






张子辉
1
,
2
{ }^{1,2}
1,2 杨亚飞
1
,
2
{ }^{1,2}
1,2 温鸿涛
1
,
2
{ }^{1,2}
1,2 杨波
1
,
2
∗
{ }^{1,2 *}
1,2∗
1
{ }^{1}
1 香港理工大学深圳研究院
2
{ }^{2}
2 vLAR Group, 香港理工大学
zihui.zhang@connect.polyu.hk bo.yang@polyu.edu.hk
摘要
我们研究了在复杂点云中进行3D物体分割的难题,而无需使用3D场景的人工标签进行监督。现有的无监督方法通常依赖于预训练的2D特征相似性或外部信号(如运动)来将3D点分组为物体,但这些方法通常局限于识别简单的物体(如汽车),或者由于预训练特征缺乏“物体质”,其分割结果往往较差。在本文中,我们提出了一种新的两阶段流水线称为GrabS。我们的方法的核心概念是在第一阶段从物体数据集中学习生成性和判别性的物体中心先验作为基础,然后在第二阶段设计一个实体代理通过查询预训练的生成先验来学习发现多个物体。我们在两个真实世界数据集和一个新创建的合成数据集上广泛评估了我们的方法,展示了显著的分割性能,明显超越所有现有的无监督方法。
1 引言
自动驾驶、实体AI和混合现实等新兴应用需要精确的语义3D场景理解。特别是,在3D点云中识别复杂物体的能力对于机器推理和与真实环境交互至关重要。现有的解决3D物体分割问题的方法主要依赖于密集或稀疏的人工标签进行3D监督(Wang等人,2018;Schult等人,2023),或大规模图像/语言注释进行2D-3D监督(Takmaz等人,2023;Yin等人,2024)。尽管它们已经取得了出色的分割结果,但收集所需的大规模注释非常耗时,使得它们在实际应用中不够吸引人且通用性较低。
为了克服这一限制,一些无监督方法试图通过依赖启发式(如点法向量/颜色/运动分布)(Zhang等人,2023;2024;Song & Yang,2022;2024)或将自监督预训练点特征的相似性(通常从2D图像重新投影)分组为3D点来实现物体分组。尽管取得了令人鼓舞的结果,但这些方法通常只能识别简单物体(如自动驾驶场景中的汽车),或者由于预训练特征缺乏“物体质”,其分割物体的质量往往较差。
在本文中,我们的目标是设计一个通用的流水线,能够在不使用任何昂贵的3D场景人工标签进行监督的情况下,精确地识别3D点云中的复杂物体。然而,这是极具挑战性的,因为它涉及两个基本问题:1)什么是物体(即,物体先验)?以及2)如何有效地估计复杂场景中的多个物体?事实上,在真实的3D世界中,这甚至更难,因为同一类别的不同物体(例如椅子)可能由于严重的遮挡、不同的方向位置和传感器噪声表现出截然不同的形态。这意味着:1)尚未定义或学习的物体先验应在潜在空间中具有判别性、鲁棒性和连续性,2)尚未设计的估计策略应考虑物体探索过程中可能出现的漏检情况。
基于此动机,我们引入了一个包含两个自然阶段的新学习框架:1)3D物体先验学习,随后是2)无需人工标签监督的3D场景物体估计。如图1左块所示,在第一阶段,我们旨在训练一个以物体为中心的网络,从单个物体形状(如ShapeNet (Chang等人,2015))中学习判别性和鲁棒性的物体先验。在第二阶段,如图1右块所示,我们引入一个多物体估计网络,仅通过第一阶段学习到的物体先验来推断输入点云中的多个物体,而无需人工标签进行训练。
对于以物体为中心的网络,为了在潜在遮挡、噪声和混乱物体方向下学习所需的物体先验,我们选择学习一个以物体为中心的生成模型。具体来说,给定一个物体点云,网络的目标是通过现有技术(如变分自动编码器(VAE)(Kingma & Welling,2014) 和扩散模型(Ho et al., 2020))估计条件潜在分布。期望潜在代码对特定视角是唯一的,并且网络可以回归相对于规范姿态的物体方向。这样,学习到的生成性物体先验可以对遮挡或噪声具有鲁棒性,而方向估计能力则使学习到的先验能够区分不同方向的物体。
关于多物体估计网络,我们的目标是在场景级点云中尽可能多地发现单个物体,但仅依赖于我们预训练的生成性物体中心网络。我们的见解是,给定从输入场景点云裁剪出的一组点的子体积,如果它恰好包含一个单一的有效物体,那么它的潜在先验应该能够恢复/生成一个合理的物体形状和方向,从而准确地与输入子集对齐。否则,该输入子体积应被丢弃或其位置和大小应更新直到找到有效物体。同时,一旦找到有效物体,网络应该能够相应地检测所有其他相似物体,而不是需要过多搜索。为了实现这一目标,我们为网络引入了两个并行分支,1)一个物体发现分支,创新地将其公式化为通过强化学习(RL)与3D场景点云探索和交互的实体代理,同时从我们预训练的生成性物体中心网络接收奖励,以及2)一个由发现的伪物体标签监督的物体分割分支。值得注意的是,一旦分割分支训练良好,基于实体代理的发现分支就会被丢弃,从而使整个多物体估计网络在推理期间高效。
我们的框架名为GrabS,通过物体中心网络学习生成物体先验,并训练一个实体代理来发现物体,最终使我们能够有效地分割场景点云中的多个物体。最接近我们工作的是EFEM(Lei等人,2023),但其学习到的物体先验不是生成性的,物体发现策略严重依赖于启发式来搜索有限数量的物体。我们的贡献如下:
- 我们介绍了一种用于3D物体分割的两阶段学习流水线。设计了一个以物体为中心的生成模型来学习判别性和鲁棒性的物体先验。
-
- 我们提出了一个多物体估计网络,通过训练一个新的设计实体代理与3D场景交互并从预训练的生成性物体中心先验网络接收奖励,从而有效地发现单个物体,无需在训练中使用人工标签。
-
- 我们在多个数据集上展示了优越的物体分割结果,并明显超越基线。我们的代码和数据可在 https://github.com/vLAR-group/GrabS 获取
2 相关工作
全监督/弱监督3D物体分割:在全监督3D点云物体分割方面取得了显著进展,包括自底向上点聚类方法(Wang等人,2018;Han等人,2020;Chen等人,2021;Vu等人,2022),自顶向下检测方法(Hou等人,2019;Yi等人,2019;Yang等人,2019;He等人,2021;Shin等人,2024),以及基于Transformer的方法(Jiahao Lu等人,2023;Lai等人,2023;Schult等人,2023;Sun等人,2023;Kolodiazhnyi等人,2024)。许多后续方法利用相对
弱的标签,例如3D边界框(Chibane等人,2022;Tang等人,2022)或物体中心(Griffiths等人,2020)来识别3D物体。虽然在公共3D数据集上取得了优异的准确性,但它们主要依赖于费力的人工标注来训练神经网络。
带自监督/监督2D/3D特征的3D物体分割:最近,随着自监督预训练技术和完全监督基础模型的发展,一系列方法(Ha & Song, 2022; Lu等人, 2023; Takmaz等人, 2023; Liu等人, 2023; Nguyen等人, 2024; Yan等人, 2024; Roh等人, 2024; Boudjoghra等人, 2024; Tai等人, 2024; Yin等人, 2024)被开发出来,利用预训练的2D/3D或语言特征(Xie等人, 2020; Caron等人, 2021; Radford等人, 2021; Kirillov等人, 2023)作为监督信号,在封闭或开放世界的数据库中发现3D物体。尽管显示出有希望的结果,但这些方法仍然依赖于2D/3D领域或对齐视觉-语言数据对的大规模注释数据,使其在实际应用中成本高昂且不具吸引力。
无监督3D物体分割:为了避免数据标注,一些最近的方法被提出,依靠启发式(如点法向量/颜色/运动分布)(Zhang等人,2023;2024;Song & Yang,2022;2024)或2D领域的预训练特征相似性(Rozenberszki等人,2024;Shi等人,2024)来发现3D物体。然而,它们识别复杂3D物体的能力往往较差。
3D物体中心先验学习:为了学习物体中心先验,大多数方法通常训练一个确定性的重建网络来预测不同表示形式的3D物体,例如网格(Yang等人,2018)、点云(Fan等人,2017)、符号距离场(SDF)(Park等人,2019)和非符号距离场UDF(Chibane等人,2020),而另一系列工作(Achlioptas等人,2018;Kim等人,2021;Klokov等人,2020;Luo & Hu,2021;Chou等人,2023;Li等人,2023a;Zeng等人,2022)训练一个生成网络来使用生成对抗网络(GAN)(Goodfellow等人,2014)、变分自动编码器(VAE)(Kingma & Welling,2014)、归一化流(Kim等人,2020)或扩散模型(Ho等人,2020)学习物体形状分布。这些方法通常旨在生成各种单个3D物体。相比之下,我们的框架并不是主要针对3D生成,而是展示发现多个3D物体的能力。
