






金东民,金泽浩*,国吉康男*
信息科学与技术研究生院
东京大学
东京,日本
{d-kim,kanazawa,kuniyosh}@isi.imi.i.u-tokyo.ac.jp
吉田直人
情报学研究科
京都大学
京都,日本
yoshida.naoto.8x@kyoto-u.ac.jp
摘要
即使没有外部奖励标准,婴儿经常表现出目标导向的行为,例如伸手去触碰感官刺激。这些由内在动机驱动的行为促进了早期发育阶段对身体和环境的自发探索和学习。尽管计算建模可以为这些行为背后的机制提供洞察,但许多关于内在动机的研究主要集中在探索如何获取外部奖励。在本文中,我们提出了一种新的密度模型,称为“自我先验”,用于代理人的多模态感官体验,并研究它是否能自主诱导目标导向行为。在基于自由能原理的主动推理框架内集成自我先验,从一个内在过程生成行为参考,该过程最小化平均过去感官体验与当前观察之间的不匹配。这种机制也类似于通过与环境的持续互动获取和利用身体图式的过程。我们在模拟环境中检验了这种方法,并确认代理自发地伸手向触觉刺激。我们的研究表明,代理通过自身的感官体验塑造内在动机行为,展示了早期发育过程中有意行为的自发涌现。
研究亮点
- 提出了一种早期有意行为的计算模型,将身体图式的形成和目标导向行动整合到自由能原理下。
-
- 引入了自我先验作为内部密度模型,无需外部奖励即可驱动目标导向行为的出现。
-
- 通过最小化观察到的多模态感官输入与经验性获得的自我先验之间的不匹配,证明了自发伸手触碰贴纸的现象。
- 共同通讯作者:金泽浩,国吉康男
代码可在 https://github.com/kim135797531/self-prior 获取。
1 引言
婴儿自发地表现出目标导向行为,例如伸手触碰感官刺激或积极探索周围环境,即使在缺乏生存所需的外部奖励时也是如此。这些行为高度受到内在满足感的驱使,被称为内在动机行为(Csikszentmihalyi,1990;Ryan & Deci,2000)。此类行为促进了无监督学习,而无需明确的外部奖励或惩罚,这在早期发育阶段已知具有各种优势(Gopnik,2009;Kanazawa等,2023;White,1959;Zaadnoordijk等,2022)。例如,婴儿自发运动产生的感官体验,如自触,不仅促进了对自身身体的学习(例如,获取身体表征)(Hoffmann等,2017),还贡献于早期自我意识的形成(Rochat,1998)。
传统观察研究和神经科学研究方法已被用于研究内在动机行为发展的机制(Di Domenico & Ryan,2017)。特别是,计算建模也被用来定量解释和预测行为发展(Oudeyer & Kaplan,2009;Shultz,2013)。使用计算机模拟进行的实验允许研究人员自由操控和控制特定变量以调查各种场景,这对于揭示仅通过传统行为研究难以观察到的潜在效应和相互作用非常有利。
虽然计算建模是研究婴儿行为发展的一种有用方法,但在现代机器人技术和机器学习中提出的许多模型倾向于将内在动机主要视为一种提高在稀疏外部奖励环境中奖励获取效率的探索机制(Aubret等,2023)。确实,这种方法可以增强强化学习代理显式任务性能的能力,例如最大化视频游戏得分。然而,它们并未充分解决当未设置明确的外部奖励目标时,完全新的行为是如何出现的问题,这意味着没有提供性能标准或信息增益。
为了解决这一局限性,我们基于预期自由能(Friston,2010;Friston等,2016)提出了一种新的内在动机计算模型(图1)。我们引入了一种内部密度模型,称为自我先验,使代理能够学习传入多模态感官信号的统计表示。当检测到学习的概率模型与实际观察之间的不匹配时,无需任何明确的奖励标准即可出现目标导向行为。具体来说,我们实现了一个模拟代理,它感知到手臂上的刺激(例如贴纸)并自发地表现出伸手触摸它的行为。在本文的后半部分,我们将讨论所提出的自我先验机制如何为发育科学、神经科学和机器学习做出贡献,将本研究定位为对婴儿早期有意行为发展的计算探究。
1.1 自由能原理
自由能原理认为,代理可以通过最小化感官输入引起的“惊讶”来学习感知和行动(Friston,2010)。在自由能框架中,惊讶指的是代理遇到意外感官观察时产生的预测误差,减少这种惊讶成为代理的主要目标。
在每个时间步
t
t
t,代理通过其感官器官从世界接收信息。我们将此感官输入记为
o
t
o_{t}
ot,称其为“观察”。尽管
o
t
o_{t}
ot是代理可以直接观察到的所有内容,但世界中可能存在产生这些观察的潜在因素。这些因素称为隐藏状态,在时间
t
t
t记为
s
t
s_{t}
st。例如,给定一个适当学习的模型,代理可以从手臂上的触觉模式(观察
o
t
o_{t}
ot)推断出手臂上有贴纸(隐藏状态
s
t
s_{t}
st)。
考虑一个必须以稳定方式满足某些生物标准才能生存的代理。为了做到这一点,代理必须准确理解其环境,这相当于推断
p
(
o
t
)
p\left(o_{t}\right)
p(ot)。根据自由能原理,代理维护自己的这些隐藏状态的概率模型,因为这样做使它可以近似
p
(
o
t
)
p\left(o_{t}\right)
p(ot),从而对世界作出推断。实际上,出于计算方便,我们通常最大化
p
(
o
t
)
p\left(o_{t}\right)
p(ot)的
log
\log
log(即
log
p
(
o
t
)
\log p\left(o_{t}\right)
logp(ot)),这被称为最大化模型证据。最小化负项
−
log
p
(
o
t
)
-\log p\left(o_{t}\right)
−logp(ot)——即所谓的惊讶——等同于最大化这个模型证据。
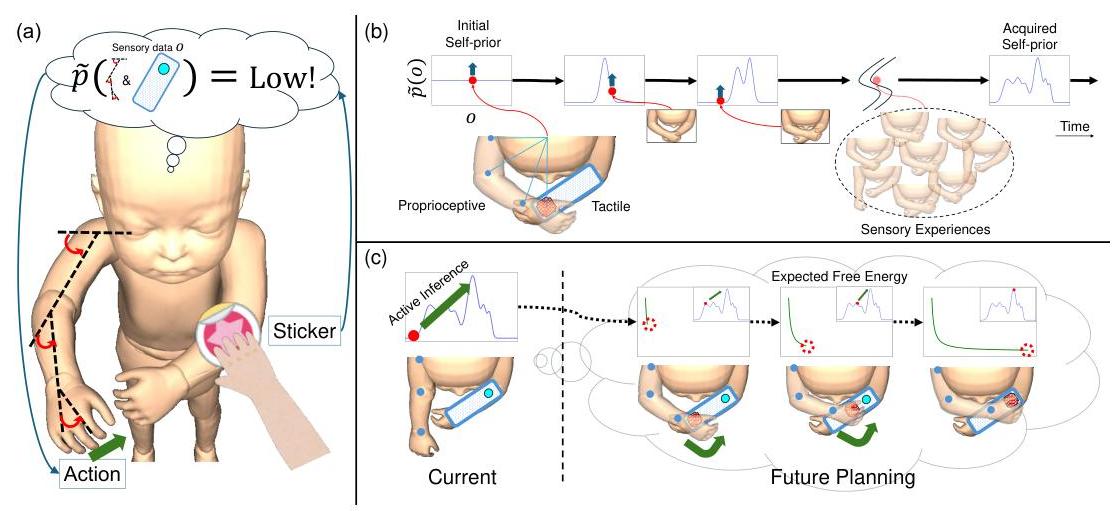
图1:通过自我先验和主动推理出现的伸手行为。(a)当贴纸放在模拟代理的左臂上时,它检测到与先前无贴纸的经验不匹配,并用右手伸向贴纸以最小化差异。(b)通过经验发展自我先验:随着感官经验的积累,感官模式的概率分布逐渐发展。(c)代理计划未来动作以最小化预期自由能,从而使感官输入与学习到的自我先验一致。结果,代理执行了朝贴纸伸手的动作。为清晰起见,使用全身婴儿插图,实际实验是在伪三维环境中进行的。
实际上,计算 p ( o t ) p\left(o_{t}\right) p(ot)需要对隐藏状态进行边缘化(即 p ( o t , s t ) p\left(o_{t}, s_{t}\right) p(ot,st)),这通常是不可行的。变分自由能原理通过引入贝叶斯推理的变分近似来解决这个问题,其中代理通过最小化变分自由能 F \mathcal{F} F间接减少惊讶,这是 − log p ( o t ) -\log p\left(o_{t}\right) −logp(ot)的一个上限。正式地, F \mathcal{F} F定义如下(详见(Parr等,2022)):
− log p ( o t ) ≤ F = E q ( s t ) [ log q ( s t ) − log p ( o t , s t ) ] = D K L [ q ( s t ) ∥ p ( s t ) ] ⏟ 复杂度 − E q ( s t ) [ log p ( o t ∣ s t ) ] ⏟ 准确性 \begin{aligned} -\log p\left(o_{t}\right) \leq \mathcal{F} & =\mathbb{E}_{q\left(s_{t}\right)}\left[\log q\left(s_{t}\right)-\log p\left(o_{t}, s_{t}\right)\right] \\ & =\underbrace{D_{\mathrm{KL}}\left[q\left(s_{t}\right) \| p\left(s_{t}\right)\right]}_{\text {复杂度 }}-\underbrace{\mathbb{E}_{q\left(s_{t}\right)}\left[\log p\left(o_{t} \mid s_{t}\right)\right]}_{\text {准确性 }} \end{aligned} −logp(ot)≤F=Eq(st)[logq(st)−logp(ot,st)]=复杂度 DKL[q(st)∥p(st)]−准确性 Eq(st)[logp(ot∣st)]
其中 D K L ( ⋅ ∣ ⋅ ) D_{\mathrm{KL}}(\cdot \mid \cdot) DKL(⋅∣⋅)表示Kullback-Leibler散度, q ( ⋅ ) q(\cdot) q(⋅)表示变分近似分布。也就是说, q ( s t ) q\left(s_{t}\right) q(st)是近似隐藏状态后验分布的变分分布。因此,为了在时间 t t t减少惊讶,代理必须保持后验和先验分布接近(降低复杂度),同时最大化观察的可能性(提高准确性)。
1.2 主动推理与预期自由能
虽然自由能原理描述了代理如何根据当前感官观察更新其模型以减少惊讶,但代理也可以通过动作
a
t
a_{t}
at直接改变其观察,使其更符合内部模型。这是主动推理的本质,更具体地说,近似后验
q
(
s
t
)
q\left(s_{t}\right)
q(st)被扩展为包括动作,即
q
(
s
t
,
a
t
)
=
q
(
a
t
∣
s
t
)
q
(
s
t
)
q\left(s_{t}, a_{t}\right)=q\left(a_{t} \mid s_{t}\right) q\left(s_{t}\right)
q(st,at)=q(at∣st)q(st)。
为了获得当前和未来步骤的最佳动作
a
t
a_{t}
at,一种方法是通过考虑未来时间点的预期自由能来计算预期自由能(Friston等,2016)。也就是说,代理预测多个可能的未来状态,并选择预计最有效地最小化自由能的轨迹。
然而,由于在相应的时间实际到达之前无法获得未来的观察结果,代理不能直接计算未来状态的自由能。因此,预期自由能假设代理对期望的观察结果有一个首选先验
p
^
(
o
t
)
\hat{p}\left(o_{t}\right)
p^(ot),这作为一个设定点。结果,
p
(
o
t
,
s
t
)
p\left(o_{t}, s_{t}\right)
p(ot,st)被扩展为包括动作,并偏向于
期望的观察结果,表示为
p
~
(
o
t
,
s
t
,
a
t
)
=
p
(
a
t
∣
s
t
)
p
(
s
t
∣
o
t
,
a
t
)
p
~
(
o
t
∣
a
t
)
\tilde{p}\left(o_{t}, s_{t}, a_{t}\right)=p\left(a_{t} \mid s_{t}\right) p\left(s_{t} \mid o_{t}, a_{t}\right) \tilde{p}\left(o_{t} \mid a_{t}\right)
p~(ot,st,at)=p(at∣st)p(st∣ot,at)p~(ot∣at)。假设
q
(
s
t
∣
o
t
,
a
t
)
≈
p
(
s
t
∣
o
t
,
a
t
)
q\left(s_{t} \mid o_{t}, a_{t}\right) \approx p\left(s_{t} \mid o_{t}, a_{t}\right)
q(st∣ot,at)≈p(st∣ot,at)以及动作上的均匀先验
p
(
a
t
)
p\left(a_{t}\right)
p(at),预期自由能
G
\mathcal{G}
G定义如下(详见(Mazzaglia等,2021;Millidge等,2020)的详细近似和推导):
