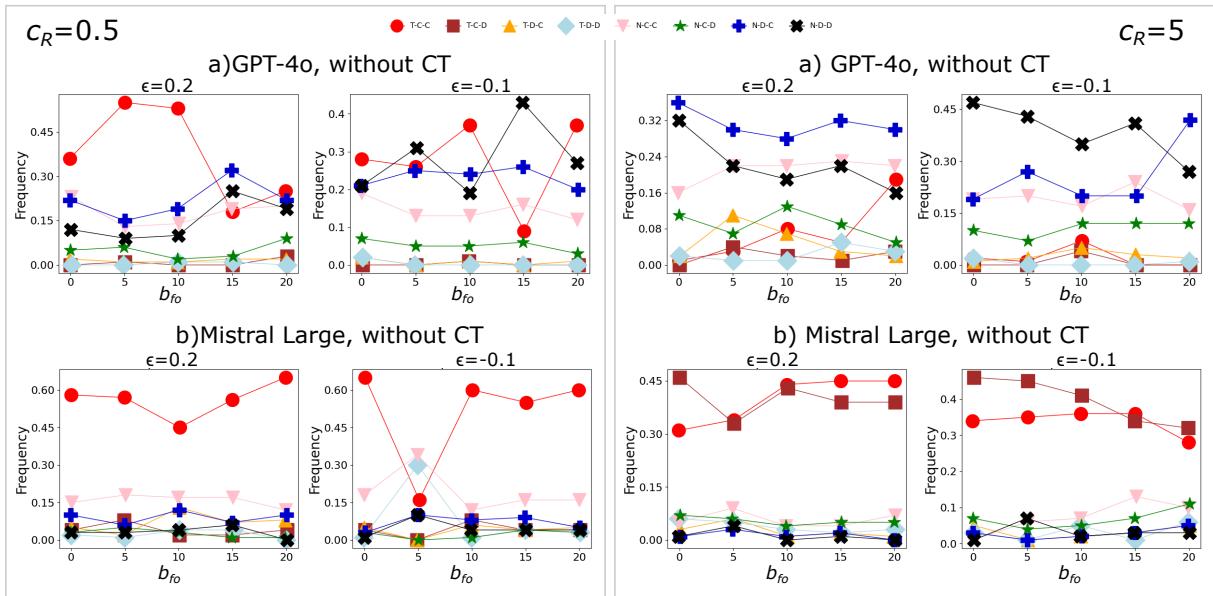
图4:使用GPT-4o和Mistral Large进行10轮重复游戏的结果(各轮平均)。左框:低监管成本(cR = 0.5)。右框:高监管成本(cR = 5)。每个面板对应于ϵ的不同值,即用户采用不安全AI的风险(ϵ < 0具有更高的风险)。
我们立即观察到,对于GPT-4o,重复游戏改变了结果。如果游戏在同一组(三个)代理中重复,他们最终会选择多种策略的混合,倾向于在低监管成本(cR)、低用户风险ϵ和低激励bfo的情况下信任(TCC),在bfo增加时不太可能信任的概率更高。相反,如果监管成本高,就更倾向于不信任,有缺陷的开发者和混合的合规与缺陷监管者,其合规比例随更高的bfo增加。总体来看,出现的画面更符合使用一次性游戏预测的游戏理论(参见[17]中的图6和7):显然,尽管由于LLM的随机性质引起的波动,重复游戏允许“平滑”数据的影响,并收敛到主要由收益矩阵驱动的结果。
在图5中,我们展示了GPT-4o中用户信任和开发者及监管者合作的频率随回合的变化,以检查这些玩家如何随时间改变其行为。我们观察到,在所有场景中,开发者和监管者一开始都有高水平的合作,随着时间推移逐渐下降。相反,用户倾向于信任较少,并在各轮中维持类似(低)的信任水平。在所有bfo和ϵ的情况下都可以观察到类似的模式,尽管在更改这些参数时绝对值略有变化。
另一方面,Mistral Large代理保持“乐观”态度,倾向于作为用户信任并作为开发者和监管者合规,高bfo进一步激励监管者在成本可忽略时合规,并在监管成本高且其他参与者表现良好时更加宽松。即使在有条件信任的情况下,Mistral Large对重复游戏也不如GPT-4o敏感。实际上,Mistral的结果与无CT的一次性场景一致,其中TCC策略占主导地位。与GPT-4o一样,我们也观察到一种替代策略的出现,即(C)TDD,其中用户倾向于信任AI,即使开发者和监管者有缺陷。这些结果在有条件信任和高cR的情况下接近博弈理论预测,同时在低cR时重复出现,某种程度上表明LLM对此参数的敏感度较低。
