






Yangyang Zhuang
1
{ }^{1}
1, Wenjia Jiang
1
,
2
{ }^{1,2}
1,2, Jiayu Zhang
3
,
4
{ }^{3,4}
3,4, Ze Yang
5
{ }^{5}
5 Joey Tianyi Zhou
6
,
7
{ }^{6,7}
6,7 Chi Zhang
1
{ }^{1}
1,
1
{ }^{1}
1 西湖大学 AGI 实验室,
2
{ }^{2}
2 河南大学,
3
{ }^{3}
3 徐州医科大学附属医院
4
{ }^{4}
4 徐州医科大学
5
{ }^{5}
5 南洋理工大学
6
{ }^{6}
6 新加坡科技研究局高性能计算研究所
7
{ }^{7}
7 新加坡科技研究局 CFAR 研究所 yyzhuang0211@gmail.com chizhang@westlake.edu.cn,
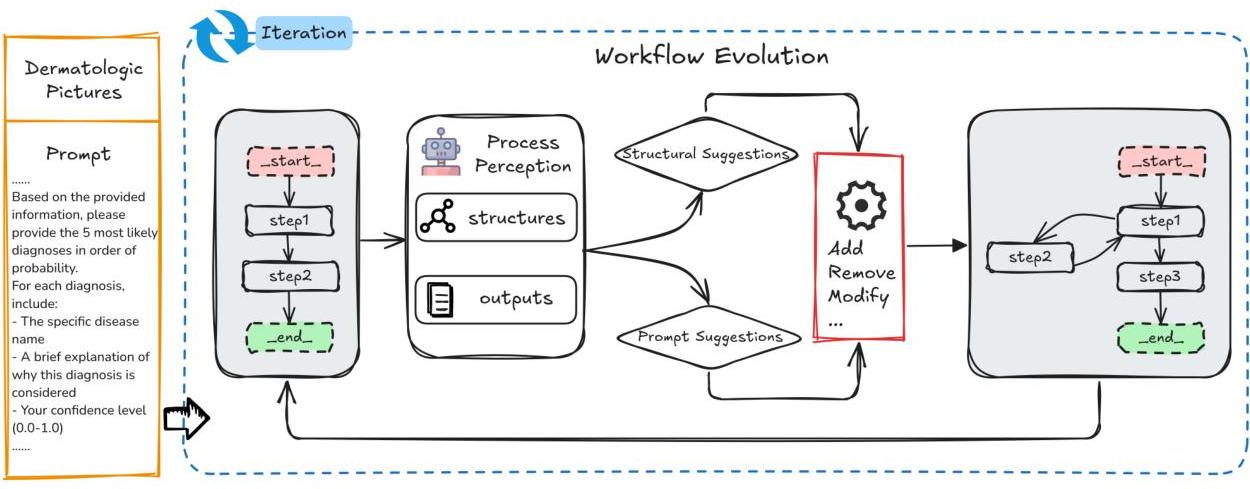
图1:工作流演化图。此图展示了一个迭代框架,用于医学诊断任务中的工作流演化。从指定诊断要求的结构化输入提示开始,系统进行过程感知以分析当前工作流的结构和输出行为。基于此分析,生成结构和提示级别的建议以指导工作流改进。这些建议导致了可操作的修改(例如,添加、删除),随后通过迭代过程将这些修改整合到工作流中。通过反复迭代,工作流逐步优化以提高诊断准确性、逻辑连贯性以及与任务目标的一致性。
摘要
基于大型语言模型(LLM)的代理在广泛的任务中展示了强大的能力,其在医疗领域的应用因其对高泛化能力和跨学科知识依赖的需求而具有特别的前景。然而,现有的医疗代理系统通常依赖于静态的手工设计的工作流,缺乏适应多样化诊断需求和新兴临床场景的能力。受到自动化机器学习(AutoML)成功的启发,本文介绍了一种新的自动设计医疗代理架构的框架。具体来说,我们定义了一个分层且富有表现力的代理搜索空间,该空间通过节点级、结构级和框架级的结构化修改实现动态工作流适应。我们的框架将医疗代理概念化为基于图的架构,由多样化的功能性节点类型组成,并支持通过诊断反馈引导的迭代自我改进。
实验结果表明,在皮肤病诊断任务中,所提出的方法有效地演化了工作流结构,并显著提高了随时间推移的诊断准确性。这项工作代表了第一个完全自动化的医疗代理架构设计框架,为在真实世界的临床环境中部署智能代理提供了可扩展和适应性强的基础。
1 引言
大型语言模型(LLMs)在解决广泛的任务方面展现了非凡的能力。利用这些模型,基于LLM的代理正在越来越多地改变各种领域中任务的执行方式,如自动化、生物学和教育。这些代理高度适应,能够从先前的经验中学习,并随着时间的推移不断改进其行为。
LLM代理的一个特别有前景的应用是在医疗保健领域。医疗领域需要高精度、效率和
可扩展性——这些特性与智能代理的优势非常吻合。在这种情况下,基于LLM的代理不仅作为辅助工具,还开始在关键过程中扮演重要角色,如诊断、医疗数据分析和治疗推荐。通过减轻医疗专业人员的负担并改善临床结果,这些代理为现代医疗系统带来了显著的价值。
在各种代理系统设计中,多代理系统非常适合复杂的医疗工作流。医学影像和诊断任务通常涉及多个跨学科部门,因此协调和协作至关重要。在这种背景下,多代理系统可以高效地将任务分配给相应的专业化代理,同时保持整体决策的一致性。它们还有助于弥合部门之间的沟通差距,并使机构间的标准化程序成为可能。
然而,当前的多代理系统在工作流设计上面临一个关键限制,即依赖于由领域专家定制的静态手工架构。尽管在有限的情况下有效,这些固定的工作流缺乏适应新诊断技术和成像模式的能力,需要耗费时间的重新设计。此外,对于每个新任务或应用场景,开发人员都需要从头创建定制的工作流,这限制了可扩展性并减慢了部署速度。
为了解决上述挑战,我们从自动化机器学习(AutoML)领域,特别是神经架构搜索(NAS)中汲取灵感,探索医疗代理的自动化架构设计。NAS已经在自主发现各种任务中高性能神经架构方面证明了其有效性。类似地,我们认为代理架构的自动设计可以增强多代理系统在动态临床环境中的适应能力。
为此,我们将代理系统概念化为基于图的动态工作流,该工作流根据大型语言模型(LLMs)的反馈进行演化。为了促进有效的工作流演化,我们定义了一个包含所有有效演化操作的综合搜索空间。这些操作分为三个级别:节点级、结构级和框架级。节点级操作包括添加或删除节点以及修改单个节点内的属性。为了
启用更复杂的推理,结构级操作引入了诸如条件决策、迭代循环和平行执行等机制,从而丰富了逻辑工作流并增强了诊断能力。在更高的抽象层次上,框架级操作结合了先进的范式,如思维链(Wei et al., 2022)、反思(Shinn et al., 2023)和圆桌讨论(Chen et al., 2024b),进一步提高了系统的推理和协调能力。