3 GRABS
3.1 总览
我们的框架包含两个阶段/网络。物体中心网络旨在从一组单独的3D物体(例如ShapeNet(Chang等人,2015)中的数千把椅子)中学习物体级别的生成先验。在该物体中心网络充分训练并冻结后,我们的最终目标是使用它来优化另一个多物体估计网络,以便在复杂的3D场景点云(例如ScanNet(Dai等人,2017)中的数千个3D房间)中发现尽可能多的相似物体。两个网络的详细信息将在第3.2节和第3.3节中讨论。
3.2 物体中心网络
给定一组通常带有规范姿态的现有数据集中收集的单独3D物体,一个特定物体被表示为 O ∈ R M × 3 \boldsymbol{O} \in \mathcal{R}^{M \times 3} O∈RM×3,其中 M M M 表示具有三个坐标通道 x y z x y z xyz 的3D点的数量。本文中忽略其他可能的特征如RGB或法线以简化处理。我们的物体中心网络包含以下两个模块,并将在这些3D物体上进行训练。
物体方向估计模块:我们的最终目标是在3D场景点云中分割潜在物体,但这些物体通常位于未知的姿态。这意味着我们的物体中心网络应首先能够推断物体相对于规范姿态的各种方向。为此,我们引入一个神经模块
f
R
f_{R}
fR,直接回归输入物体点云的方向或相对于规范姿态的观察角度的逆。
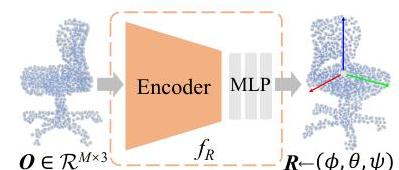
图2:物体方向估计模块。
如图2所示,给定一个物体点云
O
\boldsymbol{O}
O,我们将其输入到一个编码器以获得一个128维的全局向量,随后通过多层感知机(MLPs)直接回归三个

图3:基于VAE和扩散模型的物体生成先验学习模块。
方向参数
R
←
(
ϕ
,
θ
,
ψ
)
\boldsymbol{R} \leftarrow(\phi, \theta, \psi)
R←(ϕ,θ,ψ)。为了简化起见,我们采用PointNet++(Qi等人,2017)并在每个块中加入自注意力层作为我们的编码器,尽管也可以使用其他复杂的骨干网络,之后应用L1损失(Ke等人,2020)。为了训练这个模块,我们通过随机旋转ShapeNet中的规范姿态的合成物体来创建足够的训练对。神经架构和数据集准备的详细信息见附录A。
物体生成先验学习模块:再次,我们的最终目标是在3D场景中识别多个物体,但这些物体通常伴有噪声、自身或相互遮挡以及领域转移。一种幼稚的解决方案是通过创建无数样本来增强现有的物体级数据集进行训练,但这在数据效率上很低。我们认为,学习一个生成模块
f
G
f_{G}
fG更为可取,因为它本质上能够从适量的3D物体中捕获更鲁棒和连续的潜在分布,正如我们在第4.4节消融实验中验证的那样。
如图3左块所示,我们采用VAE框架(Kingma & Welling, 2014)来学习条件潜在分布。特别地,该模块将一个规范姿态的物体点云
O
^
\hat{\boldsymbol{O}}
O^作为输入到编码器,学习一个128维的潜在分布
N
(
μ
,
σ
2
)
\mathcal{N}\left(\boldsymbol{\mu}, \boldsymbol{\sigma}^{\mathbf{2}}\right)
N(μ,σ2)。编码器架构与我们的物体方向估计模块相同。采样的潜在代码随后被送入MLPs以学习SDF(Park等人,2019)。该SDF解码器完全遵循EFEM(Lei等人,2023)。如图3右块所示,我们的模块也灵活地采用流行的扩散模型作为替代方案。按照Diffusion-SDF(Chou等人,2023),我们的扩散模型变体学习去噪潜在代码并与我们的VAE变体联合训练。编码器/解码器和VAE/扩散层的所有细节提供在附录A中。
训练与测试:我们的物体方向估计模块
f
R
f_{R}
fR和物体生成先验学习模块
f
G
f_{G}
fG都在物体数据集上以完全监督的方式简单训练。由于我们的最终目标是利用预训练的
f
R
f_{R}
fR和
f
G
f_{G}
fG进行多物体分割,因此测试其在基准上生成高质量单个物体的能力并不重要。
3.3 多物体估计网络
在物体数据集上充分训练物体中心网络后,我们的核心目标是在复杂场景点云上分割许多相似物体,而无需人工标签进行训练。给定一个单一场景点云,一个简单的解决方案是随机裁剪许多不同位置和不同体积大小的点子体积,然后将这些子体积输入到我们预训练的物体中心网络中,获取它们的方向并随后进行形状重建。通过验证每个子体积是否有一组可以重建的点,我们可以将完美重建的点集视为发现的物体。然而,这种随机裁剪极其低效,因为缺乏合适的策略。实际上,直接学习子体积参数(如回归物体边界框)也不可行,本质上是因为裁剪操作是不可微分的。为此,我们引入了一个新颖的多物体估计网络,通过实体代理发现物体。该网络有两个共享骨干的并行分支。
给定一个输入场景点云
P
∈
R
N
×
3
\boldsymbol{P} \in \mathcal{R}^{N \times 3}
P∈RN×3,我们首先将其输入到一个骨干网络(未预训练)
f
bone
f_{\text {bone }}
fbone ,获取每点特征
F
∈
R
N
×
128
\boldsymbol{F} \in \mathcal{R}^{N \times 128}
F∈RN×128,这将在下面讨论的两个分支中使用。为了简化起见,我们采用SparseConv(Graham等人,2018)作为骨干。
作为实体代理的对象发现分支:由于训练中缺乏人工标签,发现对象实际上是一个试错过程。在这方面,我们将其实现为一个实体代理,通过强化学习(RL)主动搜索对象,这也无需密集或连续的标签。因为我们的预训练对象中心网络固有地具有丰富的对象先验,并能作为对象性的指示器,所以它自然适合充当奖励生成器。我们设置实体代理学习管道如下,包括代理及其动作空间的定义、策略网络、奖励设计和训练损失。
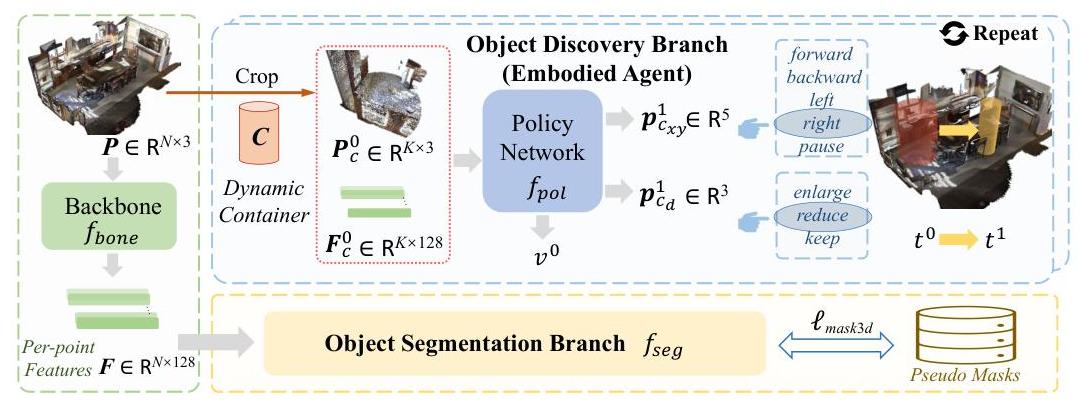
图4:多对象估计网络的框架。
- 实体代理:一个雄心勃勃的代理可以直接在动作空间中发现对象掩码,但由于3D场景点数的指数增长,探索成本会呈指数增加。因此,我们选择学习较少的参数。具体而言,我们在3D场景空间中创建了一个称为动态容器 C \boldsymbol{C} C的代理。为了简化起见,我们选择它为一个圆柱体,高度不受限制,并通过其投影在 x y x y xy平面上的中心和直径来参数化,即 C ← [ C x , C y , C d ] \boldsymbol{C} \leftarrow\left[C_{x}, C_{y}, C_{d}\right] C←[Cx,Cy,Cd]。这个代理预计从初始大小和随机位置开始,然后根据策略网络在其动作空间中动态改变其参数,并通过查询我们的预训练对象中心网络接收奖励,最终移动到一个有效的对象。
- 动作空间:针对三个参数 [ C x , C y , C d ] \left[C_{x}, C_{y}, C_{d}\right] [Cx,Cy,Cd],我们定义了以下两组动作。为了加速探索,两组动作在每个时间戳上同时执行。
- 第一组:动态容器将向前或向后移动以更新 C x C_{x} Cx,向左或向右移动以更新 C y C_{y} Cy,每次移动都以固定且预定义的步长 Δ s \Delta s Δs进行,或者保持静止不动。在探索过程中,动态容器将在每个时间戳上只选择五个动作中的一个来更新其两个位置参数 [ C x , C y ] \left[C_{x}, C_{y}\right] [Cx,Cy]。
-
- 第二组:动态容器将通过固定且预定义的比例 α \alpha α增大或减小其直径 C d C_{d} Cd以更新当前体积大小,或者保持不变。在探索过程中,容器将在每个时间戳上只选择三个动作中的一个来调整其大小参数 C d C_{d} Cd。
- 策略网络:如图4最左侧块所示,我们拥有输入场景
P
\boldsymbol{P}
P的每点特征
F
\boldsymbol{F}
F。假设容器代理在时间
t
0
t^{0}
t0处随机初始化参数
[
C
x
0
,
C
y
0
,
C
d
0
]
\left[C_{x}^{0}, C_{y}^{0}, C_{d}^{0}\right]
[Cx0,Cy0,Cd0],我们裁剪容器内的对应3D点和特征,分别记为
P
c
0
∈
R
K
×
3
\boldsymbol{P}_{c}^{0} \in \mathcal{R}^{K \times 3}