在图6中,我们展示了Mistral Large中用户信任和开发者及监管者合作的频率随回合的变化。我们观察到,在所有场景中,用户信任水平和开发者及监管者水平在开始时下降,然后在几轮后增加。这与使用GPT获得的结果形成鲜明对比,表明Mistral Large可能包含从训练过程中获得的不同偏差,倾向于偏好合作行为。这些模式也与Mistral Large在有条件信任的一次性游戏中的输出形成鲜明对比,其中NDD策略占主导地位;这表明对于此LLM,有条件信任是对其他代理观察后更新行为的不良近似。
关于每种类型代理的首选策略的分解,平均跨越各个回合,
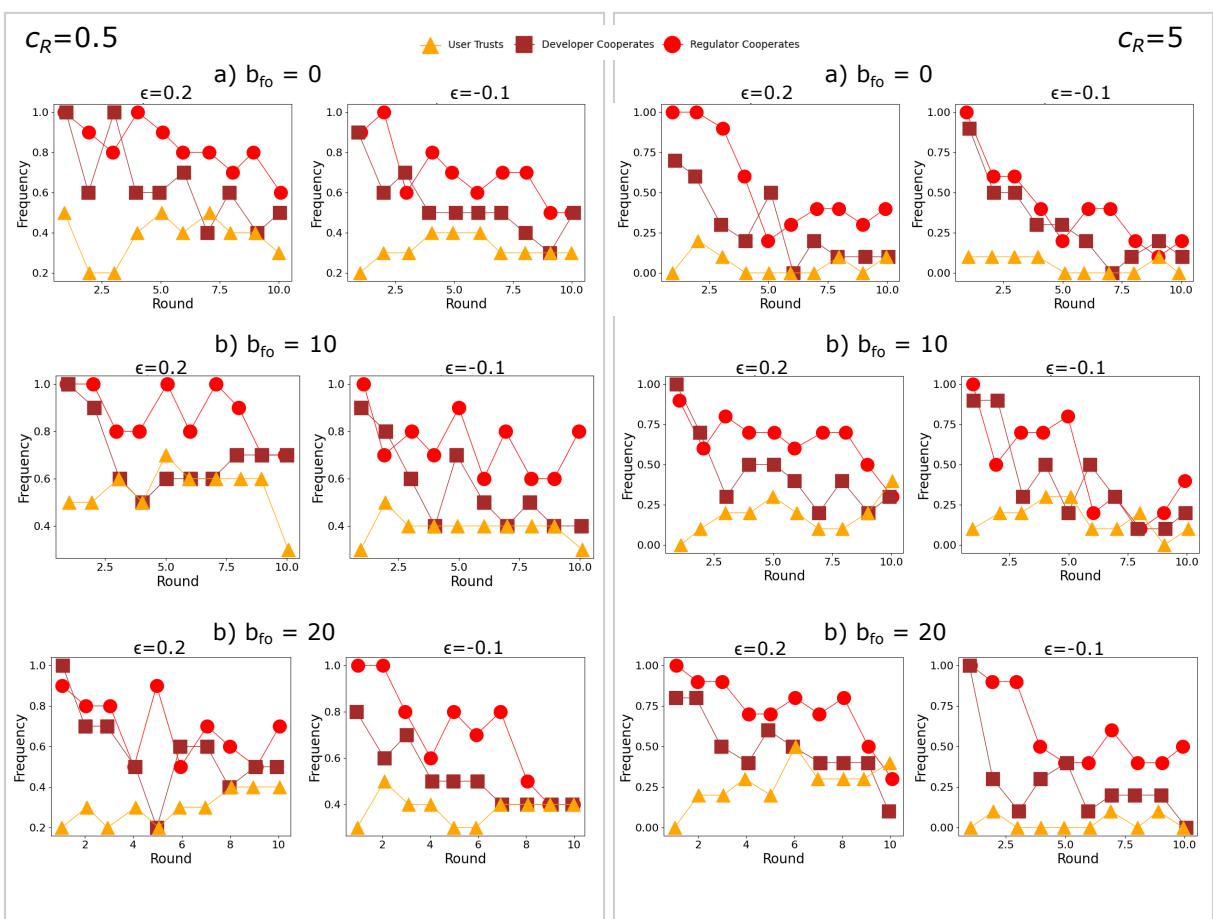
图5:使用GPT-4o进行10轮重复游戏的每轮结果,针对不同的bfo值。左框:低监管成本(cR = 0.5)。右框:高监管成本(cR = 5)。每个面板对应于ϵ的不同值,即用户采用不安全AI的风险(ϵ < 0具有更高的风险)。
在补充图S1和S4中也提供了。
C. 添加人格特征
最后,我们利用LLM代理相较于博弈论实体提供的更大灵活性,隔离与每个代理关联的人格效应。如第II B,节所述,我们提示LLM在一回游戏中扮演每个代理,根据一组现实的人格特征。我们一次为一个代理添加人格特征,其余两个保留“无”人格,然后改变组合;这样,我们可以仔细分析每个代理人格的作用。这一额外的测试集使我们能够通过明确考虑人格对出现行为的影响来更好地解释上述结果(回想一下,之前我们使用了LLM统计上与每个代理关联的默认“人格”,这是未知的),并预测指定人格对AI代理策略选择的影响。对于每个代理,我们使用第[II B.