在定义演化操作后,我们首先建立了一个仅包含单个节点的简单前馈工作流,以与LLM交互并获取诊断结果。如图1所示,当诊断错误发生时,代理系统可以识别根本原因,并为工作流演化提供结构和提示建议。随着更多案例的处理,工作流经历迭代细化,逐步纳入新节点、结构逻辑和框架级推理策略。随着时间的推移,这导致了一个更准确、稳健和高效的诊断系统的出现。这种持续演化策略使代理系统具备了应对不断变化的真实世界复杂性的自我改进能力。
为了验证我们方法的有效性,我们在两个医学诊断基准上进行了全面的实验。结果表明,我们的方法可以自动生成更高效和准确的代理架构,显著优于强基线。
我们的主要贡献如下:
- 我们提出了第一个使用LLM完全自动化设计医疗多代理系统的框架。
-
- 我们引入了一个新颖的分层搜索空间,专为动态代理工作流演化量身定制。
-
- 我们开发了一种自我改进的架构搜索算法,使代理能够通过诊断反馈优化其工作流。
2 相关工作
2.1 医疗领域中的LLM代理
近年来,大型语言模型(LLMs)的推理能力显著提高(Chen et al., 2025),这导致它们越来越多地被集成到医疗领域,以提高诊断准确性和治疗效果(Hager et al., 2024;Schmidgall et al., 2024;Singhal et al., 2023)。例如,Agent Hospital(Li et al., 2025)利用情景模拟来提高代理的医学知识和诊断准确性,提供虚拟环境进行训练和评估。基于类似原则,SkinGPT-4(Zhou et al., 2024)将视觉-语言模型应用于皮肤科诊断的改进,结合视觉和文本数据以获得精确结果。同时,MMedAgent(Li et al., 2024)集成了工具链以支持多模态任务执行,在各种医疗应用中表现出稳健性能。此外,一些工作(Kim et al., 2024;Li et al., 2023)专注于多代理协作,以提高复杂医疗工作流的效率。然而,尽管在特定任务性能上有优势,当前系统对动态工作流的关注有限,这对于适应现实世界医疗环境的复杂性和多样性至关重要。
2.2 代理协作与自我改进
最近的研究强调了基于大型语言模型(LLMs)的多代理系统(MAS)中代理协作和自我改进日益增长的重要性。常见的架构包括点对点设置、集中控制器和分层框架(Chen et al., 2023;Tran et al., 2025)。协作和自我改进的MAS在不同的应用领域显示出潜力,如MetaGPT(Hong et al., 2024)、LLMBlender(Jiang et al., 2023)和多代理辩论(Liang et al., 2024)。除了这些领域,最近的工作还集中在通过探索自我演化机制来增强开放场景中的适应能力:EvoMAC(Hu et al., 2024)通过文本反向传播引入了用于软件级开发任务的自我演化协作网络。AutoAgents(Chen et al., 2024a)支持自动代理生成和灵活协作。AFLOW(Zhang et al., 2025)使用图搜索优化任务执行路径。
3 方法论
我们提出了一种动态框架,利用大型语言模型优化医疗工作流。在我们的方法中,工作流被表示为
基于图的结构,其中包含异构节点类型,每个节点都具有特定的属性和功能角色。我们首先介绍了医疗工作流的基于图的表示,其中每个节点封装了一个具有语义和程序特性的独立操作。然后详细说明这些节点组合如何定义一个结构化和受约束的搜索空间,有效地捕捉了有效工作流配置的范围。最后,我们展示了工作流演进过程,以实现工作流设计和性能的持续改进。
3.1 工作流节点定义
在本节中,我们定义了医疗工作流及其基础组件的概念,这些组件共同构成了所提议框架内动态任务执行的基础。工作流被建模为一系列相互连接的节点,分为基本类型和工具类型。基本节点直接与LLM交互,基于提供的提示生成单一结果。相比之下,工具节点利用LLM可访问的预定义工具,重点在于支持工作流演进。为简化起见,仅引入一个工具,即图像搜索工具。此工具接受图像作为输入,并返回最相似的前k个疾病标签及其相似度评分,这些评分作为LLM诊断参考。
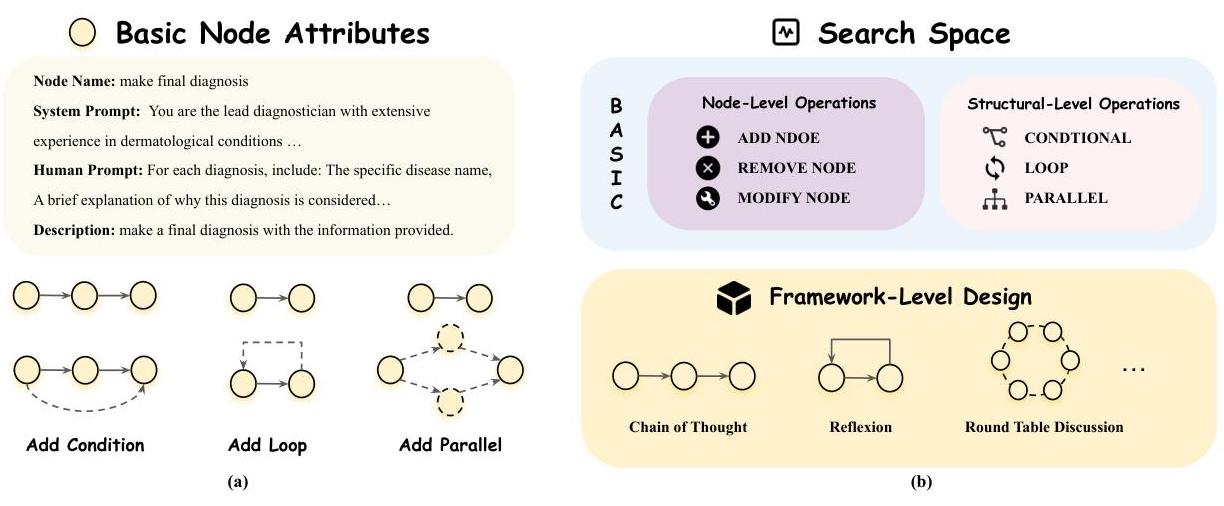
基本节点是其他结构演变的基础;例如,图2(a)显示,一个基本节点与循环条件结合转变为循环节点,而带条件分支的基本节点则变为条件节点。多个并发运行的基本节点创建了并行结构。每种结构类型都在促进复杂医疗工作流的灵活高效执行中发挥着独特作用。对于基本节点类型,以下关键属性包括:
- 系统提示:定义节点内代理的角色或身份。
-
- 人类提示:指定代理执行指定任务的指令。
-
- 描述:提供节点功能或目的的简明解释。
对于我们的工具节点类型,以下关键属性包括:
- 描述:提供节点功能或目的的简明解释。