Pc0∈RK×3和
F
c
0
∈
R
K
×
128
\boldsymbol{F}_{c}^{0} \in \mathcal{R}^{K \times 128}
Fc0∈RK×128,其中
K
K
K代表点的数量,并可能在未来的时间戳上变化。
P
c
0
\boldsymbol{P}_{c}^{0}
Pc0和
F
c
0
\boldsymbol{F}_{c}^{0}
Fc0被视为时间
t
0
t_{0}
t0的容器状态特征,并被输入到我们基于注意力的策略网络
f
p
o
l
f_{p o l}
fpol中,直接预测时间
t
1
t^{1}
t1时两组动作的策略,分别记为
p
c
x
y
1
∈
R
5
\boldsymbol{p}_{c_{x y}}^{1} \in \mathcal{R}^{5}
pcxy1∈R5和
p
c
d
1
∈
R
3
\boldsymbol{p}_{c_{d}}^{1} \in \mathcal{R}^{3}
pcd1∈R3。我们还并行估计一个状态值
v
0
v^{0}
v0,如图4上部块所示。根据预测的策略,代理将在下一个时间戳执行相应的动作,未来的探索将重复此过程,直到代理停止。请注意,在训练过程中,容器的未来步骤更有可能接近一个有效的对象,尽管其第一步总是随机初始化。

图5:从我们预训练的对象中心网络生成容器奖励的步骤。
4) 通过预训练对象中心网络设计奖励:在时间
t
0
t^{0}
t0,给定容器状态特征
P
c
0
\boldsymbol{P}_{c}^{0}
Pc0,即裁剪的点子集,我们将查询它与我们在第3.2节中预训练的对象中心网络,按照以下步骤和图5所示获取奖励
r
0
r^{0}
r0。
- 步骤 #1:点子集 P c 0 \boldsymbol{P}_{c}^{0} Pc0首先输入到预训练的对象方向模块 f R f_{R} fR,得到其姿态 R c 0 \boldsymbol{R}_{c}^{0} Rc0。然后根据 P ˙ c 0 ← P c 0 ∘ R c 0 \dot{\boldsymbol{P}}_{c}^{0} \leftarrow \boldsymbol{P}_{c}^{0} \circ \boldsymbol{R}_{c}^{0} P˙c0←Pc0∘Rc0将子集对齐到规范姿态。
-
- 步骤 #2:对齐的点子集 P ‾ c 0 \overline{\boldsymbol{P}}_{c}^{0} Pc0输入到预训练的对象生成先验模块 f G f_{G} fG。通过SDF解码器查询这 K K K个点,我们将获得对应的逐点距离值 D ‾ c 0 ∈ R K × 1 \overline{\boldsymbol{D}}_{c}^{0} \in \mathcal{R}^{K \times 1} Dc0∈RK×1。
-
- 步骤 #3:我们将通过将 D ‾ c 0 \overline{\boldsymbol{D}}_{c}^{0} Dc0的绝对距离值二值化计算候选对象掩码 M c 0 ∈ R K × 1 \boldsymbol{M}_{c}^{0} \in \mathcal{R}^{K \times 1} Mc0∈RK×1,阈值设为 δ d \delta_{d} δd。对于那些绝对距离值小于 δ d \delta_{d} δd的点,它们被视为候选对象表面点。候选对象点物理上被剔除(用操作*表示): P ‾ c 0 ← P ‾ c 0 ∗ M c 0 \overline{\boldsymbol{P}}_{c}^{0} \leftarrow \overline{\boldsymbol{P}}_{c}^{0} * \boldsymbol{M}_{c}^{0} Pc0←Pc0∗Mc0。
-
- 步骤 #4:最后,我们将这些对象点 P ‾ c 0 \overline{\boldsymbol{P}}_{c}^{0} Pc0输入到我们的预训练对象生成先验模块 f G f_{G} fG并通过Marching Cubes在SDF解码器上重建完整对象形状。如果输入候选对象 P ‾ c 0 \overline{\boldsymbol{P}}_{c}^{0} Pc0与恢复的完整形状(采样密集点)之间的Chamfer距离小于阈值 δ c \delta_{c} δc,则奖励 r 0 r^{0} r0分配为正分数,例如 r 0 ← 10 r^{0} \leftarrow 10 r0←10,否则分配为负分数,例如 r 0 ← − 1 r^{0} \leftarrow -1 r0←−1。值得注意的是,对于具有正分数的候选对象,其掩码始终存储在一个外部列表中,并被视为伪对象掩码以训练我们的对象分割分支。
- 训练损失:对于动态容器,给定其初始状态: P c 0 \boldsymbol{P}_{c}^{0} Pc0和 F c 0 \boldsymbol{F}_{c}^{0} Fc0,这些是从主干 f bone f_{\text {bone }} fbone 在时间 t 0 t^{0} t0获得的,我们通过策略网络 f p o l f_{p o l} fpol得到其预测策略和状态值: { p c t q 1 , p c d 1 , c 0 } \left\{\boldsymbol{p}_{c_{t q}}^{1}, \boldsymbol{p}_{c_{d}}^{1}, c^{0}\right\} {pctq1,pcd1,c0},并通过我们的预训练对象中心网络得到奖励 r 0 r^{0} r0。根据预测的策略执行动作,我们收集足够数量的轨迹来优化主干和策略网络,使用现有的PPO损失(Schulman等人,2017)。
( f bone , f pol ) ← ℓ p p o \left(f_{\text {bone }}, f_{\text {pol }}\right) \leftarrow \ell_{p p o} (fbone ,fpol )←ℓppo
得益于学习到的对象中心先验和我们创造性的基于实体代理的对象检测公式化,这个对象发现分支可以从复杂的场景点云中成功识别多个对象。在实现中,我们将3D场景划分为较小的块,让容器在它们内部并行搜索,从而加快探索速度。有关代理初始化、策略网络、奖励、损失函数、并行化和超参数的更多细节请参阅附录K。
对象分割分支:给定输入场景点云
P
\boldsymbol{P}
P,在动态容器探索过程中,我们会积累一系列对象掩码作为伪标签。显然,这些对象对我们直接训练分割分支非常有价值,因此即使它们可能被我们的动态容器代理遗漏,类似对象也更有可能被检测到。为此,如图4下块所示,我们的对象分割分支
f
seg
f_{\text {seg }}
fseg 以每点特征
F
\boldsymbol{F}
F作为输入,然后严格遵循Mask3D(Schult等人,2023)直接预测整个输入点云
P
\boldsymbol{P}
P的一组类别无关的对象掩码。应用来自Mask3D(Schult等人,2023)的现有监督损失来优化主干和分割分支。有关神经架构、损失函数和训练设置的更多细节请参阅附录L。
( f bone , f seg ) ← ℓ mask3d \left(f_{\text {bone }}, f_{\text {seg }}\right) \leftarrow \ell_{\text {mask3d }} (fbone ,fseg )←ℓmask3d
总体而言,我们的框架GrabS首先学习一个对象中心网络用于对象姿态对齐,接着在现有的对象级数据集上进行生成形状先验学习。以学到的先验为基础,我们引入了一个新颖的多对象估计网络,无需人类标签即可从复杂的3D场景点云中分割多个独立对象。
4 实验
数据集:我们在三个数据集上进行评估:1)具有挑战性的现实世界ScanNet数据集(Dai等人,2017),包含1201/312/100个室内场景用于训练/验证/测试;2)现实世界的S3DIS数据集(Armeni,2017),包括6个区域的室内场景;3)我们自己的合成数据集,包含4000/1000个训练/测试场景。按照EFEM(Lai等人,2023)的做法,我们首先在ShapeNet上训练对象中心网络,然后在场景数据集上进行对象分割。
基线:我们与以下相关方法进行比较。1)EFEM(Lei等人,2023):这是我们最接近的工作,它同样从ShapeNet学习对象先验,然后在训练时不使用场景注释进行对象分割。2)
E
F
E
M
mask3d
\mathbf{E F E M}_{\text {mask3d }}
EFEMmask3d :我们进一步构建此基线,通过使用EFEM发现的伪标签训练一个Mask3D模型。该模型保持与我们的对象分割分支相同的架构和训练设置。3)Unscene3D(Rozenberszki等人,2024):这是一种无监督的3D对象分割方法,利用2D预训练
