






本杰明·利普金
⋆
1
{ }^{\star 1}
⋆1 本杰明·勒布朗
⋆
5
{ }^{\star 5}
⋆5 霍弗·维格利
1
{ }^{1}
1 若昂·卢拉
1
{ }^{1}
1 大卫·R·麦克维尔
8
{ }^{8}
8 杜立
6
{ }^{6}
6 杰森·艾斯纳
6
{ }^{6}
6 瑞安·科特雷尔
2
{ }^{2}
2 维卡什·曼辛格哈卡
1
{ }^{1}
1 蒂莫西·J·奥唐奈
[
3
,
4
,
5
{ }^{[3,4,5}
[3,4,5 亚历山大·K·刘
[
1
,
7
{ }^{[1,7}
[1,7 蒂姆·维埃拉
[
2
{ }^{[2}
[2
1
{ }^{1}
1 麻省理工学院
2
{ }^{2}
2 苏黎世联邦理工学院
3
麦吉尔大学
4
{ }^{3} \mathrm{麦吉尔大学}{ }^{4}
3麦吉尔大学4 加拿大 CIFAR AI 主席
5
M
i
l
a
{ }^{5} \mathrm{Mila}
5Mila
6
{ }^{6}
6 约翰霍普金斯大学
7
{ }^{7}
7 耶鲁大学
8
C
H
I
{ }^{8} \mathrm{CHI}
8CHI FRO
摘要
在受某些约束条件影响的语言模型生成过程中,主导方法是局部约束解码(LCD),它以增量方式在每个时间步骤对令牌进行采样,从而确保约束条件不会被违反。通常,这是通过令牌屏蔽实现的:遍历词汇表并排除不符合条件的令牌。这种方法存在两个重要问题。(i) 对每个令牌评估约束可能代价过高——语言模型的词汇量通常超过100,000个令牌。(ii) LCD可能会扭曲字符串上的全局分布,仅基于局部信息采样令牌,即使它们会导致死胡同路径。本文引入了一种新算法来解决这两个问题。首先,为了避免在每一步生成时对整个词汇表评估约束,我们提出了一种自适应拒绝采样算法,该算法通常需要比传统方法少几个数量级的约束评估。其次,我们展示了如何扩展此算法以产生低方差、无偏的权重估计,这些估计可以安全地用于之前提出的顺序蒙特卡洛算法中,以纠正局部约束执行的短视行为。通过在文本到SQL、分子合成、目标推理、模式匹配和JSON领域的广泛实证评估,我们表明我们的方法优于最先进的基线方法,支持更广泛的约束类别,并改进了运行时间和性能。进一步的理论和实证分析显示,我们方法的运行效率得益于其动态使用计算的能力,随着无约束与受约束LM之间的差异而变化,因此对于更好的模型,运行时间改进更大。
1 引言
许多科学和工程学科中的任务可以通过从语言模型中生成符合硬约束的字符串来进行受控生成。例如,我们可能希望生成与某个端点匹配的API调用,生产与数据库模式一致的SQL查询,或者设计满足目标规格的分子。在这些设置中的主要方法是局部约束解码(LCD),它强制每个采样的令牌都符合约束条件(Lu等人,2021;Shin等人,2021;Scholak等人,2021;Lu等人,2022;Poesia等人,2022;Shin & Van Durme,2022;Geng等人,2023;Beurer-Kellner等人,2024;Huang等人,2024;Moskal等人,2024;Ugare等人,2024;Wang等人,2024a;Zheng等人,2024;Banerjee等人,2025)。
1
{ }^{1}
1
这种方法遭受两个关键缺点。首先,通过枚举令牌屏蔽从中采样的典型方法可能很慢。完全屏蔽要求
*共同第一作者,${ }^{\mathrm{I}}$ 共同资深作者。联系人: lipkinb@mit.edu \& tim.f.vieira@gmail.com ${ }^{1}$ 本文专注于运行时控制,但我们还注意到许多基于训练的控制方法(例如,Ziegler等人,2019;Stiennon等人,2020;Bai等人,2022;Ouyang等人,2022;Rafailov等人,2023)。
检查约束条件是否适用于词汇表中的每一项——这通常包括超过100,000个令牌——然后最终进行过滤、重新归一化和采样。在一些特殊情况下,例如当约束条件可以用正则或上下文无关语法表示时,可用优化使检查每个令牌变得可行(Willard & Louf,2023;Kuchnik等人,2023;Koo等人,2024;Ugare等人,2024;Dong等人,2024)。然而,对于黑盒约束,这些优化并不适用。其次,正如经常观察到的那样(例如,Lew等人,2023;Park等人,2024;Ahmed等人,2025;Loula等人,2025),通过对局部分布(令牌)进行重新归一化,这种方法可能会扭曲全局分布(字符串)。由于LCD在每一步短视地强制执行约束条件,它有时会贪婪地采样进入序列空间的低概率区域(见$\S 2$讨论)。
几篇论文注意到了这个问题,并提出了将受控生成作为概率调节的方法,将问题视为后验推断(Rosenfeld等人,2001;Miao等人,2020;Krause等人,2021;Yang & Klein,2021;Meng等人,2022;Qin等人,2022;Shih等人,2023;Zhang等人,2023;Hu等人,2024;Zhang等人,2024a)。在此框架下,可以使用近似推断方法——例如,重要性采样(IS)或序贯蒙特卡罗(SMC)——将从局部约束分布采样的序列修正为目标全局后验(Börschinger & Johnson,2011;Dubbin & Blunsom,2012;Yang & Eisenstein,2013;Buys & Blunsom,2015;Lin & Eisner,2018;Lew等人,2023;Zhao等人,2024;Puri等人,2025;Loula等人,2025)。
评估生成序列质量的关键诊断量是LM在每个时间步长下的局部下一个令牌分布对约束的边际概率,定义为 $Z \stackrel{\text { def }}{=} \sum_{x \in \mathcal{X}} p_{0}(x) \mathbb{1}_{Z}(x)$,其中 $p_{0}$ 是LM在词汇表 $\mathcal{X}$ 上的下一个令牌分布,$\mathbb{1}_{Z}$ 检查给定令牌是否在当前时间步长符合约束。在顺序IS或SMC中,$Z$ 出现为增量重要性权重更新。当这个量较低时,我们已经到达了一个难以采样任何满足约束的序列继续点。对于特定的SMC,这可以用于在后续重采样期间重新分配计算到更有前途的序列。使用令牌屏蔽,计算 $Z$ 的方法显而易见——只需对所有未屏蔽的令牌求和即可。然而,如果我们想从局部约束令牌分布中采样而不对整个词汇表评估 $\mathbb{1}_{Z}$,这个量可能无法直接获得,我们必须寻求估计它。
在本文中,我们介绍了一种比令牌屏蔽快得多的精确采样器,通常快几个数量级。我们的算法基于拒绝采样,因此是一种拉斯维加斯算法,即具有随机运行时间的精确算法。与其为每一步使用固定计算量,计算根据需要动态缩放。此外,我们导出了可用于在SMC中全局校正样本的无偏估计量 $Z$。
我们的核心贡献如下:
- 一种与任意约束兼容的快速拉斯维加斯采样算法。我们开发了自适应加权拒绝采样(AWRS),这是一种用于受约束生成的采样算法。与其他拒绝采样算法类似,我们方法的成本随约束难度增加而增加。然而,我们的自适应算法通过利用下一个令牌分布的尖峰性,超越了标准拒绝采样。由于该算法的速度,我们可以舒适地评估任意黑盒约束。
-
- 随机估计 Z Z Z 以纠正贪婪性。我们开发了一种方法来计算AWRS的低方差、无偏估计量 Z Z Z,支持其在近似推断方法如SMC中的集成。
-
- 运行时分析。我们在理论上和实证上描述了受限解码的工作量,具体体现在LM的无条件下一个令牌分布与条件目标分布之间的概率更新上。关键在于,AWRS在基础模型更能捕捉约束时运行更快——这意味着我们的方法对于更准确的LM更加高效。
-
- 实证评估。我们在五个具有挑战性的受控生成基准上评估了AWRS以及几种最先进的基线方法。AWRS在相关比较中提高了表达性、运行时间和准确性。
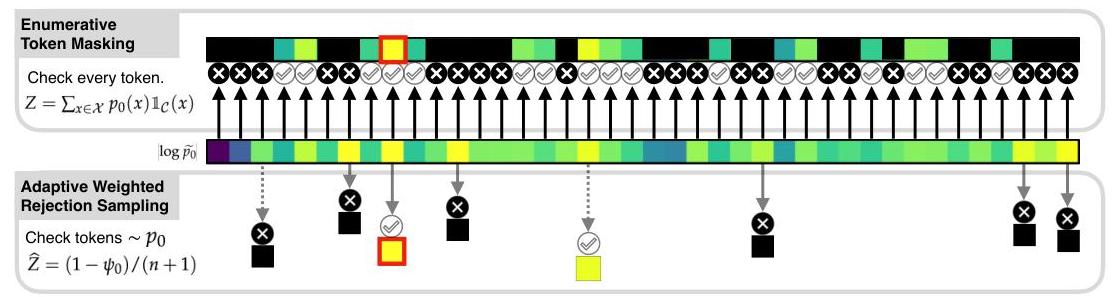
图1:我们的方法(底部)与枚举令牌屏蔽(顶部)相比。只检查了一部分令牌,同时从相同的分布中采样。
2 背景
局部约束解码(LCD)。一个字母表
X
\mathcal{X}
X 上的语言模型
P
0
P_{0}
P0 是字符串集
X
∗
\mathcal{X}^{*}
X∗ 上的概率分布。我们用
x
x
x 表示单个令牌,用
x
x
x 表示完整字符串。全局约束函数
1
L
:
X
∗
→
{
0
,
1
}
\mathbb{1}_{\mathcal{L}}: \mathcal{X}^{*} \rightarrow\{0,1\}
1L:X∗→{0,1} 编码了一组有效字符串
L
⊆
X
∗
\mathcal{L} \subseteq \mathcal{X}^{*}
L⊆X∗。受控生成的问题可以表示为从LM中采样
x
∼
P
\boldsymbol{x} \sim P
x∼P,其中
P
=
def
P
0
(
⋅
∣
x
∈
L
)
P \stackrel{\text { def }}{=} P_{0}(\cdot \mid \boldsymbol{x} \in \mathcal{L})
P= def P0(⋅∣x∈L),即从LM中采样一个满足约束条件的完整字符串,同时保留可能字符串的相对概率。这种后者属性区分了正确的全局调节与任意约束采样。
在字符串的自回归生成过程中,有时可以评估采样任何给定令牌是否会立即违反约束条件。例如,如果约束要求写一个没有单词超过5个字符的句子,则“north”的唯一可能延续应诱导词边界,而不是继续为“ern”或“east”。在每一步生成过程中,基于当前字符串前缀
x
p
x_{p}
xp,我们假设可以访问一个局部约束函数
1
C
:
X
→
{
0
,
1
}
\mathbb{1}_{\mathcal{C}}: \mathcal{X} \rightarrow\{0,1\}
1C:X→{0,1},编码一组有效的下一个令牌
C
⊆
X
\mathcal{C} \subseteq \mathcal{X}
C⊆X,使得
x
∉
C
⟹
∀
x
,
x
p
x
x
s
∉
L
x \notin \mathcal{C} \Longrightarrow \forall x, x_{p} x x_{s} \notin \mathcal{L}
x∈/C⟹∀x,xpxxs∈/L。也就是说,如果局部约束函数拒绝令牌
x
x
x,就没有有效的延续以
x
x
x 开始的
x
p
x_{p}
xp。
固定前缀
x
p
x_{p}
xp,令
p
0
p_{0}
p0 表示LM的局部先验分布在下一个令牌上——请注意此分布受前面令牌的影响。在每一步,LCD从由局部约束函数诱导的局部后验分布
p
p
p 中采样下一个令牌:
p ( x ) = def 1 Z p ~ ( x ) p ~ ( x ) = def p 0 ( x ) 1 C ( x ) Z = def ∑ x ∈ X p ~ ( x ) p(x) \stackrel{\text { def }}{=} \frac{1}{Z} \widetilde{p}(x) \quad \widetilde{p}(x) \stackrel{\text { def }}{=} p_{0}(x) \mathbb{1}_{\mathcal{C}}(x) \quad Z \stackrel{\text { def }}{=} \sum_{x \in \mathcal{X}} \widetilde{p}(x) p(x)= def Z1p (x)p (x)= def p0(x)1C(x)Z= def x∈X∑p (x)
其中
p
~
\widetilde{p}
p
是其未标准化密度,
Z
Z
Z 是其标准化常数。(注意
0
<
Z
≤
1
0<Z \leq 1
0<Z≤1。)直观地说,
Z
Z
Z 是在
p
0
p_{0}
p0 下满足局部约束的总概率。最常见的LCD实现方法是令牌屏蔽:在生成过程中精确计算
p
p
p,通过在词汇表中的每个项目上评估
1
C
\mathbb{1}_{\mathcal{C}}
1C,将不可能的令牌置零,对剩余部分求和以计算
Z
Z
Z,并重新归一化以获得
p
p
p(图1,顶部)。
通过在每个令牌处应用局部约束,LCD可以贪婪地采样进入低概率序列,这些序列很难或不可能恢复。例如,在生成一个单词不超过5个字符的句子的约束下,尽管直到这一点都没有问题,LM仍会努力完成前缀 “The Fed says the cost of a 30-yr fixed mortg”(参见Lew等人,2023)。
有趣的是,此类死胡同可以通过恰好作为LCD副产品的
Z
Z
Z 量来检测。当
Z
Z
Z 很低时,我们已达到字符串生成的一个点,只有很少的、不太可能的令牌可以延续该字符串。
2
{ }^{2}
2 这个局部
Z
Z
Z
${ }^{2}$ 为什么是 $Z$ 而不是序列概率?虽然优化序列概率的方法(如束搜索)部分解决了样本质量的要求,但存在一些注意事项。如果有很多有效令牌,其总和很大,但每个个体令牌的概率很低,那么序列概率将不公平地惩罚任何令牌(Koehn & Knowles,2017;Murray & Chiang,2018;Cohen & Beck,2019;Stahlberg & Byrne,2019)。考虑 $Z$ 的方法不遭受此缺点。
可以在序贯蒙特卡洛(SMC)中用于重新加权部分生成(粒子)以便于后续重采样步骤,这往往消除不令人满意的字符串前缀并重复更有希望的前缀(附录A 和算法1)。在这种情况下——LCD用作SMC中的提议分布——$Z$ 正是可以通过简化重要性权重得出的增量校正因子(Naesseth等人,2019)。
由于 $Z$ 是令牌屏蔽的副产品,此算法在作为SMC中的提议分布的一部分时提供自己的校正因子。然而,现代LM通常有超过100,000个令牌的词汇表;在该集合中的每个令牌上评估 $\mathbb{1}_{C}$ 并且因此精确计算 $Z$ 通常是极其缓慢的。最初似乎在这些情况下从局部后验 $p$ 中精确采样和用 $Z$ 进行精确权重校正是不切实际的。
在接下来的部分中,我们开发了一种从局部后验 $p$ 中采样的方法,它是精确的,适合大型词汇表,通常在平均时间内较快,并提供了校正因子以校正LCD的贪婪性。
简单拒绝采样。简单拒绝采样是一种无需循环遍历整个令牌词汇表即可从
p
p
p 提供精确样本的算法。它通过从
p
0
p_{0}
p0 中抽取令牌
x
x
x,然后检查令牌是否满足
1
C
(
x
)
\mathbb{1}_{C}(x)
1C(x) 来工作。如果是,则返回该令牌;否则,重复此过程。返回的令牌是从
p
p
p 中精确抽取的样本。
与令牌屏蔽的恒定成本相比,这是一个拉斯维加斯算法,即具有随机运行时间的精确算法。很容易证明该算法在满足约束之前的预期抽样次数为
1
2
\frac{1}{2}
21;还可以证明
D
K
L
(
p
∥
p
0
)
=
−
log
Z
D_{K L}\left(p \| p_{0}\right)=-\log Z
DKL(p∥p0)=−logZ (Levy,2008;Freer等人,2010),因此预期运行时间为
D
K
L
(
p
∥
p
0
)
D_{K L}\left(p \| p_{0}\right)
DKL(p∥p0) 的指数倍。当约束相对容易满足(即,当
Z
≈
1
Z \approx 1
Z≈1 时,所以
D
K
L
(
p
∥
p
0
)
D_{K L}\left(p \| p_{0}\right)
DKL(p∥p0) 较低),这可能导致比全词汇表令牌屏蔽所需的运行时间快得多的情况。然而,当
Z
Z
Z 非常小
(
Z
<
∣
X
∣
−
1
)
\left(Z<|\mathcal{X}|^{-1}\right)
(Z<∣X∣−1),拒绝采样的运行时间甚至比令牌屏蔽更糟糕。
自适应拒绝采样(ARS)。自适应拒绝采样(Gilks & Wild,1992;Mansinghka等人,2009)是一种永远不会比令牌屏蔽更慢且通常显著更快的拒绝采样版本。在ARS中,我们在拒绝采样过程中自适应地移除遇到的每个无效令牌,这样我们永远不会两次采样同一个被拒绝的令牌。这一简单的修改可以极大地提高算法的运行时间(图F.2)。
两种拒绝采样方法都只在其绘制的样本上评估
1
C
\mathbb{1}_{C}
1C,因此可以比令牌屏蔽更高效。然而,两者都无法直接精确计算
Z
Z
Z。这个问题的解决方案来自于以下观察:对于SMC,足以使用独立的无偏估计量来代替每个局部
Z
Z
Z,而不是精确值,作为校正因子(附录A和算法2;Naesseth等人,2015)。
3 我们的算法
作为令牌屏蔽副产物得到的昂贵但精确的校正因子的替代方案,我们希望找到廉价的、无偏的
Z
Z
Z 的估计值,这些估计值可以作为简单或自适应拒绝采样的副产物计算。
我们向此目标迈出的第一步是认识到在生成有效下一个令牌
x
x
x 之前的被拒绝的令牌数量包含有关
Z
Z
Z 的大小的信息:当生成大量被拒绝的令牌时,这表明
Z
Z
Z 很小,可以作为当前前缀
x
p
x_{p}
xp 已落入全局后验
P
P
P 的低概率区域的标志。
实际上,在简单拒绝采样中,试验次数
n
0
+
1
n_{0}+1
n0+1(即,
n
0
n_{0}
n0 次拒绝加上最终的成功)是对
1
/
Z
1 / Z
1/Z 的无偏估计。不幸的是,
1
/
(
n
0
+
1
)
1 /\left(n_{0}+1\right)
1/(n0+1) 不是对
Z
Z
Z 的无偏估计,我们需要无偏估计
Z
Z
Z 才能正确地将其用于SMC。自适应拒绝采样中的偏差更严重,因为即使当
Z
Z