G = E q ( o t , s t , a t ) [ log q ( s t , a t ) − log p ~ ( o t , s t , a t ) ] ≈ − E q ( o t ) [ log p ~ ( o t ) ] ⏟ 外在价值 − E q ( o t ) [ D K L [ q ( s t ∣ o t ) ∥ q ( s t ) ] ] ⏟ 内在价值 − E q ( s t ) [ H ( q ( a t ∣ s t ) ) ] ⏟ 动作熵 \begin{aligned} \mathcal{G} & =\mathbb{E}_{q\left(o_{t}, s_{t}, a_{t}\right)}\left[\log q\left(s_{t}, a_{t}\right)-\log \tilde{p}\left(o_{t}, s_{t}, a_{t}\right)\right] \\ & \approx-\underbrace{\mathbb{E}_{q\left(o_{t}\right)}\left[\log \tilde{p}\left(o_{t}\right)\right]}_{\text {外在价值 }}-\underbrace{\mathbb{E}_{q\left(o_{t}\right)}\left[D_{\mathrm{KL}}\left[q\left(s_{t} \mid o_{t}\right) \| q\left(s_{t}\right)\right]\right]}_{\text {内在价值 }}-\underbrace{\mathbb{E}_{q\left(s_{t}\right)}\left[\mathcal{H}\left(q\left(a_{t} \mid s_{t}\right)\right)\right]}_{\text {动作熵 }} \end{aligned} G=Eq(ot,st,at)[logq(st,at)−logp~(ot,st,at)]≈−外在价值 Eq(ot)[logp~(ot)]−内在价值 Eq(ot)[DKL[q(st∣ot)∥q(st)]]−动作熵 Eq(st)[H(q(at∣st))]
其中 H \mathcal{H} H表示信息熵。也就是说,为了在未来时间 t t t减少惊讶,代理必须(i)增加偏好观察结果的概率,(ii)从这些观察结果中获得高信息增益,以及(iii)保持多样化的动作。正如上面所示,预期自由能将实用(外在)和认知(内在)价值整合到一个表达式中,从而自然解决了探索-开发困境。外在动机项类似于为实现目标或获取生存所需奖励的动力,而内在动机项则对应于探索新信息或减少不确定性的内在愿望。由于两者都以相同的信息单位(nats)测量,它们在一个统一系统内自动平衡。
2 自我先验:习得偏好以引发目标导向行为
在预期自由能下,代理人不需要环境明确定义标量奖励。这是因为假定代理人拥有一个优选观察的分布,称为优选先验,它充当行动规划的设定点。然而,由于优选先验通常以固定形式给出,移除外在奖励信号并不意味着代理人自主生成了其目标导向行为。
相比之下,在本研究中,我们允许代理人通过额外学习一个内部密度模型来自主确定其行动规划的设定点,我们称之为自我先验。通过这种方式,代理人自发地生成目标导向行为,以最小化其内部模型与环境之间的差异,包括其自身身体。
技术上,我们通过对标准预期自由能公式进行简单修改来实现这一点——将自我先验项从原始优选先验项中分离出来。这使得可以提取一个内在动机项,该项维持通过经验历史形成的偏好,不同于维持特定经验的外在动机项。根据(Oudeyer & Kaplan,2009)提出的分类,这对应于内部稳态内在动机,尤其是与所谓熟悉度驱动的内在动机最为密切相关。我们将在讨论部分进一步探讨为什么内在动机可以在自由能公式的外在动机项中被提取。
为了在主动推理框架中实现自我先验,我们重新定义每个优选观察
o
o
o为两个组成部分:(i) 必须维持以满足生存要求的外在观察
o
E
o^{E}
oE,以及(ii) 与自我先验相关的内在观察
o
I
o^{I}
oI。这里,
o
I
o^{I}
oI指代身体状态或感觉——例如手臂上的触觉模式——这些可以在不影响代理人基本功能的情况下变化。因此,我们将
p
~
(
o
)
\tilde{p}(o)
p~(o)分解为
p
~
(
o
E
,
o
I
)
\tilde{p}\left(o^{E}, o^{I}\right)
p~(oE,oI),并在本研究中假设独立性,使得
p
~
(
o
E
,
o
I
)
=
p
~
(
o
E
)
p
~
(
o
I
)
\tilde{p}\left(o^{E}, o^{I}\right)=\tilde{p}\left(o^{E}\right) \tilde{p}\left(o^{I}\right)
p~(oE,oI)=p~(oE)p~(oI)。因此,包含自我先验的预期自由能变为:
G ≈ − E q ( o t ) [ log p ~ ( o t ) ] ⏟ 外在 (稳态) − E q ( o t ) [ D K L [ q ( s t ∣ o t ) ∥ q ( s t ) ] ] ⏟ 内在 (异态) − H ′ = − E q ( o t E , o t I ) [ log p ~ ( o t E , o t I ) ] ⏟ 稳态 − E q ( o t ) [ D K L [ q ( s t ∣ o t ) ∥ q ( s t ) ] ] ⏟ 异态 − H ′ = − E q ( o t E ) [ log p ~ ( o t E ) ] ⏟ 外在 (均态-, 固定) − E q ( o t I ) [ log p ~ ( o t I ) ] ⏟ 内在 (均态-, 熟悉度) − E q ( o t ) [ D K L [ q ( s t ∣ o t ) ∥ q ( s t ) ] ] ⏟ 内在 (异态-, 新颖性) − H ′ \begin{aligned} \mathcal{G} & \approx-\underbrace{\mathbb{E}_{q\left(o_{t}\right)}\left[\log \tilde{p}\left(o_{t}\right)\right]}_{\text {外在 (稳态) }}-\underbrace{\mathbb{E}_{q\left(o_{t}\right)}\left[D_{\mathrm{KL}}\left[q\left(s_{t} \mid o_{t}\right) \| q\left(s_{t}\right)\right]\right]}_{\text {内在 (异态) }}-\mathcal{H}^{\prime} \\ & =-\underbrace{\mathbb{E}_{q\left(o_{t}^{E}, o_{t}^{I}\right)}\left[\log \tilde{p}\left(o_{t}^{E}, o_{t}^{I}\right)\right]}_{\text {稳态 }}-\underbrace{\mathbb{E}_{q\left(o_{t}\right)}\left[D_{\mathrm{KL}}\left[q\left(s_{t} \mid o_{t}\right) \| q\left(s_{t}\right)\right]\right]}_{\text {异态 }}-\mathcal{H}^{\prime} \\ & =-\underbrace{\mathbb{E}_{q\left(o_{t}^{E}\right)}\left[\log \tilde{p}\left(o_{t}^{E}\right)\right]}_{\text {外在 (均态-, 固定) }}-\underbrace{\mathbb{E}_{q\left(o_{t}^{I}\right)}\left[\log \tilde{p}\left(o_{t}^{I}\right)\right]}_{\text {内在 (均态-, 熟悉度) }}-\underbrace{\mathbb{E}_{q\left(o_{t}\right)}\left[D_{\mathrm{KL}}\left[q\left(s_{t} \mid o_{t}\right) \| q\left(s_{t}\right)\right]\right]}_{\text {内在 (异态-, 新颖性) }}-\mathcal{H}^{\prime} \end{aligned} G≈−外在 (稳态) Eq(ot)[logp~(ot)]−内在 (异态) Eq(ot)[DKL[q(st∣ot)∥q(st)]]−H′=−稳态 Eq(otE,otI)[logp~(otE,otI)]−异态 Eq(ot)[DKL[q(st∣ot)∥q(st)]]−H′=−外在 (均态-, 固定) Eq(otE)[logp~(otE)]−内在 (均态-, 熟悉度) Eq(otI)[logp~(otI)]−内在 (异态-, 新颖性) Eq(ot)[DKL[q(st∣ot)∥q(st)]]−H′
这里,
H
′
\mathcal{H}^{\prime}
H′表示动作分布的熵。
我们设计系统使得代理能够自动学习自我先验,通过自动获取一种基于过去观察频率估计熟悉度的机制。实施细节在下一节中提供。
3 自我先验的计算模型
在本节中,我们介绍了基于主动推理框架结合自我先验的计算仿真模型的具体实现。我们分别介绍了离散变量和连续变量环境下的模型。在离散环境中,模型使用小尺寸矩阵构建,以便直接检查其行为。对于需要高维变量空间的连续环境,我们使用深度神经网络和深度强化学习中的技术。
3.1 离散模型
离散模型使用分类分布作为生成模型,处理离散随机变量:
先验: P ( s t ∣ s t − 1 , a t − 1 ) = Cat ( B a t − 1 ) 后验: Q ( s t ) = Cat ( ϕ t ) 可能性: P ( o t ∣ s t ) = Cat ( A ) \begin{aligned} \text { 先验: } & P\left(s_{t} \mid s_{t-1}, a_{t-1}\right)=\operatorname{Cat}\left(\mathbf{B}_{a_{t-1}}\right) \\ \text { 后验: } & Q\left(s_{t}\right)=\operatorname{Cat}\left(\phi_{t}\right) \\ \text { 可能性: } & P\left(o_{t} \mid s_{t}\right)=\operatorname{Cat}(\mathbf{A}) \end{aligned} 先验: 后验: 可能性: P(st∣st−1,at−1)=Cat(Bat−1)Q(st)=Cat(ϕt)P(ot∣st)=Cat(A)
这里,我们使用大写字母(例如 P , Q P, Q P,Q)表示离散分布,并用 Cat ( ⋅ ) \operatorname{Cat}(\cdot) Cat(⋅)表示分类分布。观察 o t o_{t} ot和隐藏状态 s t s_{t} st分别是具有 N o N_{o} No和 N s N_{s} Ns行的一热列向量,分别对应于可能观察和隐藏状态的数量。粗体符号如 A \mathbf{A} A和 B \mathbf{B} B表示分类分布的矩阵参数。 B \mathbf{B} B包含每个可用动作 a a a的单独矩阵(例如,如果动作是{LEFT, STOP, RIGHT},则存在单独的矩阵 B LEFT , B STOP , B RIGHT \mathbf{B}_{\text {LEFT }}, \mathbf{B}_{\text {STOP }}, \mathbf{B}_{\text {RIGHT }} BLEFT ,BSTOP ,BRIGHT )。 A \mathbf{A} A是一个 N o × N s N_{o} \times N_{s} No×Ns矩阵,每个 B a t − 1 \mathbf{B}_{a_{t-1}} Bat−1是一个 N s × N s N_{s} \times N_{s} Ns×Ns方阵。基于这些定义,给定动作 a t − 1 a_{t-1} at−1下的变分自由能 F \mathcal{F} F可以重写为:
F = E Q ( s t ) [ log Q ( s t ) − log P ( o t , s t ) ] = E Q ( s t ) [ log Q ( s t ) − log P ( s t ) ] − E Q ( s t ) [ log P ( o t ∣ s t ) ] = ϕ t ⋅ ( log ϕ t − log ( B a t − 1 ϕ t − 1 ) ) − ϕ t ⋅ ( log ( A ⋅ o t ) ) \begin{aligned} \mathcal{F} & =\mathbb{E}_{Q\left(s_{t}\right)}\left[\log Q\left(s_{t}\right)-\log P\left(o_{t}, s_{t}\right)\right] \\ & =\mathbb{E}_{Q\left(s_{t}\right)}\left[\log Q\left(s_{t}\right)-\log P\left(s_{t}\right)\right]-\mathbb{E}_{Q\left(s_{t}\right)}\left[\log P\left(o_{t} \mid s_{t}\right)\right] \\ & =\phi_{t} \cdot\left(\log \phi_{t}-\log \left(\mathbf{B}_{a_{t-1}} \phi_{t-1}\right)\right)-\phi_{t} \cdot\left(\log \left(\mathbf{A} \cdot o_{t}\right)\right) \end{aligned} F=EQ(st)[logQ(st)−logP(ot,st)]=EQ(st)[logQ(st)−logP(st)]−EQ(st)[logP(ot∣st)]=ϕt⋅(logϕt−log(Bat−1ϕt−1))−ϕt⋅(log(A⋅ot))
相应地,通过取 F \mathcal{F} F相对于 ϕ \phi ϕ的导数,可以推导出最小化自由能的参数 ϕ \phi ϕ:
∂ F ∂ ϕ t = log ϕ t − log ( B a t − 1 ϕ t − 1 ) + 1 − log ( A ⋅ o t ) = 0 ∴ log ϕ t ≈ log ( A ⋅ o t ) + log ( B a t − 1 ϕ t − 1 ) ϕ t ≈ σ ( log ( A ⋅ o t ) + log ( B a t − 1 ϕ t − 1 ) ) \begin{aligned} \frac{\partial \mathcal{F}}{\partial \phi_{t}} & =\log \phi_{t}-\log \left(\mathbf{B}_{a_{t-1}} \phi_{t-1}\right)+1-\log \left(\mathbf{A} \cdot o_{t}\right)=0 \\ \therefore \log \phi_{t} & \approx \log \left(\mathbf{A} \cdot o_{t}\right)+\log \left(\mathbf{B}_{a_{t-1}} \phi_{t-1}\right) \\ \phi_{t} & \approx \sigma\left(\log \left(\mathbf{A} \cdot o_{t}\right)+\log \left(\mathbf{B}_{a_{t-1}} \phi_{t-1}\right)\right) \end{aligned} ∂ϕt∂F∴logϕtϕt=logϕt−log(Bat−1ϕt−1)+1−log(A⋅ot)=0≈log(A⋅ot)+log(Bat−1ϕt−1)≈σ(log(A⋅ot)+log(Bat−1ϕt−1))
这里,
σ
\sigma
σ表示softmax函数,它规范化
ϕ
\phi
ϕ的元素,使它们总和为1。换句话说,新的后验参数
ϕ
\phi
ϕ可以从之前的动作
a
t
−
1
a_{t-1}
at−1和当前观察
o
t
o_{t}
ot计算得出。
我们假设可能性分布
Cat
(
A
)
\operatorname{Cat}(\mathbf{A})
Cat(A)和先验分布
Cat
(
B
)
\operatorname{Cat}(\mathbf{B})
Cat(B)已经准确学习。也就是说,参数
A
\mathbf{A}
A精确指定了每个可能的隐藏状态
s
t
s_{t}
st对应的观察
o
t
o_{t}
ot,而
B
\mathbf{B}
B精确指定了每个可能动作
a
t
a_{t}
at在每个状态下的结果。这种简化假设使我们能够在不引入生成模型其他部分副作用的情况下,隔离自我先验变化对行为的影响(在稍后讨论的连续模型中,可能性和先验的学习都包括在内)。
作为未来观察的设定点的分布
P
~
(
o
t
)
\tilde{P}\left(o_{t}\right)
P~(ot)以分类分布
Cat
(
C
)
\operatorname{Cat}(\mathbf{C})
Cat(C)的形式给出,其中
C
\mathbf{C}
C是一个每行对应于每个可能
o
t
o_{t}
ot的列向量。在
本研究中,由于我们旨在考察由自我先验驱动的行为,所有
o
t
o_{t}
ot仅包含与
o
t
I
o_{t}^{I}
otI相关的信息。因此,整个
Cat
(
C
)
\operatorname{Cat}(\mathbf{C})
Cat(C)被定义为自我先验:
自我先验: P ~ ( o t I ) = Cat ( C ) \text { 自我先验: } \quad \tilde{P}\left(o_{t}^{I}\right)=\operatorname{Cat}(\mathbf{C}) 自我先验: P~(otI)=Cat(C)
代理通过记录先前经历观察的频率并将相应的观察概率存储在参数
C
\mathbf{C}
C中来自主学习自我先验。
C
\mathbf{C}
C的初始值设置为所有观察具有相等概率。
为了确定最佳动作
a
t
a_{t}
at,我们按照上述方法计算与每个可能动作相关的预期自由能。这由以下公式给出:
G = E Q ( s t + 1 , o t + 1 ∣ a t ) [ log Q ( s t + 1 ∣ a t ) − log P ~ ( o t + 1 , s t + 1 ∣ a t ) ] = E Q ( s t + 1 , o t + 1 ∣ a t ) [ log Q ( s t + 1 ∣ a t ) − log P ( s t + 1 ∣ o t + 1 , a t ) − log P ~ ( o t + 1 ) ] ≈ E Q ( s t + 1 , o t + 1 ∣ a t ) [ log Q ( s t + 1 ∣ a t ) − log Q ( s t + 1 ∣ o t + 1 , a t ) − log P ~ ( o t + 1 ) ] = E Q ( s t + 1 , o t + 1 ∣ a t ) [ log Q ( o t + 1 ∣ a t ) − log Q ( o t + 1 ∣ s t + 1 , a t ) − log P ~ ( o t + 1 ) ] \begin{aligned} \mathcal{G} & =\mathbb{E}_{Q\left(s_{t+1}, o_{t+1} \mid a_{t}\right)}\left[\log Q\left(s_{t+1} \mid a_{t}\right)-\log \tilde{P}\left(o_{t+1}, s_{t+1} \mid a_{t}\right)\right] \\ & =\mathbb{E}_{Q\left(s_{t+1}, o_{t+1} \mid a_{t}\right)}\left[\log Q\left(s_{t+1} \mid a_{t}\right)-\log P\left(s_{t+1} \mid o_{t+1}, a_{t}\right)-\log \tilde{P}\left(o_{t+1}\right)\right] \\ & \approx \mathbb{E}_{Q\left(s_{t+1}, o_{t+1} \mid a_{t}\right)}\left[\log Q\left(s_{t+1} \mid a_{t}\right)-\log Q\left(s_{t+1} \mid o_{t+1}, a_{t}\right)-\log \tilde{P}\left(o_{t+1}\right)\right] \\ & =\mathbb{E}_{Q\left(s_{t+1}, o_{t+1} \mid a_{t}\right)}\left[\log Q\left(o_{t+1} \mid a_{t}\right)-\log Q\left(o_{t+1} \mid s_{t+1}, a_{t}\right)-\log \tilde{P}\left(o_{t+1}\right)\right] \end{aligned} G=EQ(st+1,ot+1∣at)[logQ(st+1∣at)−logP~(ot+1,st+1∣at)]=EQ(st+1,ot+1∣at)[logQ(st+1∣at)−logP(st+1∣ot+1,at)−logP~(ot+1)]≈EQ(st+1,ot+1∣at)[logQ(st+1∣at)−logQ(st+1∣ot+1,at)−logP~(ot+1)]=EQ(st+1,ot+1∣at)[logQ(ot+1∣at)−logQ(ot+1∣st+1,at)−logP~(ot+1)]
为了便于实际计算,方程可以重新表述如下:
G ≈ E Q ( s t + 1 ∣ a t ) Q ( o t + 1 ∣ s t + 1 , a t ) [ − log Q ( o t + 1 ∣ s t + 1 , a t ) ] + E Q ( o t + 1 ∣ a t ) [ log Q ( o t + 1 ∣ a t ) − log P ~ ( o t + 1 ) ] = E Q ( s t + 1 ∣ a t ) P ( o t + 1 ∣ s t + 1 ) [ − log P ( o t + 1 ∣ s t + 1 ) ] + E Q ( o t + 1 ∣ a t ) [ log Q ( o t + 1 ∣ a t ) − log P ~ ( o t + 1 ) ] = E Q ( s t + 1 ∣ a t ) [ H [ P ( o t + 1 ∣ s t + 1 ) ] ] + D K L [ Q ( o t + 1 ∣ a t ) ∥ P ~ ( o t + 1 ) ] = ( B a t ϕ t ) ⋅ H [ A ] + D K L [ A B a t ϕ t ∥ C ] \begin{aligned} \mathcal{G} \approx \mathbb{E}_{Q\left(s_{t+1} \mid a_{t}\right) Q\left(o_{t+1} \mid s_{t+1}, a_{t}\right)}\left[-\log Q\left(o_{t+1} \mid s_{t+1}, a_{t}\right)\right] \\ & +\mathbb{E}_{Q\left(o_{t+1} \mid a_{t}\right)}\left[\log Q\left(o_{t+1} \mid a_{t}\right)-\log \tilde{P}\left(o_{t+1}\right)\right] \\ & =\mathbb{E}_{Q\left(s_{t+1} \mid a_{t}\right) P\left(o_{t+1} \mid s_{t+1}\right)}\left[-\log P\left(o_{t+1} \mid s_{t+1}\right)\right] \\ & +\mathbb{E}_{Q\left(o_{t+1} \mid a_{t}\right)}\left[\log Q\left(o_{t+1} \mid a_{t}\right)-\log \tilde{P}\left(o_{t+1}\right)\right] \\ & =\mathbb{E}_{Q\left(s_{t+1} \mid a_{t}\right)}\left[\mathcal{H}\left[P\left(o_{t+1} \mid s_{t+1}\right)\right]\right]+D_{\mathrm{KL}}\left[Q\left(o_{t+1} \mid a_{t}\right) \| \tilde{P}\left(o_{t+1}\right)\right] \\ & =\left(\mathbf{B}_{a_{t}} \phi_{t}\right) \cdot \mathcal{H}[\mathbf{A}]+D_{\mathrm{KL}}\left[\mathbf{A} \mathbf{B}_{a_{t}} \phi_{t} \| \mathbf{C}\right] \end{aligned} G≈EQ(st+1∣at)Q(ot+1∣st+1,at)[−logQ(ot+1∣st+1,at)]+EQ(ot+1∣at)[logQ(ot+1∣at)−logP~(ot+1)]=EQ(st+1∣at)P(ot+1∣st+1)[−logP(ot+1∣st+1)]+EQ(ot+1∣at)[logQ(ot+1∣at)−logP~(ot+1)]=EQ(st+1∣at)[H[P(ot+1∣st+1)]]+DKL[Q(ot+1∣at)∥P~(ot+1)]=(Batϕt)⋅H[A]+DKL[ABatϕt∥C]