由于资源限制,我们专注于有条件信任的情境,cR = 0.5和ϵ = −0.1,这是根据[54]和上述发现展示最有趣结果的情景。所有其他参数均按之前设置。
图7总结了GPT-4o和Mistral Large的结果。更多结果见补充图S7。从图[7,
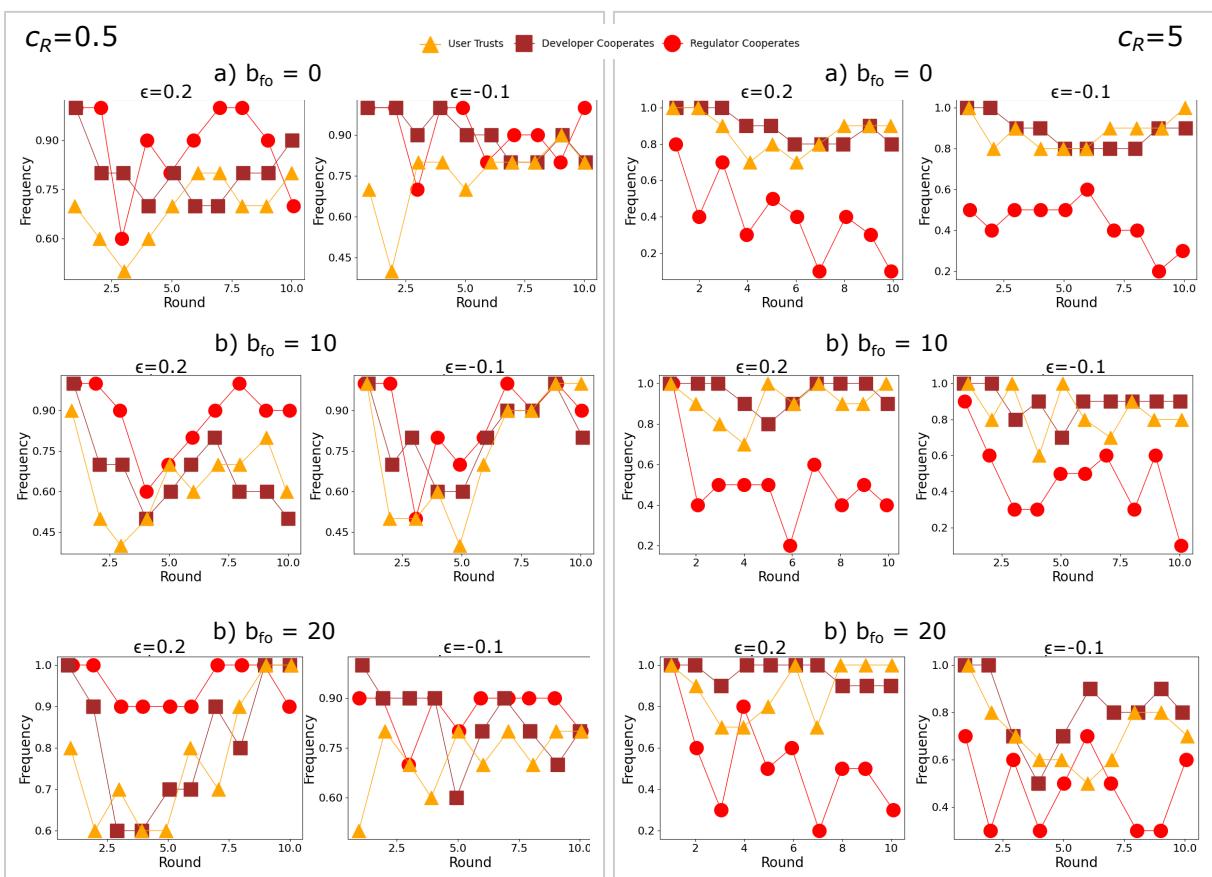
图6:使用Mistral Large进行10轮重复游戏的每轮结果,针对不同的bfo值。左框:低监管成本(cR = 0.5)。右框:高监管成本(cR = 5)。每个面板对应于ϵ的不同值,即用户采用不安全AI的风险(ϵ < 0具有更高的风险)。
总体而言,GPT代理比Mistral的更乐观,后者大多复制了无人格时获得的“悲观”结果,参见图3.