Z 很小时,我们可能只会采样少量拒绝,限制了
n
0
n_{0}
n0 作为关于
Z
Z
Z 的可靠信息来源的有用性。
3.1 预热:加权拒绝采样(WRS)
在简单拒绝采样的设定中,我们可以通过运行 L ≥ 1 L \geq 1 L≥1 个额外的拒绝循环来收集更多关于 Z Z Z 的数据。除了减少方差外,这还现在产生了对 Z Z Z 的无偏估计。达到 L + 1 L+1 L+1 次成功的所需总试验次数 T T T(拒绝和成功)服从参数为 Z ~ \tilde{Z} Z~ 和 L + 1 L+1 L+1 的负二项分布。让 n = ∑ i = 0 L n i n=\sum_{i=0}^{L} n_{i} n=∑i=0Lni 表示 L + 1 L+1 L+1 次循环中的总拒绝次数,
Z ~ = def L T − 1 = L ( n + ( L + 1 ) ) − 1 = L n + L \tilde{Z} \stackrel{\text { def }}{=} \frac{L}{T-1}=\frac{L}{(n+(L+1))-1}=\frac{L}{n+L} Z~= def T−1L=(n+(L+1))−1L=n+LL
是负二项分布的
Z
Z
Z 参数的一个已知的无偏估计量,前提是
L
≥
1
L \geq 1
L≥1(Forbes et al., 2011)。这允许我们定义以下算法,用于从
p
p
p 中联合生成下一个令牌
x
x
x 和对
Z
Z
Z 的无偏估计
Z
~
\tilde{Z}
Z~。
定义 1. 给定一个未标准化的目标
p
~
\tilde{p}
p~ 如上所述,加权拒绝采样生成
⟨
x
,
Z
~
⟩
∼
Q
WRS
\langle x, \tilde{Z}\rangle \sim Q_{\text {WRS }}
⟨x,Z~⟩∼QWRS 如下:
- 运行拒绝采样以获得一个有效样本 x x x : 通过 n 0 n_{0} n0 次拒绝 r i r_{i} ri 直到获得接受的令牌 x ∈ C x \in \mathcal{C} x∈C 样本 ⟨ r 1 , … , r n 0 , x ⟩ ∼ p 0 \left\langle r_{1}, \ldots, r_{n_{0}}, x\right\rangle \sim p_{0} ⟨r1,…,rn0,x⟩∼p0。
-
- 对于预算为 L ≥ 1 L \geq 1 L≥1 的额外循环,重复第 1 步并计数每个循环中的拒绝次数 n 1 , … , n L n_{1}, \ldots, n_{L} n1,…,nL。
-
- 计算估计 Z ~ = def L n + L \tilde{Z} \stackrel{\text { def }}{=} \frac{L}{n+L} Z~= def n+LL,其中 n = ∑ i = 0 L n i n=\sum_{i=0}^{L} n_{i} n=∑i=0Lni。
-
- 返回
⟨
x
,
Z
~
⟩
\langle x, \tilde{Z}\rangle
⟨x,Z~⟩
NumPy中的实现可在清单1中找到。
命题 1. 对于 ⟨ x , Z ~ ⟩ ∼ Q W R S , x \langle x, \tilde{Z}\rangle \sim Q_{W R S}, x ⟨x,Z~⟩∼QWRS,x 按照 p p p 分布,且 E [ Z ~ ] = Z \mathbb{E}[\tilde{Z}]=Z E[Z~]=Z。
命题 2. Q W R S Q_{W R S} QWRS 的预期运行时间按 O ( L Z ) \mathcal{O}\left(\frac{L}{Z}\right) O(ZL) 扩展。
使用这些估计,简单拒绝采样可以安全地集成到SMC作为提议分布,支持对LCD贪心性的校正。 L = 1 L=1 L=1 就足够保证无偏性,并且我们发现它在实践中工作得很好,但 L L L 可以增加以换取更高的运行时间来减少方差(图F.1)。
- 返回
⟨
x
,
Z
~
⟩
\langle x, \tilde{Z}\rangle
⟨x,Z~⟩
3.2 自适应加权拒绝采样 (AWRS)
在自适应环境下,拒绝的数量减少了,负二项式估计量不再适用。但是,基于Lew等人的框架(2022年)的辅助变量论证可以推导出另一种公式,不仅基于拒绝数量,还基于从
p
0
p_{0}
p0 中移除的概率质量。
定义 2. 给定一个未标准化的目标
p
~
\tilde{p}
p~,AWRS生成
⟨
x
,
Z
~
⟩
∼
Q
A
W
R
S
\langle x, \tilde{Z}\rangle \sim Q_{A W R S}
⟨x,Z~⟩∼QAWRS 如下:
- 抽样 ⟨ r 1 , … , r n 0 , x ⟩ \left\langle r_{1}, \ldots, r_{n_{0}}, x\right\rangle ⟨r1,…,rn0,x⟩ 如下:从 n 0 n_{0} n0 个唯一的拒绝 r i r_{i} ri 抽取,直到获得 x ∈ C x \in \mathcal{C} x∈C。注意超出第一步后,我们不是从 p 0 p_{0} p0 中抽样,而是从 X \ r < i \mathcal{X} \backslash \mathbf{r}_{<i} X\r<i 上的重新归一化分布中抽样。
-
- 计算 ψ 0 = ∑ i = 1 n 0 p 0 ( r i ) \psi_{0}=\sum_{i=1}^{n_{0}} p_{0}\left(r_{i}\right) ψ0=∑i=1n0p0(ri)。
-
- 生成一个额外的轨迹 ⟨ s 1 , … , s n 1 , x ∗ ⟩ \left\langle s_{1}, \ldots, s_{n_{1}}, x^{*}\right\rangle ⟨s1,…,sn1,x∗⟩,通过从尚未被拒绝的元素中继续抽样,进行额外的 n 1 n_{1} n1 次新的唯一拒绝,直到找到一个元素 x ∗ x^{*} x∗。注意 x ∗ x^{*} x∗ 可能与 x x x 相同,因为接受的元素会被替换(不像拒绝的元素)。
-
- 计算估计 Z ~ = def 1 − ψ 0 n + 1 \tilde{Z} \stackrel{\text { def }}{=} \frac{1-\psi_{0}}{n+1} Z~= def n+11−ψ0,其中 n = n 0 + n 1 n=n_{0}+n_{1} n=n0+n1。
-
- 返回
⟨
x
,
Z
~
⟩
\langle x, \tilde{Z}\rangle
⟨x,Z~⟩
可以在Listing 2中找到NumPy的实现。
命题 3. 对于 ⟨ x , Z ~ ⟩ ∼ Q A W R S , x \langle x, \tilde{Z}\rangle \sim Q_{A W R S}, x ⟨x,Z~⟩∼QAWRS,x 按照 p p p 分布,且 E [ Z ~ ] = Z \mathbb{E}[\tilde{Z}]=Z E[Z~]=Z。
命题 4. Q A W R S Q_{A W R S} QAWRS 的期望运行时间按 O ( ∑ x ∉ C π x ) \mathcal{O}\left(\sum_{x \notin \mathcal{C}} \pi_{x}\right) O(∑x∈/Cπx) 扩展,其中 π x = def p 0 ( x ) p 0 ( x ) + Z \pi_{x} \stackrel{\text { def }}{=} \frac{p_{0}(x)}{p_{0}(x)+Z} πx= def p0(x)+Zp0(x),即相对于 Z Z Z 的每个非符合令牌的概率。
如上所述,AWRS生成下一个令牌和适合在SMC内使用的校正因子。此外,AWRS提供了显著的运行时间优势。显然,由于我们不能重新采样拒绝,我们必须在最多 ∣ X \ C ∣ |\mathcal{X} \backslash \mathcal{C}| ∣X\C∣ 拒绝步骤后成功——无效令牌的数量——无论 Z Z Z 有多小。AWRS也具有更低的期望运行时间。直观上,我们可以这样认为采样接受的时间:如果单个非符合令牌的质量可比或高于 Z Z Z,即所有符合令牌的总和,它可以被认为是一个干扰项。期望运行时间并非所有非符合令牌都同等贡献,而是仅由这些——通常是罕见的——干扰项主导。确切值在附录 G.2 中推导并进一步探讨。
- 返回
⟨
x
,
Z
~
⟩
\langle x, \tilde{Z}\rangle
⟨x,Z~⟩
4 实验
我们的实验测量了我们方法在不同领域5个任务中的准确性和运行时间的实际影响。 3 { }^{3} 3 我们使用任务特定的度量标准而不是评估采样器内部行为(例如,它如何准确估计 Z Z Z ),但请参见图3和附录F。我们将AWRS与强基线进行比较,考虑了两个版本:ARS-LCD,它使用无权重的自适应拒绝采样进行简单的LCD;AWRS-SMC,它在SMC内使用加权版本。
方法。我们首先比较以下未经校正的方法在运行时间和下游任务准确性方面的表现。本节中的方法产生 M = 1 M=1 M=1 个无权重样本:
- 基础语言模型(Base LM)。从未强迫任何约束条件下从语言模型中采样序列,即采样 x ∼ P 0 \boldsymbol{x} \sim P_{0} x∼P0。
-
- 使用令牌屏蔽进行局部约束解码(TM-LCD)。约束解码的标准方法。我们屏蔽整个令牌词汇表,重新归一化并采样。 4 { }^{4} 4
-
- 使用自适应拒绝采样进行局部约束解码(ARS-LCD)。LCD的更快实现:而不是屏蔽整个词汇表,我们从相同的LCD分布中使用ARS绘制样本。(我们尚未使用重要性权重校正,因此我们只运行第一个拒绝循环。)
- 上述基线使我们能够衡量自适应拒绝采样在多大程度上改善了运行时间。我们下一组方法超出了LCD,返回一个加权的 M M M 个字符串集合,使得集合中 x x x 的期望权重为 P 0 ( x ) ⋅ 1 L ( x ) ∝ P ( x ) P_{0}(x) \cdot \mathbb{1}_{\mathcal{L}}(x) \propto P(x) P0(x)⋅1L(x)∝P(x)。
-
- 样本验证。从语言模型中采样 M M M 个完整字符串,并根据 1 L \mathbb{1}_{\mathcal{L}} 1L 对其加权(相当于丢弃不在 L \mathcal{L} L 中的字符串)。 5 { }^{5} 5
-
- 使用约束作为扭曲的顺序蒙特卡罗(Twisted SMC)。直接从语言模型中采样令牌,但在使用令牌 x x x 扩展部分序列后使用 1 L ( x ) \mathbb{1}_{\mathcal{L}}(x) 1L(x) 作为扭曲函数来过滤部分序列。请注意,这与 Loula 等人(2025)中的可编程扭曲不同,而非学习型扭曲(Naesseth 等人,2019;Lawson 等人,2022)。
-
-
使用 AWRS 提议的顺序蒙特卡罗(AWRS-SMC)。使用 AWRS 算法作为 SMC 的提议分布。与 ARS-LCD 类似,该方法使用自适应拒绝采样循环生成标记,但确实计算了校正因子。
3 { }^{3} 3 我们注意到,我们的实现都是用纯 Python 编写的,并且相对未优化。本文呈现的运行时间改进纯粹是由算法进步驱动的。作为一种灵活的即插即用方法,我们鼓励系统实践者捕获许多未开发的速度提升。我们在附录 H.1 中概述了一个部分并发的例子。
4 { }^{4} 4 由于完整令牌屏蔽的高成本,我们仅在其中一个基准测试中包含此基线,以说明我们的数量级加速。
5 { }^{5} 5 这个基线是一种常见的方法,用于将约束纳入LM生成管道(Cobbe 等人,2021;Hendrycks 等人,2021;Nakano 等人,2021;Ahn 等人,2022;Shi 等人,2022;Uesato 等人,2022;Olausson 等人,2023;Lightman 等人,2023;Ankner 等人,2024;Gandhi 等人,2024;Wang 等人,2024b;Xin 等人,2024;Zhang 等人,2024b)。
# 度量。
-
- 准确性。返回字符串的准确性由基准定义。对于构建加权集合的方法,我们报告从该集合中返回随机字符串的系统的预期准确性(权重成比例的概率)。 6 { }^{6} 6
-
- 运行时间。生成 M M M 个完整字符串所需的平均秒数。 7 { }^{7} 7
基准。
- 文本到SQL(Spider)。任务:从自然语言问题及其对应的数据库模式生成SQL查询。数据:Spider数据集(Yu等人,2018)的开发分割。度量:执行准确性(检查生成的SQL查询在测试数据库上执行时是否产生与真实查询相同的结果)。基础LM:Llama 3.1 8B-Instruct。约束函数:由Roy等人(2024)提供的SQL上下文无关语法的Python解析器,以强制语法正确的SQL。
-
- JSON。任务:生成符合特定JSON Schema的文档。数据:JSONSchemaBench数据集中Github-trivial、-easy和-medium任务的验证分割。度量:是否生成符合模式的有效JSON文档。基础LM:Llama 3.1 8B-Instruct。约束函数:检查输出是否可以解析为JSON,并使用Python jsonschema库进行验证。使用流式JSON解析器进行解析,这允许在生成完整文档之前增量检测某些模式违规。
-
- 目标推理(Planetarium)。任务:在PDDL规划语言的STRIPS子集中正式定义代理的目标,使用自然语言描述目标以及指定代理初始状态和计划的PDDL代码。数据:来自Planetarium基准测试的Blocksworld任务,最多包含10个对象(Zuo等人,2024)。度量:与真实PDDL描述的等价性。基础LM:Llama 3.1 8B。约束函数:检查目标的STRIPS语法,如Planetarium Blocksworld域中定义的 + 使用真实计划执行模拟以验证结果状态是否与预测(部分)目标匹配。
-
- 分子合成任务:使用SMILES符号生成类药物化合物(Weininger,1988)。数据:通过反复从GDB-17数据库(Ruddigkeit等人,2012)中选择20个随机样本创建的少量提示。度量:药物相似性估计(QED;Bickerton等人,2012),一种广泛使用的分子质量度量。基础LM:Llama 3.1 8B。约束函数:通过Python partialsmiles库实现的SMILES前缀验证器(O’Boyle,2024)。
-
- 模式匹配。任务:生成符合表达性模式匹配规范的字符串。与形式化的正则表达式相比,这些模式包含确定性有限状态自动机无法完全捕捉的显式特征,包括无限中心嵌套和条件。数据:通过附录I中的流水线生成的400多个模式匹配规范。基础LM:Llama 3.1 8B-Instruct。度量:遵守指定的模式。约束函数:增量模式验证器,检查给定前缀后是否仍然可能存在完整匹配(Barnett,2014)。
实验结果与讨论
AWRS优于最先进的受控生成方法。表1显示了每个领域中每种方法的准确性和运行时间。我们观察到以下结果:
-
受控生成优于不受控生成。在几乎没有运行时间开销的情况下,ARS-LCD在所有基准测试中提高了Base LM的准确性。
6 { }^{6} 6 理由是返回 x x x 的概率随着 M M M 的增长接近 P ( x ) P(\boldsymbol{x}) P(x),所以我们大约返回 x ∼ P \boldsymbol{x} \sim P x∼P,就像Base LM返回 x ∼ P 0 \boldsymbol{x} \sim P_{0} x∼P0 一样。请注意,我们可以通过从集合中选择最可能的字符串或更普遍地通过最小贝叶斯风险方法选择或构造一个“共识字符串”来进一步提高准确性,该字符串在加权集合下的预期任务损失较低。
7 { }^{7} 7 我们的运行时间随 M M M 呈次线性增长,因为我们使用了并行硬件(GPU)。具体来说,从LLM获取下一个令牌分布 p 0 p_{0} p0 的调用在 M M M 个字符串上进行了批处理。
| 方法 | 准确性 | 运行时间(秒/例) |
| :-- | :-- | :-- |
| Base LM | 0.530 ( 0.50 , 0.56 ) 0.530(0.50,0.56) 0.530(0.50,0.56) | 0.79 ( 0.76 , 0.82 ) 0.79(0.76,0.82) 0.79(0.76,0.82) |
| ARS-LCD | 0.569 ( 0.54 , 0.60 ) 0.569(0.54,0.60) 0.569(0.54,0.60) | 1.07 ( 1.01 , 1.12 ) 1.07(1.01,1.12) 1.07(1.01,1.12) |
| Sample-Verify | 0.600 ( 0.58 , 0.62 ) 0.600(0.58,0.62) 0.600(0.58,0.62) | 2.76 ( 2.62 , 2.91 ) 2.76(2.62,2.91) 2.76(2.62,2.91) |
| Twisted SMC | 0.596 ( 0.57 , 0.62 ) 0.596(0.57,0.62) 0.596(0.57,0.62) | 2.89 ( 2.73 , 3.06 ) 2.89(2.73,3.06) 2.89(2.73,3.06) |
| AWRS-SMC | 0.608 ( 0.58 , 0.63 ) 0.608(0.58,0.63) 0.608(0.58,0.63) | 5.33 ( 5.05 , 5.61 ) 5.33(5.05,5.61) 5.33(5.05,5.61) |