图2:节点属性和分层搜索空间的插图。(a)展示了基本节点的属性及其如何演变为复杂的工作流结构,如条件分支、循环和平行执行。每个基本节点包含可配置参数,包括系统提示、人类提示、描述和可选的图像路径。这些属性允许代理在工作流中执行特定的医疗诊断任务。(b)展示了用于动态工作流设计的拟议分层搜索空间,包括节点级、结构级和框架级操作。这些操作实现了细粒度节点操作、控制流结构(例如条件、循环、并行)和高级别推理模式(如思维链、反思和圆桌讨论)的出现。
- 工具名称:节点将使用的工具名称。
-
- 描述:提供节点功能或目的的简明解释。
3.2 搜索空间
为了促进系统的工作流演化,我们提出了一种分层且富有表现力的搜索空间,该空间定义了代理在节点级、结构级和框架级操作上的可行动策略,从而实现对工作流架构和任务特定参数的精确调整。
节点级操作。节点级操作专注于修改单个工作流组件以优化功能和简化执行。
-
添加:向工作流中引入新节点,可以是基本功能节点或集成了特定功能的工具节点。通过添加节点,工作流可以容纳额外的功能,增强问题解决能力。
-
- 删除:消除不必要的或冗余的节点以提高工作流效率。删除节点有助于简化执行路径,从而得到更简洁和针对性的过程。
-
- 修改:调整现有节点的提示配置。这使得能够对节点行为进行精细控制,以更好地满足任务需求。
结构级操作。结构操作允许修改和扩展总体工作流逻辑,解决分支、反馈循环和并行执行路径。
- 修改:调整现有节点的提示配置。这使得能够对节点行为进行精细控制,以更好地满足任务需求。
-
条件结构:条件分支根据指定标准重定向工作流执行,为定制任务处理创建动态路径。这通过允许基于决策逻辑和运行时条件的不同路径增加了工作流的灵活性和适应性。
-
- 循环结构:反馈循环允许在特定条件下迭代节点执行,支持需要重复评估或精炼的任务。适当的循环设计优化了迭代过程,包括条件阈值、迭代限制和反馈路径。
-
- 并行结构:并行执行路径允许多代理同时分析,提高计算效率并促进协作工作流。这些结构特别有益于可以
-
将任务划分为可独立处理的子任务的情况,从而减少总执行时间。在需要高吞吐量、涉及大数据集或需要同时执行独立过程的情况下,并行结构大有裨益。此外,并行执行允许不同代理独立表达观点而不受他人影响,促进无偏见的贡献。一旦所有代理分享了他们的观点,他们就可以继续整合和考虑彼此的见解,从而得出更全面和协作的结果。
框架级设计。搜索空间隐含地包括高层次的概念性工作流模式——如圆桌讨论——作为抽象模板。这些模式不是预先定义为固定模块,而是通过在搜索过程中组合低级节点和结构操作动态出现,如图2所示。例如,可以通过编排一组互连节点在一个循环结构中模拟圆桌讨论的行为。这种设计允许框架通过合成可重用的原始元素以目标驱动的方式灵活构建复杂的任务特定工作流。 -
反思框架:该框架侧重于通过反思思考进行迭代自我评估和知识提炼,以提升问题解决能力。促进持续评估和学习使代理能够随着时间的推移适应和改进,从而做出更明智的决策。
-
- 协作框架:通过允许来自不同领域的专家同时工作,该框架增强了应对复杂问题的能力,提供更好的解决方案。
-
- 思维链推理:它将复杂任务分解为顺序、模块化的步骤,允许在每个阶段进行详细分析。通过系统地解决每个组成部分,它增强了整体执行过程的准确性和彻底性。
-
- 圆桌讨论框架:多个代理围绕共同任务或主题协作和商讨,以实现更高效或准确的解决方案。每个代理可能采用不同的模型或算法,并与其他代理共享信息,类似于圆桌会议,以整合多样见解并优化最终结果。
-
- 分析合并讨论(CMD)框架:具有投票机制的并行分析组,用于共识驱动的决策。
3.3 工作流演进
我们提出的流程演化过程是一个连续的迭代周期。最初,大型语言模型对工作流执行进行诊断分析,以识别潜在问题,并将其分类为各种错误情况。收集和分析这些错误的原因以生成改进建议。然后将这些建议转化为可操作的工作流修改,确保符合要求以实现有针对性的改进。更新的工作流经过验证后进行更新,随后进入下一诊断阶段继续迭代。这一诊断、收集原因、分析、接收建议、验证和更新的过程确保了工作流在结构和执行性能方面的持续细化和优化。
首先,LLM专注于诊断工作流错误,它汇总了所有工作流节点的输出并将错误分为两类主要类别。图像理解错误:由于特征识别或提取不准确而导致的问题,这会损害诊断决策的准确性。诊断决策错误:即使图像特征正确识别,由于推理缺陷或错误决策导致的错误。然后,LLM追溯这些错误的根本原因,确定它们是源于图像特征识别不准确还是诊断推理不足。在此过程中保留与问题节点相关的关键数据,以便进行更深入的分析以揭示诊断不准确的根源。
基于这一分析,系统继续分析工作流的逻辑结构并从其组件中提取详细的描述性元数据。这一过程由大型语言模型的视觉感知能力推动,