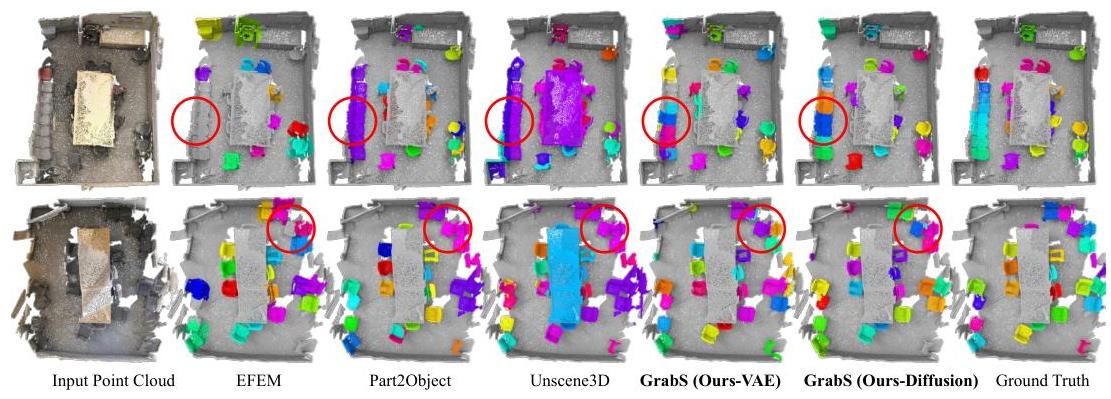
图6:ScanNet验证集上的定性结果。红圈突出显示差异。
DINO特征以提供伪3D注释来训练检测器。4)Part2Object(Shi等人,2024):这是一种无监督方法,也结合了DINO特征。为参考,我们还包括了完全监督的3D方法Mask3D(Schult等人,2023),以及最近的完全监督2D/语言模型OpenIns3D(Huang等人,2024)和SAI3D(Yin等人,2024)。
关于我们的流水线,一旦对象发现分支通过RL训练良好,在测试时,策略网络可以通过查询冻结的对象中心网络(例如,我们的VAE版本)在点云上发现多个对象。直观上,给定更多的轨迹,对象发现分支很可能识别更多的对象。为了比较,我们直接测试了我们训练良好的对象发现分支,分别给予50/100/300/600条轨迹,记为GrabS(Ours-VAE) ) d 1 × 50 )_{\mathrm{d} 1 \times 50} )d1×50。注意,原始EFEM在每个场景发现对象时使用了600条轨迹。
指标:评估指标包括不同IoU阈值下的标准平均精度(AP)、召回率(RC)和精确度(PR)得分。
4.1 在ScanNet上的评估
按照EFEM(Lei等人,2023)的设置以确保公平比较,我们在ShapeNet的椅子类别上训练一个对象中心网络,随后在ScanNet的训练集上以无监督方式训练一个多对象估计网络。我们仅在验证集和在线隐藏测试集上的椅子上评估性能,将所有预测的掩码视为椅子。
结果与分析:表1和图6展示了定量和定性结果。我们可以看到:1)我们的方法显著优于最接近的工作EFEM(Lai等人,2023)。2)对于另外两种无监督方法Unscene3D(Rozenberszki等人,2024)和Part2Object(Shi等人,2024),我们为它们的预测掩码分配真实类别标签,并排除所有非椅子预测。我们明显在所有指标上超越它们,证明了我们方法的优越性。
表2比较了ScanNet隐藏测试集上的结果。可以看到,我们的方法显著优于EFEM,并达到早期完全监督方法3D-BoNet(Yang等人,2019)的接近分数,展示了我们无监督学习方案的巨大潜力。不过,我们也注意到我们的方法在验证集和隐藏测试集之间存在性能差距。我们推测这可能是由于两组之间的分布差距引起的,因为完全监督方法Mask3D在两组上也显示出明显的性能差距。随着未来收集更多3D对象和场景数据集,我们相信域差距可以缩小。更多定性结果请参见附录N。
4.2 在S3DIS上的评估
类似于ScanNet数据集,我们仅在椅子类别上进行评估。为了公平比较,我们完全遵循现有的两种无监督方法Unscene3D(Rozenberszki等人,2024)和Part2Object(Shi等人,2024)在S3DIS上进行跨数据集验证。具体而言,我们直接使用在第4.1节中训练的多对象估计网络在S3DIS的测试集上进行评估。注意,基线EFEM没有训练阶段,根据其设计直接应用于S3DIS的测试集。
表1:我们方法和基线在ScanNet验证集上的定量结果。
| AP(%) | AP50(%) | AP25(%) | RC(%) | RC50(%) | RC25(%) | PR(%) | PR50(%) | PR25(%) |
|---|---|---|---|---|---|---|---|---|
| 3D Supervised | Mask3D (Schult et al., 2023) | 82.9 | 94.4 | 97.0 | - | - | - | - |
| 2D Foundation | OpenIns3D (Huang et al., 2024) | 66.7 | 82.4 | 85.7 | - | - | - | - |
| Model Supervised | SAUD (Yin et al., 2024) | 38.5 | 62.5 | 81.2 | 54.3 | 79.9 | 95.4 | 38.1 |
| Unsupervised | Unscene3D (Rosenberecki et al., 2024) | 37.2 | 62.4 | 79.2 | 51.7 | 70.4 | 84.1 | 18.7 |
| Part2Object (Shi et al., 2024) | 34.4 | 56.8 | 73.9 | 46.4 | 65.5 | 78.5 | 45.5 | |
| EFEM (Lei et al., 2023) | 24.6 | 50.8 | 61.3 | |||||
| EFEM trend 3 / { }_{\text {trend } 3 \text { / }} trend 3 / | 38.8 | 55.1 | 63.8 | 52.4 | 68.7 | 80.8 | 18.8 | |
| GrahS (Ours-VAE) Res100 { }_{\text {Res100 }} Res100 | 26.3 | 50.7 | 56.9 | 36.0 | 54.3 | 60.6 | 55.3 | |
| GrahS (Ours-VAE) Res100 { }_{\text {Res100 }} Res100 | 26.9 | 51.2 | 59.1 | 35.6 | 53.9 | 60.3 | 53.6 | |
| GrahS (Ours-VAE) Res100 { }_{\text {Res100 }} Res100 | 28.5 | 55.2 | 66.8 | 39.3 | 60.8 | 69.5 | 46.5 | |
| GrahS (Ours-VAE) Res100 { }_{\text {Res100 }} Res100 | 28.7 | 56.2 | 66.9 | 39.5 | 61.6 | 69.5 | 45.9 | |
| GrahS (Ours-VAE) | 46.7 | 71.5 | 82.9 | 53.2 | 74.5 | 85.2 | 52.1 | |
| GrahS (Ours-Diffusion) | 47.1 | 70.6 | 81.1 | 52.9 | 73.3 | 82.9 | 54.9 |
表2:我们方法和基线在ScanNet隐藏测试集上的定量结果。
| AP(%) | AP50(%) | AP25(%) |
|---|---|---|
| 3D Supervised | 3D-BoNet (Yang et al., 2019) | 34.5 |
| SoftGroup (Vu et al., 2022) | 69.4 | |
| Mask3D (Schult et al., 2023) | 73.7 | |
| Unsupervised | EFEM (Lei et al., 2023) | 20.2 |
| GrahS (Ours-VAE) | 29.0 | |
| GrahS (Ours-Diffusion) | 28.5 |
结果与分析:如表3和表4所示,我们的方法总体上显著优于所有无监督基线,尽管Unscene3D和Part2Object从训练良好的强大DINO模型中提取了特别强的视觉特征。仔细查看图7中的定性结果,我们可以发现:1)EFEM很可能会错过检测对象,主要是因为其对象发现阶段依赖于启发式方法,而不是像我们这样的通用检测器。2)Unscene3D和Part2Object在分离彼此靠近的相似对象时遇到困难,或者倾向于将对象过度分割成部分。这主要是因为预训练的2D DINO特征未能捕捉到细致的对象中心表示,尽管这些特征提供了对象位置和粗略形状的提示。相比之下,我们的方法学习了辨别性和鲁棒性的3D对象中心先验,这为多对象估计网络提供了精确的信号以识别对象。更多定量和定性结果请参见附录O。
表3:S3DIS Area-5上的跨数据集验证定量结果。
| Unsupervised | Unscene3D (Rosenberecki et al., 2024) | 42.6 | 63.4 | 80.3 | 51.9 | 68.6 | 83.3------
| 17.4 | 23.5 | 27.7 | 30.0 | 50.5 | 76.4 | 45.2 | 64.7 | 82.6 | 43.5 | 62.5 | 80.1 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| ------ EFEM (Lei et al., 2023) | 14.9 | 35.7 | 45.3 | 18.6 | 36.0 | 45.3 | 43.6 | 92.1 | 100.0 | ||