(a) 文本到SQL
| 方法 | 准确性 | 运行时间(秒/例) |
|---|---|---|
| Base LM | 0.032 ( 0.01 , 0.06 ) 0.032(0.01,0.06) 0.032(0.01,0.06) | 1.07 ( 0.97 , 1.17 ) 1.07(0.97,1.17) 1.07(0.97,1.17) |
| ARS-LCD | 0.18 ( 0.11 , 0.26 ) 0.18(0.11,0.26) 0.18(0.11,0.26) | 0.77 ( 0.68 , 0.86 ) 0.77(0.68,0.86) 0.77(0.68,0.86) |
| Sample-Verify | 0.205 ( 0.13 , 0.28 ) 0.205(0.13,0.28) 0.205(0.13,0.28) | 4.55 ( 4.25 , 4.84 ) 4.55(4.25,4.84) 4.55(4.25,4.84) |
| Twisted SMC | 0.479 ( 0.39 , 0.57 ) 0.479(0.39,0.57) 0.479(0.39,0.57) | 3.20 ( 2.93 , 3.47 ) 3.20(2.93,3.47) 3.20(2.93,3.47) |
| AWRS-SMC | 0.528 ( 0.44 , 0.62 ) 0.528(0.44,0.62) 0.528(0.44,0.62) | 2.62 ( 2.42 , 2.82 ) 2.62(2.42,2.82) 2.62(2.42,2.82) |
© 目标推理
| 方法 | 准确性 | 运行时间(秒/例) |
|---|---|---|
| Base LM | 0.570 ( 0.52 , 0.62 ) 0.570(0.52,0.62) 0.570(0.52,0.62) | 0.10 ( 0.09 , 0.11 ) 0.10(0.09,0.11) 0.10(0.09,0.11) |
| ARS-LCD | 0.993 ( 0.98 , 1.00 ) 0.993(0.98,1.00) 0.993(0.98,1.00) | 0.13 ( 0.11 , 0.14 ) 0.13(0.11,0.14) 0.13(0.11,0.14) |
| TM-LCD | 0.978 ( 0.96 , 0.99 ) 0.978(0.96,0.99) 0.978(0.96,0.99) | 6.91 ( 5.68 , 8.46 ) 6.91(5.68,8.46) 6.91(5.68,8.46) |
| 方法 | 准确性 | 运行时间(秒/例) |
|---|---|---|
| Base LM | 0.683 ( 0.64 , 0.72 ) 0.683(0.64,0.72) 0.683(0.64,0.72) | 2.37 ( 2.16 , 2.59 ) 2.37(2.16,2.59) 2.37(2.16,2.59) |
| ARS-LCD | 0.781 ( 0.74 , 0.82 ) 0.781(0.74,0.82) 0.781(0.74,0.82) | 3.78 ( 3.40 , 4.15 ) 3.78(3.40,4.15) 3.78(3.40,4.15) |
| Sample-Verify | 0.845 ( 0.81 , 0.88 ) 0.845(0.81,0.88) 0.845(0.81,0.88) | 6.24 ( 5.74 , 6.76 6.24(5.74,6.76 6.24(5.74,6.76 |
| Twisted SMC | 0.866 ( 0.84 , 0.90 ) 0.866(0.84,0.90) 0.866(0.84,0.90) | 6.31 ( 5.74 , 6.90 ) 6.31(5.74,6.90) 6.31(5.74,6.90) |
| AWRS-SMC | 0.903 ( 0.87 , 0.93 ) 0.903(0.87,0.93) 0.903(0.87,0.93) | 10.51 ( 9.61 , 11.44 ) 10.51(9.61,11.44) 10.51(9.61,11.44) |
(b) JSON
| 方法 | 准确性 | 运行时间(秒/例) |
|---|---|---|
| Base LM | 0.150 ( 0.10 , 0.20 ) 0.150(0.10,0.20) 0.150(0.10,0.20) | 0.52 ( 0.50 , 0.54 ) 0.52(0.50,0.54) 0.52(0.50,0.54) |
| ARS-LCD | 0.568 ( 0.53 , 0.60 ) 0.568(0.53,0.60) 0.568(0.53,0.60) | 0.58 ( 0.54 , 0.62 ) 0.58(0.54,0.62) 0.58(0.54,0.62) |
| Sample-Verify | 0.539 ( 0.50 , 0.57 ) 0.539(0.50,0.57) 0.539(0.50,0.57) | 1.96 ( 1.93 , 1.99 ) 1.96(1.93,1.99) 1.96(1.93,1.99) |
| Twisted SMC | 0.549 ( 0.52 , 0.57 ) 0.549(0.52,0.57) 0.549(0.52,0.57) | 2.04 ( 1.99 , 2.09 ) 2.04(1.99,2.09) 2.04(1.99,2.09) |
| AWRS-SMC | 0.568 ( 0.54 , 0.59 ) 0.568(0.54,0.59) 0.568(0.54,0.59) | 1.52 ( 1.47 , 1.57 ) 1.52(1.47,1.57) 1.52(1.47,1.57) |
(d) 分子合成
| 方法 | 准确性 | 运行时间(秒/例) |
|---|---|---|
| Base LM | 0.570 ( 0.52 , 0.62 ) 0.570(0.52,0.62) 0.570(0.52,0.62) | 0.10 ( 0.09 , 0.11 ) 0.10(0.09,0.11) 0.10(0.09,0.11) |
| ARS-LCD | 0.993 ( 0.98 , 1.00 ) 0.993(0.98,1.00) 0.993(0.98,1.00) | 0.13 ( 0.11 , 0.14 ) 0.13(0.11,0.14) 0.13(0.11,0.14) |
| TM-LCD | 0.978 ( 0.96 , 0.99 ) 0.978(0.96,0.99) 0.978(0.96,0.99) | 6.91 ( 5.68 , 8.46 ) 6.91(5.68,8.46) 6.91(5.68,8.46) |
| 方法 | 准确性 | 运行时间(秒/例) |
|---|---|---|
| Sample-Verify | 0.781 ( 0.74 , 0.82 ) 0.781(0.74,0.82) 0.781(0.74,0.82) | 0.28 ( 0.26 , 0.30 ) 0.28(0.26,0.30) 0.28(0.26,0.30) |
| Twisted SMC | 0.796 ( 0.76 , 0.84 ) 0.796(0.76,0.84) 0.796(0.76,0.84) | 0.20 ( 0.19 , 0.22 ) 0.20(0.19,0.22) 0.20(0.19,0.22) |
| AWRS-SMC | 0.990 ( 0.98 , 1.00 ) 0.990(0.98,1.00) 0.990(0.98,1.00) | 0.36 ( 0.33 , 0.40 ) 0.36(0.33,0.40) 0.36(0.33,0.40) |
(e) 模式匹配
表1:具有95%引导置信区间的不同领域中方法准确性和运行时间的比较。运行时间表示数据集中所有实例的平均执行时间(以秒为单位)。Sample-Verify和Twisted SMC使用了
M
=
10
M=10
M=10个粒子运行。AWRS-SMC使用了
M
=
5
M=5
M=5个粒子运行。
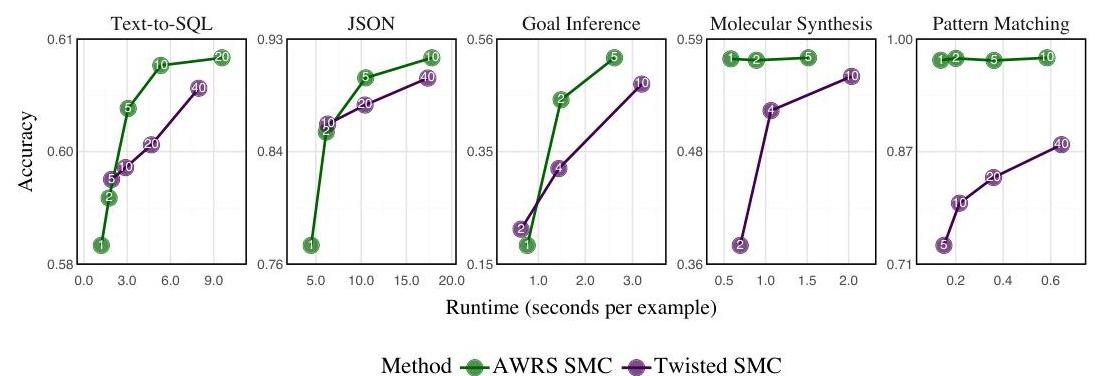
图2:AWRS-SMC和Twisted SMC在不同粒子数下的运行时间和准确性。
- 自适应采样比令牌屏蔽快得多,且没有损失准确性。在模式匹配领域——这是唯一一个在计算上可行运行TM-LCD的地方——ARS-LCD在保持相同准确性的同时速度快约50倍。 6 { }^{6} 6
-
- 校正贪婪性可以提高准确性。AWRS-SMC始终匹配或优于ARS-LCD,在三个领域(目标推理、JSON和文本到SQL)显著改善。其他两个领域(分子合成和模式匹配)在贪婪性方面受到的影响较小,因为它们的局部约束 1 C \mathbb{1}_{C} 1C是精确的,只允许有有效延续的前缀。
-
-
AWRS-SMC优于现有的校正贪婪性的方法。在所有基准测试中,使用一半粒子数的AWRS-SMC达到了与Sample-Verify和Twisted SMC相当或更高的准确性。
6 { }^{6} 6 这种50倍的速度提升是在完整的序列生成级别上,包括所有用于LM计算的时间。不考虑这个常数因子,速度提升更大。
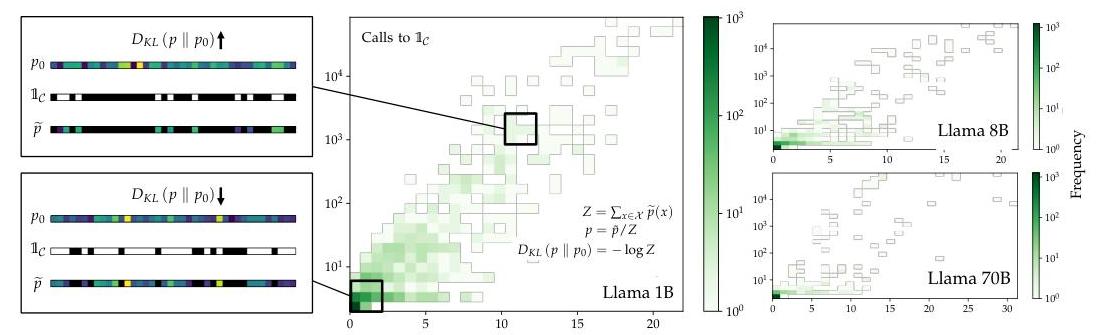
图3:AWRS调用 1 C \mathbb{1}_{\mathcal{C}} 1C的数量(y轴)随 D K L ( p ∥ p 0 ) D_{K L}\left(p \| p_{0}\right) DKL(p∥p0)(Nats;x轴)变化。
-
接下来,我们研究AWRS-SMC如何随着粒子数量(图2)和LM大小(图K.1)扩展,与现有从全局分布采样的方法进行比较。
- AWRS-SMC比现有的SMC方法更快。在所有领域中,AWRS-SMC在较低运行时间的情况下实现了比Twisted SMC更高的准确性。这种差异在局部约束 1 C \mathbb{1}_{\mathcal{C}} 1C是精确的领域最为显著(分子合成和模式匹配)。在这种情况下,1粒子的AWRS-SMC表现优于使用数十个粒子的Twisted SMC。这表明AWRS-SMC的改进来自于将约束纳入提议分布而不是必须猜测和检查。
-
- 使用较小LM的AWRS-SMC优于使用较大LM的现有SMC方法。图K.1显示了使用LLama 3.2 1B的AWRS-SMC在运行时间和准确性方面都优于使用LLama 3.1 8B和Llama 3.3 70B的Twisted SMC。这表明将信息丰富的约束纳入提议是一种使小模型超越其重量级的方法。
AWRS通过动态分配计算实现加速。正如我们在广泛的理论和实证运行时间分析(附录G.2和图G.1和F.2)中所示,AWRS随约束符合难度 D K L ( p ∥ p 0 ) D_{K L}\left(p \| p_{0}\right) DKL(p∥p0)扩展,在预期条件下采样一个标记所需的时间较少,而在非预期条件下所需的时间更多。我们分析了模式匹配基准中的TM-LCD结果,其中令牌屏蔽支持每个令牌采样步骤的地面真实值 D K L ( p ∥ p 0 ) D_{K L}\left(p \| p_{0}\right) DKL(p∥p0)的确切计算。然后我们对这些步骤运行AWRS,说明几个关键结果(图3)。
- 使用较小LM的AWRS-SMC优于使用较大LM的现有SMC方法。图K.1显示了使用LLama 3.2 1B的AWRS-SMC在运行时间和准确性方面都优于使用LLama 3.1 8B和Llama 3.3 70B的Twisted SMC。这表明将信息丰富的约束纳入提议是一种使小模型超越其重量级的方法。
- 在大多数采样步骤中, D K L ( p ∥ p 0 ) D_{K L}\left(p \| p_{0}\right) DKL(p∥p0)很小;AWRS通常只检查2或3个令牌。
-
- 对于最难的情况,当 D K L ( p ∥ p 0 ) D_{K L}\left(p \| p_{0}\right) DKL(p∥p0)增加时,AWRS的运行时间动态扩展。一个有趣的后果是AWRS对于更精确的基础模型采样更快。
-
- 随着 D K L ( p ∥ p 0 ) D_{K L}\left(p \| p_{0}\right) DKL(p∥p0)的增长,AWRS通常不会恶化。AWRS大致受制于那些个体概率接近或超过 Z Z Z的非符合令牌的数量。这一组通常是小的,并且经验上更精确的模型似乎减少了这一组的大小。即使模型的最佳选择是错误的,它通常仍然偏好符合约束的令牌而非任意不符合的令牌。
6 相关工作
一种加速受限解码的方法是预编译受限约束类以减少运行时开销。工程进展使得至少部分编译表达为正则(Deutsch et al., 2019; Willard & Louf, 2023; Kuchnik et al., 2023)或上下文无关(Koo et al., 2024; Ugare et al., 2024; Dong et al., 2024)语言以及受限布尔电路类成为可能(Ahmed et al., 2025)。相比之下,我们的方法支持任意可编程约束。
另一种方法探索了限制约束评估次数。Poesia等人(2022)和Ugare等人(2025)允许LM不受限制地继续并随后回溯错误。Scholak等人(2021)和Shin & Van Durme(2022)在束搜索中使用top-k截断。Loula等人(2025),类似于Morin & Bengio(2005)的精神,分层化词汇并递增约束检查器至字节序列。A
Outlines库的一个子集(v. 0.2.2; Willard & Louf, 2023)使用确定性概率排序搜索的变化形式,首先按logits对令牌进行排序,然后产生第一个符合要求的令牌。我们的工作在概率框架内构建这些方法,推导出等价于令牌屏蔽的精确采样器(ARS-LCD)以及支持在SMC中安全使用此类样本的重要性权重(AWRS-SMC)。
几篇近期论文使用SMC来纠正LCD的贪婪性(Lew等人,2023;Zhao等人,2024;Loula等人,2025)。这些方法存在显著限制:Zhao等人(2024)需要昂贵的微调过程来学习扭曲,而Loula等人(2025)要求约束能够分解为慢速和快速组件,后者仍需在大量令牌上进行评估。相比之下,我们的方法无需任何调整即可适用于任何约束,并且评估更加节省资源,通常在固定时间内比扭曲SMC更精确。
7 结论
局部约束解码既慢又贪婪。在本文中,我们分别通过引入(i)自适应拒绝采样器,该采样器所需的约束评估量级少得多,以及(ii)一种计算权重的算法,将此局部采样器转换为全局采样器,解决了这些弱点。在许多具有挑战性的受控生成领域中,我们发现即使使用较少的粒子和较小的语言模型,我们的方法也比现有方法更快且更准确。最后,我们通过理论和实证分析表明,我们的方法所做的约束评估数量随无约束和受约束LM分布之间的KL散度扩展——因此,我们的方法对于更强大的LM更快。
可重复性
所有代码和数据将在论文被接受后发布。
作者贡献
第一作者
- Benjamin Lipkin (lipkinb@mit.edu): 研究构思、正式分析(算法、适当加权)、软件开发(采样器)、实验开发(模拟、模式匹配)、可视化、写作
-
- Benjamin LeBrun (benjamin.lebrun@mail.mcgill.ca): 主要软件工程师(基础设施、接口、SMC)、实验开发(文本到SQL、JSON、模式匹配)、可视化、写作
贡献者
- Jacob Hoover Vigly (jahoo@mit.edu): 正式分析(运行时间复杂度、参数估计器)、技术建议(采样算法)、可视化、写作
-
- João Loula (jloula@mit.edu): 软件开发(算法优化)、实验开发(目标推理、分子合成)、可视化、写作
-
- David MacIver (david@chi-fro.org): 实验开发(JSON)
-
- Li Du (leodu@cs.jhu.edu): 软件开发(语法解析原型)
-
- Jason Eisner (jason@cs.jhu.edu): 技术建议(顺序推断)、写作
-
- Ryan Cotterell (ryan.cotterell@inf.ethz.ch): 组织管理
-
- Vikash Mansinghka (vkm@mit.edu): 组织管理
高级作者
- Timothy J. O’Donnell (timothy.odonnell@mcgill.ca): 组织管理、高级项目领导、项目叙事发展、写作
-
- Alexander K. Lew (alexander.lew@yale.edu): 高级项目领导、研究构思、正式分析(适当加权)、项目叙事发展、项目指导和导师、写作
-
- Tim Vieira (tim.f.vieira@gmail.com): 高级项目领导、研究构思、正式分析(算法、顺序推断)、软件开发(语法解析)、项目叙事发展、项目指导和导师、写作
致谢
BLi由国家科学基金会研究生研究奖学金资助,资助编号为2141064。JHV由国家科学基金会SBE博士后研究奖学金资助,资助编号为SMA-2404644。这项研究部分得到了Mila(mila.quebec)提供的计算资源的支持。
参考文献
Kareem Ahmed, Kai-Wei Chang, 和 Guy Van den Broeck. 受控生成通过局部约束重采样. 在第十三届国际学习表示会议上,2025年。URL https://openreview.net/pdf?id=8g4XgC8HPF.
Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan Fu, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Daniel Ho, Jasmine Hsu, Julian Ibarz, Brian Ichter, Alex Irpan, Eric Jang, Rosario Jauregui Ruano, Kyle Jeffrey, Sally Jesmonth, Nikhil J Joshi, Ryan Julian, Dmitry Kalashnikov, Yuheng Kuang, Kuang-Huei Lee, Sergey Levine, Yao Lu, Linda Luu, Carolina Parada, Peter Pastor, Jornell Quiambao, Kanishka Rao, Jarek Rettinghouse, Diego Reyes, Pierre Sermanet, Nicolas Sievers, Clayton Tan, Alexander Toshev, Vincent Vanhoucke, Fei Xia, Ted Xiao, Peng Xu, Sichun Xu, Mengyuan Yan, 和 Andy Zeng. 做我能做的,而不是我说的:将语言接地为机器人能力. arXiv预印本arXiv:2204.01691, 2022年。URL https://arxiv.org/abs/2204.01691.
Zachary Ankner, Mansheej Paul, Brandon Cui, Jonathan Daniel Chang, 和 Prithviraj Ammanabrolu. 大声批评奖励模型. 在NeurIPS 2024多元对齐研讨会中,2024年。URL https://arxiv.org/pdf/2408.11791.
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, Carol Chen, Catherine Olsson, Christopher Olah, Danny Hernandez, Dawn Drain, Deep Ganguli, Dustin Li, Eli Tran-Johnson, Ethan Perez, Jamie Kerr, Jared Mueller, Jeffrey Ladish, Joshua Landau, Kamal Ndousse, Kamile Lukosuite, Liane Lovitt, Michael Sellitto, Nelson Elhage, Nicholas Schiefer, Noemi Mercado, Nova DasSarma, Robert Lasenby, Robin Larson, Sam Ringer, Scott Johnston, Shauna Kravec, Sheer El Showk, Stanislav Fort, Tamera Lanham, Timothy Telleen-Lawton, Tom Conerly, Tom Henighan, Tristan Hume, Samuel R. Bowman, Zac Hatfield-Dodds, Ben Mann, Dario Amodei, Nicholas Joseph, Sam McCandlish, Tom Brown, 和 Jared Kaplan. 宪法AI:来自AI反馈的安全性. arXiv预印本arXiv:2212.08073, 2022年。URL https://arxiv.org/abs/2212.08073.
Debangshu Banerjee, Tarun Suresh, Shubham Ugare, Sasa Misailovic, 和 Gagandeep Singh. CRANE:使用受限LLM生成的推理. arXiv预印本arXiv:2502.09061, 2025年。URL https://arxiv.org/pdf/2502.09061.
Matthew Barnett. regex, 2014. URL https://github.com/mrabarnett/mrab-regex.
Luca Beurer-Kellner, Marc Fischer, 和 Martin Vechev. 引导LLM正确方向:快速、非侵入式的受控生成. 在机器学习国际会议上,pp. 3658-3673。PMLR, 2024年。URL https://proceedings.mlr.press/v235/beurer-kellner24a.html.
G Richard Bickerton, Gaia V Paolini, Jérémy Besnard, Sorel Muresan, 和 Andrew L Hopkins. 量化药物的化学美. 自然化学, 4(2):90-98, 2012年。URL https://www.nature.com/articles/nchem.1243.
Benjamin Börschinger 和 Mark Johnson. 贝叶斯词分割的粒子滤波算法. 在澳大利亚语言技术协会研讨会的会议记录中,2011年12月。URL https://aclanthology.org/U11-1004/.
Jan Buys 和 Phil Blunsom. 用于生成性转换依赖句法分析的贝叶斯模型. 在国际依存句法会议记录中,2015年。URL https://aclanthology.org/#15-2108/.
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, 和 John Schulman. 训练验证器解决数学文字问题. arXiv预印本arXiv:2110.14168, 2021年。URL https://arxiv.org/pdf/2110.14168.
Eldan Cohen 和 Christopher Beck. 关于神经序列模型中束搜索性能退化的实证分析. 在机器学习国际会议上,pp. 12901299。PMLR, 2019年。URL https://proceedings.mlr.press/v97/cohen19a/cohen19a.pdf.
Daniel Deutsch, Shyam Upadhyay, 和 Dan Roth. 用于受约束序列推理的一般目的算法. 在计算自然语言学习会议记录中,2019年。URL https://aclanthology.org/K19-1045/.
Yixin Dong, Charlie F Ruan, Yaxing Cai, Ruihang Lai, Ziyi Xu, Yilong Zhao, 和 Tianqi Chen. XGrammar: 大型语言模型灵活高效的结构化生成引擎. arXiv预印本arXiv:2411.15100, 2024年。URL https://arxiv.org/pdf/2411.15100.
Gregory Dubbin 和 Phil Blunsom. 使用粒子滤波器进行无监督的部分词性推断. 在NAACL HLT工作坊关于语言结构归纳的会议记录中,蒙特利尔,QC,2012年。URL https://aclanthology.org/W12-1907.pdf.
Catherine Forbes, Merran Evans, Nicholas Hastings, 和 Brian Peacock. 统计分布. Wiley & Sons, 2011年.
Cameron E Freer, Vikash K Mansinghka, 和 Daniel M Roy. 何时概率程序可能计算上可处理?在现代应用的蒙特卡罗方法NIPS研讨会上,pp. 41, 2010年。URL https://web.mit.edu/vkm/www/FreerManRoy-NIPSMC-2010.pdf.
Kanishk Gandhi, Denise HJ Lee, Gabriel Grand, Muxin Liu, Winson Cheng, Archit Sharma, 和 Noah Goodman. 搜索流(SoS):学习在语言中搜索. 在第一次语言建模会议上,2024年。URL https://openreview.net/pdf?id=2cop2jmQVL.
Saibo Geng, Martin Josifoski, Maxime Peyrard, 和 Robert West. 不进行微调的语法约束解码用于结构化NLP任务. 在经验方法在自然语言处理会议记录中,2023年。URL https://aclanthology.org/2023.emnlp-main.674.pdf.
Saibo Geng, Hudson Cooper, Michał Moskal, Samuel Jenkins, Julian Berman, Nathan Ranchin, Robert West, Eric Horvitz, 和 Harsha Nori. 从语言模型生成结构化输出:基准和研究,2025年。URL https://arxiv.org/abs/2501.10868.
Walter R Gilks 和 Pascal Wild. Gibbs抽样中的自适应拒绝抽样. 皇家统计学会杂志:C系列(应用统计学),41(2):337-348, 1992年.
Dan Hendrycks, Steven Basart, Saurav Kadavath, Mantas Mazeika, Akul Arora, Ethan Guo, Collin Burns, Samir Puranik, Horace He, Dawn Song, 和 Jacob Steinhardt. 使用APPS测量编码挑战能力. arXiv预印本arXiv:2105.09938, 2021年。URL https://arxiv.org/pdf/2105.09938.
Edward J Hu, Moksh Jain, Eric Elmoznino, Younesse Kaddar, Guillaume Lajoie, Yoshua Bengio, 和 Nikolay Malkin. 大型语言模型中难以处理的推断摊销. 在第十二届国际学习表示会议上,2024年。URL https://openreview.net/pdf?id=0uj6p4ca60.
Wenlong Huang, Fei Xia, Dhruv Shah, Danny Driess, Andy Zeng, Yao Lu, Pete Florence, Igor Mordatch, Sergey Levine, Karol Hausman, 和 Brian Ichter. 基于模型的解码:使用基于模型的指南进行文本生成. 在神经信息处理系统进展会议记录中,卷36,2024年。URL https://proceedings.neurips.cc/paper_files/paper/2023/file/bb3cfcb0284642a973dd631ec9184f2f-Paper-Conference.pdf.
Philipp Koehn 和 Rebecca Knowles. 神经机器翻译的六个挑战. 在第一届神经机器翻译研讨会记录中,pp. 28-39, 2017年。URL https://aclanthology.org/W17-3204.pdf.
Terry Koo, Frederick Liu, 和 Luheng He. 基于自动机的语言模型解码约束. 在语言建模会议上,2024年。URL https://openreview.net/forum?id=BDBdblmyzY.
Ben Krause, Akhilesh Deepak Gotmare, Bryan McCann, Nitish Shirish Keskar, Shafiq Joty, Richard Socher, 和 Nazneen Fatema Rajani. GeDi: 生成性判别器引导的序列生成. 在Findings of the Association for Computational Linguistics: EMNLP 2021, pp. 4929-4952, 2021年。URL https://aclanthology.org/2021.findings-emnlp.424.pdf.
Michael Kuchnik, Virginia Smith, 和 George Amvrosiadis. 使用RELM验证大型语言模型. 机器学习和系统会议记录,5, 2023年。URL https://proceedings.mlsys.org/paper_files/paper/2023/file/93c7d9da61ccb2a60ac047e92787c3ef-Paper-mlsys2023.pdf.
Dieterich Lawson, Allan Raventós, Andrew Warrington, 和 Scott Linderman. SIA’O: 使用扭曲目标的平滑推断. 神经信息处理系统进展,2022年。URL https://proceedings.neurips.cc/paper_files/paper/2022/file/fddc79681b2df2734c01444f9bc2a17e-Paper-Conference.pdf.
Roger Levy. 基于期望的句法理解. 认知,106(3):1126-1177, 2008年。URL https://doi.org/10.1016/j.cognition.2007.05.006.
Alexander K Lew, Marco Cusumano-Towner, 和 Vikash K Mansinghka. 辅助变量的递归蒙特卡罗和变分推断. 在不确定性人工智能。机器学习研究会议记录中,2022年。URL https://proceedings.mlr.press/v180/lew22a/lew22a.pdf.
Alexander K Lew, Tan Zhi-Xuan, Gabriel Grand, 和 Vikash Mansinghka. 使用概率程序的大型语言模型序贯蒙特卡罗引导. 在ICML 2023研讨会:离散空间中的采样和优化,2023年。URL https://openreview.net/pdf?id=Ul2K0qXxXy.
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, 和 Karl Cobbe. 让我们逐步验证. 在Tawlffh国际学习表示会议上,2023年。URL https://openreview.net/pdf?id=v8L0pN6EOi.
Chu-Cheng Lin 和 Jason Eisner. 条件序列模型的神经粒子平滑用于采样. 在北美计算语言学协会人类语言技术分会会议记录中,2018年。URL https://aclanthology.org/N18-1005/.
João Loula, Benjamin LeBrun, Li Du, Ben Lipkin, Clemente Pasti, Gabriel Grand, Tianyu Liu, Yahya Emara, Marjorie Freedman, Jason Eisner, Ryan Cotterell, Vikash Mansinghka, Alex Lew, Tim Vieira, 和 Tim O’Donnell. 通过序贯蒙特卡罗控制大型语言模型的句法和语义. 在第十三届国际学习表示会议上,2025年。URL https://openreview.net/pdf?id=xoXn62FzD0.
Ximing Lu, Peter West, Rowan Zellers, Ronan Le Bras, Chandra Bhagavatula, 和 Yejin Choi. NeuroLogic 解码:(未)监督神经文本生成与谓词逻辑约束. 在2021年北美计算语言学协会会议记录中,pp. 4288-4299, 2021年。URL https://aclanthology.org/2021.naacl-main.339.pdf.
Ximing Lu, Sean Welleck, Peter West, Liwei Jiang, Jungo Kasai, Daniel Khashabi, Ronan Le Bras, Lianhui Qin, Youngjae Yu, Rowan Zellers, Noah Smith, 和 Yejin Choi. NeuroLogic A*esque 解码:带前瞻启发式的受约束文本生成. 在2022年北美计算语言学协会会议记录中,pp. 780-799, 2022年。URL https://aclanthology.org/2022.naacl-main.57.pdf.
Vikash Mansinghka, Daniel Roy, Eric Jonas, 和 Joshua Tenenbaum. 系统随机搜索的精确和近似采样. 在人工智能和统计会议上,pp. 400-407. PMLR, 2009年。URL https://proceedings.mlr.press/v5/mansinghka09a.html.
MegaIng. interegular, 2019年。URL https://github.com/MegaIng/interegular.