生成工作流的结构化、基于图的表示。生成的表示提供了工作流架构的视觉和逻辑概览,清晰地展示了组件之间的相互连接和依赖关系。使用Mermaid可视化工作流,允许直接查看生成流程图中的循环条件和条件分支。这种结构表示使系统能够准确识别节点之间的关系,并理解它们在整个过程中履行的具体功能角色。通过将这种结构理解与关键问题分析相结合,LLM可以提供更有针对性和更有效的改进建议。
接下来,这些建议经过过滤过程以消除不切实际的提案,例如那些需要超出智能代理能力范围的外部输入的提案。剩余的建议进一步分为两组:结构建议:旨在优化整个工作流架构和结构依赖关系的建议。提示建议:专注于细化任务特定配置(如提示模板)以提高节点性能的建议。
最后,这些过滤后的建议经过细化并整合到工作流中,以支持有效的演进和优化。最初,这些建议被重新制定为可操作的更新,并以JSON格式标准化返回。结构建议主要旨在改进工作流的整体架构。由于它们对底层结构的潜在影响,这些建议必须经过严格的验证过程。这一步骤对于确保不会引入无效或不适当的搜索空间中的动作至关重要,因为这些动作可能会破坏或损害现有工作流设计的完整性。一旦验证通过,它们就被应用以优化工作流的架构和执行流程。另一方面,提示建议直接修改任务特定配置,如提示模板,并无缝应用,无需额外的验证步骤。通过系统地细化和整合这些建议,工作流迭代演进,实现结构和诊断性能的持续改进。
通过验证和整合,框架系统地融入改进
同时防止引入可能扰乱工作流结构的低效或错误动作。这种细化机制确保每个验证过的结构建议和提示修改都能对工作流功能产生有意义的提升,从而实现持续和有针对性的优化。
整个过程——从诊断和错误分析到工作流更新——可以被视为一个进化周期。在每次迭代中,我们运行多个示例,然后细化工作流以生成更新版本。这一过程不断重复,直到最终工作流在验证集上的准确性收敛,标志着进化的完成。
4 实验
4.1 实验设置
数据集。为了评估我们所提框架的有效性,我们选择皮肤病诊断任务作为主要测试平台。这个领域特别适合评估多代理架构,因为它固有的复杂性:准确的诊断通常需要跨学科的知识和一个多步骤的推理过程,涉及对皮肤病变的视觉检查、患者历史和症状-诊断相关性。我们使用了两个皮肤病学数据集来评估工作流演化:
SKIN Concepts 数据集。SKINCON(Daneshjou 等人,2023)基于Fitzpatrick 17k皮肤病数据集(Groh 等人,2022,2021),包括3230张带有48个临床相关概念注释的图像,如“斑块”、“鳞屑”和“侵蚀”。这些注释涵盖了113种皮肤病类型,并基于皮肤科医生使用的既定临床词汇,确保其在多种疾病过程中的适用性。
增强型皮肤状况图像数据集。皮肤状况(Naqvi,2023)包含总共2394张增强图像,涵盖六种不同的皮肤病况,每个类别包含399张图像。这种平衡结构使其非常适合训练机器学习模型,特别是在医学图像分析领域。
数据处理。在初步数据准备期间,我们识别出数据集中描绘位于私人或敏感身体部位的皮肤状况的图像子集。由于内容调节限制,这些图像被LLM拒绝,无法在
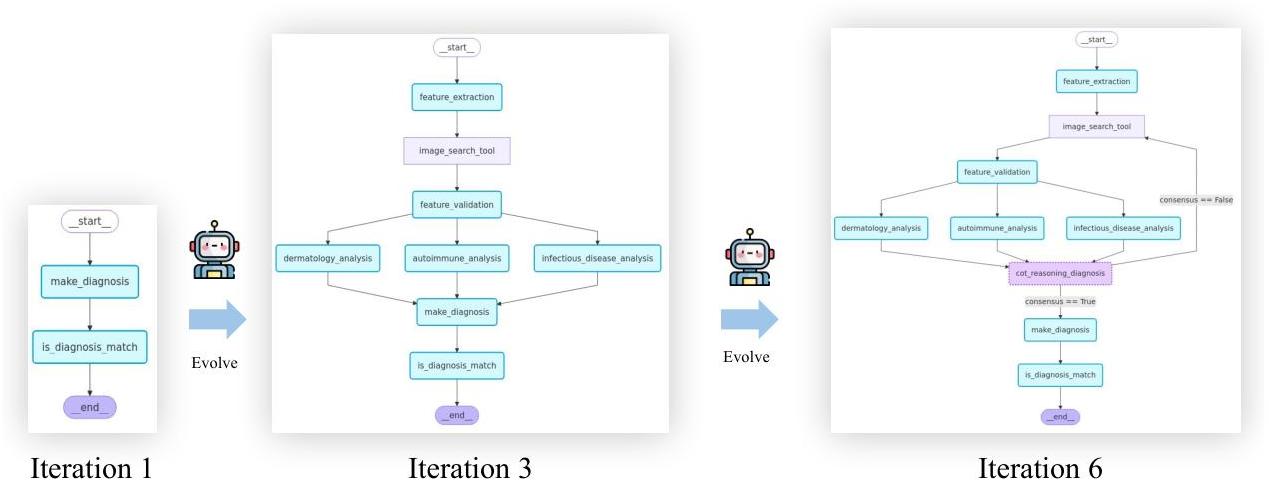
图3:迭代中的工作流演化。我们可视化了诊断工作流在三个关键阶段的状态:初始状态(迭代0)、部分细化后的中间状态(迭代3)和最终演化的工作流(迭代6)。演化过程展示了系统通过添加条件分支、并行推理路径和特定错误循环如何逐步改进其结构。这些结构性改进通过迭代自我适应实现了更准确和稳健的诊断推理。
工作流执行过程中进行处理。此外,我们遇到了另一个问题,大约20张图像的URL链接损坏,无法下载。为了维护实验的完整性并确保所有代理架构的一致、可靠评估,我们从数据集中排除了这些样本。
数据集划分:SKIN Concepts 数据集:训练集和验证集各包含50张随机采样的图像,测试集包含224张图像,确保所有疾病类型都有每类两张图像的代表性。SKIN Conditions 数据集:训练集和验证集各有50张图像;测试集包含120张图像,每种病况20张。
实施细节。我们实施了一个包含训练、验证和测试阶段的实验过程。
在每次训练批次之后,进化机制调整工作流结构。然后在单独的数据集上验证模型性能。这一训练和进化周期重复进行,直到训练完成,随后对测试集进行最终评估。
我们的框架基于LangGraph(Inc., 2023)。LangGraph为我们提供了一些预包装的内容,我们只需要在LangGraph的基础上开发我们的节点设计。此外,我们提供了一个工具列表,您可以在其中添加自定义工具。在工具列表中,我们已经定义了
用于查找相似图像的图像搜索工具。图像搜索工具利用预训练的CLIP(ViTL/14)(Radford et al., 2021)模型从不属于训练、验证和测试集的数据中提取特征向量,而无需进一步微调,将这些向量存储在Pinecone(Pinecone Systems, 2023)数据库中。当使用图像工具搜索相似图像时,可以直接匹配存储在此数据库中的特征向量。