| GrahS (Ours-VAE) | 46.4 | 66.2 | 73.8 | 51.0 | 67.1 | 74.0 | 68.5 | 91.5 | 97.0 | ||
| GrahS (Ours-Diffusion) | 44.2 | 58.0 | 62.6 | 45.7 | 58.9 | 63.2 | 70.8 | 91.6 | 96.4 |
4.3 在合成数据集上的评估
尽管我们在第4.1节和第4.2节中仅在椅子类别上进行实验以与基线公平比较,但我们的方法设计上对任何对象类别都是未知的。为了进一步评估我们方法在通过单个网络发现多类对象方面的有效性,我们选择使用ShapeNet中的对象创建一个合成房间数据集。
具体来说,我们分别创建了4000/1000个用于训练/测试的3D室内房间(场景)。为了避免数据泄露,对于每个训练场景,我们仅从ShapeNet的验证集中选择3D对象,而对于每个测试场景,我们仅从ShapeNet的测试集中选择3D对象。在每个训练/测试房间(场景)中,我们随机放置属于ShapeNet的6类{椅子、沙发、电话、飞机、步枪、柜子}的4至8个对象。注意,我们仅使用ShapeNet训练集中上述6类的3D对象来训练单个对象中心网络。关于我们的合成数据集的更多细节请参见附录M,我们已将其发布以供未来研究。
为了在我们的合成数据集上进行类别无关的对象分割,我们除了EFEM还包括经典算法HDBSCAN (McInnes & Healy, 2017)作为无监督基线。对于Unscene3D和Part2Object,两者都需要配对的RGB图像来通过预训练的DINO/v2提取2D特征以训练其自身的检测网络,因此由于缺乏配对的RGB图像,无法直接在我们的合成数据集上训练它们。作为参考,我们直接重用在第4.1节ScanNet训练集上良好训练的模型,然后在我们的合成数据集上进行测试。由于这种设置对他们来说并不完全公平,我们将它们归类为“无监督&Real2Syn”。作为参考,我们也训练了一个完全监督的Mask3D (Schult et al., 2023)。
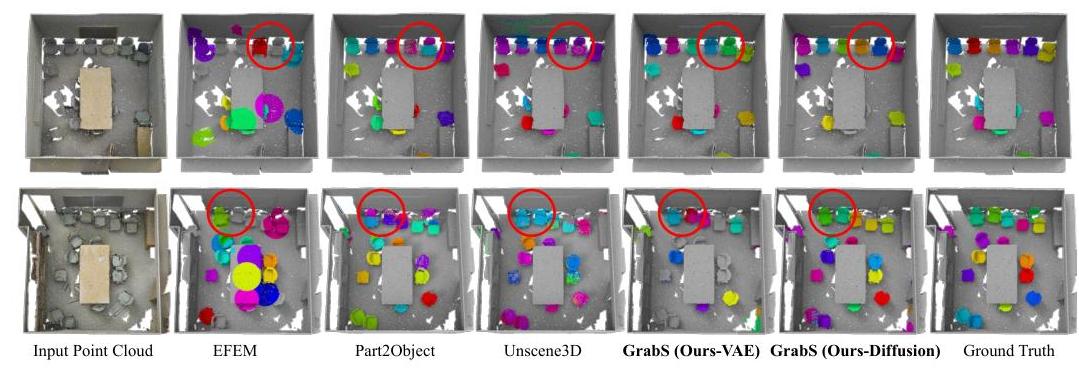
图7:S3DIS数据集上的定性结果。红圈突出显示差异。
表4:S3DIS所有6个区域上的跨数据集验证定量结果。
| AP(%) | AP50(%) | AP25(%) | RC(%) | RC50(%) | RC25(%) | PR(%) | PR50(%) | PR25(%) | ||
|---|---|---|---|---|---|---|---|---|---|---|
| Unsupervised | Unscene3D (Rosenbervaki et al., 2024) | 30.3 | 51.9 | 70.4 | 40.0 | 58.6 | 73.9 | 13.8 | 19.7 | 24.5 |
| Part2Object (Shi et al., 2024) | 25.3 | 48.4 | 67.0 | 36.5 | 57.3 | 72.3 | 37.8 | 60.5 | 76.4 | |
| EFEM (Lei et al., 2023) | 16.2 | 37.8 | 45.9 | 20.5 | 40.4 | 45.5 | 41.5 | 76.1 | 99.6 | |
| GrabS (Ours-VAE) | 41.8 | 61.7 | 67.0 | 45.9 | 63.0 | 67.9 | 60.0 | 84.0 | 90.7 | |
| GrabS (Ours-Diffusion) | 39.2 | 57.2 | 62.6 | 42.2 | 58.2 | 63.0 | 60.0 | 73.7 | 79.7 |
表5:我们合成数据集测试集上的定量结果。
| AP(%) | AP50(%) | AP25(%) | RC(%) | RC50(%) | RC25(%) | PR(%) | PR50(%) | PR25(%) | ||
|---|---|---|---|---|---|---|---|---|---|---|
| 3D Supervised | Mask3D (Schult et al., 2023) | 84.1 | 96.0 | 96.7 | 87.1 | 96.2 | 96.9 | 89.5 | 98.9 | 99.5 |
| Unsupervised | Unscene3D (Rosenbervaki et al., 2024) | 37.7 | 59.7 | 76.2 | 50.5 | 70.4 | 83.9 | 8.2 | 14.8 | 15.4 |
| & Real2Syn | Part2Object (Shi et al., 2024) | 46.1 | 69.3 | 81.5 | 53.1 | 70.9 | 83.4 | 10.2 | 15.0 | 19.1 |
| Unsupervised | HDBSCAN (McInnes & Healy, 2017) | 7.6 | 12.5 | 23.4 | 10.8 | 15.8 | 24.7 | 36.6 | 58.5 | 90.0 |
| EFEM (Lei et al., 2023) | 20.7 | 34.1 | 46.6 | 23.3 | 34.7 | 46.7 | 53.3 | 90.6 | 98.7 | |
| GrabS (Ours-VAE) | 58.7 | 85.0 | 90.6 | 71.6 | 87.9 | 91.1 | 76.0 | 93.7 | 96.3 | |
| GrabS (Ours-Diffusion) | 58.5 | 85.9 | 91.5 | 72.4 | 88.7 | 91.7 | 77.9 | 95.7 | 98.5 |
结果与分析:如表5和图8所示,我们的方法明显优于HDBSCAN和EFEM,因为HDBSCAN很难将点分组为复杂的3D形状,而EFEM只能基于其启发式方法检测有限的对象。更多结果请参见附录P。
4.4 消融研究
为了评估我们流水线中每个组件的有效性和超参数选择的影响,我们在ScanNet验证集上进行了以下广泛的消融实验。我们选择VAE版本的对象中心网络作为我们的完整框架进行参考。
(1) 使用确定性的对象中心网络。这是为了评估学习生成性对象中心先验的优势。特别是,我们简单地将VAE的概率潜在分布替换为确定性的潜在向量(AE),保持对象中心网络的其他层不变。训练这样的确定性网络后,我们使用它在3D场景上优化我们的多对象估计网络,如同我们的完整框架一样。
(2) 移除对象方向估计模块。这是为了评估对齐输入对象点云相对于规范姿态的重要性。没有它,复杂3D场景中的混乱对象方向可能导致对象分割性能下降。
(3) 移除对象发现分支。这是为了评估实体代理在对象发现中的有效性。没有它,我们随机选择每个场景中的50个位置,并随机设定半径范围为
0
∼
2
0 \sim 2
0∼2米作为容器来发现对象作为伪标签。
(4) 移除对象分割分支。这是为了评估对象分割分支的有效性。没有它,我们仅使用对象发现分支通过查询冻结的对象中心网络收集对象掩码。
(5)
∼
\sim
∼ (8) 对容器位置移动步长
Δ
s
\Delta s
Δs的敏感性。这是为了评估动态容器探索3D空间时不同选择的移动步长
Δ
s
\Delta s
Δs的影响。
(9)
∼
\sim
∼ (11) 对容器大小变化比率
α
\alpha
α的敏感性。这是为了评估容器大小变化速度
α
\alpha
α的不同选择在探索3D空间时的影响。

图8:我们合成数据集测试集上的定性结果。
(12)
∼
\sim
∼ (15) 对二进制阈值
δ
d
\delta_{d}
δd的敏感性。阈值
δ
d
\delta_{d}
δd有助于将表面点的SDF值转换为二进制对象掩码,这主要影响伪掩码的质量。
(16)
∼
\sim
∼ (18) 对奖励阈值
δ
c
\delta_{c}
δc的敏感性。由于奖励对代理至关重要,我们因此针对阈值
δ
c
\delta_{c}
δc进行了四次消融实验,验证输入点云是否与其重建的3D形状匹配,然后分配正或负奖励。
表6:我们GrabS在ScanNet验证集上所有消融模型的结果。加粗的设置是在我们的完整框架中选择的。
| AP(%) | AP50(%) | AP25(%) | RC(%) | RC50(%) | RC25(%) | PR(%) | PR50(%) | PR25(%) | |
|---|---|---|---|---|---|---|---|---|---|