总体而言,为AI代理添加人格提供了更多的细微差别和可能结果,可以为预测AI监管中的信任提供信息。当指定人格时,两种LLM提供了相似的结果,表明固定这个额外参数是增加通过LLM获得可重复结果机会的关键。此外,预先结果表明,如果得到有条件信任的支持,AI代理总体上对当前AI监管持相对悲观的看法。这一观察可能表明,当人格设置为“无”时,AI代理的默认人格更接近于“悲观”态度。了解这是否是系统性的,以及它是否源自训练数据,是未来研究的任务。
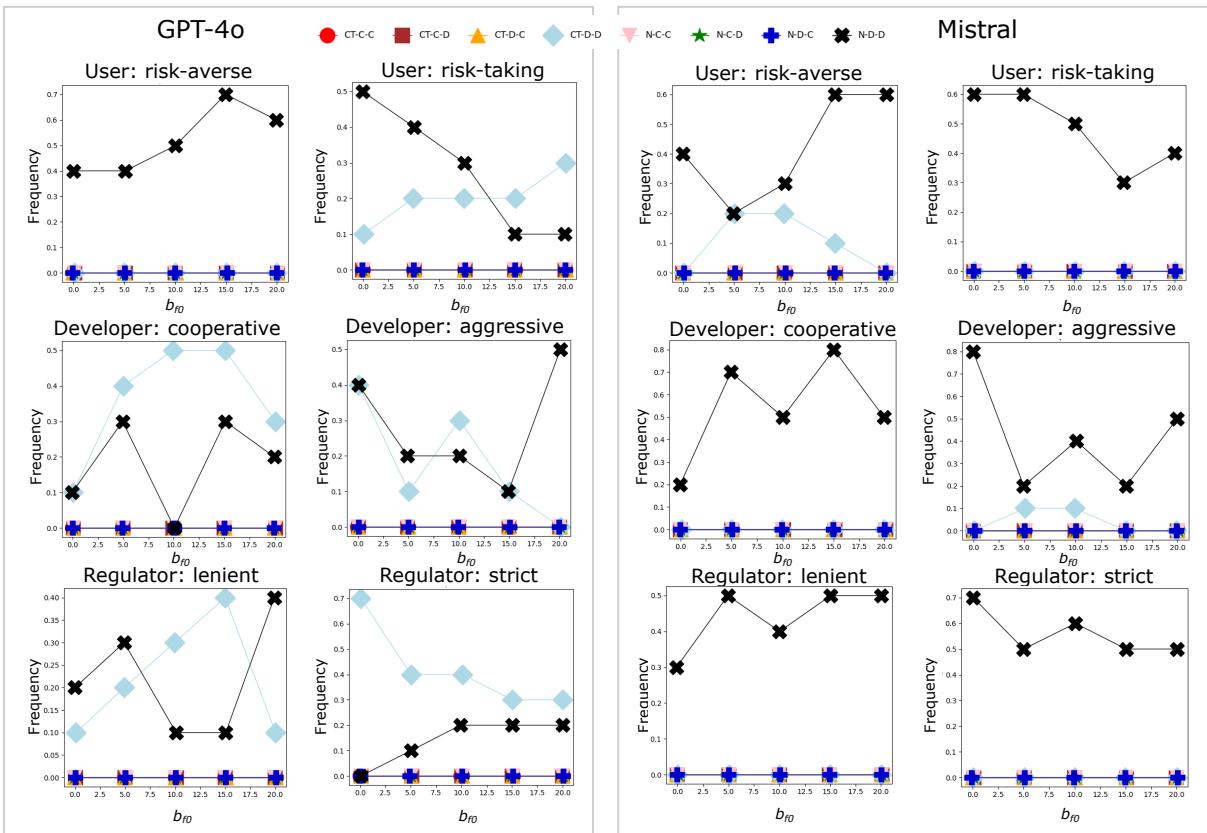
图7:使用GPT-4o(左)和Mistral Large(右)进行一次性游戏的人格特征结果。每行包含两组对比人格,描述见II. 所有情景均具有CT,cR = 0.5和ϵ = −0.1。
IV. 讨论
这项工作首次系统地测试了AI代理在博弈论框架内的表现,该游戏并非文献中的标准游戏,因此没有数据来训练LLM。因此,所获得的结果真正来源于收益矩阵和其他类型训练数据的交互,而之前的成果[42, [48]
关于问题“LLM是否信任AI监管?”我们的研究提供了几个关键要点。
总体而言,AI用户根据开发者和监管者的行为,潜在地根据其人格(尽管后者似乎起次要作用)来信任他们。然后,信任根本上取决于所使用的LLM:对于基于GPT的代理,有条件信任促进了整体信任,而Mistral代理在一次性游戏中则经历了完全相反的情况。重复游戏使LLM更一致,预测用户在不受监管者声誉制约的情况下会有混合或相对较高的信任,但在有条件信任的情况下则不会信任。回想起来,LLM可能混合基于收益的游戏与从真实数据训练中得出的统计结果,这可能表明监管者在数据源中的声誉相对较低,因此LLM代理倾向于信任他们较少。如果AI开发的风险显著,监管机构应展示高可靠性以促进用户信任。
当监管成本低,且监管者倾向于更多监管时,AI代理建议
开发者会更倾向于合规,否则可能背叛。相反,监管者被建议倾向于背叛,除非得到适当的激励。监管机构应确保可管理的监管成本,并具备高能力识别不合规行为,以一致地实施安全措施。
总的来说,结果不如纯博弈论的结果清晰,但呈现更多细微差别,可能与LLM的内在随机性以及数据中的偏差有关,这些偏差可能平衡基于收益的决策。这些结果补充了先前呼吁紧急采取行动以确保AI的安全性和可信度,并分配必要的资源给监控机构[56, [57]
然后,我们观察到LLM并不完全与理论博弈结果一致。这可能源于训练数据的干扰、LLM在进行数学建模时遇到的挑战(主要处理统计关联[58]),或其对收益矩阵元素的不同敏感性。尽管如此,这一观察开启了令人兴奋的方向:识别最适合嵌入经验数据元素的LLM可能会引发博弈研究,这些研究也能反映现实世界情况并可能改进预测。然而,这一努力需要非常谨慎地进行,以避免因LLM的黑箱性质而产生虚假结果。实际上,图[7
最后,本研究揭示了博弈论学者在接近基于LLM的模拟时的一个方法论注意事项,即选择一种LLM或另一种LLM对结果有深远影响,类似于在人类实验中使用不同人群样本的情况[59]。为了确保可重复性和可靠预测,强烈建议对LLM的行为进行额外测试,并改进其可解释性和选择指南,以融合两门学科的最佳部分,解锁具有深远社会影响和立即应用于社会发展、治理和经济生态系统中战略代理的新研究方向。
A. 局限性及未来研究方向