基线。为了建立比较框架以评估我们工作流演化方法的有效性,我们实施了两种基线方法进行基于图像的皮肤病诊断。第一种基线利用GPT-4o作为单代理模型直接诊断输入图像,没有任何中间推理或工作流调整。这提供了一个简单的基准来评估诊断准确性。
第二种基线增强了GPT-4o,采用了思维链(CoT)提示机制。这种方法引导GPT-4o通过中间步骤推理后再生成最终诊断。尽管CoT相比直接诊断增强了可解释性,但它并未利用自适应或演化的工作流,这是我们所提方法的核心。
第三种基线涉及一种“圆桌”讨论设置,这是一种多代理系统配置。
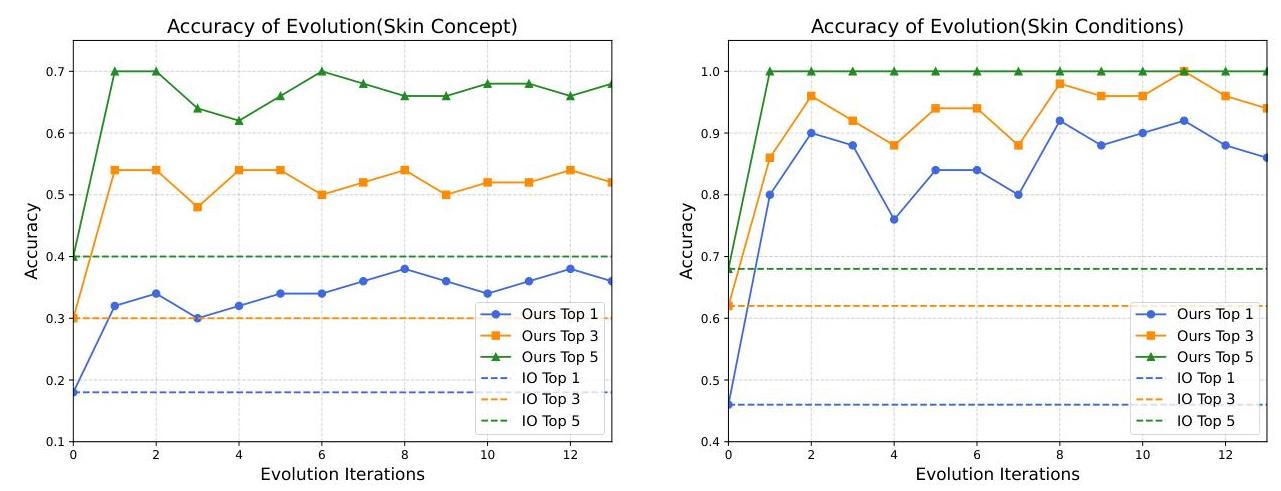
图4:工作流演化迭代中的Top-k诊断准确性。此图展示了工作流在迭代优化过程中Top-k准确性如何提高。每个点代表一轮工作流演化后的诊断性能。上升趋势表明结构改进和提示更新有效提升了诊断能力。曲线最终收敛,表明系统在发现足够优化的工作流后趋于稳定。图中的结果使用GPT-4o获得。
系统配置。在这种方法中,多个代理围绕共同任务或主题协作和商讨,以实现更高效或准确的解决方案。每个代理可能采用不同的模型或算法,并与其他代理共享信息,类似于圆桌会议,以整合多样见解并优化最终结果。
这些基线允许量化工作流演化在泛化能力和诊断性能方面的收益。
评估指标。为了评估诊断模型,我们采用了基于Top-1、Top-3和Top-5预测的准确性指标。每次诊断尝试都会根据模型的置信分数生成排名预测集,并将这些预测的正确性与真实标签进行比较。
在验证阶段,每次进化迭代后测量Top-1、Top-3和Top-5准确性,使我们能够观察这些指标随着工作流的进化如何改进。在测试阶段,使用我们的工作流进化方法获得的最终准确性与基线进行比较,展示了动态和自适应工作流的优势。
遵循(Wang et al., 2023),我们采用了多数投票共识指标,记为cons@64,反映同一类别的多个输入中方法达成一致诊断的频率(
n
=
64
\mathrm{n}=64
n=64)。该指标提供了
在输入变异和采样噪声下模型鲁棒性和可靠性的代理。
这些指标使我们能够量化工作流进化过程中准确性的进展以及在未见数据上测试时所提方法的整体泛化能力,特别是在多样疾病类别中。
4.2 进化过程分析
进化可视化。如果以文本形式直接将工作流节点输入LLM,LLM可能会轻易忽略循环和条件分支等结构关系。为了更好地理解我们的工作流如何随时间演变,我们在三个代表性阶段可视化结构:初始工作流(迭代0)、中间状态(迭代3)和最终演化工作流(迭代6)。这些可视化揭示了系统如何逐步引入结构改进,如条件分支、并行推理路径和特定错误循环。图3提供了这些阶段的对比视图。
定量分析 为了定量评估我们工作流进化框架的有效性,我们跟踪了多次进化迭代中的诊断性能——通过Top-1 准确性、Top-3 准确性和Top-5 准确性衡量。在每次迭代中,系统基于之前的诊断错误和结构改进完善其工作流,使其推理能力逐步提升。
| LLM | 方法 | 皮肤概念准确性 (%) | 皮肤状况准确性 (%) | ||||
|---|---|---|---|---|---|---|---|
| Top-1 | Top-3 | Top-5 | Top-1 | Top-3 | Top-5 | ||
| GPT-4o | IO | 20.27 | 30.63 | 36.04 | 50.83 | 78.33 | 86.67 |
| CoT (Wei et al., 2022) | 18.47 | 28.83 | 33.78 | 55.83 | 76.67 | 82.50 | |
| 圆桌会议 (Chen et al., 2024b) | 21.17 | 27.93 | 32.43 | 45.83 | 75.83 | 80.83 | |
| 我们的 | 29.28 | 40.09 | 50.45 | 90.83 | 95.00 | 100.00 | |
| GPT-4o-mini | IO | 11.71 | 20.72 | 23.87 | 27.50 | 69.17 | 80.83 |
| CoT (Wei et al., 2022) | 6.31 | 15.32 | 24.32 | 22.50 | 65.00 | 84.17 | |
| 圆桌会议 (Chen et al., 2024b) | 10.81 | 19.82 | 23.42 | 25.83 | 70.00 | 78.33 | |
| 我们的 | 13.51 | 21.62 | 24.77 | 45.83 | 74.17 | 85.83 |
表1:使用GPT-4o和GPT-4o-mini在皮肤概念和皮肤状况上的Top-k诊断准确性(%)。更高值表示更好性能。