| (1) 替换VAE为AE | 32.0 | 57.1 | 76.7 | 46.2 | 73.7 | 90.6 | 26.2 | 45.9 | 52.6 |
| (2) 移除方向估计器 | 35.3 | 56.3 | 69.7 | 42.9 | 61.5 | 72.0 | 52.4 | 77.6 | 87.5 |
| (3) 移除对象发现分支 | 34.2 | 56.7 | 69.4 | 41.6 | 61.4 | 73.1 | 50.7 | 78.1 | 89.0 |
| (4) 移除对象分割分支 | 25.7 | 47.9 | 55.3 | 33.5 | 50.2 | 56.0 | 57.1 | 87.1 | 95.5 |
| (5) Δ s = 0.2 \Delta s=0.2 Δs=0.2 | 43.6 | 61.3 | 72.0 | 48.0 | 63.1 | 71.6 | 62.3 | 84.1 | 91.3 |
| (6) Δ s = 0.3 \Delta s=0.3 Δs=0.3 | 46.7 | 71.5 | 82.9 | 53.2 | 74.5 | 85.2 | 52.1 | 76.4 | 83.0 |
| (7) Δ s = 0.4 \Delta s=0.4 Δs=0.4 | 40.1 | 58.1 | 67.4 | 44.9 | 60.8 | 69.6 | 57.1 | 79.5 | 87.3 |
| (8) Δ s = 0.5 \Delta s=0.5 Δs=0.5 | 38.1 | 56.5 | 66.9 | 43.4 | 59.8 | 69.9 | 51.8 | 73.7 | 82.6 |
| (9) α = 1 / 3 \alpha=1 / 3 α=1/3 | 40.8 | 61.4 | 72.9 | 48.0 | 66.4 | 77.3 | 48.8 | 71.6 | 77.7 |
| (10) α = 1 / 4 \alpha=1 / 4 α=1/4 | 46.7 | 71.5 | 82.9 | 53.2 | 74.5 | 85.2 | 52.1 | 76.4 | 83.0 |
| (11) α = 1 / 5 \alpha=1 / 5 α=1/5 | 43.3 | 61.9 | 69.5 | 48.4 | 64.5 | 71.7 | 59.9 | 81.8 | 87.2 |
| (12) δ d = 0.01 \delta_{d}=0.01 δd=0.01 | 40.1 | 59.3 | 67.8 | 45.5 | 61.7 | 69.1 | 61.2 | 85.1 | 91.9 |
| (13) δ d = 0.02 \delta_{d}=0.02 δd=0.02 | 46.7 | 71.5 | 82.9 | 53.2 | 74.5 | 85.2 | 52.1 | 76.4 | 83.0 |
| (14) δ d = 0.05 \delta_{d}=0.05 δd=0.05 | 43.4 | 62.8 | 69.3 | 47.8 | 64.0 | 69.8 | 64.9 | 88.4 | 94.0 |
| (15) δ d = 0.10 \delta_{d}=0.10 δd=0.10 | 42.9 | 61.4 | 69.5 | 47.2 | 62.4 | 70.1 | 63.2 | 86.0 | 93.7 |
| (16) δ c = 0.12 \delta_{c}=0.12 δc=0.12 | 42.6 | 60.8 | 67.6 | 47.6 | 63.7 | 69.9 | 63.1 | 85.7 | 91.2 |
| (17) δ c = 0.14 \delta_{c}=0.14 δc=0.14 | 46.7 | 71.5 | 82.9 | 53.2 | 74.5 | 85.2 | 52.1 | 76.4 | 83.0 |
| (18) δ c = 0.16 \delta_{c}=0.16 δc=0.16 | 43.8 | 68.8 | 81.0 | 52.1 | 75.8 | 86.9 | 41.3 | 63.7 | 68.6 |
分析:从表6可以看出:1)选择学习生成性对象中心先验对我们的框架影响最大。没有它,AP得分显著下降。这是因为确定性形状先验在潜在空间中不够鲁棒和连续,因此无法推广到与ShapeNet对象大不相同的现实世界3D场景。2)移除对象方向估计模块对性能的影响次之,证明该模块对于对齐现实世界对象的方向是必要的。3)对于我们的多对象估计网络中的四个超参数,整体性能不太容易受到不同选择的影响,显示出我们框架的鲁棒性。有关S3DIS上 δ c \delta_{c} δc的更多消融实验,请参阅附录E。在实体代理发现对象的过程中,我们通过将3D场景划分为更小的块来并行创建多条轨迹。我们进一步在附录C中对并行轨迹的数量进行了消融实验。
5 结论
本文展示了无需训练时使用3D场景的人工标签,即可从复杂的现实世界点云中有效发现多个3D对象。这是通过我们的新两阶段学习流水线实现的,其中第一阶段通过大规模对象数据集上的对象中心网络学习生成对象先验。通过查询所学先验并接收对象性的奖励,第二阶段通过我们多对象估计网络中的新公式化实体代理学习发现相似的3D对象。在多个真实世界数据集和我们创建的合成数据集上的广泛实验表明,我们的方法在单个或多个对象类别上的分割性能优异。
致谢:这项工作部分由国家自然科学基金项目62271431资助,部分由香港研究资助局项目25207822 & 15225522资助。
参考文献
Panos Achlioptas, Olga Diamanti, Ioannis Mitliagkas, 和 Leonidas Guibas. 学习3D点云的表示和生成模型. ICML, 2018.
I Armeni. 联合2D-3D语义数据用于室内场景理解. arXiv预印本arXiv:1702.01105, 2017.
Mohamed El Amine Boudjoghra, Angela Dai, Jean Lahoud, Hisham Cholakkal, Rao Muhammad Anwer, Salman Khan, 和 Fahad Shahbaz Khan. Open-YOLO 3D: 快速且准确的开放词汇3D实例分割. arXiv:2406.02548, 2024.
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, 和 Armand Joulin. 自监督视觉Transformer的出现属性. ICCV, 2021.
Angel X. Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, Jianxiong Xiao, Li Yi, 和 Fisher Yu. ShapeNet: 信息丰富的3D模型库. arXiv:1512.03012, 2015.
Shaoyu Chen, Jiemin Fang, Qian Zhang, Wenyu Liu, 和 Xinggang Wang. 层次聚合用于3D实例分割. ICCV, 2021.
Julian Chibane, Aymen Mir, 和 Gerard Pons-Moll. 神经非符号距离场用于隐函数学习. NeurIPS, 2020.
Julian Chibane, Francis Engelmann, Tuan Anh Tran, 和 Gerard Pons-Moll. Box2Mask: 使用边界框弱监督3D语义实例分割. ECCV, 2022.
Gene Chou, Yuval Bahat, 和 Felix Heide. Diffusion-SDF: 条件生成建模的符号距离函数. ICCV, 2023.
Christopher Choy, JunYoung Gwak, 和 Silvio Savarese. 4D时空卷积网络: Minkowski卷积神经网络. 2019.
Angela Dai, Angel X. Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, 和 Matthias Nießner. ScanNet: 富注释的室内场景3D重建. CVPR, 2017.
Haoqiang Fan, Hao Su, 和 Leonidas Guibas. 单张图像的3D物体重建点集生成网络. CVPR, 2017.
Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, 和 Yoshua Bengio. 生成对抗网络. NIPS, 2014.