我们的模型嵌入了战略性决策的关键机制,并通过FAIRGAME确保了结果的可重复性。然而,仍存在若干限制,可以促进未来的研究和更精细的见解。首先,我们考虑了用户、开发者和监管者的平均场行为——甚至是平均场人格。实际上,用户被细分为选择使用哪种AI系统的市场细分,公司也可能选择重新定位以避免特别繁重的监管。另一方面,遵守AI安全规定可能成为公司的价值主张,其成本会因为获得的竞争优势而大幅降低。未来的研究可以通过纳入网络或异质人群、人口之间的合作伙伴选择,以及潜在考虑非线性成本结构来解决这些限制。此外,除了有条件的信任论点外,我们未包括所有代理感知之间的反馈循环;状态依赖的收益权重可以解决这一点。
另一个未来发展的领域是更明确地建模不同监管机构之间的竞争,这种竞争往往为了资源和群体选择而展开[60, [61]
此外,我们简化了代理之间的信息和监管流动。通常,媒体和学术界承担着传达和解释有关参与者情绪和信任的信息的角色。类似地,开发者的职责通常通过营销或其他供应商传递给用户,从而掩盖了许多AI系统的隐藏内容。监管机构也常常依赖机构和会计师进行调查和报告。未来的研究可以通过添加多个LLM代理的人群,假设每个角色,来明确考虑这些中介效应。
我们还评论一下LLM本身。测试AI代理在战略游戏中扮演主要角色的能力对于准备其在不同应用中的使用至关重要,并可能揭示简单建模方法必然忽略的非线性和复杂性。然而,LLM的黑箱性质要求仔细评估和解释结果。随着改进其可解释性的研究进展[62, [63]
总体而言,尽管存在建模限制,我们的简单情景有助于思考政策制定者应该做出哪些假设,以促进安全开发AI的采用。关键在于,我们调查了基于游戏的AI系统会对这些假设提出什么建议,挑战其对AI景观主要参与者行为和战略决策的信任。这种构想可能具有价值,能够刺激推理和预测,以及基于复杂模型的策略决策。
致谢
这项工作是在“AI治理建模”研讨会期间完成的,得到了Future of Life研究所(T.A.H)的慷慨支持。T.A.H. 和 Z.S. 得到了EPSRC(资助编号EP/Y00857X/1)的支持。M.H.D 和 N.B. 得到了EPSRC(资助编号EP/Y008561/1)和皇家国际交流补助金IES-R3-223047的支持。E.F.D. 得到了F.W.O.高级博士后资助(12A7825N)的支持,A.M.F. 和 H.C.F. 得到了INESC-ID和项目CRAI C645008882- 00000055/510852254(IAPMEI/PRR)的支持。D.P. 得到了欧盟通过ERC IN-SPIRE资助(项目编号101076926)的支持;然而,表达的观点和意见仅属于作者,不一定反映欧盟、欧洲研究委员会执行机构或欧洲委员会的观点。
[1] Y. Bengio, G. Hinton, A. Yao, D. Song, P. Abbeel 等, “管理极端AI风险在快速进步中,” Science, vol. 384, no. 6698, pp. 842–845, May 2024. [Online]. Available: https://www.science.org/doi/abs/10.1126/science.adn0117
[2] L. Floridi, J. Cowls, M. Beltrametti, R. Chatila, P. Chazerand, V. Dignum, C. Luetge, R. Madelin, U. Pagallo, F. Rossi 等, “Ai4people—一个良好的AI社会的伦理框架:机会、风险、原则和建议,” Minds and machines, vol. 28, pp. 689–707, 2018.