| 操作 | Top-1 准确性 (%) | Top-3 准确性 (%) | Top-5 准确性 (%) |
|---|---|---|---|
| 添加工具节点 | 21.62 ( − 7.66 ) 21.62(-7.66) 21.62(−7.66) | 30.18 ( − 9.91 ) 30.18(-9.91) 30.18(−9.91) | 36.94 ( − 13.51 ) 36.94(-13.51) 36.94(−13.51) |
| 修改节点提示 | 19.37 ( − 9.91 ) 19.37(-9.91) 19.37(−9.91) | 27.93 ( − 12.16 ) 27.93(-12.16) 27.93(−12.16) | 33.78 ( − 16.67 ) 33.78(-16.67) 33.78(−16.67) |
| 删除节点 | 28.83 ( − 0.45 ) 28.83(-0.45) 28.83(−0.45) | 41.44 ( + 1.35 ) 41.44(+1.35) 41.44(+1.35) | 50.90 ( − 0.45 ) 50.90(-0.45) 50.90(−0.45) |
表2:不同操作的消融结果。每一行显示在禁用特定操作时的Top-1、Top-3和Top-5准确性。括号中的值表示与完整模型Top-1(29.28 %)、Top-3(40.09 %)和Top-5(50.45 %)相比的准确性下降。
图4展示了工作流演化过程中Top-1准确性、Top-3准确性和Top-5准确性的变化。直线代表直接将图像输入LLM进行诊断的准确性。可以看出,演化工作流的准确性始终高于IO线。我们在早期迭代中观察到一致的上升趋势,表明工作流结构和提示配置的改进提高了诊断性能。准确性最终收敛,表明系统已达到稳定且有效的工作流配置。这种模式展示了框架从经验中学习并随时间自我优化的能力。
此外,在皮肤概念数据集中,训练集和验证集各包含50张随机选择的图像,而测试集包含所有类别的图像。我们的工作流在训练集上迭代演化,并在验证集上进行验证。最终,它在包含所有类别的测试集上取得了良好的结果。这展示了我们演化工作流的泛化能力。
4.3 性能比较结果
诊断准确性比较。为了全面评估我们的方法在皮肤病诊断任务中的有效性,我们比较了多个最先进的大型语言模型(LLMs)中的各种提示策略。具体来说,我们报告了使用GPT-4o和GPT-4o-mini在皮肤概念和皮肤状况上的Top-k诊断准确性。如表1所示,我们的方法始终优于现有基线,包括IO、CoT(Wei et al., 2022)和圆桌会议(Chen et al., 2024b),在所有LLMs和评估指标上均取得优越结果。如图1所示,我们的方法在Top-k准确性上取得了显著提升,突显了其卓越的诊断能力和不同模型间的鲁棒性。
工作流稳定性。除了诊断准确性和结构适应性外,我们还通过评估它们在多个独立样本上的共识行为来评估演化工作流的稳定性。我们报告了在皮肤概念数据集上使用GPT-4o模型的每类共识准确性(cons@64),如图5所示。我们的方法在广泛的条件下始终获得更高的共识得分,包括常见疾病(如湿疹、银屑病)和罕见或视觉复杂的疾病(如脓疱疮、酒渣鼻)。这不仅展示了演化工作流的整体鲁棒性,还展示了其细粒度可靠性。
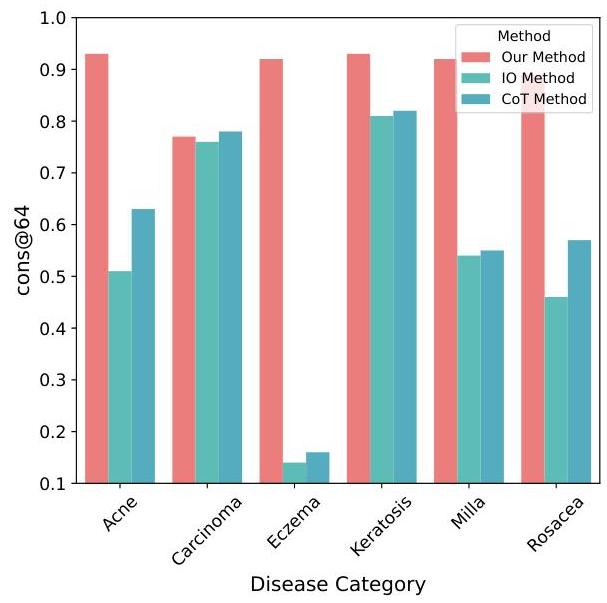
图5:不同方法的每疾病共识准确性(cons@64)。此图展示了在六种不同疾病类别下,每种方法的预测稳定性,通过每类64个样本的多数投票共识评估。我们的方法始终获得更高的cons@64得分,表明在病例间诊断鲁棒性和类内一致性方面的改进。
4.4 组件消融分析
我们进行了一项全面的消融研究,以调查不同工作流修改操作在我们进化框架中的作用。具体来说,我们将所有操作分为三类:添加、修改和删除。每个类别涵盖了一系列针对节点或结构组件(如条件、循环、并行)的细粒度操作。
在这项研究中,我们进行了消融实验以评估不同操作对工作流有效性的影响。具体来说,我们从可能的操作集合中选择了三个关键操作:添加工具节点、修改节点提示和删除节点。首先,添加工具节点的操作旨在获取关于相似图像的信息。为了评估这一操作的必要性,我们将其从搜索空间中移除并观察性能变化。同样,我们也对修改节点提示和删除节点的操作进行了相同处理,将它们从搜索空间中排除,以分析每个操作对整体系统性能和有效性的影响。这些实验将帮助我们理解每个操作在工作流优化中的作用和重要性。
为了评估它们各自的贡献,我们一次禁用一个特定操作,并检查在皮肤概念数据集上的Top-1诊断准确性。结果总结在表2中,揭示了每个操作在实现有效性能改进中的相对重要性。一方面,值得注意的是,与添加工具节点和提示修改相关的操作对性能产生了特别强烈的影响,突显了它们在工作流适应性和优化中的重要性。另一方面,我们可以看到删除节点对准确性没有显著影响。然而,在实践中,拥有太多功能相似的节点可能会降低工作流的执行效率。