Tao Meng, Sidi Lu, Nanyun Peng, 和 Kai-Wei Chang. 具有神经分解预言的可控文本生成. 神经信息处理系统进展,35:28125-28139, 2022年。URL https://proceedings.neurips.cc/paper_files/paper/2022/file/b40d5797756800c97f3d525c2e4c8357-Paper-Conference.pdf.
Ning Miao, Yuxuan Song, Hao Zhou, 和 Lei Li. 你有合适的剪刀吗?通过蒙特卡洛方法裁剪预训练语言模型. 在计算语言学协会年会记录中,2020年。URL https://aclanthology.org/2020.acl-main.314/.
Frederic Morin 和 Yoshua Bengio. 层次概率神经网络语言模型. 在国际人工智与统计研讨会记录中,pp. 246-252. PMLR, 2005年。URL https://proceedings.mlr.press/r5/morin05a/morin05a.pdf.
Michal Moskal, Madan Musuvathi, 和 Emre Kıcıman. AI 控制器接口. https://github.com/microsoft/aici/, 2024年.
Kenton Murray 和 David Chiang. 纠正神经机器翻译中的长度偏差. 在第三届机器翻译会议记录:研究论文中,pp. 212-223, 2018年。URL https://aclanthology.org/#18-6322.pdf.
Christian Naesseth, Fredrik Lindsten, 和 Thomas Schon. 嵌套序贯蒙特卡罗方法. 在Francis Bach和David Blei(eds.)编辑的第32届国际机器学习会议记录中,volume 37 of Proceedings of Machine Learning Research, pp. 1292-1301, Lille, France, 07-09 Jul 2015. PMLR. URL https://proceedings.mlr.press/v37/naesseth15.html.
Christian A. Naesseth, Fredrik Lindsten, 和 Thomas B. Schön. 序贯蒙特卡罗元素. Found. Trends Mach. Learn., 12(3), 2019年。doi: 10.1561/2200000074. URL https://doi.org/10.1561/2200000074.
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, Xu Jiang, Karl Cobbe, Tyna Eloundou, Gretchen Krueger, Kevin Button, Matthew Knight, Benjamin Chess, 和 John Schulman. WebGPT:带有浏览器辅助问答的人类反馈. arXiv预印本arXiv:2112.09332, 2021年。URL https://arxiv.org/pdf/2112.09332.
Noel O’Boyle. partialsmiles: 支持不完整SMILES的验证SMILES解析器, 2024年。URL https://github.com/baoilleach/partialsmiles.
Theo Olausson, Alex Gu, Ben Lipkin, Cedegao Zhang, Armando Solar-Lezama, Joshua Tenenbaum, 和 Roger Levy. LINC: 结合语言模型和一阶逻辑证明器的神经符号推理方法. 在经验方法在自然语言处理会议记录中,2023年。URL https://aclanthology.org/2023.emnlp-main.313/.
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, 和 Ryan Lowe. 训练语言模型跟随指令并使用人类反馈. 在神经信息处理系统进展会议记录中,2022年。URL https://proceedings.neurips.cc/paper_files/paper/2022/file/b1efde53be364a73914f58805a001731-Paper-Conference.pdf.
Kanghee Park, Jiayu Wang, Taylor Berg-Kirkpatrick, Nadia Polikarpova, 和 Loris D’Antoni. 语法对齐解码. 神经信息处理系统进展,37: 24547-24568, 2024年。URL https://proceedings.neurips.cc/paper_files/paper/2024/file/2bdc2267c3d7d01523e2e17ac0a754f3-Paper-Conference.pdf.
Gabriel Poesia, Alex Polozov, Vu Le, Ashish Tiwari, Gustavo Soares, Christopher Meek, 和 Sumit Gulwani. Synchromesh: 可靠的代码生成从预训练语言模型. 在国际学习表示会议中,2022年。URL https://openreview.net/forum?id=KmtVD97J43e.
Isha Puri, Shivchander Sudalairaj, Guangxuan Xu, Kai Xu, 和 Akash Srivastava. 概率推断方法用于使用粒子基蒙特卡罗方法的LLMs推理时扩展. arXiv预印本arXiv:2502.01618, 2025年。URL https://arxiv.org/pdf/2502.01618.
Lianhui Qin, Sean Welleck, Daniel Khashabi, 和 Yejin Choi. COLD解码:基于能量的受限文本生成与朗之万动力学. 神经信息处理系统进展,35:9538-9551, 2022年。URL https://proceedings.neurips.cc/paper_files/paper/2022/file/3e25d1aff47964c8409fd5c8dc0438d7-Paper-Conference.pdf.
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, 和 Chelsea Finn. 直接偏好优化:你的语言模型实际上是一个奖励模型. 神经信息处理系统进展,36:53728-53741, 2023年。URL https://proceedings.neurips.cc/paper_files/paper/2023/file/a85b405ed65c6477a4fe8302b5e06ce7-Paper-Conference.pdf.
Ronald Rosenfeld, Stanley Chen, 和 Xiaojin Zhu. 整句指数语言模型:语言统计集成的载体. 计算语音与语言,15, 012001. URL https://www.sciencedirect.com/science/article/abs/pii/S0885230800901591.
Subhro Roy, Samuel Thomson, Tongfei Chen, Richard Shin, Adam Pauls, Jason Eisner, 和 Benjamin Van Durme. BenchCLAMP: 评估语言模型在句法和语义解析上的基准. 在神经信息处理系统进展会议上,卷36, 2024年。URL https://proceedings.neurips.cc/paper_files/paper/2023/file/9c1535a02f0ce079433344e14d910597-Paper-Datasets_and_Benchmarks.pdf.
Lars Ruddigkeit, Ruud Van Deursen, Lorenz C Blum, 和 Jean-Louis Reymond. 化学宇宙数据库GDB-17中列举1660亿有机小分子. 化学信息与建模期刊,52(11):2864-2875, 2012年。URL https://pubs.acs.org/doi/pdf/10.1021/ci300415d.
Torsten Scholak, Nathan Schucher, 和 Dzmitry Bahdanau. PICARD: 从语言模型中增量解析以实现受约束的自动回归解码. 在经验方法在自然语言处理会议记录中,2021年。
URL https://aclanthology.org/2022.emnlp-main.39/.
Freda Shi, Daniel Fried, Marjan Ghazvininejad, Luke Zettlemoyer, 和 Sida I Wang. 自然语言到代码翻译与执行. 在经验方法在自然语言处理会议记录中,2022年。URL https://aclanthology.org/2022.emnlp-main.231/.
Andy Shih, Dorsa Sadigh, 和 Stefano Ermon. 长时间温度缩放. 在机器学习国际会议上,pp. 31422-31434。PMLR, 2023年。URL https://proceedings.mlr.press/v202/shih23a/shih23a.pdf.
Richard Shin 和 Benjamin Van Durme. 使用代码训练的语言模型进行少量样本语义解析. 在北美计算语言学协会人类语言技术分会会议记录中,2022年。URL https://aclanthology.org/2022.naacl-main.396/.
Richard Shin, Christopher Lin, Sam Thomson, Charles Chen Jr, Subhro Roy, Emmanouil Antonios Platanios, Adam Pauls, Dan Klein, Jason Eisner, 和 Benjamin Van Durme. 受约束的语言模型生成少量样本语义解析器. 在经验方法在自然语言处理会议记录中,2021年。URL https://aclanthology.org/2021.emnlp-main.608/.
Felix Stahlberg 和 Bill Byrne. 关于NMT搜索错误和模型错误:猫把你的舌头叼走了吗?在2019年经验方法在自然语言处理和第九届国际自然语言处理联合会议(EMNLP-IJCNLP)的会议记录中,pp. 3356-3362, 2019年。URL https://aclanthology.org/D19-1331.pdf.
Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, 和 Paul F Christiano. 学习总结使用人类反馈. 在神经信息处理系统进展会议记录中,卷33, 2020年。URL https://proceedings.neurips.cc/paper_files/paper/2020/file/1f89885d556929e98d3ef9b86448f951-Paper.pdf.
Jonathan Uesato, Nate Kushman, Ramana Kumar, Francis Song, Noah Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, 和 Irina Higgins. 使用过程和结果反馈解决数学文字问题. arXiv预印本arXiv:2211.14275, 2022年。URL https://arxiv.org/pdf/2211.14275.
Shubham Ugare, Tarun Suresh, Hangoo Kang, Sasa Misailovic, 和 Gagandeep Singh. SynCode: 使用语法增强改进LLM代码生成. arXiv预印本arXiv:2403.01632, 2024年。URL https://arxiv.org/pdf/2403.01632.
Shubham Ugare, Rohan Gumaste, Tarun Suresh, Gagandeep Singh, 和 Sasa Misailovic. IterGen: 迭代结构化LLM生成. 在第十三届国际学习表示会议上,2025年。URL https://openreview.net/pdf?id=ac93gRzxxV.
Tim Vieira. Gumbel-max 技巧和加权水库采样,2014年。URL http://timvieira.github.io/blog/post/2014/08/01/gumbel-max-trick-and-weighted-reservoir-sampling/.
Bailin Wang, Zi Wang, Xuezhi Wang, Yuan Cao, Rif A Saurous, 和 Yoon Kim. 语法提示用于特定领域的语言生成与大型语言模型. 在神经信息处理系统进展会议记录中,2024a年。URL https://openreview.net/forum?id=B4tkwuzeiY¬eId=BaPOkL142Y.
Peiyi Wang, Lei Li, Zhihong Shao, Runxin Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, 和 Zhifang Sui. Math-Shepherd: 不需要人工注释验证和强化LLMs逐步推理. 在第62届计算语言学年度会议记录(第一卷:长论文)中,pp. 9426-9439, 2024b年。URL https://aclanthology.org/2024.acl-long.510.pdf.
David Weininger. SMILES, 化学语言和信息系统。1. 方法论和编码规则介绍。化学信息与计算机科学期刊,28(1):31-36, 1988.
Brandon T Willard 和 Rémi Louf. 高效引导的大规模语言模型生成。arXiv预印本arXiv:2307.09702, 2023年。URL https://arxiv.org/pdf/2307.09702.
Huajian Xin, Daya Guo, Zhihong Shao, Zhizhou Ren, Qihao Zhu, Bo Liu, Chong Ruan, Wenda Li, 和 Xiaodan Liang. Deepseek-prover: 通过大规模合成数据推进LLMs中的定理证明。arXiv预印本arXiv:2405.14333, 2024年。URL https://arxiv.org/pdf/2405.14333.
Kevin Yang 和 Dan Klein. FUDGE: 使用未来判别器的受控文本生成。在北美计算语言学协会人类语言技术分会会议记录中,2021年。URL https://aclanthology.org/2021.naacl-main.276/.
Yi Yang 和 Jacob Eisenstein. 无监督文本规范化的一个对数线性模型。在经验方法在自然语言处理会议记录中,2013年。URL https://aclanthology.org/D13-1007/.
Tao Yu, Rui Zhang, Kai Yang, Michihiro Yasunaga, Dongxu Wang, Zifan Li, James Ma, Irene Li, Qingning Yao, Shanelle Roman, Zilin Zhang, 和 Dragomir Radev. Spider: 大规模人工标注数据集用于复杂和跨域语义解析和文本到SQL任务。在经验方法在自然语言处理会议记录中,2018年。URL https://aclanthology.org/D18-1425.
Honghua Zhang, Meihua Dang, Nanyun Peng, 和 Guy Van den Broeck. 自回归语言生成的可处理控制。在机器学习国际会议记录中。机器学习研究会议记录,2023年。URL https://proceedings.mlr.press/v202/zhang23g/zhang23g.pdf.
Honghua Zhang, Po-Nien Kung, Masahiro Yoshida, Guy Van den Broeck, 和 Nanyun Peng. 大型语言模型的适应性逻辑控制。神经信息处理系统进展,37:115563-115587, 2024a年。URL https://proceedings.neurips.cc/paper_files/paper/2024/file/d15c16cf5619a2b1606da5fc88e3f1a9-Paper-Conference.pdf.
Lunjun Zhang, Arian Hosseini, Hritik Bansal, Mehran Kazemi, Aviral Kumar, 和 Rishabh Agarwal. 生成验证器:作为下一个令牌预测的奖励建模。在NeurIPS’24数学推理与AI研讨会第四次会议记录中,2024b年。URL https://openreview.net/pdf?id=CxHRoTLmPX.
Stephen Zhao, Rob Brekelmans, Alireza Makhzani, 和 Roger Baker Grosse. 语言模型中的概率推断通过扭曲序贯蒙特卡罗。在机器学习国际会议记录中,pp. 60704-60748。PMLR, 2024年。URL https://proceedings.mlr.press/v235/zhao24c.html.
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Barrett, 和 Ying Sheng. SGLang: 结构化语言模型程序的有效执行。在神经信息处理系统进展会议记录中,2024年。URL https://openreview.net/forum?id=VqkAKQibpq.
Daniel M Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B Brown, Alec Radford, Dario Amodei, Paul Christiano, 和 Geoffrey Irving. 从人类偏好微调语言模型。arXiv预印本arXiv:1909.08593, 2019年。URL https://arxiv.org/pdf/1909.08593.
Max Zuo, Francisco Piedrahita Velez, Xiaochen Li, Michael L Littman, 和 Stephen H Bach. Planetarium: 将文本翻译为结构化规划语言的严格基准。arXiv预印本arXiv:2407.03321, 2024年。URL https://arxiv.org/pdf/2407.03321.