[3] T. Baker, “关于安全、安全和值得信赖的AI的行政命令:解读拜登的AI政策路线图,” Nov. 2023.
[4] G. Finocchiaro, “人工智能的监管,” AI & SOCIETY, vol. 39, no. 4, pp. 1961–1968, 2024.
[5] L. Hammond, A. Chan, J. Clifton, J. Hoelscher-Obermaier, A. Khan, E. McLean, C. Smith, W. Barfuss, J. Foerster, T. Gavenˇciak, T. A. Han, E. Hughes, V. Kovaˇr´ık, J. Kulveit, J. Z. Leibo, C. Oesterheld, C. S. de Witt, N. Shah, M. Wellman, P. Bova, T. Cimpeanu, C. Ezell, Q. Feuillade-Montixi, M. Franklin, E. Kran, I. Krawczuk, M. Lamparth, N. Lauffer, A. Meinke, S. Motwani, A. Reuel, V. Conitzer, M. Dennis, I. Gabriel, A. Gleave, G. Hadfield, N. Haghtalab, A. Kasirzadeh, S. Krier, K. Larson, J. Lehman, D. C. Parkes, G. Piliouras, 和 I. Rahwan, “来自高级AI的多方风险,” 2025. [Online]. Available: https://arxiv.org/abs/2502.14143
- [6] Y. Bengio, S. Mindermann, D. Privitera, T. Besiroglu, R. Bommasani, S. Casper, Y. Choi, P. Fox, B. Garfinkel, D. Goldfarb 等, “国际AI安全报告,” arXiv preprint arXiv:2501.17805, 2025.
-
- [7] S. T. Powers, O. Linnyk, M. Guckert, J. Hannig, J. Pitt, N. Urquhart, A. Ek´art, N. Gumpfer, T. A. Han, P. R. Lewis 等, “我们在其中游泳:单独依靠法规不会带来对AI的正当信任,” IEEE Technology and Society Magazine, vol. 42, no. 4, pp. 95–106, 2024.
-
- [8] J. Laux, S. Wachter 等, “值得信赖的人工智能和欧盟AI法案:关于可信性和风险接受性的混淆,” Regulation & Governance, vol. 18, no. 1, pp. 3–32, 2024.
-
- [9] C. Siegmann 和 M. Anderljung, “布鲁塞尔效应与人工智能,” Oct. 2022.
-
- [10] J. Tallberg, E. Erman 等, “人工智能全球治理:实证和规范研究的下一步,” International Studies Review, vol. 25, no. 3, p. viad040, 2023, 私人与公共监管.
-
- [11] J. Clark 和 G. K. Hadfield, “AI安全的监管市场,” arXiv, Dec. 2019.
-
- [12] M. Anderljung, J. Barnhart 等, “前沿AI监管:管理新兴公共安全风险,” Jul. 2023.
-
- [13] R. Clarke, “AI的监管替代方案,” Computer Law & Security Review, vol. 35, no. 4, pp. 398–409, 2019.
-
- [14] A. Dafoe, “AI治理:概述和理论视角,” 在《牛津AI治理手册》中, J. B. Bullock, Y.-C. Chen, J. Himmelreich, V. M. Hudson, A. Korinek, M. M. Young, 和 B. Zhang 编辑. Oxford University Press, 2023, p. 0.
-
- [15] G. K. Hadfield 和 J. Clark, “监管市场:AI治理的未来,” Apr. 2023.
-
- [16] E. Zaidan 和 I. A. Ibrahim, “在复杂且迅速变化的监管环境中的人工智能治理:全球视角,” Humanities and Social Sciences Communications, vol. 11, no. 1, pp. 1–18, 2024.
-
- [17] Z. Alalawi, P. Bova, T. Cimpeanu, A. Di Stefano, M. H. Duong, E. F. Domingos, T. A. Han, M. Krellner, B. Ogbo, S. T. Powers 等, “信任AI监管?辨别用户对于建立信任和有效AI监管至关重要,” arXiv preprint arXiv:2403.09510, 2024.
-
- [18] D. Kondor, V. Hafez, S. Shankar, R. Wazir, 和 F. Karimi, “从复杂系统角度评估人工智能风险,” Philosophical Transactions A, vol. 382, no. 2285, p. 20240109, 2024.
-
- [19] K. J. D. Chan, G. Papyshev, 和 M. Yarime, “平衡人工智能的监管与创新:自上而下的命令控制和自下而上的自我监管方法分析,” Technology in Society, vol. 79, p. 102747, 2024.