5 结论
目前专注于皮肤病学的多代理系统受到刚性、手动设计的工作流框架的阻碍,这些框架缺乏适应不断变化的诊断需求和多样化要求的能力。为了克服这一局限性,我们提出了一种节点级进化框架,通过自主探索和发展可行的工作流引入灵活性。通过在节点级别实现动态进化,我们的框架允许工作流有机地适应,从而有效地响应变化条件和复杂的诊断场景。这种方法通过支持模块化更新、结构调整和并行处理,同时自主优化工作流路径,显著增强了灵活性。因此,我们的框架为提高皮肤病学多代理系统中的诊断准确性、操作效率和响应能力提供了一个可扩展和适应性强的解决方案。
参考文献
Guangyao Chen, Siwei Dong, Yu Shu, Ge Zhang, Jaward Sesay, Börje F. Karlsson, Jie Fu, and Yemin Shi. 2024a. Autoagents: A framework for automatic agent generation. Preprint, arXiv:2309.17288.
Justin Chen, Swarnadeep Saha, and Mohit Bansal. 2024b. ReConcile: Round-table conference improves reasoning via consensus among diverse LLMs. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7066-7085, Bangkok, Thailand. Association for Computational Linguistics.
Shuaihang Chen, Yuanxing Liu, Wei Han, Weinan Zhang, and Ting Liu. 2025. A survey on llm-based multi-agent system: Recent advances and new frontiers in application. Preprint, arXiv:2412.17481.
Weize Chen, Yusheng Su, Jingwei Zuo, Cheng Yang, Chenfei Yuan, Chi-Min Chan, Heyang Yu, Yaxi Lu, Yi-Hsin Hung, Chen Qian, Yujia Qin, Xin Cong, Ruobing Xie, Zhiyuan Liu, Maosong Sun, and Jie Zhou. 2023. Agentverse: Facilitating multiagent collaboration and exploring emergent behaviors. Preprint, arXiv:2308.10848.
Roxana Daneshjou, Mert Yuksekgonul, Zhuo Ran Cai, Roberto Novoa, and James Zou. 2023. Skincon: A skin disease dataset densely annotated by domain experts for fine-grained model debugging and analysis. Preprint, arXiv:2302.00785.
Matthew Groh, Caleb Harris, Roxana Daneshjou, Omar Badri, and Arash Koochek. 2022. Towards transparency in dermatology image datasets with skin tone annotations by experts, crowds, and an algorithm. Proceedings of the ACM on Human-Computer Interaction, 6(CSCW2):1-26.
Matthew Groh, Caleb Harris, Luis Soenksen, Felix Lau, Rachel Han, Aerin Kim, Arash Koochek, and Omar Badri. 2021. Evaluating deep neural networks trained on clinical images in dermatology with the fitzpatrick 17k dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1820-1828.