A 条件语言建模
字符串。字母表 X \mathcal{X} X 是一个有限符号集合。令 X ∗ \mathcal{X}^{*} X∗ 表示由 X \mathcal{X} X 中的符号组成的字符串集合。令 ε \varepsilon ε 表示空字符串。令 ∣ x ∣ |x| ∣x∣ 表示 x ∈ X ∗ x \in \mathcal{X}^{*} x∈X∗ 的长度。我们还定义了 □ ∉ X \square \notin \mathcal{X} □∈/X 作为一个特殊的字符串结束标记。
约束条件。设 1 L : X ∗ → { 0 , 1 } \mathbb{1}_{\mathcal{L}}: \mathcal{X}^{*} \rightarrow\{0,1\} 1L:X∗→{0,1} 是一个约束函数,编码一组有效字符串 L ⊆ X ∗ \mathcal{L} \subseteq \mathcal{X}^{*} L⊆X∗。设 L → = def { x ∣ x x ′ ∈ L } \overrightarrow{\mathcal{L}} \stackrel{\text { def }}{=}\left\{\boldsymbol{x} \mid \boldsymbol{x} \boldsymbol{x}^{\prime} \in \mathcal{L}\right\} L= def {x∣xx′∈L},即, L \mathcal{L} L 中字符串的所有有效前缀集合。我们定义增量约束函数:
1 L ∗ ( x ′ ∣ x ) { 1 x ∈ L if x ′ = □ 1 x x ′ ∈ L otherwise \mathbb{1}_{\mathcal{L}}^{*}\left(x^{\prime} \mid \boldsymbol{x}\right) \begin{cases}\mathbb{1}_{\boldsymbol{x} \in \mathcal{L}} & \text { if } x^{\prime}=\square \\ \mathbb{1}_{\boldsymbol{x} x^{\prime} \in \mathcal{L}} & \text { otherwise }\end{cases} 1L∗(x′∣x){1x∈L1xx′∈L if x′=□ otherwise
语言模型。一个语言模型 P 0 P_{0} P0 是 X ∗ \mathcal{X}^{*} X∗ 上的概率分布。前缀概率 P ⃗ 0 ( x ) \vec{P}_{0}(\boldsymbol{x}) P0(x) 是从 P 0 P_{0} P0 中抽取的字符串以 x \boldsymbol{x} x 为前缀的概率:
P ⃗ 0 ( x ) = def ∑ x ′ ∈ X ∗ P 0 ( x x ′ ) \vec{P}_{0}(\boldsymbol{x}) \stackrel{\text { def }}{=} \sum_{\boldsymbol{x}^{\prime} \in \mathcal{X}^{*}} P_{0}\left(\boldsymbol{x} \boldsymbol{x}^{\prime}\right) P0(x)= def x′∈X∗∑P0(xx′)
条件前缀概率是从 P 0 P_{0} P0 中抽取的字符串以 x x ′ x x^{\prime} xx′ 为前缀给定它已经有前缀 x x x 的概率对于任何字符串 x , x ′ ∈ X ∗ x, x^{\prime} \in \mathcal{X}^{*} x,x′∈X∗ :
P ⃗ 0 ( x ′ ∣ x ) = def P ⃗ 0 ( x x ′ ) P ⃗ 0 ( x ) and P ⃗ 0 ( □ ∣ x ) = def P 0 ( x ) / P ⃗ 0 ( x ) \vec{P}_{0}\left(\boldsymbol{x}^{\prime} \mid \boldsymbol{x}\right) \stackrel{\text { def }}{=} \frac{\vec{P}_{0}\left(\boldsymbol{x} \boldsymbol{x}^{\prime}\right)}{\vec{P}_{0}(\boldsymbol{x})} \quad \text { and } \quad \vec{P}_{0}(\square \mid \boldsymbol{x}) \stackrel{\text { def }}{=} P_{0}(\boldsymbol{x}) / \vec{P}_{0}(\boldsymbol{x}) P0(x′∣x)= def P0(x)P0(xx′) and P0(□∣x)= def P0(x)/P0(x)
然后, x x x 的概率可以分解为
P 0 ( x ) = P ⃗ 0 ( □ ∣ x ) ∏ t = 1 ∣ x ∣ P ⃗ 0 ( x t ∣ x < t ) P_{0}(\boldsymbol{x})=\vec{P}_{0}(\square \mid \boldsymbol{x}) \prod_{t=1}^{|\boldsymbol{x}|} \vec{P}_{0}\left(x_{t} \mid \boldsymbol{x}_{<t}\right) P0(x)=P0(□∣x)t=1∏∣x∣P0(xt∣x<t)
全局调节。我们在最近定义受限生成为概率调节的工作基础上展开讨论(例如,Börschinger & Johnson, 2011; Dubbin & Blunsom, 2012; Yang & Eisenstein, 2013; Buys & Blunsom, 2015; Lin & Eisner, 2018; Miao 等人, 2020; Krause 等人, 2021; Yang & Klein, 2021; Meng 等人, 2022; Qin 等人, 2022; Zhang 等人, 2023; Hu 等人, 2024; Lew 等人, 2023; Zhao 等人, 2024; Park 等人, 2024; Ahmed 等人, 2025; Loula 等人, 2025)。特别是,我们将语言模型先验 x ∼ P 0 \boldsymbol{x} \sim P_{0} x∼P0 在条件 1 L ( x ) \mathbb{1}_{\mathcal{L}}(\boldsymbol{x}) 1L(x) 下的后验分布 P ( x ) P(\boldsymbol{x}) P(x) 定义为
P ( x ) = def 1 G P ⃗ ( x ) P ⃗ ( x ) = def P 0 ( x ) 1 L ( x ) G = def ∑ x ∈ X ∗ P ⃗ ( x ) P(\boldsymbol{x}) \stackrel{\text { def }}{=} \frac{1}{G} \vec{P}(\boldsymbol{x}) \quad \vec{P}(\boldsymbol{x}) \stackrel{\text { def }}{=} P_{0}(\boldsymbol{x}) \mathbb{1}_{\mathcal{L}}(\boldsymbol{x}) \quad G \stackrel{\text { def }}{=} \sum_{\boldsymbol{x} \in \mathcal{X}^{*}} \vec{P}(\boldsymbol{x}) P(x)= def G1P(x)P(x)= def P0(x)1L(x)G= def x∈X∗∑P(x)
为了使 P P P 成为一个定义良好的概率分布,我们需要 G = Pr x ∼ P 0 [ 1 L ( x ) ] > 0 G=\operatorname{Pr}_{\boldsymbol{x} \sim P_{0}}\left[\mathbb{1}_{\mathcal{L}}(\boldsymbol{x})\right]>0 G=Prx∼P0[1L(x)]>0。换句话说,必须有一种方法可以从 P 0 P_{0} P0 生成符合约束条件的字符串,并且 G G G 告诉我们该事件的概率。注意
P ( x ) = Pr X ∼ P 0 [ X = x ∣ X ∈ L ] P(\boldsymbol{x})=\operatorname{Pr}_{X \sim P_{0}}[X=\boldsymbol{x} \mid X \in \mathcal{L}] P(x)=PrX∼P0[X=x∣X∈L]
概率调节是一种诱人的条件生成方法,因为它是唯一一种保留所有满足条件事件相对概率的方法。
注意
P
P
P 是一个语言模型,因此它有条件前缀概率
P
⃗
\vec{P}
P。然而,通常情况下,
G
G
G 和条件前缀概率难以精确计算,因为它们涉及所有
x
∈
X
∗
\boldsymbol{x} \in \mathcal{X}^{*}
x∈X∗ 的不可行求和(Rosenfeld等人,2001)。这使得祖先抽样,即从条件前缀概率分布中左到右抽样变得不可行。接下来,我们将开发(近似)从
P
P
P 抽样的方法。
(序列级)拒绝抽样。从
P
P
P 抽样的最直接算法是拒绝抽样。请注意这是样本验证方法的意图:
def rejection_sampling():
while True:
\(\boldsymbol{x} \sim P_{0}\) # 从先验中抽样完整字符串
if \(\mathbb{1}_{\mathcal{L}}(\boldsymbol{x}):\) # 只有当条件被满足时才返回字符串
return \(x\)
```
拒绝抽样的预期运行时间为每样本 $\mathcal{O}(1 / G)$。所以在这种设置下只有当 $G \approx 1$ 时才是实际可行的。
局部约束解码。局部约束解码(通常通过令牌屏蔽执行)定义了一个语言模型 $\ell$,试图通过用 $\vec{\ell}\left(x^{\prime} \mid \boldsymbol{x}\right) \approx \vec{P}\left(x^{\prime} \mid \boldsymbol{x}\right)$ 近似 $\vec{P}$ 来近似 $P$,其中
$$
\vec{\ell}\left(x^{\prime} \mid \boldsymbol{x}\right) \stackrel{\text { def }}{=} \frac{\vec{P}_{0}\left(x^{\prime} \mid \boldsymbol{x}\right) \overrightarrow{\mathbb{1}_{\mathcal{L}}}\left(x^{\prime} \mid \boldsymbol{x}\right)}{L(\boldsymbol{x})} \text { and } L(\boldsymbol{x}) \stackrel{\text { def }}{=} \sum_{x^{\prime} \in, X \cup\{0\}} \vec{P}_{0}\left(x^{\prime} \mid \boldsymbol{x}\right) \overrightarrow{\mathbb{1}_{\mathcal{L}}}\left(x^{\prime} \mid \boldsymbol{x}\right)
$$
先前工作(如Lew等,2023;Park等,2024;Ahmed等,2025)表明这种局部近似在理论和实践中可能非常不同(即,有偏差)于 $P$。幸运的是,我们可以使用我们接下来描述的技术通过额外计算来改进这个近似(即克服这个偏差)。
解释为什么局部约束解码是有偏的。尽管 $\ell$ 是一种有效的生成满足 $\mathbb{1}_{\mathcal{L}}(\boldsymbol{x})$ 的字符串 $\boldsymbol{x} \sim \ell$ 的方法,但它倾向于过度代表某些字符串。我们可以通过字符串的相对概率量化这一点
$$
\rho(\boldsymbol{x}) \stackrel{\text { def }}{=} \frac{P(\boldsymbol{x})}{\ell(\boldsymbol{x})}=\frac{1}{G} \frac{P_{0}(\boldsymbol{x}) \mathbb{1}_{\mathcal{L}}(\boldsymbol{x})}{\ell(\boldsymbol{x})}=\frac{1}{G} \prod_{t=1}^{|\boldsymbol{x}|+1} L\left(\boldsymbol{x}_{<t}\right)
$$
因为
$$
P(\boldsymbol{x})=\frac{P_{0}(\boldsymbol{x}) \mathbb{1}_{\mathcal{L}}(\boldsymbol{x})}{G} \quad \text { and } \quad \ell(\boldsymbol{x})=\frac{P_{0}(\boldsymbol{x}) \mathbb{1}_{\mathcal{L}}(\boldsymbol{x})}{\prod_{t=1}^{|\boldsymbol{x}|+1} L\left(\boldsymbol{x}_{<t}\right)}
$$
换句话说,如果我们比较来自局部分布 $\ell$ 的样本与其在全局分布 $P$ 中的相对概率,那么字符串 $\boldsymbol{x}$ 将以 $\rho(\boldsymbol{x})$ 更多或更少的速率出现,具体取决于 $\rho(\boldsymbol{x})<1$ 或 $\rho(\boldsymbol{x})>1$。
在这项工作中,对于所有 $\boldsymbol{x}$,$L(\boldsymbol{x}) \leq 1$。
在 $\rho(\boldsymbol{x})$ 的表达式中,实际上依赖于字符串 $\boldsymbol{x}$ 而独立于 $G$ 的因子对我们来说是幸运的,因为我们无法高效地计算 $G$。设 $w(\boldsymbol{x})=G \rho(\boldsymbol{x})=$ $\prod_{t=1}^{|\boldsymbol{x}|+1} L\left(\boldsymbol{x}_{<t}\right)$
显然,$\prod_{t=1}^{|\boldsymbol{x}|+1} L\left(\boldsymbol{x}_{<t}\right)$ 对样本质量是一个重要的诊断指标。
操作上,当从 $\ell$ 抽样时,累积乘积的局部 L 是检测低质量样本的有用信号。
有趣的是,平均权重等于 $G$,即,$\mathbb{E}_{\boldsymbol{x} \sim \ell}\left[\prod_{t=1}^{|\boldsymbol{x}|+1} L\left(\boldsymbol{x}_{<t}\right)\right]=G$。
虽然偏差表达式不关心顺序,但很难不去思考从 $\ell$ 祖先抽样的操作视图;在这种视图中,样本是通过从条件令牌分布中抽样从左到右创建的。我们说我们的特定样本受到其局部归一化常数乘积的影响。这个量衡量了约束如何影响样本。如果约束只排除了非常低(甚至零)概率的令牌,则失真将很小,因为 $L$ 将接近 1。
这种操作视图激发了SMC。在SMC的情况下,我们比较长度 $\leq t$ 的完整和不完整的字符串样本,并重新抽样那些看起来在轨道上的样本,即,
偏向那些具有更高中间权重值的样本。因此,如果粒子最初被提议分布所青睐,则可能会被复制的高权重粒子取代。
以下是一个简单的例子,说明全局调节,可以用来说明相对于局部调节的区别。
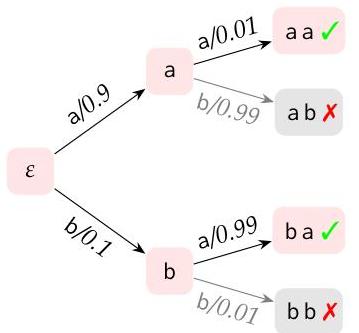
例1. 假设 $\mathcal{X}=\{\mathrm{a}, \mathrm{b}\}$,有效字符串的语言是 $\mathcal{L}=\{\mathrm{aa}, \mathrm{ba}\}$,并且概率分布在以下概率树中给出,该树用有效和无效字符串进行了注释:
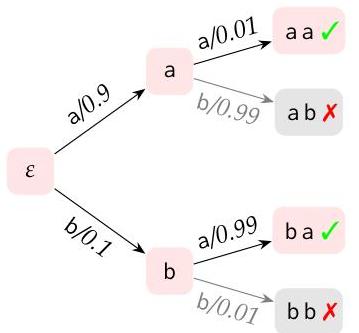
在原始分布下,我们有
$p(\mathrm{a} \mathrm{a})=.9 \cdot .01=0.009$
$p(\mathrm{ab})=.9 \cdot .99=0.891$
$p(b a)=.1 \cdot .99=0.099$
$p(b b)=.1 \cdot .01=0.001$
全局调节分布是
$\vec{P}(\mathrm{aa})=.083333$
$\vec{P}(\mathrm{ba})=.916667$
这个例子展示了局部反转:在原始分布 $P_{0}$ 下,第一个符号在 .9 的情况下是 a,而在 .1 的情况下是 b。然而,在调节之后,使 a 如此常见的情况(即 ab)被禁止。更重要的是,b 的一些次要情况也被禁止。这使得全局调节后的条件前缀概率变为:
$\vec{P}(\mathrm{a} \mid \varepsilon)=\frac{0.009}{0.009+.099}=.083333$
$\vec{P}(\mathrm{~b} \mid \varepsilon)=\frac{0.099}{0.009+.099}=.916667$
这是一个相对于 .9 和 .1 的剧烈反转。
重要性抽样。在我们的设定中,重要性抽样是一种简单的基于抽样的近似推断技术,可以用来扩展局部约束的数据并带有一个权重校正。权重校正允许我们通过更多抽样来克服 $\tilde{\ell} \approx \vec{P}$ 的偏差。给定计算预算为 $M>0$ 次抽样,重要性抽样过程如下所示:
1. 从局部约束分布中抽样:$\boldsymbol{x}^{(1)}, \ldots, \boldsymbol{x}^{(M)} \stackrel{\text { i.i.d. }}{\sim} q$,其中 $q$ 是一个提议分布,例如 $q=\ell$。
2. 2. 计算每个 $m: w^{(m)}=\frac{P_{0}\left(\boldsymbol{x}^{(m)}\right.}{q\left(\boldsymbol{x}^{(m)}\right)}$ 的权重。对于特殊情况 $q=\ell$,权重简化为 $w^{(m)}=\prod_{t=1}^{\left|x^{(m)}\right|+1} L\left(\boldsymbol{x}_{<t}\right)$。
3. 3. 定义估计
$$
\widehat{G} \stackrel{\text { def }}{=} \frac{1}{M} \sum_{m=1}^{M} w^{(m)} \quad \widehat{\bar{P}}(\boldsymbol{x}) \stackrel{\text { def }}{=} \frac{1}{M} \sum_{m=1}^{M} w^{(m)} \mathbb{1}_{\boldsymbol{x}=\boldsymbol{x}^{(m)}} \quad \widehat{P}(\boldsymbol{x}) \stackrel{\text { def }}{=} \frac{\widehat{\bar{P}}(\boldsymbol{x})}{\widehat{G}}
$$
4. 返回来自后验估计 $\widehat{P}$ 的样本
例2 (续例1)。回到上述例子,在这种情况下,使用局部条件分布作为提议的重要性抽样生成
$\ell(\mathrm{a} \mathrm{a})=.9$,权重 $L(\mathrm{a}) \cdot L(\mathrm{a} \mathrm{a})=1 \cdot .01=.01$
$\ell(\mathrm{b} \mathrm{a})=.1$,权重 $L(\mathrm{~b}) \cdot L(\mathrm{~b} \mathrm{a})=1 \cdot .99=.99$
因此,重要性加权分布估计为
$\widehat{P}(\mathrm{a} \mathrm{a})=\frac{.01 .9}{.01 .9+.1 .99}=.083333$
$\widehat{P}(\mathrm{~b} \mathrm{a})=\frac{9+.1}{.01 .9+.1 .99}=.916667$