这里,我们使用
Q
(
o
t
∣
s
t
,
a
t
−
1
)
=
P
(
o
t
∣
s
t
)
Q\left(o_{t} \mid s_{t}, a_{t-1}\right)=P\left(o_{t} \mid s_{t}\right)
Q(ot∣st,at−1)=P(ot∣st),因为状态到观察的映射被认为与动作无关。此外,由于在我们的设置中假设
A
\mathbf{A}
A和
B
\mathbf{B}
B是完全已知的,离散实验中省略了参数信息增益的动作熵项(参见(Parr等,2022)以获取上述公式的详细说明)。
在离散环境中,我们从当前时间
t
t
t开始计算到未来时间
t
+
N
t+N
t+N的预期自由能。然后使用所有步骤的总预期自由能来评估策略
π
=
{
a
t
,
a
t
+
1
,
…
,
a
t
+
N
}
\pi=\left\{a_{t}, a_{t+1}, \ldots, a_{t+N}\right\}
π={at,at+1,…,at+N}。策略被计算为动作上的分类分布,从中采样动作如下:
策略: P ( π ) = σ ( − G ) \text { 策略: } \quad P(\pi)=\sigma(-\mathcal{G}) 策略: P(π)=σ(−G)
3.2 连续模型
先前关于将自由能原则从离散扩展到连续领域的研究常常利用深度神经网络的强大表达能力。事实上,最初在深度强化学习中提出的一些技术已经被证明可以密切逼近自由能优化。例如,PlaNet中的循环状态空间模型(RSSM)(Hafner等,2019)可以被解释为优化变分自由能(Çatal等,2020),而策略梯度方法可以被视为最小化预期自由能(Millidge,2020)。遵循这些先例,我们在连续环境中使用深度神经网络实现自由能最小化(图2)。
离散模型固定了变分自由能中的可能性和先验分布参数,而连续模型则使用深度神经网络训练这两个分布,类似于RSSM,针对参数
ϕ
\phi
ϕ:
先验:
p
ϕ
(
h
t
∣
s
t
−
1
,
a
t
−
1
)
后验:
q
ϕ
(
s
t
∣
h
t
,
o
t
)
可能性:
p
ϕ
(
o
t
∣
s
t
)
\begin{aligned} \text { 先验: } & p_{\phi}\left(h_{t} \mid s_{t-1}, a_{t-1}\right) \\ \text { 后验: } & q_{\phi}\left(s_{t} \mid h_{t}, o_{t}\right) \\ \text { 可能性: } & p_{\phi}\left(o_{t} \mid s_{t}\right) \end{aligned}
先验: 后验: 可能性: pϕ(ht∣st−1,at−1)qϕ(st∣ht,ot)pϕ(ot∣st)
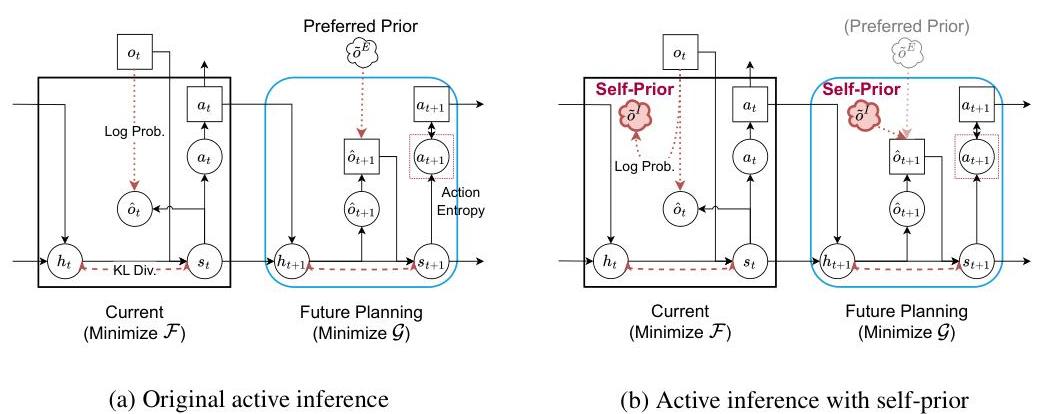
图2:使用深度神经网络进行主动推理的图形模型,以最小化变分自由能 F \mathcal{F} F和预期自由能 G \mathcal{G} G。自我先验 p ~ ( o t I ) \tilde{p}\left(o_{t}^{I}\right) p~(otI)被训练以最大化观察 o t I o_{t}^{I} otI的对数似然。在预期自由能计算中(蓝色突出显示),学习到的自我先验与固定的优选先验一起作为行为设定点。虽然理论上可以同时应用优选先验和自我先验,但为了清楚阐述,本研究仅使用自我先验;因此,图中优选先验显示为淡化的。
先验通过线性层将前一隐藏状态
s
t
−
1
s_{t-1}
st−1和动作
a
t
−
1
a_{t-1}
at−1编码为单一向量,然后输入GRU单元(Chung等,2014)以随时间整合输入。GRU的隐藏状态通过两层MLP输出多元高斯分布的参数,从中采样随机状态。我们将此随机状态与GRU隐藏状态连接起来,生成先验特征
h
t
h_{t}
ht。我们使用
h
t
h_{t}
ht区分先验表示与后验变量
s
t
s_{t}
st(也就是说,变分自由能
F
\mathcal{F}
F中的KL项,原为
D
K
L
[
q
(
s
t
)
∥
p
(
s
t
)
]
D_{\mathrm{KL}}\left[q\left(s_{t}\right) \| p\left(s_{t}\right)\right]
DKL[q(st)∥p(st)],现在表示为
D
K
L
[
q
ϕ
(
s
t
∣
h
t
,
o
t
)
∥
p
ϕ
(
h
t
∣
s
t
−
1
,
a
t
−
1
)
]
D_{\mathrm{KL}}\left[q_{\phi}\left(s_{t} \mid h_{t}, o_{t}\right) \| p_{\phi}\left(h_{t} \mid s_{t-1}, a_{t-1}\right)\right]
DKL[qϕ(st∣ht,ot)∥pϕ(ht∣st−1,at−1)])。
后验接收先验特征
h
t
h_{t}
ht和嵌入观察
o
t
o_{t}
ot连接的向量作为输入。我们使用嵌入观察,因为在我们的实验中涉及多模态感官数据,嵌入允许我们将不同维度的感官输入整合为单一表示。由于嵌入方法可能因实验而异,更多细节将在实验部分提供。连接后的
h
t
h_{t}
ht和
o
t
o_{t}
ot通过后验网络中的两层MLP,输出多元高斯分布的参数,并从该分布中采样后验特征
s
t
s_{t}
st。
可能性网络通过线性层将
s
t
s_{t}
st转换为
o
t
o_{t}
ot,然后将嵌入的
o
t
o_{t}
ot解码为特定模态的观察。先验、后验和可能性网络的参数
ϕ
\phi
ϕ通过梯度下降优化,以最小化以下自由能:
F = E q ( s t ) [ log q ( s t ) − log p ( o t , s t ) ] = E q ( s t ) [ log q ( s t ) − log p ( s t ) ] − E q ( s t ) [ log p ( o t ∣ s t ) ] = D K L [ q ( s t ) ∥ p ( s t ) ] − E q ( s t ) [ log p ( o t ∣ s t ) ] ∴ arg min ϕ F = arg min ϕ [ D K L [ q ϕ ( s t ∣ h t , o t ) ∥ p ϕ ( h t ∣ s t − 1 , a t − 1 ) ] − E q ϕ ( s t ∣ h t , o t ) [ log p ϕ ( o t ∣ s t ) ] ] \begin{aligned} \mathcal{F} & =\mathbb{E}_{q\left(s_{t}\right)}\left[\log q\left(s_{t}\right)-\log p\left(o_{t}, s_{t}\right)\right] \\ & =\mathbb{E}_{q\left(s_{t}\right)}\left[\log q\left(s_{t}\right)-\log p\left(s_{t}\right)\right]-\mathbb{E}_{q\left(s_{t}\right)}\left[\log p\left(o_{t} \mid s_{t}\right)\right] \\ & =D_{\mathrm{KL}}\left[q\left(s_{t}\right) \| p\left(s_{t}\right)\right]-\mathbb{E}_{q\left(s_{t}\right)}\left[\log p\left(o_{t} \mid s_{t}\right)\right] \\ \therefore \underset{\phi}{\arg \min } \mathcal{F} & =\underset{\phi}{\arg \min }\left[D_{\mathrm{KL}}\left[q_{\phi}\left(s_{t} \mid h_{t}, o_{t}\right) \| p_{\phi}\left(h_{t} \mid s_{t-1}, a_{t-1}\right)\right]-\mathbb{E}_{q_{\phi}\left(s_{t} \mid h_{t}, o_{t}\right)}\left[\log p_{\phi}\left(o_{t} \mid s_{t}\right)\right]\right] \end{aligned} F∴ϕargminF=Eq(st)[logq(st)−logp(ot,st)]=Eq(st)[logq(st)−logp(st)]−Eq(st)[logp(ot∣st)]=DKL[q(st)∥p(st)]−Eq(st)[logp(ot∣st)]=ϕargmin[DKL[qϕ(st∣ht,ot)∥pϕ(ht∣st−1,at−1)]−Eqϕ(st∣ht,ot)[logpϕ(ot∣st)]]
在连续模型中,如同离散情况一样,我们不考虑外在偏好,以专注于由自我先验驱动的行为。因此,我们设置 p ~ ( o t ) = p ~ ( o t I ) \tilde{p}\left(o_{t}\right)=\tilde{p}\left(o_{t}^{I}\right) p~(ot)=p~(otI)。自我先验使用基于归一化流的密度估计器实现,具体为神经样条流(NSF)(Durkan等,2019)。代理通过最大化每一步观察的对数似然来自主学习自我先验。为了高效训练神经网络,我们从重放缓冲区 D \mathcal{D} D中采样观察,该缓冲区存储最近经历的轨迹:
自我先验:
p
~
ξ
(
o
t
)
arg
min
ξ
L
self
=
arg
min
ξ
E
o
∼
D
[
−
log
p
~
ξ
(
o
)
]
\begin{gathered} \text { 自我先验: } \quad \tilde{p}_{\xi}\left(o_{t}\right) \\ \underset{\xi}{\arg \min } \mathcal{L}_{\text {self }}=\underset{\xi}{\arg \min } \mathbb{E}_{o \sim \mathcal{D}}\left[-\log \tilde{p}_{\xi}(o)\right] \end{gathered}
自我先验: p~ξ(ot)ξargminLself =ξargminEo∼D[−logp~ξ(o)]
与离散模型不同,后者通过最小化到未来时间
t
+
N
t+N
t+N的预期自由能之和来规划动作,连续模型无法枚举这些可能性。为此,我们采用受强化学习中演员-评论家方法启发的学习方法,类似于(Millidge,2020)。具体来说,我们训练一个独立的策略网络,从状态
s
t
s_{t}
st预测适当的动作
a
t
a_{t}
at,并另外训练一个预期效用网络,估计超出
t
+
N
t+N
t+N之后无限范围的预期自由能:
策略: q θ ( a t ∣ s t ) 预期效用: g ψ ( s t ) \begin{aligned} \text { 策略: } & q_{\theta}\left(a_{t} \mid s_{t}\right) \\ \text { 预期效用: } & g_{\psi}\left(s_{t}\right) \end{aligned} 策略: 预期效用: qθ(at∣st)gψ(st)
这种方法类似于软演员-批评(Haarnoja等,2018),其中策略网络和效用网络都以后验特征 s t s_{t} st作为输入,使用三层MLP输出多元高斯分布的参数,并从该分布中采样。相应地,策略和效用网络按以下方式进行训练:
KaTeX parse error: Expected & or \\ or \cr or \end at end of input: …begin{array}{l}
\begin{aligned}
\left{
\begin{array}{ll}
\text { if } t<H \
\text { if } t=H
\end{array}\right.