Benjamin Graham, Martin Engelcke, 和 Laurens van der Maaten. 使用子流形稀疏卷积网络的3D语义分割. CVPR, 2018.
David Griffiths, Jan Boehm, 和 Tobias Ritschel. 找到你的(3D)中心: 使用学习损失的3D对象检测. ECCV, 2020.
Huy Ha 和 Shuran Song. 语义抽象: 来自2D视觉-语言模型的开放世界3D场景理解. CoRL, 2022.
Lei Han, Tian Zheng, Lan Xu, 和 Lu Fang. OccuSeg: 考虑占用的3D实例分割. CVPR, 2020.
Tong He, Chunhua Shen, 和 Anton van den Hengel. DyCo3D: 通过动态卷积稳健的3D点云实例分割. CVPR, 2021.
Jonathan Ho, Ajay Jain, 和 Pieter Abbeel. 去噪扩散概率模型. NeurIPS, 2020.
Ji Hou, Angela Dai, 和 Matthias Nießner. 3D-SIS: RGB-D扫描的3D语义实例分割. CVPR, 2019.
Ji Hou, Benjamin Graham, Matthias Nießner, 和 Saining Xie. 探索对比场景上下文的数据高效3D场景理解. CVPR, 2021.
Zhening Huang, Xiaoyang Wu, Xi Chen, Hengshuang Zhao, Lei Zhu, 和 Joan Lasenby. Openins3d: 拍照并查找用于3D开放词汇实例分割. ECCV, 2024.
Jiahao Lu, Jiacheng Deng, Chuxin Wang, 和 Jianfend He. 查询细化Transformer用于3D实例分割. ICCV, 2023.
Lei Ke, Shichao Li, Yanan Sun, Yu-Wing Tai, 和 Chi-Keung Tang. GSNet: 具有几何和场景感知监督的联合车辆姿态和形状重建. ECCV, 2020.
Hyeongju Kim, Hyeonseung Lee, Woo Hyun Kang, Joun Yeop Lee, 和 Nam Soo Kim. SoftFlow: 流形上的标准化流的概率框架. NeurIPS, 2020.
Jinwoo Kim, Jaehoon Yoo, Juho Lee, 和 Seunghoon Hong. SetVAE: 用于集合结构数据生成建模的层次组合学习. CVPR, 2021.
Diederik P Kingma 和 Max Welling. 自动编码变分贝叶斯. ICLR, 2014.
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollár, 和 Ross Girshick. 分割任何东西. ICCV, 2023.
Roman Klokov, Edmond Boyer, 和 Jakob Verbeek. 离散点流网络用于高效的点云生成. ECCV, 2020.
Maxim Kolodiazhnyi, Anna Vorontsova, Anton Konushin, 和 Danila Rukhovich. OneFormer3D: 统一点云分割的一个Transformer. CVPR, 2024.
Xin Lai, Yuhui Yuan, Ruihang Chu, Yukang Chen, Han Hu, 和 Jiaya Jia. 面向3D实例分割的无注意力掩码Transformer. ICCV, 2023.
Loic Landrieu 和 Martin Simonovsky. 大规模点云语义分割使用超级点图. CVPR, 2018.
Jiahui Lei, Congyue Deng, Karl Schmeckpeper, Leonidas Guibas, 和 Kostas Daniilidis. EFEM: 无场景监督的3D对象分割的等变神经场期望最大化. CVPR, 2023.
Muheng Li, Yueqi Duan, Jie Zhou, 和 Jiwen Lu. Diffusion-SDF: 通过体素化的扩散实现文本到形状的转换. CVPR, 2023a.
Qing Li, Huifang Feng, Kanle Shi, Yue Gao, Yi Fang, Yu-Shen Liu, 和 Zhizhong Han. SHS-NET: 用于定向法线估计的点云签名超曲面学习. CVPR, 2023b.
Qing Li, Huifang Feng, Kanle Shi, Yue Gao, Yi Fang, Yu-Shen Liu, 和 Zhizhong Han. 学习签名超曲面用于定向点云法线估计. IEEE TPAMI, 2024.
Youquan Liu, Lingdong Kong, Jun Cen, Runnan Chen, Wenwei Zhang, Liang Pan, Kai Chen, 和 Ziwei Liu. 通过蒸馏视觉基础模型分割任意点云序列. NeurIPS, 2023.
Yuheng Lu, Chenfeng Xu, Xiaobao Wei, Xiaodong Xie, Masayoshi Tomizuka, Kurt Keutzer, 和 Shanghang Zhang. 无3D标注的开放词汇点云对象检测. CVPR, 2023.
Shitong Luo 和 Wei Hu. 扩散概率模型用于3D点云生成. CVPR, 2021.
Leland McInnes 和 John Healy. 加速的基于密度的分层聚类. ICDMW, 2017.
Phuc D. A. Nguyen, Tuan Duc Ngo, Evangelos Kalogerakis, Chuang Gan, Anh Tran, Cuong Pham, 和 Khoi Nguyen. Open3DIS: 使用2D掩码引导的开放词汇3D实例分割. CVPR, 2024.
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-yao Huang, Shang-wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jegou, 和 Julien Mairal. DINOv2: 无监督学习鲁棒视觉特征. TMLR, 2024.
Jeong Joon Park, Peter Florence, Julian Straub, Richard Newcombe, 和 Steven Lovegrove. DeepSDF: 学习用于形状表示的连续符号距离函数. CVPR, 2019.
Charles R. Qi, Li Yi, Hao Su, 和 Leonidas J. Guibas. PointNet++: 度量空间中点集的深度分层特征学习. NIPS, 2017.
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, 和 Ilya Sutskever. 从自然语言监督中学习可转移的视觉模型. ICML, 2021.
Wonseok Roh, Hwanhee Jung, Giljoo Nam, Jinseop Yeom, Hyunje Park, Sang Ho, 和 Yoon Sangpil. 边缘感知3D实例分割网络与智能语义先验. CVPR, 2024.
David Rozenberszki, Or Litany, 和 Angela Dai. UnScene3D: 室内场景的无监督3D实例分割. CVPR, 2024.
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, 和 Oleg Klimov. 近端策略优化算法. arXiv:1707.06347, 2017.
Jonas Schult, Francis Engelmann, Alexander Hermans, Or Litany, Siyu Tang, 和 Bastian Leibe. Mask3D: 面向3D语义实例分割的Mask Transformer. ICRA, 2023.
Cheng Shi, Yulin Zhang, Bin Yang, Jiajin Tang, 和 Sibei Yang. Part2Object: 层次无监督3D实例分割. ECCV, 2024.
Sangyun Shin, Kaichen Zhou, Madhu Vankadari, Andrew Markham, 和 Niki Trigoni. 球形遮罩: 使用球形表示的粗到细3D点云实例分割. CVPR, 2024.
Ziyang Song 和 Bo Yang. OGC: 从点云刚体动力学中无监督3D对象分割. NeurIPS, 2022.
Ziyang Song 和 Bo Yang. 通过几何一致性无监督3D点云对象分割. TPAMI, 2024.
Jiahao Sun, Chunmei Qing, Junpeng Tan, 和 Xiangmin Xu. Superpoint Transformer用于3D场景实例分割. AAAI, 2023.
Hanchen Tai, Qingdong He, Jiangning Zhang, Yijie Qian, Zhenyu Zhang, Xiaobin Hu, Yabiao Wang, 和 Yong Liu. 开放词汇SAM3D: 理解任何3D场景. arXiv:2405.15580, 2024.
Ayça Takmaz, Elisabetta Fedele, Robert W. Sumner, Marc Pollefeys, Federico Tombari, 和 Francis Engelmann. OpenMask3D: 开放词汇3D实例分割. NeurIPS, 2023.
Linghua Tang, Le Hui, 和 Jin Xie. 学习超点间亲和力用于弱监督3D实例分割. ACCV, 2022.
Thang Vu, Kookhoi Kim, Tung M. Luu, Xuan Thanh Nguyen, 和 Chang D. Yoo. SoftGroup用于点云的3D实例分割. CVPR, 2022.
Weiyue Wang, Ronald Yu, Qiangui Huang, 和 Ulrich Neumann. SGPN: 用于3D点云实例分割的相似性组提案网络. CVPR, 2018.
Saining Xie, Jiatao Gu, Demi Guo, Charles R Qi, Leonidas Guibas, 和 Or Litany. PointContrast: 无监督预训练用于3D点云理解. ECCV, 2020.
Mi Yan, Jiazhao Zhang, Yan Zhu, 和 He Wang. MaskClustering: 基于视图共识的Mask图聚类用于开放词汇3D实例分割. CVPR, 2024.
Bo Yang, Jianan Wang, Ronald Clark, Qingyong Hu, Sen Wang, Andrew Markham, 和 Niki Trigoni. 学习用于点云3D实例分割的对象边界框. NeurIPS, 2019.