这正是全局分布。
序贯蒙特卡洛。序贯蒙特卡洛(SMC)是重要性抽样的扩展,它有效地将重要性抽样应用于一系列中间目标分布,这些分布旨在保持部分生成在轨道上,而不是整个序列一次。
我们定义一个中间塑造函数 $\vec{\varphi}: \mathcal{X}^{*} \rightarrow \mathbb{R}_{\geq 0}$,这是为部分生成的字符串提供中间反馈的关键。另一方面,完整字符串将由 $\widehat{P}$ 判断。在此工作中,我们使用 $\vec{\varphi}(\boldsymbol{x})=\widehat{P}_{0}(\boldsymbol{x}) \mathbb{1}_{\mathcal{C}}^{\prime}(\boldsymbol{x})$ 作为我们的塑造函数,但我们会很快讨论替代方案。在我们的SMC算法版本中,完整和不完整的字符串都将通过时间索引状态空间演变,其中在时间 $t$,状态包含两个变量:长度 $\leq t$ 的字符串,布尔值指示字符串是否处于活动状态(未完成)。当字符串处于活动状态时,其长度限制为等于 $t$。一旦字符串完成,就永远不会改变,即,不能向其附加符号。
我们将初始目标定义为
$$
\pi_{0}(\alpha, \boldsymbol{x}) \stackrel{\text { def }}{=} \mathbb{1}_{\alpha=\top, \boldsymbol{x}=\varepsilon}
$$
这意味着最初唯一可能的状态是 $\langle\top, \varepsilon\rangle$,即,处于活动状态并等于空字符串。我们定义中间目标 $\pi_{t}$(对于 $t>0$ )为 ${ }^{9}$
$$
\begin{aligned}
\pi_{t}(\alpha, \boldsymbol{x}) & =\vec{\varphi}(\boldsymbol{x}) \mathbb{1}_{|\boldsymbol{x}|=t, \alpha=\top} & & {[\text { incomplete }]} \\
& +\widehat{P}(\boldsymbol{x}) \mathbb{1}_{|\boldsymbol{x}|<t, \alpha=\perp} & & {[\text { complete; length }<t]}
\end{aligned}
$$
注意当 $t \rightarrow \infty, \pi_{t}(\top, \cdot)$ 收敛到 $\widehat{P}$。
在此工作中,${ }^{10}$ 我们使用 $\vec{\varphi}(\boldsymbol{x})=\widehat{P}_{0}(\boldsymbol{x}) \mathbb{1}_{\mathcal{C}}^{\prime}(\boldsymbol{x})$ 作为我们的塑造函数(如Loula等人,2025)。在这种选择的中间目标下,约束检查器确保我们始终至少有一个有效的字符串前缀 $\boldsymbol{x}$ 的完整。这种反馈对于尽快检测到字符串保证失败的情况很有用,并且对于检测到先验的大部分概率质量已被消除的情况也很有用(即,在重要性抽样的意义上,我们很可能有一个低权重的粒子)。关于 $\widehat{P}$,它提供了
${ }^{9} \mathrm{~A}$ 完整字符串 $x$ 需要 $|\boldsymbol{x}|+1$ 步才能生成,这是由于最后的 $\square$ 事件。这就是为什么 $\pi_{t}$ 包含长度小于 $t$ 的完整字符串,而不是(比如说)$\leq t$。
${ }^{10} \mathrm{~A}$ 设计 $\vec{\varphi}$ 的指导原则是近似 $\vec{\varphi} \approx \vec{P}$。然而,任何满足技术条件 $\vec{\varphi}(\boldsymbol{x})=0 \Longrightarrow \widehat{P}(\boldsymbol{x})=0$ 的 $\vec{\varphi}$ 选择都会收敛(尽管速度不同)。注意如果 $\vec{\varphi}=\widehat{P}$,SMC算法是 $P$ 的精确采样器。不幸的是,精确计算 $\widehat{P}$ 是不可行的,所以我们必须对其进行近似。
对于 $\rho(\boldsymbol{x})$,实际上是独立于 $G$ 的字符串 $\boldsymbol{x}$ 的因素,这对我们来说是很幸运的,因为我们无法高效地计算 $G$。设 $w(\boldsymbol{x})=G \rho(\boldsymbol{x})=$ $\prod_{t=1}^{|\boldsymbol{x}|+1} L\left(\boldsymbol{x}_{<t}\right)$
显然,$\prod_{t=1}^{|\boldsymbol{x}|+1} L\left(\boldsymbol{x}_{<t}\right)$ 是样本质量的重要诊断依据。
操作上,当从 $\ell$ 中抽样时,局部 L 的累积乘积是一个检测低质量样本的有用信号。
有趣的是,平均权重等于 $G$,即,$\mathbb{E}_{\boldsymbol{x} \sim \ell}\left[\prod_{t=1}^{|\boldsymbol{x}|+1} L\left(\boldsymbol{x}_{<t}\right)\right]=G$。
虽然偏差表达式不关心顺序,但很难不去思考从 $\ell$ 进行祖先后代抽样的操作视图;在这种视图中,样本是通过从条件令牌分布中抽样从左到右创建的。我们说我们的特定样本受到其局部归一化常数乘积的扭曲。这个量衡量了约束对样本的影响程度。如果约束仅排除了非常低(甚至零)概率的令牌,那么失真将会很小,因为 $L$ 将接近 1。
这种操作视图激发了SMC。在SMC的情况下,我们比较长度 $\leq t$ 的完整和不完整字符串样本,并重新抽样那些似乎在轨的样本,即,
偏向那些具有更高中间权重值的样本。因此,如果一个粒子最初被提议分布所青睐,则可能会被替换为更高权重粒子的副本。
下面是一个简单的例子,说明全局调节,可以用来说明相对于局部调节的区别。
示例1. 假设 $\mathcal{X}=\{\mathrm{a}, \mathrm{b}\}$,有效字符串的语言是 $\mathcal{L}=\{\mathrm{aa}, \mathrm{ba}\}$,并且概率分布在以下概率树中编码,该树用有效和无效字符串进行了注释:
在原始分布下,我们有
$p(\mathrm{a} \mathrm{a})=.9 \cdot .01=0.009$
$p(\mathrm{ab})=.9 \cdot .99=0.891$
$p(b a)=.1 \cdot .99=0.099$
$p(b b)=.1 \cdot .01=0.001$
全局调节分布为
$\vec{P}(\mathrm{aa})=.083333$
$\vec{P}(\mathrm{ba})=.916667$
这个例子展示了一个局部反转:在原始分布 $P_{0}$ 下,第一个符号在 .9 的情况下是 a,而在 .1 的情况下是 b。然而,在调节之后,使 a 如此常见的案例(即 ab)被禁止。而且,不太重要的是,b 的一个小案例也被禁止。这使得全局调节后的条件前缀概率为:
$\vec{P}(\mathrm{a} \mid \varepsilon)=\frac{0.009}{0.009+.099}=.083333$
$\vec{P}(\mathrm{~b} \mid \varepsilon)=\frac{0.099}{0.009+.099}=.916667$
这分别对应于 .9 和 .1 的剧烈反转。
重要性抽样。在我们的设定中,重要性抽样是一种简单的基于抽样的近似推断技术,可以通过权重校正扩展局部约束数据。权重校正允许我们通过更多抽样克服 $\tilde{\ell} \approx \vec{P}$ 的偏差。给定计算预算为 $M>0$ 次抽样,重要性抽样过程如下所示:
1. 从局部约束分布中抽样:$\boldsymbol{x}^{(1)}, \ldots, \boldsymbol{x}^{(M)} \stackrel{\text { i.i.d. }}{\sim} q$,其中 $q$ 是一个提议分布,例如 $q=\ell$。
2. 2. 计算每个 $m: w^{(m)}=\frac{P_{0}\left(\boldsymbol{x}^{(m)}\right.}{q\left(\boldsymbol{x}^{(m)}\right)}$ 的权重。对于特殊情形 $q=\ell$,权重简化为 $w^{(m)}=\prod_{t=1}^{\left|x^{(m)}\right|+1} L\left(\boldsymbol{x}_{<t}\right)$。
3. 3. 定义估计
$$
\widehat{G} \stackrel{\text { def }}{=} \frac{1}{M} \sum_{m=1}^{M} w^{(m)} \quad \widehat{\bar{P}}(\boldsymbol{x}) \stackrel{\text { def }}{=} \frac{1}{M} \sum_{m=1}^{M} w^{(m)} \mathbb{1}_{\boldsymbol{x}=\boldsymbol{x}^{(m)}} \quad \widehat{P}(\boldsymbol{x}) \stackrel{\text { def }}{=} \frac{\widehat{\bar{P}}(\boldsymbol{x})}{\widehat{G}}
$$
4. 返回来自后验估计 $\widehat{P}$ 的样本
生成
$\ell(\mathrm{a} \mathrm{a})=.9$,权重为 $L(\mathrm{a}) \cdot L(\mathrm{a} \mathrm{a})=1 \cdot .01=.01$
$\ell(\mathrm{b} \mathrm{a})=.1$,权重为 $L(\mathrm{~b}) \cdot L(\mathrm{~b} \mathrm{a})=1 \cdot .99=.99$
因此,重要性加权分布估计为
$\widehat{P}(\mathrm{a} \mathrm{a})=\frac{.01 .9}{.01 .9+.1 .99}=.083333$
$\widehat{P}(\mathrm{~b} \mathrm{a})=\frac{.9+.1}{.01 .9+.1 .99}=.916667$
这正是全局分布。
序贯蒙特卡洛。序贯蒙特卡洛(SMC)是重要性抽样的扩展,它有效地将重要性抽样应用于一系列中间目标分布,这些分布旨在保持部分生成在轨道上,而不是整个序列一次。
我们定义一个中间塑造函数 $\vec{\varphi}: \mathcal{X}^{*} \rightarrow \mathbb{R}_{\geq 0}$,这是为部分生成的字符串提供中间反馈的关键。另一方面,完整字符串将由 $\widehat{P}$ 判断。在此工作中,我们使用 $\vec{\varphi}(\boldsymbol{x})=\widehat{P}_{0}(\boldsymbol{x}) \mathbb{1}_{\mathcal{C}}^{\prime}(\boldsymbol{x})$ 作为我们的塑造函数(如Loula等人,2025)。在这种选择的中间目标下,约束检查器确保我们始终至少有一个有效的字符串前缀 $\boldsymbol{x}$ 的完整。这种反馈对于尽快检测到字符串保证失败的情况很有用,并且对于检测到先验的大部分概率质量已被消除的情况也很有用(即,在重要性抽样的意义上,我们很可能有一个低权重粒子)。关于 $\widehat{P}$,它提供了
${ }^{9}$ 完整字符串 $x$ 需要 $|\boldsymbol{x}|+1$ 步才能生成,这是由于最后的 $\square$ 事件。这就是为什么 $\pi_{t}$ 包含长度小于 $t$ 的完整字符串,而不是(例如)$\leq t$。
${ }^{10}$ 设计 $\vec{\varphi}$ 的指导原则是近似 $\vec{\varphi} \approx \vec{P}$。然而,任何满足技术条件 $\vec{\varphi}(\boldsymbol{x})=0 \Longrightarrow \widehat{P}(\boldsymbol{x})=0$ 的 $\vec{\varphi}$ 选择都会收敛(尽管速度不同)。注意如果 $\vec{\varphi}=\widehat{P}$,那么SMC算法就是 $P$ 的精确采样器。不幸的是,精确计算 $\widehat{P}$ 是不可行的,所以我们必须对其进行近似。
足够的条件以确定 $\vec{P}(\boldsymbol{x})=0$。然而,它并未提供更多超出这一点的信息。 ${ }^{11}$
我们定义简写
$$
\vec{\psi}\left(x^{\prime} \mid \boldsymbol{x}\right) \stackrel{\text { def }}{=} \begin{cases}\frac{\vec{P}(\boldsymbol{x})}{\vec{\psi}(\boldsymbol{x})} & \text { 如果 } x^{\prime}=\square \\ \frac{\vec{\psi}\left(\boldsymbol{x} x^{\prime}\right)}{\vec{\psi}(\boldsymbol{x})} & \text { 否则 }\end{cases}
$$
重要的是,此定义给出了 $\vec{P}, \forall \boldsymbol{x} \in \mathcal{X}^{*}$ 的以下分解,
$$
\vec{P}(\boldsymbol{x})=\vec{\psi}(\varepsilon) \vec{\psi}(\square \mid \boldsymbol{x}) \prod_{t=1}^{|\boldsymbol{x}|} \vec{\psi}\left(x_{t} \mid \boldsymbol{x}_{<t}\right)
$$
验证完全字符串的形状权重与重要性抽样中使用的形状权重等价很简单:
$$
\frac{\vec{P}(\boldsymbol{x})}{q(\boldsymbol{x})}=\vec{\psi}(\varepsilon) \frac{\vec{\psi}(\square \mid \boldsymbol{x})}{\vec{q}(\square \mid \boldsymbol{x})} \prod_{t=1}^{|\boldsymbol{x}|} \frac{\vec{\psi}\left(x_{t} \mid \boldsymbol{x}_{<t}\right)}{\vec{q}\left(x_{t} \mid \boldsymbol{x}_{<t}\right)}
$$
我们在Alg. 1中提供了SMC过程的伪代码。
算法1 序列蒙特卡洛
procedure (\operatorname{SMC}(q, \vec{\psi}, M, \tau))
for (m=1 \ldots M);
(\left(x^{(m)}, w^{(m)}, \alpha^{(m)}\right) \leftarrow(\varepsilon, \vec{\psi}(\varepsilon)), true ())
while (\exists m \in 1 \ldots M: \alpha^{(m)}😃
for (m=1 \ldots M) s.t. (\alpha^{(m)}😃
(x^{\prime} \sim q\left(\cdot \mid \boldsymbol{x}^{(m)}\right))
if (x^{\prime}=\square:)
(\alpha^{(m)} \leftarrow) false
else
(x^{(m)} \leftarrow x^{(m)} \circ x^{\prime})
(w^{(m)} \leftarrow w^{(m)} \frac{\vec{\psi}\left(x^{\prime} \mid \boldsymbol{x}{(m)}\right)}{q\left(x{\prime} \mid \boldsymbol{x}^{(m)}\right)})
(\left(x^{( }\right), w^{( }\left), \alpha^{( }\right)\right) \leftarrow \operatorname{RESAMPLE}\left(x^{( }\right), w^{( }\left), \alpha^{( }\right), \tau) )
(\vec{G} \leftarrow \frac{1}{M} \sum_{m=1}^{M} w^{(m)})
(\vec{P}(\boldsymbol{x}) \leftarrow \frac{1}{M} \sum_{m=1}^{M} w^{(m)} \mathbb{1}\left{\boldsymbol{x}=\boldsymbol{x}^{(m)}\right})
(\vec{P}(\boldsymbol{x}) \leftarrow \frac{\vec{P}(\boldsymbol{x})}{G})
return ((\vec{G}, \vec{P}, \vec{P}))
procedure RESAMPLE (\left(\boldsymbol{x}^{( }\right), w^{( }\left), \alpha^{( }\right), \tau) )
(W \leftarrow \sum_{m=1}^{M} w^{(m)})
(\vec{M} \leftarrow W^{2} /\left(\sum_{m=1}{M}\left(w{(m)}\right)^{2}\right) \quad \triangleright) 有效样本量
if (\vec{M}<\tau \cdot M: \quad \triangleright) 如果需要,则重新抽样
(\vec{x}^{( }\leftarrow \boldsymbol{x}^{( }\left); \bar{w}^{( }\leftarrow w^{( }\right) \quad \triangleright) 临时副本
for (m=1 \ldots M:)
(R \sim \operatorname{Categorical}\left(\frac{1}{W}\left(\bar{w}^{(1)}, \ldots, \bar{w}^{(M)}\right)\right))
(\left(x^{(m)}, w^{(m)}, \alpha^{(m)}\right) \leftarrow\left(\bar{x}^{®}, W / M, \alpha^{®}\right))
return (\left(x^{( }\right), w^{( }\left), \alpha^{( }\right))
适当加权令牌提议的扩展。我们的方法使用了Alg. 1的一个扩展,允许适当的加权提议分布。更具体地说,令牌提议
${ }^{11}$ 注意从技术条件的角度来看,允许 $\vec{x}_{C}(x)$ 存在假阳性(即被认为是可接受但实际上不是的字符串)是可以的;但是禁止假阴性。
```
procedure \(\operatorname{SMC}-\operatorname{PWP}(q, \tilde{\psi}, M, \tau)\)
for \(m=1 \ldots M\)
\(\left(x^{(m)}, w^{(m)}, \alpha^{(m)}\right) \leftarrow(\varepsilon, \tilde{\psi}(\varepsilon)\), true \()\)
while \(\exists m \in 1 \ldots M: \alpha^{(m)}:\)
for \(m=1 \ldots M\) s.t. \(\alpha^{(m)}:\)