\end{aligned}
$$
我们使用 GAE ( λ ) \operatorname{GAE}(\lambda) GAE(λ)估计来训练效用网络(Schulman等,2015)。对于连续模型中所有其他未指定的超参数和训练稳定化技术(例如KL散度剪辑、动作熵缩放),我们遵循(Mazzaglia等,2021)。
4 实验与结果
在本节中,我们通过计算机模拟验证了由多模态感官体验学习到的自我先验驱动的目标导向行为的出现。我们的实验设置假设了一个场景:婴儿代理检测到其左臂上的贴纸,关注该物体,并最终用右手将其移除——类似于(Bigelow,1986)的研究,其中在一个盲婴的身体上放置了一个无声玩具以检查伸手行为。
我们的实验基于以下假设:(i)由于婴儿通常没有贴纸附着在身体上,因此它会获得一个“我的身体上没有贴纸”的自我先验;(ii)当贴纸附着时,感官观察与自我先验之间的不匹配增加了自由能;(iii)为了减少自由能,代理自发地生成指向贴纸的伸手行为。
通过这些实验,我们(i)验证了代表代理自身偏好的自我先验是如何自主形成的,(ii)确认了在包含自我先验的自由能最小化框架内目标导向行为的出现,并且(iii)在离散环境中展示了即使面对相同的刺激,行为也可能因自我先验的变化而有所不同。
4.1 离散模拟
在离散环境中,代理接收由离散本体感受和触觉输入组成的多模态观察(图3)。代理的右手可以占据五个位置中的一个,标记为 0 , 1 , 2 , 3 0,1,2,3 0,1,2,3或4,表示其本体感受状态。左臂上有三个触觉传感器,位于右手坐标系中的位置1,2和3处,每个传感器可以独立激活,产生 2 3 = 8 2^{3}=8 23=8种可能的触觉状态。因此,观察变量 o t o_{t} ot可以取 5 × 8 = 40 5 \times 8=40 5×8=40个不同的值,并表示为一个40维的一热列向量(表1)。
看护者可以在代理的左臂上附着一张贴纸。如果贴纸放在特定位置(例如位置
x
x
x),无论右手的位置如何,代理都会持续从位置
x
x
x接收到触觉信号。如果右手正好与贴纸的位置重合,代理会感知到单一的触觉信号。
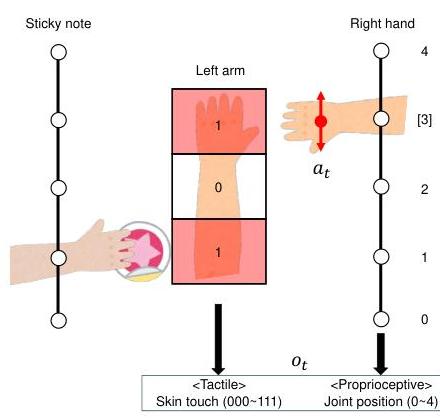
图3:离散环境概述。右手可以在左臂上方或外部左右移动,触觉输入发生在右手所在位置或贴纸附着位置。
表1:离散环境中感官观察的可能组合
| o t o_{t} ot | 触觉 ( 000 ∼ 111 ) (000 \sim 111) (000∼111) | 手的位置 ( 0 ∼ 4 ) (0 \sim 4) (0∼4) |
|---|---|---|
| 0 | 000 | 0 |
| 1 | 000 | 1 |
| ⋮ \vdots ⋮ | ⋮ \vdots ⋮ | ⋮ \vdots ⋮ |
| 28 | 101 | 3 |
| ⋮ \vdots ⋮ | ⋮ \vdots ⋮ | ⋮ \vdots ⋮ |
| 39 | 111 | 4 |
在每个时间步,代理选择三种动作
a
t
a_{t}
at之一:(i)保持静止,(ii)向左移动一步,或(iii)向右移动一步。因此,
a
t
a_{t}
at表示为一个3维的一热列向量。在离散实验中,策略
π
\pi
π考虑未来4步范围内的所有
3
4
=
81
3^{4}=81
34=81种可能的动作序列,并根据方程10中定义的预期自由能总和按概率选择每个序列。
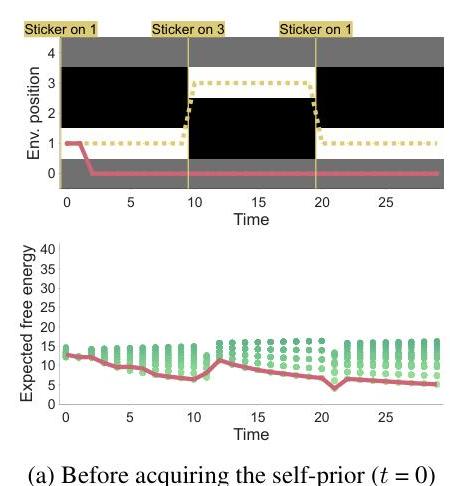
在离散环境实验的第一阶段,我们让代理在足够长的时间(10,000步)内无约束运行。对于真实婴儿来说,这样的观察可能对应于满足外在偏好的各种日常体验。然而,为了简化起见,我们假设了一种运动喃语条件,在这种条件下,代理随机选择其动作a。最初,自我先验在所有可能的观察上均匀分布,因此即使存在贴纸也不会做出反应(图5a)。
通过运动喃语,代理学习到“当右手在左臂上方时会出现单一触觉信号”,结果是“当右手不在左臂上时不会出现触觉信号”(图4左侧)。当看护者将贴纸附着在左臂的位置1时,会在不同于当前手位置(位置4)的地方生成触觉信号。根据新学到的自我先验,这是一种低概率情况,导致自由能增加(即由于与模型不匹配而引起注意)。然后,代理开始规划动作以减少预期自由能,并得出触摸贴纸最符合其自我先验的结论。结果,代理显示出朝位置1移动的目标导向行为(图5b)。同样,当看护者将贴纸移到位置3时,代理检测到这种新信号与模型不符并迅速伸手朝位置3伸去。
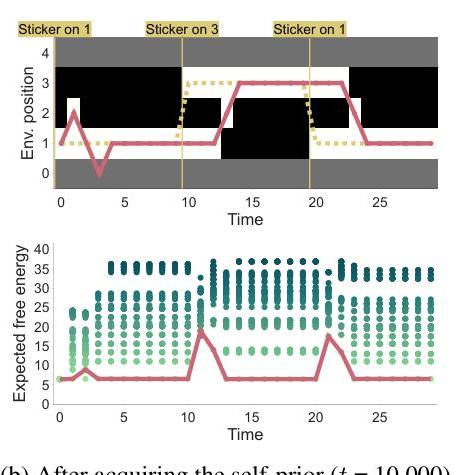
接下来,我们在贴纸仍留在位置3的情况下让代理再次进行一轮运动喃语(20,000步)。随着时间的推移,自我先验逐渐更新,使得位置3的触觉信号概率相对于贴纸不存在时有所增加。换句话说,代理开始期望无论手的位置如何,在位置3都会有触觉输入(图4右侧)。
经过这一延长的喃语后,如果贴纸被移到位置1,代理仍然注意到这种不匹配(因为位置1的触觉信号与自我先验不符)并伸手触摸它。然而,如果贴纸重新放回位置3,代理不再表现出一致的目标导向行为(图6)。因为自我先验已经适应了位置3,所以没有额外的不匹配出现。因此,伸手或不伸手之间的预期自由能差异可以忽略不计,代理只是随机行动。
在这种情况下,自我先验没有引发任何动机,这使我们可以隔离出内在动机在预期自由能框架中传统信息增益成分的影响。在这个实验中,由于参数
A
\mathbf{A}
A和
B
\mathbf{B}
B已经固定在完全准确的状态下,从观察中无法获得新的信息。结果,没有出现认识
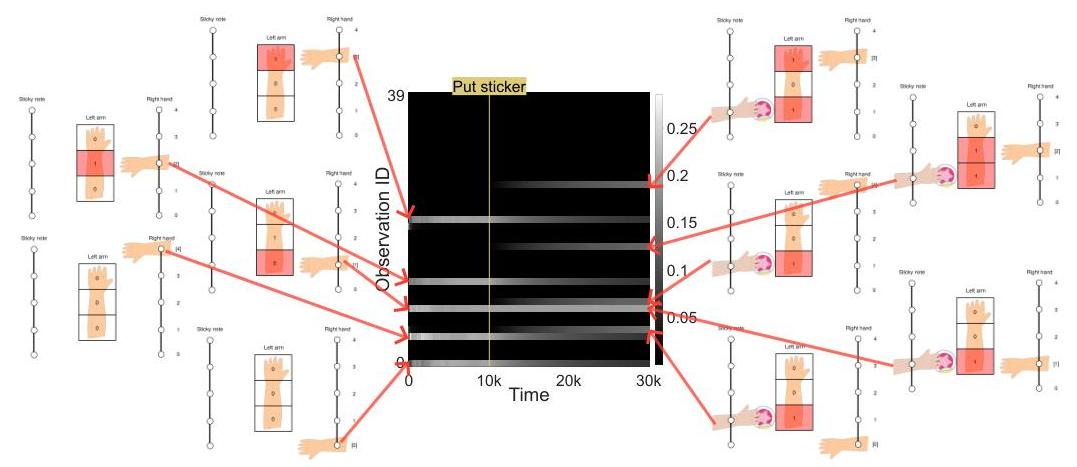
图4:自我先验随时间的变化。在贴纸附着之前,手臂上没有贴纸的情况下的概率增加
(
t
<
10
,
000
)
(t<10,000)
(t<10,000)。贴纸附着之后,代理逐渐适应了贴纸存在的新情况
(
t
≥
10
,
000
)
(t \geq 10,000)
(t≥10,000)。
(b) 获取自我先验后
(
t
=
10
,
000
)
(t=10,000)
(t=10,000)
图5:获取自我先验前后代理行为的比较。上图展示了环境随时间的变化:红线表示手的位置,黄色虚线表示贴纸的位置。白色区域表示触觉反馈发生的区域,黑色区域表示没有触觉反馈的区域,灰色区域表示手臂外部从未发生触觉反馈的区域。下图显示了随时间变化的预期自由能。每个绿色点代表候选策略的自由能,自由能较低的策略更有可能被选中。红线连接实际选择的策略。(a) 在获取自我先验之前,即使手臂上有贴纸,代理也不会作出反应。(b) 在获取自我先验之后,出现了目标导向行为:当贴纸出现在手臂上时,代理将其手移动到贴纸的位置。
(信息寻求)驱动力出现,所有策略产生的预期自由能几乎相同,导致代理随机行为。
相比之下,我们观察到,即使不可能获得额外的信息增益,由自我先验引发的动作仍然可以生成。换句话说,由于自我先验的参数
C
\mathbf{C}
C随着经验不断演变,基于经验的熟悉性相关的内在动机仍然被诱导。结果,代理被驱动采取能够使其新更新的自我先验与观察相一致的行为。
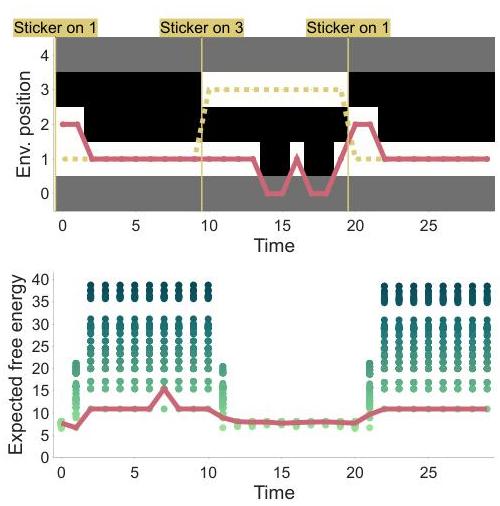
图6:当贴纸持续附着在位置3时代理的行为( t = 30 , 000 t=30,000 t=30,000)。当贴纸放置在其他位置时,代理仍然伸手朝它们伸去;然而,当贴纸放置在位置3时,代理不再表现出兴趣。
4.2 连续模拟
到目前为止,我们已经介绍了一个简单离散设置的核心思想,即目标导向行为可以从自我先验中涌现出来。我们现在将其扩展到具有连续值变量的环境中,灵感来自于(Marcel等人,2022)的环境设置(图7)。
起初,代理的两条手臂位于xy平面上。左前臂、左臂、躯干、右臂和右前臂的长度分别为80mm、70mm、140mm、70mm和80mm。左前臂上有一个30mm宽的二维触觉传感器阵列,相对于前臂本身横向放置。右前臂末端有一个半径为6mm的圆形“右手”,可以在左前臂上生成触觉输入。
所有关节角度都以弧度表示。左肘和左肩的角度分别固定为
π
/
3
\pi / 3
π/3和
2
π
/
3
2 \pi / 3
2π/3,而右肩和右肘的角度范围分别为
[
0
,
2
π
/
3
]
[0,2 \pi / 3]
[0,2π/3]和
[
0
,
3
π
/
4
]
[0,3 \pi / 4]
[0,3π/4]。此外,右手可以在伪z(高度)轴上移动,范围为
[
0
,
20
]
m
m
[0,20] \mathrm{mm}
[0,20]mm。
类似于离散情况,代理感知到本体感觉和触觉;然而,现在这些量是连续的。本体感觉输入是一个三维实数值向量(肩膀、肘部、手部),而触觉输入则由一个归一化为
[
0
,
1
]
[0,1]
[0,1]的
80
×
30
80 \times 30
80×30实值矩阵表示。每当右手距离左前臂的高度
≤
10
m
m
\leq 10 \mathrm{~mm}
≤10 mm时,左前臂上的触觉传感器会被激活,强度与手的高度成反比。
为了在连续模型中将触觉和本体感觉模态统一表示为一个综合观察
o
t
o_{t}
ot,我们将每个模态嵌入到相同维度的向量中。具体而言,我们使用四层Conv2D模块嵌入触觉矩阵,并使用两层MLP嵌入本体感觉向量。生成的嵌入通过逐元素加法结合以生成集成观察嵌入