-
- [20] P. Bova, A. Di Stefano, 和 T. A. Han, “双目睁开:警惕激励措施有助于提高AI安全性,” Journal of Physics: Complexity, vol. 5, no. 2, p. 025009, 2024.
-
- [21] T. A. Han, L. M. Pereira 等, “是否监管:理想化AI竞赛的社会动力学分析,” Journal of Artificial Intelligence Research, vol. 69, pp. 881–921, Nov. 2020.
-
- [22] E. Commission, “人工智能与未来的工作,” https://europa.eu/eurobarometer/surveys/detail/3222, 2025.
-
- [23] IPSOS, “2024年IPSOS AI监测:关于AI及其带来的未来的态度和感受的变化,” https://www.ipsos.com/en-uk/ipsos-ai-monitor-2024-changing-attitudes-and-feelings-about-aiand-future-it-will-bring, 2024.
-
- [24] T. A. Han, C. Perret, 和 S. T. Powers, “何时(或不)信任智能机器:重复博弈中信任的进化博弈论分析洞察,” Cognitive Systems Research, vol. 68, pp. 111–124, 2021.
-
- [25] A. Buscemi 和 D. Proverbio, “Roguegpt:不道德调优使ChatGPT4在158字内变成流氓AI,” arXiv preprint arXiv:2407.15009, 2024.
-
- [26] P. Andras, L. Esterle, M. Guckert, T. A. Han, P. R. Lewis, K. Milanovic, T. Payne, C. Perret, J. Pitt, S. T. Powers 等, “信任智能机器:深化技术系统中的信任,” IEEE Technology and Society Magazine, vol. 37, no. 4, pp. 76–83, 2018.
-
- [27] S. Armstrong, N. Bostrom 等, “奔向悬崖:人工智能发展模型,” Ai & Society, vol. 31, no. 2, pp. 201–206, May 2016.
-
- [28] A. Askell, M. Brundage 等, “合作在负责任AI开发中的作用,” arXiv, Jul. 2019.
-
- [29] B. Cottier, T. Besiroglu 等, “谁在AI领域领先?对行业AI研究的分析,” 2024.
-
- [30] P. Cihon, M. J. Kleinaltenkamp 等, “AI认证:通过减少信息不对称推进道德实践,” IEEE Transactions on Technology and Society, vol. 2, no. 4, pp. 200–209, Dec. 2021.
-
- [31] D. C. North, Institutions, institutional change and economic performance. Cambridge university press, 1990. [32] J. Hofbauer 和 K. Sigmund, Evolutionary games and population dynamics. Cambridge university press,
-
- 1998. [33] K. Sigmund, “自私的微积分,” 在The Calculus of Selfishness. Princeton University Press, 2010.
-
- [34] J. S. Park, J. O’Brien, C. J. Cai, M. R. Morris, P. Liang, 和 M. S. Bernstein, “生成型代理:人类行为的交互式仿真,” 在Proceedings of the 36th annual acm symposium on user interface software and technology, 2023, pp. 1–22.
-
- [35] C. A. Bail, “生成型AI能否改善社会科学?” Proceedings of the National Academy of Sciences, vol. 121, no. 21, p. e2314021121, 2024.
-
- [36] W. X. Zhao, K. Zhou, J. Li, T. Tang, X. Wang, Y. Hou, Y. Min, B. Zhang, J. Zhang, Z. Dong 等, “大型语言模型综述,” arXiv preprint arXiv:2303.18223, vol. 1, no. 2, 2023.
-
- [37] A. Buscemi 和 D. Proverbio, “大型语言模型检测报纸的政治倾向,” arXiv preprint arXiv:2406.00018, 2024.
-
- [38] ——, “Chatgpt vs Gemini vs Llama在多语言情感分析中的比较,” arXiv preprint arXiv:2402.01715, 2024.
-
- [39] N. Lee, J. Hong, 和 J. Thorne, “评估LLM评估者的一致性,” arXiv preprint arXiv:2412.00543, 2024.
-
- [40] OpenAI. (2023) Introducing chatgpt. [Online]. Available: https://openai.com/blog/chatgpt
-
- [41] M. AI. (2025) Au large. [Online]. Available: https://mistral.ai/news/mistral-large
-
- [42] Y. Lu, A. Aleta, C. Du, L. Shi, 和 Y. Moreno, “LLMs和生成型代理模型用于复杂系统研究,” Physics of Life Reviews, 2024.
-
- [43] Z. Song 和 T. A. Han, “关于非约束承诺的演变,” Physics of Life Reviews, vol. 52, pp. 245–247, 2025.
-
- [44] P. A. Van Lange, J. Joireman, C. D. Parks, 和 E. Van Dijk, “社会困境心理学:综述,” Organizational Behavior and Human Decision Processes, vol. 120, no. 2, pp. 125–141, 2013.