Paul Hager, Friederike Jungmann, Robbie Holland, Kunal Bhagat, Inga Hubrecht, Manuel M Knauer, Jakob Vielhauer, Marcus Makowski, Rickmer F Braren, Georgios Kaissis, and Daniel Rueckert. 2024. Evaluation and mitigation of the limitations of large language models in clinical decision-making. Nature Medicine, 30:2613 - 2622.
Sirui Hong, Mingchen Zhuge, Jiaqi Chen, Xiawu Zheng, Yuheng Cheng, Ceyao Zhang, Jinlin Wang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber. 2024. Metagpt: Meta programming for a multi-agent collaborative framework. Preprint, arXiv:2308.00352.
Yue Hu, Yuzhu Cai, Yaxin Du, Xinyu Zhu, Xiangrui Liu, Zijie Yu, Yuchen Hou, Shuo Tang, and Siheng Chen. 2024. Self-evolving multi-agent collaboration networks for software development. Preprint, arXiv:2410.16946.
LangChain Inc. 2023. Langgraph.大型语言模型与成对排名和生成融合。预印本,arXiv:2306.02561。
Yubin Kim, Chanwoo Park, Hyewon Jeong, Yik Siu Chan, Xuhai Xu, Daniel McDuff, Hyeonhoon Lee, Marzyeh Ghassemi, Cynthia Breazeal 和 Hae Won Park。2024。MDAgents:用于医疗决策的自适应 LLM 协作。预印本,arXiv:2404.15155。
Binxu Li, Tiankai Yan, Yuanting Pan, Jie Luo, Ruiyang Ji, Jiayuan Ding, Zhe Xu, Shilong Liu, Haoyu Dong, Zihao Lin 和 Yixin Wang。2024。MMedAgent:使用多模态代理学习使用医疗工具。在计算语言学协会发现:EMNLP 2024 的会议记录中,第 8745-8760 页,美国迈阿密。计算语言学协会。
Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Yang, Tristan Naumann, Hoifung Poon 和 Jianfeng Gao。2023。LLaVA-Med:一天内训练一个适用于生物医学的大语言和视觉助手。预印本,arXiv:2306.00890。
Junkai Li, Yunghwei Lai, Weitao Li, Jingyi Ren, Meng Zhang, Xinhui Kang, Siyu Wang, Peng Li, Ya-Qin Zhang, Weizhi Ma 和 Yang Liu。2025。Agent Hospital:一个具有可进化医疗代理的医院模拟器。预印本,arXiv:2405.02957。
Tian Liang, Zhiwei He, Wenxiang Jiao, Xing Wang, Yan Wang, Rui Wang, Yujiu Yang, Shuming Shi 和 Zhaopeng Tu。2024。通过多代理辩论鼓励大型语言模型的发散思维。在 2024 年自然语言处理经验方法会议记录中,第 17889-17904 页,美国迈阿密。计算语言学协会。
Syed Ali Raza Naqvi。2023。增强型皮肤状况图像数据集。Kaggle。
Pinecone Systems Inc. 2023。Pinecone:用于 AI 应用程序的矢量数据库。为可扩展且高效的 AI 应用程序设计的矢量数据库,支持语义搜索、元数据过滤和实时更新。
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger 和 Ilya Sutskever。2021。从自然语言监督中学习可转移的视觉模型。预印本,arXiv:2103.00020。
Samuel Schmidgall, Rojin Ziaei, Carl Harris, Eduardo Reis, Jeffrey Jopling 和 Michael Moor。2024。AgentClinic:一个多模态代理基准来评估模拟临床环境中的 AI。ArXiv,abs/2405.07960。
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan 和 Shunyu Yao。2023。反思:具有语言强化学习的代理。在第 37 届神经信息处理系统国际会议记录中,NIPS '23,纽约州 Red Hook。Curran Associates Inc.
Karan Singhal, Shekoofeh Azizi, Tao Tu, S. Sara Mahdavi, Jason Wei, Hyung Won Chung, Nathan Scales, Ajay Tanwani, Heather Cole-Lewis, Stephen Pfohl, Perry Payne, Martin Seneviratne, Paul Gamble, Chris Kelly, Abubakr Babiker, Nathanael Schaerli,
Aakanksha Chowdhery, Philip Mansfield, Dina Demner-Fushman, Blaise Aguera y Arcas, Dale Webster, Greg S. Corrado, Yossi Matias, Katherine Chou, Juraj Gottweis, Nenad Tomasev, Yun Liu, Alvin Rajkomar, Joelle Barral, Christopher Semturs, Alan Karthikesalingam, and Vivek Natarajan. 2023. 大型语言模型编码临床知识。NATURE, 620(7972):172+。
Khanh-Tung Tran, Dung Dao, Minh-Duong Nguyen, Quoc-Viet Pham, Barry O’Sullivan, and Hoang D. Nguyen. 2025. 多代理协作机制:LLM 调查。预印本,arXiv:2501.06322。
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2023. 自我一致性改进了语言模型中的思维链推理。预印本,arXiv:2203.11171。
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. 2022. 思维链提示激发了大型语言模型中的推理能力。在第 36 届神经信息处理系统国际会议记录中,NIPS '22,纽约州 Red Hook。Curran Associates Inc.
Jiayi Zhang, Jinyu Xiang, Zhaoyang Yu, Fengwei Teng, Xionghui Chen, Jiaqi Chen, Mingchen Zhuge, Xin Cheng, Sirui Hong, Jinlin Wang, Bingnan Zheng, Bang Liu, Yuyu Luo, and Chenglin Wu. 2025. AFLOW:自动化代理工作流生成。预印本,arXiv:2410.10762。
Juexiao Zhou, Xiaonan He, Liyuan Sun, Jiannan Xu, Xiuying Chen, Yuetan Chu, Longxi Zhou, Xingyu Liao, Bin Zhang, Shawn Afvari, and Xin Gao. 2024. 预训练多模态大型语言模型增强了使用 SkinGPT-4 的皮肤病诊断。NATURE COMMUNICATIONS, 15(1)。
参考论文:https://arxiv.org/pdf/2504.11301



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