o
t
o_{t}
ot。为了从该嵌入解码回原始感官模态,我们使用四层ConvTranspose2D用于触觉输出和两层MLP用于本体感觉输出。
看护者可以在左前臂上固定高度0 mm处附着一个半径为4 mm的贴纸。如果代理在其右手中心连续10个时间步骤内保持在右手和贴纸半径之和范围内,则可以移除贴纸。
在每个时间步骤中,右肩和右肘角度各自可以在-0.05至+0.05 rad之间旋转,手的高度可以移动-0.5至+0.5 mm。为了使手靠近前臂,我们施加了额外的约束,即手的中心必须保持在前臂表面15 mm范围内。如果提议的移动会使手超出此区域,则忽略代理的动作并保留其先前位置。
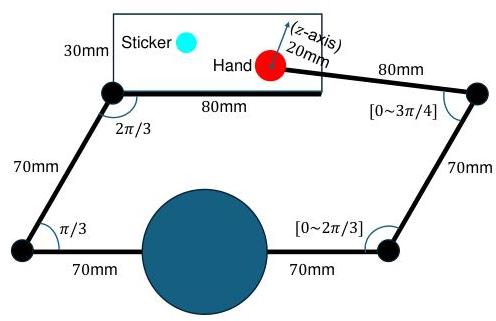
图7:连续环境概述。与离散环境一样,右手可以在左臂上方和周围移动,并在手或贴纸所在位置生成触觉感觉。
我们在一台运行Ubuntu 22.04.5 LTS 64位(Linux 5.15.0-1066)的机器上进行了连续环境实验,该机器配备了Intel Xeon E5-2698 v4 CPU和NVIDIA Tesla V100-SXM2 GPU,使用Python 3.11.10和PyTorch 2.5.1。对于基于规范化流的自我先验,我们使用了“zuko”库(版本1.3.0),并且我们的整体算法实现很大程度上基于Dreamer(Hafner等,2020)和对比主动推理(Mazzaglia等,2021)。
为了训练和评估我们的深度模型,我们将剧集存储在重放缓冲区中,并在模型训练期间随机采样。每个剧集要么通过使用随机动作收集,要么通过遵循主动推理中的代理策略收集,两者的选择概率相等(50%)。同样,对于一半的剧集,在手臂上的随机位置放置一张贴纸;对于另一半剧集,不使用贴纸。每个剧集由
L
=
1000
L=1000
L=1000个时间步骤组成。
在收集初始批次的10个剧集后,我们在每个剧集结束时对模型进行100轮训练。在每轮中,我们从重放缓冲区中采样
B
=
50
B=50
B=50条长度为
L
=
50
L=50
L=50的轨迹,并生成计划范围为
H
=
15
H=15
H=15的想象轨迹以进行策略学习。对于变分自由能最小化,轨迹是从所有可用数据中采样的,无论是否存在贴纸或行为是随机还是策略驱动的。这是为了确保获取准确的世界模型,类似于离散环境中的假设,即
A
\mathbf{A}
A和
B
\mathbf{B}
B已经是已知的。同样,所有数据都被用于预期自由能最小化,以便代理可以学习哪些动作在各种条件下有效减少自由能。
对于自我先验学习,我们构建数据集,使得约5%的剧集包含贴纸,其余部分则是在没有任何贴纸的情况下采样的。因此,正如离散环境实验中所展示的那样,自我先验倾向于赋予高概率的观察结果如“当右手在左臂上方时会出现单点触碰”和“当右手远离左臂时没有触碰”。
只要在左臂上放置贴纸,代理就会表现出目标导向的伸手行为(图8a)。这是因为触摸贴纸通过与自我先验一致来最小化自由能(图8b)。此外,在成功接触贴纸后,代理继续触摸它直到贴纸被移除,表明一种持续的动力来解决不匹配,而不是仅仅在接触后失去兴趣。
有趣的是,即使右手最初没有触碰到手臂,代理也会表现出伸手朝贴纸的方向移动的行为。如果自我先验仅基于触觉信息学习,(i) 右手触碰左臂和 (ii) 贴纸附着的情况可能无法区分——因为这两种情况都会在手臂上产生单一触觉点。在这种情况下,不会出现朝贴纸伸手的行为。然而,代理确实朝贴纸伸手,这表明自我先验是通过整合触觉和本体感觉输入学习的。从这个意义上说,我们的系统——利用从多模态感官输入学习的自我先验生成伸手行为——类似于(Gallagher,1986;Hoffmann,2021)中提到的身体图式概念,支持行动规划和控制。
此外,即使在轨迹中途出现额外的触碰——例如来自右手本身的触碰——从而暂时增加与单点自我先验的不匹配,代理接受这种短期偏差以实现最终目标,即最小化总体自由能。这种强大、抗噪的
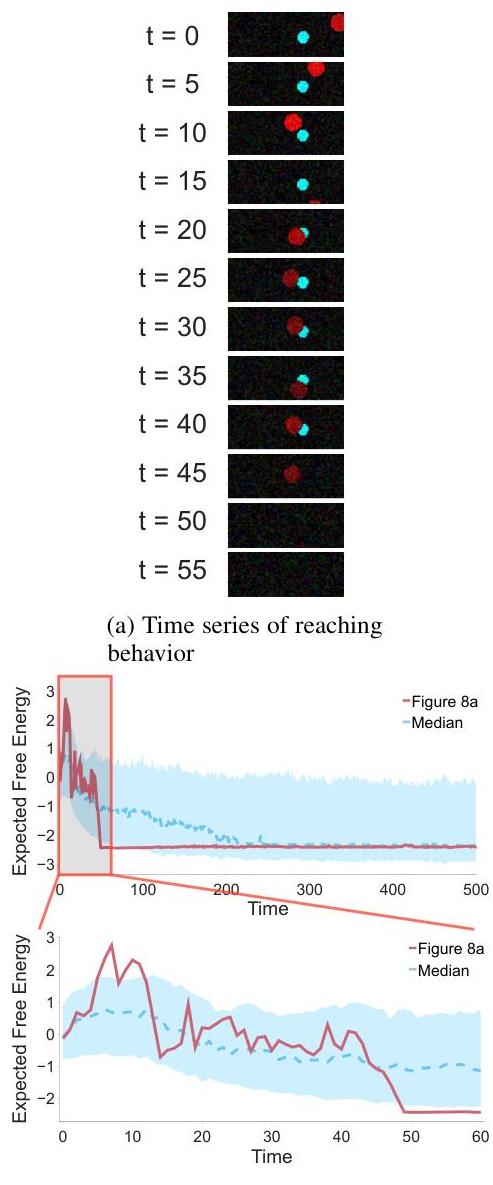
图8:当贴纸放置在连续环境中时的代理行为。(a)当贴纸(蓝色圆圈)附着时,手(红色圆圈)朝其移动,说明目标导向的伸手行为。该图可视化了代理的触觉矩阵,灰度触觉数据叠加了手和贴纸的彩色标记,以便清晰显示。(b)伸手拿贴纸减少了预期自由能,移除贴纸导致其最小化。阴影区域代表使用8个模型训练种子测试8个环境种子的64次实验的标准差。该图选择了种子14,以清楚地演示伸手行为。
容忍的目标导向行动序列表明,我们的代理在整个互动过程中保持了连贯的意图。
5 讨论
我们提出了自我先验作为一种从代理感官体验中自主形成的内在偏好。然后,我们将其应用于模拟婴儿代理中,并在主动推理框架内确认了目标导向行为的出现——特别是伸手拿贴纸。在本节中,为了阐明我们的工作对发育科学的贡献,我们首先
详细讨论了自我先验如何在现有的内在动机计算模型分类中定位。然后,我们提出了自我先验作为早期有意行为潜在起源的作用。之后,我们解释了我们的方法与以前尝试生成自发行为的研究有何不同,最后,我们讨论了这项工作的局限性。
5.1 内部稳态内在动机
自我先验代表了一个从外在动机中分离出来的内在动机项,这似乎有些违反直觉。此外,内在动机源于外部世界感官数据的想法可能看起来自相矛盾。我们认为这种混淆源于对外部和内部术语使用的不一致,这一点也被(Oudeyer & Kaplan, 2009)指出。在本文中,我们采用了他们推荐的分类,区分:
- 外部 vs. 内部,指的是奖励计算是在环境中还是在代理内部进行。
-
- 外在 vs. 内在,指的是奖励标准是由外部还是内部确定。
根据这些定义,任何外部奖励——例如机器学习任务中的游戏得分——都属于外在,因为它从代理外部提供,并带有预设阈值。同时,内部驱动可以是外在或内在的。如果代理根据其内部模型计算自己的奖励阈值——例如根据学习的世界模型测量“新信息增益”——则该驱动被认为是内在的。相比之下,尽管一开始可能会让人困惑,但内部却外在的动机是指代理检查其自身状态并直接根据外部固定的准则计算奖励,例如“维持电池水平在50%”。
- 外在 vs. 内在,指的是奖励标准是由外部还是内部确定。
因此,区分外在与内在动机的关键因素不是信息源自环境还是代理内部,而是谁设置了奖励计算的阈值。在这个意义上,预期自由能仍然是一个内部框架,因为代理本身计算了外在和内在组件。此外,这里引入的自我先验方法被视为内部内在动机,因为代理的内部模型(自我先验)直接计算并更新行为标准。
(Oudeyer & Kaplan, 2009)还引入了另一个分类轴——稳态与异态——并指出稳态内在动机确实存在。也就是说,如果代理的驱动方向是获取新信息,则构成异态形式的内在动机;然而,维持熟悉状态也可以被视为内在动机(稳态),因为代理内部定义了“熟悉度”设定点。
预期自由能框架通常将优选先验解释为与生存要求相关的观察结果(例如血糖或电池水平)。由于这些设定点不能随意更改,它们通常被认为是外在的,并且不明确与它们的稳态性质区分开来。然而,如果代理可以自由指定自己的设定点,我们可以将这些设定点分类为稳态内在动机。
因此,我们认为自我先验引发的动机是一种内部稳态内在动机——它旨在“维持或恢复从代理自身的感官体验中学到的参考模式”(表2)。这与传统的寻求新信息以学习的异态内在动机形成对比(例如,减少关于隐藏状态的不确定性)。相反,自我先验直接触发行动以解决与已经习得的身体模式的任何不匹配。在(Oudeyer & Kaplan, 2009)中,这类似于分布熟悉度动机(DFM),它驱动代理返回到反复遇到的感官配置。
5.2 早期有意行为的起源
婴儿最初主要依赖反射机制进行行动。然而,随着时间的推移,他们逐渐发展出(Mele & Moser, 1994)描述的“有意行为”,包括(i)一个判断如何处理传入刺激的动机系统和(ii)执行真正目标导向行动的能力。根据(Zaadnoordijk & Bayne, 2020),刺激驱动的意图首先出现,
表2:自我先验在动机分类中的定位
| 外在 | 内在 | ||
|---|---|---|---|
| 外在 | 异态 | ||
| 外部 | 游戏得分 | ( N / A ) (\mathrm{N} / \mathrm{A}) (N/A) | ( N / A ) (\mathrm{N} / \mathrm{A}) (N/A) |
| 内部 | 感官数据与固定值的差距 | 感官数据与自我先验的差距 | 通过感官数据获取信息增益 |
随后,随着经验的积累,更多的内源性意图出现。例如,新生儿依靠觅食反射获取喂养经验;后来,仅仅是看到奶瓶就能促使他们伸手喝奶(刺激驱动意图)。当他们意识到内部状态如饥饿时,他们会主动寻找奶瓶(内源性意图)。
随着时间的推移,为了认识到自己是独立实体,婴儿必须经历丰富的多模态冗余和时空关联的经验(Rochat, 1998)。顺序发展的有意行动可能自发地提供此类经验的机会。(Thelen等,1993)同样指出,婴儿最初既缺乏执行伸手动作的能力,也缺乏意图,而稳定意图的形成以及由这些意图驱动的主动探索促进了伸手的学习。然而,先前的研究并未详细探讨支撑刺激驱动意图和有意行动的神经结构。