\(\left(x^{\prime}, w^{\prime}\right) \sim q\left(\cdot \mid x^{(m)}\right)\)
if \(x^{\prime}=\square:\)
\(\alpha^{(m)} \leftarrow\) false
else
\(x^{(m)} \leftarrow x^{(m)} \circ x^{\prime}\)
\(w^{(m)} \leftarrow w^{(m)} \cdot w^{\prime}\)
\(\left(x^{( }, w^{( }, \alpha^{( }), \alpha^{( })\right) \leftarrow \operatorname{RESAMPLE}\left(x^{( }, w^{( }, \alpha^{( }, \tau)\right.\)
\(\tilde{G} \leftarrow \frac{1}{M} \sum_{m=1}^{M} w^{(m)}\)
\(\tilde{\tilde{P}}(x) \leftarrow \frac{1}{M} \sum_{m=1}^{M} w^{(m)} \mathbb{1}\left\{x=x^{(m)}\right\}\)
\(\tilde{P}(x) \leftarrow \frac{\tilde{P}(x)}{\tilde{G}}\)
return \((\tilde{G}, \tilde{P}, \tilde{P})\)
procedure RESAMPLE \(\left(\boldsymbol{x}^{( }\right), w^{( }\left), \alpha^{( }\right), \tau\) )
\(W \leftarrow \sum_{m=1}^{M} w^{(m)}\)
\(\vec{M} \leftarrow W^{2} /\left(\sum_{m=1}^{M}\left(w^{(m)}\right)^{2}\right) \quad \triangleright\) 有效样本大小
if \(\vec{M}<\tau \cdot M: \quad \triangleright\) 如有需要重新采样
\(\vec{x}^{( }\leftarrow \boldsymbol{x}^{( }\left); \bar{w}^{( }\leftarrow w^{( }\right) \quad \triangleright\) 临时副本
for \(m=1 \ldots M:\)
\(R \sim \operatorname{Categorical}\left(\frac{1}{W}\left(\bar{w}^{(1)}, \ldots, \bar{w}^{(M)}\right)\right)\)
\(\left(x^{(m)}, w^{(m)}, \alpha^{(m)}\right) \leftarrow\left(\bar{x}^{(R)}, W / M, \alpha^{(R)}\right)\)
return \(\left(x^{( }\right), w^{( }\left), \alpha^{( }\right)\)
B 递归辅助变量推断 (RAVI)
重要性抽样是一种通过提议分布
q
q
q 进行未标准化目标分布
p
ˉ
\bar{p}
pˉ 的近似抽样方法,其标准化常数为
Z
Z
Z。我们希望设计具有有利属性的
q
q
q 以实现下游目标,例如高效的运行时间。关键在于,这种强提议分布
q
q
q 的设计通常通过辅助随机选择
r
r
r 来调解,使得我们抽样得到
⟨
x
,
r
⟩
∼
q
\langle x, r\rangle \sim q
⟨x,r⟩∼q。当这种情况发生时,有必要计算权重
w
(
x
,
r
)
w(x, r)
w(x,r) 以校正
r
r
r。
RAVI(Lew 等人,2022)为我们提供了一种通用灵活的方法来推导相对任意选择的
q
q
q 的权重。在 RAVI 中,我们可以处理任何空间
X
\mathcal{X}
X 上的任何未标准化目标分布
p
ˉ
\bar{p}
pˉ。令
⟨
x
,
w
⟩
∼
Q
\langle x, w\rangle \sim Q
⟨x,w⟩∼Q 表示从提议
q
q
q 抽样并计算其权重
w
w
w 的过程。我们感兴趣的是开发具有以下性质的
Q
Q
Q:
定义3. 提议分布
Q
Q
Q 是适当加权的,如果:
E ⟨ x , w ⟩ ∼ Q [ w f ( x ) ] = Z E x ∼ p [ f ( x ) ] \underset{\langle x, w\rangle \sim Q}{\mathbb{E}}[w f(x)]=Z \underset{x \sim p}{\mathbb{E}}[f(x)] ⟨x,w⟩∼QE[wf(x)]=Zx∼pE[f(x)]
请注意,通过取平凡的 f ( x ) = 1 f(x)=1 f(x)=1,该性质意味着 E ⟨ x , w ⟩ ∼ Q [ w ] = Z \mathbb{E}_{\langle x, w\rangle \sim Q}[w]=Z E⟨x,w⟩∼Q[w]=Z。
B. 1 提议
RAVI 提议是一个联合分布
q
(
r
,
x
)
q(r, x)
q(r,x) 在乘积空间
R
×
X
\mathcal{R} \times \mathcal{X}
R×X 上,其中
R
\mathcal{R}
R 持有提议所作的辅助随机选择。通常,提议将被设计成使边缘
q
(
x
)
q(x)
q(x) 成为对目标
p
(
x
)
p(x)
p(x) 的良好近似。
在本工作中,我们考虑的完全是精确提议,其中
q
(
x
)
=
p
(
x
)
q(x)=p(x)
q(x)=p(x)。这是通过各种形式的拒绝抽样实现的,其中
r
r
r 表示拒绝抽样器生成的辅助随机性。由于
q
(
x
)
=
∑
r
∈
R
q
(
r
,
x
)
q(x)=\sum_{r \in \mathcal{R}} q(r, x)
q(x)=∑r∈Rq(r,x) 通常是无法精确评估的,通常的重要性权重
w
=
p
ˉ
(
x
)
q
(
x
)
w=\frac{\bar{p}(x)}{q(x)}
w=q(x)pˉ(x) 不能直接计算。RAVI 提供了一种可以高效计算(嘈杂的)重要性权重的方法,同时仍满足适当加权。
B. 2 元提议
RAVI 元提议 h ( r ; x ) h(r ; x) h(r;x) 被设计用来根据已知的 x x x 推断 r r r。最优元提议应为 q ( r ∣ x ) = def q ( r , x ) / q ( x ) q(r \mid x) \stackrel{\text { def }}{=} q(r, x) / q(x) q(r∣x)= def q(r,x)/q(x),但这种最优选择通常是不可行的。在实践中,我们选择了一个概率分布族 h ( r ; x ) h(r ; x) h(r;x) 在 R \mathcal{R} R 上,由 x ∈ X x \in \mathcal{X} x∈X 索引,并具有适当的支撑,以便定义一个“扩展”的目标 ( p ˉ h ) ( r , x ) = def p ˉ ( x ) h ( r ; x ) (\bar{p} h)(r, x) \stackrel{\text { def }}{=} \bar{p}(x) h(r ; x) (pˉh)(r,x)= def pˉ(x)h(r;x) 在联合空间上。正式地,我们需要 p ˉ h ≪ q . 12 \bar{p} h \ll q.{ }^{12} pˉh≪q.12 对于给定的 x x x,这意味着 h h h 应该以概率1提出某个 r r r 使得 q ( r , x ) > 0 q(r, x)>0 q(r,x)>0。
B. 3 适当加权抽样
定义4. 我们定义从提议 q q q 和元提议 h h h 中进行的一级RAVI抽样(参见定义5中的两级RAVI抽样)如下:
-
生成 ( r , x ) ∼ q (r, x) \sim q (r,x)∼q。
-
- 评估 w = def p ˉ ( x ) h ( r ; x ) q ( r , x ) w \stackrel{\text { def }}{=} \frac{\bar{p}(x) h(r ; x)}{q(r, x)} w= def q(r,x)pˉ(x)h(r;x)。
-
- 返回
⟨
x
,
w
⟩
\langle x, w\rangle
⟨x,w⟩。
这可以被视为在扩展状态空间 R × X \mathcal{R} \times \mathcal{X} R×X 上的标准重要性抽样。加权值 ⟨ ⟨ r , x ⟩ , w ⟩ \langle\langle r, x\rangle, w\rangle ⟨⟨r,x⟩,w⟩ 对扩展目标 p ˉ ( x ) h ( r ; x ) \bar{p}(x) h(r ; x) pˉ(x)h(r;x) 是适当加权的,这意味着加权值 ⟨ x , w ⟩ \langle x, w\rangle ⟨x,w⟩ 对重新边际化的
12 { }^{12} 12 对于在同一域上的两个分布 μ , ν \mu, \nu μ,ν,如果 μ \mu μ 在所有 ν \nu ν 为零的地方也为零,则称 μ \mu μ 关于 ν \nu ν 是绝对连续的(AC),记为 μ ≪ v \mu \ll v μ≪v。
目标 p ⃗ ( x ) \vec{p}(x) p(x) 是适当加权的。当 h ( r ; x ) h(r ; x) h(r;x) 执行“完美元推断”,即当 h ( r ; x ) = q ( r ∣ x ) h(r ; x)=q(r \mid x) h(r;x)=q(r∣x) 时,那么 w = p ⃗ ( x ) h ( r ; x ) q ( r , x ) = p ⃗ ( x ) q ( r ∣ x ) q ( r ∣ x ) q ( x ) = p ⃗ ( x ) q ( x ) w=\frac{\vec{p}(x) h(r ; x)}{q(r, x)}=\frac{\vec{p}(x) q(r \mid x)}{q(r \mid x) q(x)}=\frac{\vec{p}(x)}{q(x)} w=q(r,x)p(x)h(r;x)=q(r∣x)q(x)p(x)q(r∣x)=q(x)p(x),这意味着我们计算出了确切的重要性权重。否则,重要性权重会更加嘈杂,但仍然具有相同的期望值(即, E [ w ∣ x ] = p ⃗ ( x ) q ( x ) \mathbb{E}[w \mid x]=\frac{\vec{p}(x)}{q(x)} E[w∣x]=q(x)p(x);结果我们也得到了 E [ w ] = E ( r , x ) ∼ q [ p ⃗ ( x ) q ( x ) ] = Z \mathbb{E}[w]=\mathbb{E}_{(r, x) \sim q}\left[\frac{\vec{p}(x)}{q(x)}\right]=Z E[w]=E(r,x)∼q[q(x)p(x)]=Z)。
命题5. 给定提议 q ( r , x ) q(r, x) q(r,x) 和元提议 h ( r ; x ) h(r ; x) h(r;x),使得 p ⃗ h ≪ q \vec{p} h \ll q ph≪q,Def. 4 对 p ⃗ \vec{p} p 是适当加权的。 - 返回
⟨
x
,
w
⟩
\langle x, w\rangle
⟨x,w⟩。
证明。
KaTeX parse error: Expected '}', got '&' at position 757: …ribution] } \\ &̲ {[Def. of } p]…
B. 4 更深的递归推理
如果我们自己的元推理 h h h 引入辅助变量 s ∈ S s \in \mathcal{S} s∈S(所以我们就有了 h ( s , r ; x ) h(s, r ; x) h(s,r;x) ),那么我们可以重复这个过程,添加一个元-元提议 j ( s ; r , x ) j(s ; r, x) j(s;r,x) 来逼近 h ( s ∣ r ; x ) h(s \mid r ; x) h(s∣r;x)。然后我们的适当加权算法就变成了:
定义5. 我们定义从提议 q q q、元提议 h h h 和元-元提议 j j j 中进行的两级RAVI抽样如下:
- 生成 ( r , x ) ∼ q (r, x) \sim q (r,x)∼q 和 s ∼ j ( ⋅ ; r , x ) s \sim j(\cdot ; r, x) s∼j(⋅;r,x)。
-
- 评估 w = def p ⃗ ( x ) h ( s , r , x ) q ( r , x ) j ( s ; r , x ) w \stackrel{\text { def }}{=} \frac{\vec{p}(x) h(s, r, x)}{q(r, x) j(s ; r, x)} w= def q(r,x)j(s;r,x)p(x)h(s,r,x)。
-
- 返回
⟨
x
,
w
⟩
\langle x, w\rangle
⟨x,w⟩。
直观上,由于 h h h “过度扩展”了目标分布,不仅包括了 r r r 还包括了 s s s,我们必须现在用一个分布在 s s s 上的分布 j j j 来扩展提议 q q q。一般来说,我们可以继续这个过程(例如,如果 j j j 有辅助变量),交替扩展模型和提议,直到我们到达不再引入新辅助变量的扩展。
- 返回
⟨
x
,
w
⟩
\langle x, w\rangle
⟨x,w⟩。
命题6. 给定提议
q
(
r
,
x
)
q(r, x)
q(r,x)、元提议
h
(
s
,
r
;
x
)
h(s, r ; x)
h(s,r;x) 和元-元提议
j
(
s
;
r
,
x
)
j(s ; r, x)
j(s;r,x),使得
p
⃗
h
≪
q
j
\vec{p} h \ll q j
ph≪qj,Def. 5 对
p
⃗
\vec{p}
p 是适当加权的。
证明。
E ⟨ x , w ⟩ ∼ Q S-RAVI [ w f ( x ) ] = E ⟨ r , x ⟩ ∼ q , s ∼ j ( ⋅ ; r , x ) [ p ˉ ( x ) h ( s , r ; x ) q ( r , x ) j ( s ; r , x ) f ( x ) ] = ∑ r ∈ R ∑ s ∈ X ∑ s ∈ S q ( r , x ) j ( s ; r , x ) p ˉ ( x ) h ( s , r ; x ) q ( r , x ) j ( s ; r , x ) f ( x ) = ∑ r ∈ R ∑ s ∈ X ∑ s ∈ S p ˉ ( x ) h ( s , r ; x ) f ( x ) = ∑ x ∈ X p ˉ ( x ) f ( x ) ∑ r ∈ R ∑ s ∈ S h ( s , r ; x ) = ∑ x ∈ X p ˉ ( x ) f ( x ) ∑ r ∈ R h ( r ; x ) = ∑ x ∈ X p ˉ ( x ) f ( x ) = ∑ x ∈ X Z p ( x ) f ( x ) = Z ∑ x ∈ X p ( x ) f ( x ) = Z E x ∼ p [ f ( x ) ] \begin{aligned} & \underset{\langle x, w\rangle \sim Q_{\text {S-RAVI }}}{\mathbb{E}}[w f(x)] \\ & =\underset{\langle r, x\rangle \sim q, s \sim j(\cdot ; r, x)}{\mathbb{E}}\left[\frac{\bar{p}(x) h(s, r ; x)}{q(r, x) j(s ; r, x)} f(x)\right] \\ & =\sum_{r \in \mathcal{R}} \sum_{s \in \mathcal{X}} \sum_{s \in \mathcal{S}} q(r, x) j(s ; r, x) \frac{\bar{p}(x) h(s, r ; x)}{q(r, x) j(s ; r, x)} f(x) \\ & =\sum_{r \in \mathcal{R}} \sum_{s \in \mathcal{X}} \sum_{s \in \mathcal{S}} \bar{p}(x) h(s, r ; x) f(x) \\ & =\sum_{x \in \mathcal{X}} \bar{p}(x) f(x) \sum_{r \in \mathcal{R}} \sum_{s \in \mathcal{S}} h(s, r ; x) \\ & =\sum_{x \in \mathcal{X}} \bar{p}(x) f(x) \sum_{r \in \mathcal{R}} h(r ; x) \\ & =\sum_{x \in \mathcal{X}} \bar{p}(x) f(x) \\ & =\sum_{x \in \mathcal{X}} Z p(x) f(x) \\ & =Z \sum_{x \in \mathcal{X}} p(x) f(x) \\ & =Z \underset{x \sim p}{\mathbb{E}}[f(x)] \end{aligned} ⟨x,w⟩∼QS-RAVI E[wf(x)]=⟨r,x⟩∼q,s∼j(⋅;r,x)E[q(r,x)j(s;r,x)pˉ(x)h(s,r;x)f(x)]=r∈R∑s∈X∑s∈S∑q(r,x)j(s;r,x)q(r,x)j(s;r,x)pˉ(x)h(s,r;x)f(x)=r∈R∑s∈X∑s∈S∑pˉ(x)h(s,r;x)f(x)=x∈X∑pˉ(x)f(x)r∈R∑s∈S∑h(s,r;x)=x∈X∑pˉ(x)f(x)r∈R∑h(r;x)=x∈X∑pˉ(x)f(x)=x∈X∑Zp(x)f(x)=Zx∈X∑p(x)f(x)=Zx∼pE[f(x)]
[定义5]
[期望的定义]
[消去;绝对连续]
[重新排列]
[边缘化
s
s
s]
[
h
(
⋅
;
x
)
h(\cdot ; x)
h(⋅;x) 是一个分布]
[
p
p
p 的定义]
[重新排列]
[期望的定义]
B. 5 RAVI 直觉用于定义1 (WRS)
在RAVI框架的背景下,WRS可以理解为代表在抽样过程中生成的被拒绝样本作为辅助变量。辅助空间
R
=
∪
i
∈
N
X
i
\mathcal{R}=\cup_{i \in \mathbb{N}} \mathcal{X}^{i}
R=∪i∈NXi由在获得接受样本之前被拒绝的有限样本列表组成。提议
q
q
q生成拒绝抽样的轨迹,而元提议
h
h
h生成
L
L
L个额外的拒绝循环以改进我们对辅助变量的推理。最后,元-元提议
j
j
j考虑由
h
h
h引入的额外辅助变量。
直观上,随着
L
L
L的增加,我们获得了接受概率
Z
Z
Z的更好估计,导致重要性权重的方差降低。当
L
→
∞
L \rightarrow \infty
L→∞时,元提议
h
(
r
;
x
)
h(r ; x)
h(r;x)收敛到其最优分布
q
(
r
∣
x
)
q(r \mid x)
q(r∣x),并且元-元提议
j
(
s
;
r
,
x
)
j(s ; r, x)
j(s;r,x)收敛到其最优分布
h
(
s
∣
r
;
x
)
h(s \mid r ; x)
h(s∣r;x)。
B. 6 RAVI直觉用于定义2 (AWRS)
在RAVI框架的背景下,AWRS代表一种修改,其中提议、元提议和元-元提议中的抽样程序都保留了先前被拒绝样本的记忆。抽样分布不断在每次拒绝后重新归一化,以考虑移除的概率质量。这种适应需要不同的权重计算,考虑到在整个抽样过程中变化的概率分布。
C 第3.1节(WRS)的证明
首先,我们将使用RAVI推导WRS算法的正确权重。
命题7.
Q
W
R
S
Q_{W R S}
QWRS对于
p
⃗
\vec{p}
p是正确加权的。
证明。我们将使用来自Def. 5的两级RAVI框架来证明这一点。
参考论文:https://arxiv.org/pdf/2504.05410


















 4030
4030

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