-
- [45] N. Balabanova, A. Bashir, P. Bova, A. Buscemi, T. Cimpeanu, H. C. da Fonseca, A. Di Stefano, M. H. Duong, E. F. Domingos, A. Fernandes 等, “媒体与负责任的AI治理:博弈论和LLM分析,” arXiv preprint arXiv:2503.09858, 2025.
-
- [46] M. A. Nowak, “合作进化的五条规则,” science, vol. 314, no. 5805, pp. 1560–1563, 2006.
-
- [47] S. Van Segbroeck, J. M. Pacheco, T. Lenaerts, 和 F. C. Santos, “重复群体互动中公平性的出现,” Physical review letters, vol. 108, no. 15, p. 158104, 2012.
-
- [48] A. Buscemi, D. Proverbio, A. Distefano, T. Han, 和 P. Li`o, “Fairgame:使用博弈论识别AI代理偏见的框架,” 准备中, 2025.
-
- [49] M. A. Nowak, A. Sasaki, C. Taylor, 和 D. Fudenberg, “有限种群中合作的出现和进化稳定性,” Nature, vol. 428, no. 6983, pp. 646–650, 2004.
-
- [50] I. Zisis, S. Di Guida, T. A. Han, G. Kirchsteiger, 和 T. Lenaerts, “由接受驱动的慷慨:预期游戏的进化分析,” Scientific reports, vol. 5, no. 1, p. 18076, 2015.
-
- [51] D. G. Rand, C. E. Tarnita, H. Ohtsuki, 和 M. A. Nowak, “一次性匿名最后通牒游戏中公平性的进化,” Proceedings of the National Academy of Sciences, vol. 110, no. 7, pp. 2581–2586, 2013.
-
- [52] A. Vidler 和 T. Walsh, “使用大型语言模型玩游戏:随机性和策略,” arXiv preprint arXiv:2503.02582, 2025.
-
- [53] Y. Deng, Z. Li, S. Mahadevan, 和 Z. Song, “零阶算法优化Softmax注意力,” in 2024 IEEE International Conference on Big Data (BigData). IEEE, 2024, pp. 24–33.
-
- [54] Z. Alalawi, T. A. Han, Y. Zeng, 和 A. Elragig, “通往良好医疗服务和患者满意度的路径:基于进化博弈论的方法,” in Artificial Life Conference Proceedings. MIT Press One Rogers Street, Cambridge, MA 02142-1209, USA journals-info . . . , 2019, pp. 135–142.
-
- [55] H. Chen 和 J. Hou, “智能数据治理:使用KG和LLM构建企业数据管理系统,” in Proceedings of the 2024 International Conference on Cloud Computing and Big Data, 2024, pp. 266–271.
-
- [56] M. Kinniment, L. J. K. Sato, H. Du, B. Goodrich, M. Hasin 等, “评估语言模型代理在真实自主任务中的表现,” Jan. 2024. [Online]. Available: http://arxiv.org/abs/2312.11671
-
- [57] GOV.UK, “介绍AI安全研究所,” https://www.gov.uk/government/publications/ai-safetyinstitute-overview/introducing-the-ai-safety-institute, 2023.
-
- [58] J. Ahn, R. Verma, R. Lou, D. Liu, R. Zhang, 和 W. Yin, “大型语言模型用于数学推理:进展与挑战,” arXiv preprint arXiv:2402.00157, 2024.
-
- [59] E. H. Hagen 和 P. Hammerstein, “博弈论与人类进化:对实验博弈的一些近期解释的批评,” Theoretical population biology, vol. 69, no. 3, pp. 339–348, 2006.
-
- [60] P. Richerson, R. Baldini, A. V. Bell, K. Demps, K. Frost, V. Hillis, S. Mathew, E. K. Newton, N. Naar, L. Newson 等, “文化群体选择在解释人类合作中起着重要作用:证据草图,” Behavioral and Brain Sciences, vol. 39, p. e30, 2016.
-
- [61] J. C. van den Bergh 和 J. M. Gowdy, “从群体选择视角看经济行为、制度和组织,” Journal of Economic Behavior & Organization, vol. 72, no. 1, pp. 1–20, 2009.
-
- [62] R. Ali, F. Caso, C. Irwin, 和 P. Li`o, “Entropy-lens:变压器计算的信息签名,” arXiv preprint arXiv:2502.16570, 2025.
-
- [63] B. El, D. Choudhury, P. Li`o, 和 C. K. Joshi, “通过注意力图实现图变压器的机械可解释性,” arXiv preprint arXiv:2502.12352, 2025.
参考 Paper:https://arxiv.org/pdf/2504.08640
- [63] B. El, D. Choudhury, P. Li`o, 和 C. K. Joshi, “通过注意力图实现图变压器的机械可解释性,” arXiv preprint arXiv:2502.12352, 2025.



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