与此同时,神经生理学证据表明,前扣带回皮层主要处理个体决策中的奖励相关错误,而后扣带回皮层处理与自传信息相关的不一致信号——例如自己的身体或过去的经历——并触发新行为(Brewer等,2013;Pearson等,2011)。我们提出的自我先验与此“自我相关预测”概念一致,表明当新输入无法满足这些预测时,系统会启动行动。换句话说,即使没有任何外部设计的目标,保存从过去经验中学习到的自我先验的内在驱动力也可以表现为类似婴儿持续触摸新发现的手臂上的贴纸的行为。这反映了皮亚杰关于初级循环反应的概念,重复尝试可以进一步完善意图,为计算研究婴儿有意行为起源提供了理论基础。
在我们的实验中,我们固定了自我先验的学习率。然而,过高的学习率可能导致过度反应(强迫性反应)对小变化,而过低的学习率可能导致对新刺激的漠不关心(冷漠)。未来的工作可以调查如何通过生物可变性建模更灵活的学习率,通过自我相关预测误差处理塑造不同的行为风格。
5.3 内在动机的计算模型
旨在计算上解决内在动机的方法主要在强化学习中进行了探索,其中设计高质量的奖励函数仍然是一个重大挑战。因此,内在动机已被提出作为一种手段,使代理更有效地探索环境并更好地推断奖励函数。然而,一个根本问题依然存在:代理如何在没有目标的环境中自主形成动机并生成行为?在这种情况下,什么样的价值引导代理的行动(Juechems & Summerfield,2019)?
另一种方法是稳态强化学习,在这种方法中,代理只需通过维持某些感官通道达到指定阈值即可生成一系列行为,而无需环境目标(Keramati & Gutkin,2011)。最近的研究通过深度神经网络将这一概念扩展到复杂场景,研究内部生理状态如何驱动行为(Yoshida等,2024)。在主动推理下,类似的机制出现:通过相对于内部设定点(表示为首选先验)最小化自由能,代理可以生成像伸手抓取目标之类的单一目标导向行为(Oliver等,2022)或协调重复行为(Matsumoto等,2022)。
然而,尽管这些方法看似无需外部奖励运作,大多数依赖于实验者提前固定参考值(例如设定点、首选先验)。因此,虽然
代理的奖励计算是内部的,但其设定点的最终来源是外部的。结果,这些系统并未完全解决“价值从何而来,代理如何自主建立价值?”这一基本问题。
为了让代理独立建立自己的价值函数,既不能预先确定外部奖励也不能预先确定内部设定点。但是,如果没有这些指标,很难跟踪进展或判断行为的效用,这就是为什么许多关于内在动机的研究仍主要将其用于促进外部任务的探索(Aubret等,2023)——较少关注代理如何自动生成和维持目标。
一些研究确实调查了纯粹由内在动机引发的行为,并在没有外部定义奖励的情景中对其进行了定性评估(Eysenbach等,2018;Pathak等,2017)。虽然这些突显了代理获取多样化技能或行为的过程,但它们通常涉及一种异态方法——持续寻求新颖状态。因此,一旦不确定性充分降低,进一步探索往往会减少,出现的新行为也更少。
主动推理提供了一个统一的理论框架,可以将外在和内在动机整合到自由能这一单一定量衡量标准下(Parr等,2022)。此外,(Biehl等,2018)表明,许多现有的内在动机方法可以在主动推理中被理解为改进后验的过程——这一观点让人联想到(Schmidhuber,2010),他将内在动机定义为寻求“更好的世界模型”。然而,这种改进后验的动机同样是异态的:它们促进探索直到不确定性得到解决,之后引发的行为显著减少。
最近,研究开始探索稳态形式的内在动机,其中代理自主定义自己的设定点,但目的是保持已学习的状态或过去的经验,而不是持续寻求新颖性。例如,(Marcel等,2022)提出了一种模型,首先学习自我触碰的潜在表示,然后将其用作设定点,引导当前观察接近最近的自我触碰状态,从而引发伸手行为。类似地,(Kim等,2023;Takemura等,2018)将机器人末端效应器的一步前向和逆向模型(从运动喃语中学习)作为行为设定点,并证明了这种模型可以在没有明确奖励的情况下生成朝远处目标伸手的行为。更接近我们方法的是,(Sajid等,2021)在自由能框架内引入了“习得偏好”的概念,并从语义上分析了减少观察与偏好之间不匹配的驱动力如何引发新行为。然而,这些方法尚未充分讨论如何将这些自我习得的设定点与传统的外在或基于信息增益的内在动机整合起来。
在本文中,我们在主动推理框架内解决了这些问题,提出了一种方法,即代理基于过去经验塑造自己的设定点,然后在传入感官偏离该学习到的内部模型时自发生成目标导向行为。我们的方法回答了“价值从何而来?”这个问题,建议“部分价值可能由代理积累的经验塑造”,展示了(i)代理维持自我定义的设定点而非遵循实验者强加的设定点;(ii)它仍然利用主动推理机制进行长期规划以最小化预期自由能;(iii)它可以理论上与现有的外在或异态内在动机整合。结果是一个全面的框架,在此框架内,代理的价值系统由内部塑造和维护,同时完全兼容既定的动机过程。
5.4 局限性和未来方向
尽管我们的研究提供了一个概念验证,但它受到若干限制。首先,我们在离散环境和低自由度(3-DoF)连续环境中测试了我们的方法。然而,真实的婴儿或机器人表现出远为复杂和多样化的感运动交互,强调需要将我们的框架扩展到更高维的状态和动作空间。特别是,未来的工作可以借鉴早期人类感运动经验(包括胎儿阶段)的模拟(Kim等,2022),以探索丰富的子宫内感运动输入如何塑造自我先验和目标导向行为,澄清在具身发育约束下可能出现的行动类型(Kuniyoshi,2019)。
此外,我们的实验集中在贴纸突然引入的场景中。这种选择有助于通过排除固定的外在
动机(例如外部规定的奖励标准)来孤立基于熟悉度的内在动机的效果。实际上,婴儿和机器人往往需要平衡多种驱动(例如能量稳态和基于新颖性的信息增益)。设计系统评估不同动机如何互补或冲突,并如何整合为连贯行为的实验仍然是未来研究的重要方向。
我们的研究表明,通过将基于可学习自我先验的内在稳态项与基于固定首选先验的外在项分离——这是先前工作中常见于预期自由能的——代理不仅可以生成旨在实现预定义目标的动作,还可以自发生成目标导向行为。然而,当前的一个限制是,虽然自我先验的使用通过预期自由能集成到策略生成中,但自我先验的学习是与变分自由能的学习分开进行的。
解决这种分离的一个潜在线索在于分层架构。具体来说,反映长期经验的高层次隐藏状态可能逐渐被学习,从中推断出的可能性分布可以作为低层次的自我先验。这不同于传统的分层推理,其中高层次仅学习先验并在较慢的时间尺度上确定动作以影响低层次(例如,
P
(
s
t
∣
s
t
−
1
,
a
t
−
1
)
=
Cat
(
B
a
t
−
1
)
P\left(s_{t} \mid s_{t-1}, a_{t-1}\right)=\operatorname{Cat}\left(\mathbf{B}_{a_{t-1}}\right)
P(st∣st−1,at−1)=Cat(Bat−1))。相反,它持续从低层次接收信息以学习先验,仅用于在长时间内形成自我先验(例如,
P
(
s
)
=
Cat
(
B
)
P(s)=\operatorname{Cat}(\mathbf{B})
P(s)=Cat(B))。
另一种可能性是,自我先验的学习不由皮质处理,而是由一个单独的记忆系统如海马体处理,因此可能需要与在自由能原则下提出的推理系统进行结构分离。这些开放假设的具体验证留给未来工作。
在离散环境中,我们看到放置贴纸并保持原地逐渐改变了自我先验,从而相应地改变了代理的行为。相比之下,在连续环境中,我们将遇到贴纸的概率固定在
5
%
5 \%
5%,有效地将自我先验学习与贴纸观察事件的演变脱钩。这是因为在学习自我先验模型时使用了存储过去数据而不考虑时间顺序的重放缓冲区,这使得难以研究自我先验随时间的增量变化。为了模拟刺激驱动意图如何在真实的婴儿或机器人中巩固为更内源性的意图形式,我们需要能够处理长时序依赖的分层状态空间模型(Friston等,2017)或基于变压器的架构(Vaswani等,2017),这些架构可以从扩展的时间序列中学习世界模型(Chen等,2022)。
6 结论
基于自由能原理和主动推理框架,我们证明了代理内在驱动学习和维持“自我先验”——类似于身体图式——即使在没有外部指定奖励的情况下也能引发目标导向行为。特别地,虽然传统的主动推理文献强调了异态内在动机(即寻求新信息),但我们的工作突出了稳态形式的内在动机——积极努力保持熟悉的感官体验。
使用模拟婴儿触摸和检查手臂上的贴纸作为示例,我们展示了如何通过内部驱动解决自我模型与传入数据之间的不匹配来表现行为,例如伸手和去除贴纸,而无需任何明确的奖励标准。这为发育心理学中的刺激驱动有意行为提供了计算解释,并暗示了其与后扣带回皮层神经生物学文献的相关性,后者处理与自传信息相关的错误。
未来的工作应(i)结合基于熟悉度和其他动机(外在和信息寻求)以测试多个驱动如何在一个单一的自由能框架内整合,以及(ii)将我们的方法扩展到更长的时间尺度和更复杂的物理环境中——例如高自由度机器人平台或全规模婴儿模拟——以研究意图的长期形成和细化。这对于捕捉有意行为的发展轨迹尤为重要。
致谢和资金披露
本研究得到了日本科学技术振兴机构(JST)PRESTO资助编号JPMJPR23S4的支持。
参考文献
Aubret, A., Matignon, L., & Hassas, S. (2023). An Information-Theoretic Perspective on Intrinsic Motivation in Reinforcement Learning: A Survey. Entropy, 25(2), 327.
Biehl, M., Guckelsberger, C., Salge, C., Smith, S. C., & Polani, D. (2018). Expanding the Active Inference Landscape: More Intrinsic Motivations in the Perception-Action Loop. Frontiers in neurorobotics.
Bigelow, A. E. (1986). The development of reaching in blind children. British Journal of Developmental Psychology, 4(4), 355-366.
Brewer, J., Garrison, K., & Whitfield-Gabrieli, S. (2013). What about the “Self” is Processed in the Posterior Cingulate Cortex? Frontiers in Human Neuroscience, 7.
Chen, C., Wu, Y.-F., Yoon, J., & Ahn, S. (2022). Reinforcement Learning with Transformer World Models. arXiv:2202.09481.
Chung, J., Gulcehre, C., Cho, K., & Bengio, Y. (2014). Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. arXiv:1912.01603.
Csikszentmihalyi, M. (1990). Flow: The psychology of optimal experience. New York: Harper & Row.
Di Domenico, S. I. & Ryan, R. M. (2017). The Emerging Neuroscience of Intrinsic Motivation: A New Frontier in Self-Determination Research. Frontiers in Human Neuroscience, 11.
Durkan, C., Bekasov, A., Murray, I., & Papamakarios, G. (2019). Neural spline flows. Advances in neural information processing systems, 32.
Eysenbach, B., Gupta, A., Ibarz, J., & Levine, S. (2018). Diversity is All You Need: Learning Skills without a Reward Function123. arXiv:1802.06070.
Friston, K. (2010). The free-energy principle: a unified brain theory? Nature Reviews Neuroscience, 11(2), 127-138.
Friston, K., FitzGerald, T., Rigoli, F., Schwartenbeck, P., O’Doherty, J., & Pezzulo, G. (2016). Active inference and learning. Neuroscience & Biobehavioral Reviews, 68, 862-879.
Friston, K. J., Parr, T., & de Vries, B. (2017). The graphical brain: Belief propagation and active inference. Network Neuroscience, 1(4), 381-414.
Gallagher, S. (1986). Body Image and Body Schema: A Conceptual Clarification. The Journal of Mind and Behavior, 7(4), 541-554.
Gopnik, A. (2009). The philosophical baby: What children’s minds tell us about truth, love & the meaning of life. Random House.
Haarnoja, T., Zhou, A., Abbeel, P., & Levine, S. (2018). Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In International conference on machine learning (pp. 1861-1870).: PMLR.
Hafner, D., Lillicrap, T., Ba, J., & Norouzi, M. (2020). Dream to Control: Learning Behaviors by Latent Imagination. arXiv:1912.01603.
Hafner, D., Lillicrap, T., Fischer, I., Villegas, R., Ha, D., Lee, H., & Davidson, J. (2019). Learning latent dynamics for planning from pixels. In International conference on machine learning (pp. 2555-2565).: PMLR.
Hoffmann, M. (2021). Body models in humans, animals, and robots: Mechanisms and plasticity. In Body schema and body image: New directions. (pp. 152-180). New York, NY, US: Oxford University Press.
Hoffmann, M., Chinn, L. K., Somogyi, E., Heed, T., Fagard, J., Lockman, J. J., & O’Regan, J. K. (2017). Development of reaching to the body in early infancy: From experiments to robotic models. In 2017 Joint IEEE International Conference on Development and Learning and Epigenetic Robotics (ICDL-EpiRob) (pp. 112-119).
Juechems, K. & Summerfield, C. (2019). Where Does Value Come From? Trends in Cognitive Sciences, 23(10), 836-850.
Kanazawa, H., Yamada, Y., Tanaka, K., Kawai, M., Niwa, F., Iwanaga, K., & Kuniyoshi, Y. (2023). Open-ended movements structure sensorimotor information in early human development. Proceedings of the National Academy of Sciences, 120(1), e2209953120.
Keramati, M. & Gutkin, B. (2011). A Reinforcement Learning Theory for Homeostatic Regulation. In Advances in Neural Information Processing Systems, volume 24: Curran Associates, Inc.
Kim, D., Kanazawa, H., & Kuniyoshi, Y. (2022). Simulating a Human Fetus in SoftUterus. In 2022 IEEE International Conference on Development and Learning (ICDL) (pp. 135-141)., D., Kanazawa, H., & Kuniyoshi, Y. (2023). 使用预测学习作为复杂动态中的感运动发展出现伸手行为. 在第11届动物和机器的适应性运动国际研讨会(AMAM2023)(pp. 144-145): 动物和机器的适应性运动组织委员会.
Kuniyoshi, Y. (2019). 通过胚胎期的行为和认知的具身涌现和发展融合自主性和社会性. 哲学交易皇家学会B: 生物科学, 374(1771), 20180031.
Marcel, V., O’Regan, J. K., & Hoffmann, M. (2022). 使用生成模型从自发的自我触碰中学习到达自身身体. 在2022年IEEE国际发展与学习会议(ICDL)(pp. 328-335).
Matsumoto, T., Ohata, W., Benureau, F. C. Y., & Tani, J. (2022). 扩展主动推理的目标导向规划和目标理解:通过模拟和物理机器人实验的评估. 熵, 24(4), 469.
Mazzaglia, P., Verbelen, T., & Dhoedt, B. (2021). 对比主动推理. 高级神经信息处理系统进展, 34, 13870-13882.
Mele, A. R. & Moser, P. K. (1994). 故意行动. Noûs, 28(1), 39-68.
Millidge, B. (2020). 深度主动推理作为变分策略梯度. 数学心理学杂志, 96, 102348.
Millidge, B., Tschantz, A., Seth, A. K., & Buckley, C. L. (2020). 关于主动推理与推理控制的关系. 在T. Verbelen, P. Lanillos, C. L. Buckley, & C. De Boom (编), 主动推理,计算机与信息科学通讯 (pp. 3-11). Cham: Springer International Publishing.
Oliver, G., Lanillos, P., & Cheng, G. (2022). 类人机器人上的主动推理实证研究. IEEE认知与发展系统汇刊, 14(2), 462-471.
Oudeyer, P.-Y. & Kaplan, F. (2009). 内在动机是什么?计算方法的分类. 前沿神经机器人, 1, 6.
Parr, T., Pezzulo, G., & Friston, K. J. (2022). 主动推理: 心理、大脑和行为中的自由能原则. MIT出版社.
Pathak, D., Agrawal, P., Efros, A. A., & Darrell, T. (2017). 自监督预测驱动的好奇心探索. 在国际机器学习会议 (pp. 2778-2787).: PMLR.
Pearson, J. M., Heilbronner, S. R., Barack, D. L., Hayden, B. Y., & Platt, M. L. (2011). 后扣带回皮层:适应变化世界的行为. 认知科学趋势, 15(4),
143
−
151
143-151
143−151.
Rochat, P. (1998). 婴儿的自我感知与行动. 实验脑研究, 123(1),
102
−
109
102-109
102−109.
Ryan, R. M. & Deci, E. L. (2000). 内在与外在动机: 经典定义与新方向. 当代教育心理学, 25(1), 54-67.
Sajid, N., Tigas, P., Zakharov, A., Fountas, Z., & Friston, K. (2021). 无奖励学习中探索与偏好满足的权衡. arXiv:2106.04316.
Schmidhuber, J. (2010). 创造力、乐趣和内在动机的正式理论 (1990-2010). IEEE自主心理发展汇刊, 2(3), 230-247.
Schulman, J., Moritz, P., Levine, S., Jordan, M., & Abbeel, P. (2015). 高维连续控制的广义优势估计. arXiv:1506.02438.
Shultz, T. R. (2013). 发育心理学中的计算模型. 在P. D. Zelazo (编), 牛津发育心理学手册, 第1卷: 身体与心灵. 牛津大学出版社.
Takemura, N., Inui, T., & Fukui, T. (2018). 基于前向和逆向变换交互的到达和指向发展的神经网络模型. 发育科学, 21(3), e12565.
Thelen, E., Corbetta, D., Kamm, K., Spencer, J. P., Schneider, K., & Zernicke, R. F. (1993). 到达的转变: 映射意图和内在动力学. 儿童发展, 64(4),
1058
−
1098
1058-1098
1058−1098.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2017). 注意力就是你所需要的. arXiv:1706.03762.
White, R. W. (1959). 动机再思考:能力的概念. 心理学评论, 66(5), 297.
Yoshida, N., Daikoku, T., Nagai, Y., & Kuniyoshi, Y. (2024). 通过直接优化稳态出现的综合行为. 神经网络, 177, 106379.
Zaadnoordijk, L. & Bayne, T. (2020). 故意代理的起源. psyArXiv:wa8gb.
Zaadnoordijk, L., Besold, T. R., & Cusack, R. (2022). 婴儿学习对无监督机器学习的启示. 自然机器智能, 4(6), 510-520.
Çatal, O., Wauthier, S., De Boom, C., Verbelen, T., & Dhoedt, B. (2020). 学习用于主动推理的生成状态空间模型. 前沿计算神经科学, 14.
参考论文:https://arxiv.org/pdf/2504.11075



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