Yaoqing Yang, Chen Feng, Yiru Shen, 和 Dong Tian. FoldingNet: 通过深度网格变形的点云自动编码器. CVPR, 2018.
Li Yi, Wang Zhao, He Wang, Minhyuk Sung, 和 Leonidas Guibas. GSPN: 点云中用于3D实例分割的生成形状提案网络. CVPR, 2019.
Yingda Yin, Yuzheng Liu, Yang Xiao, Daniel Cohen-Or, Jingwei Huang, 和 Baoquan Chen. SAI3D: 分割3D场景中的任何实例. CVPR, 2024.
Xiaohui Zeng, Arash Vahdat, Francis Williams, Zan Gojcic, Or Litany, Sanja Fidler, 和 Karsten Kreis. LION: 潜在点扩散模型用于3D形状生成. NeurIPS, 2022.
Lunjun Zhang, Anqi Joyce Yang, Yuwen Xiong, Sergio Casas, Bin Yang, Mengye Ren, 和 Raquel Urtasun. 从LiDAR点云中无监督对象检测的趋势. CVPR, 2023.
Zhikai Zhang, Jian Ding, Li Jiang, Dengxin Dai, 和 Gui-Song Xia. FreePoint: 无监督点云实例分割. CVPR, 2024.
附录
A 对象中心网络架构和数据准备的详细信息
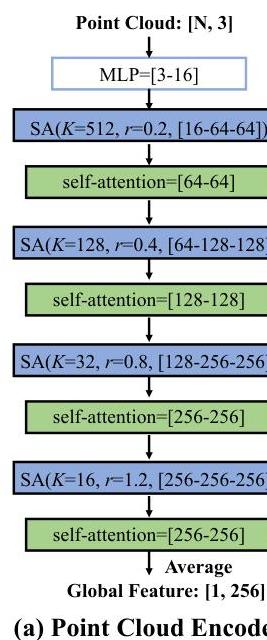
我们的GrabS框架的对象中心网络包括一个方向估计网络、一个变分自编码器(VAE)和一个扩散网络。这些组件共享一个共同的编码器架构,该架构基于PointNet++,随后是自注意力块。如图9(a)所示,编码器由四个集合抽象(SA)块组成,每个SA块后面都跟着一个自注意力机制。SA块的特征在于具有球半径 r r r的 K K K个局部区域,接着是三个多层感知机(MLP)层。
从编码器中提取形状特征后,方向估计网络使用一个隐藏神经元为128的单一MLP层来回归三个旋转角度。VAE使用一层输出高斯分布的均值和方差,从中抽取样本特征。VAE的解码器由十个MLP层组成,输入、输出和隐藏维度分别为259、1和256,用于回归查询点的符号距离函数(SDF)。
对于扩散模型,潜在特征来自训练良好的VAE,条件嵌入则通过图9(a)所示的编码器架构从输入形状中获得。去噪网络是一个三层MLP,维度为 { 256 × 3 − 256 × 2 − 256 } \{256 \times 3-256 \times 2-256\} {256×3−256×2−256}。去噪MLP的输入是条件、噪声特征和时间嵌入的连接。时间戳被归一化到范围 [ 0 , 1 ] [0,1] [0,1],其嵌入通过正弦和余弦函数计算。
在训练对象中心网络时的数据准备方面,我们利用相同的数据进行方向估计、VAE和扩散模型。在分割真实世界场景期间,对象中心网络的训练数据来源于EFEM(Lai等人, 2023)提供的带有遮挡的ShapeNet(Chang等人, 2015)椅子。这些遮挡是由投影深度图像生成的。此外,我们遵循他们的方法,随机结合地面、墙壁和其他对象的碎片,以模拟真实的背景条件。
对于合成场景,我们使用ShapeNet中的六个类别而不引入遮挡,但仍保留背景数据增强以模仿场景环境。
(a) 点云编码器
(b) 策略网络
图9:(a) 方向估计网络、VAE和扩散中使用的点云编码器的详细信息;(b) 策略网络。
B Grabs中注意力块的消融研究
全局信息对于学习表面的内外部非常重要,正如在(Li等人,2024;2023b)中讨论的那样。按照他们的方法,我们在对象中心网络的编码器中加入注意力块。在本节中,我们对此进行消融研究。表7显示了注意力块的必要性。
表7:对象中心网络中注意力块的消融研究。
| | AP(%) | AP50(%) | AP25(%) |
| :–: | :–: | :–: | :–: |: |
| 移除注意力块 | 42.9 | 66.3 | 76.9 |
| 完整Grabs |
46.7
\mathbf{4 6 . 7}
46.7 |
71.5
\mathbf{7 1 . 5}
71.5 |
82.9
\mathbf{8 2 . 9}
82.9 |
C 并行轨迹数量的消融研究
我们进一步对对象发现分支并行创建的轨迹数量进行消融研究。这里我们分别选择25/50/75/100条轨迹,而在我们的主要实验中选择了50条。
表8显示了结果。我们可以看到,1)一旦轨迹数量超过某个数量(例如50),轨迹数量就不是关键因素。2)过少的轨迹会导致最终性能略有下降,因为发现的对象掩码数量不足。
表8:不同并行轨迹数量在ScanNet验证集上的消融结果。
| 轨迹数量 | AP(%) | AP50(%) | AP25(%) |
|---|---|---|---|
| 25 | 42.0 | 64.1 | 74.4 |
| 50 | 46.7 | 71.5 | 82.9 |
| 75 | 46.9 | 69.5 | 80.8 |
| 100 | 47.1 | 69.7 | 81.3 |
D 不同超点类型的影响的消融研究
当在ScanNet上训练Mask3D时,它使用ScanNet在交叉注意块中提供的超点将体素特征分组为超点特征。这些超点特征然后通过交叉注意与查询特征交互。此过程的主要目的是减少计算负载和GPU内存使用,提高训练和推理效率。
我们进一步进行实验以评估ScanNet数据集提供的超点的影响。特别是,我们选择使用以下两种新策略:1)使用SPG(Landrieu & Simonovsky, 2018)以无监督方式生成的超点,2)直接在体素上提取特征而不是超点。
表9显示了ScanNet验证集上的结果。我们可以看到,直接使用没有任何超点的体素可以实现与ScanNet超点相当的性能,尽管后者略好一些。
表9:不同类型的超点在ScanNet验证集上的消融结果。
| AP(%) | AP50(%) | AP25(%) | |
|---|---|---|---|
| ScanNet超点 | 46.7 \mathbf{4 6 . 7} 46.7 | 71.5 \mathbf{7 1 . 5} 71.5 | 82.9 \mathbf{8 2 . 9} 82.9 |
| SPG超点 | 43.7 | 61.9 | 69.1 |
| 无超点 | 45.1 | 65.2 | 72.3 |
E 不同数据集中 δ c \delta_{c} δc的敏感性分析
我们进一步在ScanNet和S3DIS上进行全面消融研究以评估参数 δ c \delta_{c} δc的敏感性。从表10可以看出, δ c \delta_{c} δc在两个数据集上通常应设置为0.14或0.16。然而,由于S3DIS中的遮挡或扭曲形状比ScanNet更多,因此在S3DIS中识别3D物体对我们以物体为中心的网络更具挑战性。因此,S3DIS中的 δ c \delta_{c} δc略大于ScanNet中的值(更宽松)。
表10: δ c \delta_{c} δc在ScanNet验证集和S3DIS Area5上的消融结果。
| AP(%) | AP50(%) | AP25(%) | ||
|---|---|---|---|---|
| ScanNet | δ c = 0.12 \delta_{c}=0.12 δc=0.12 | 42.6 | 60.8 | 67.6 |
| δ c = 0.14 \delta_{c}=0.14 δc=0.14 | 46.7 \mathbf{4 6 . 7} 46.7 | 71.5 \mathbf{7 1 . 5} 71.5 | 82.9 | |
| δ c = 0.16 \delta_{c}=0.16 δc=0.16 | 43.8 | 68.8 | 81.0 | |
| δ c = 0.18 \delta_{c}=0.18 δc=0.18 | 43.8 | 70.1 | 85.0 \mathbf{8 5 . 0} 85.0 | |
| δ c = 0.20 \delta_{c}=0.20 δc=0.20 | 42.5 | 69.9 | 84.2 | |
| S3DIS Area5 | δ c = 0.12 \delta_{c}=0.12 δc=0.12 | 46.2 | 65.7 | 71.7 |
| δ c = 0.14 \delta_{c}=0.14 δc=0.14 | 46.4 | 66.2 | 73.8 | |
| δ c = 0.16 \delta_{c}=0.16 δc=0.16 | 51.3 \mathbf{5 1 . 3} 51.3 | 81.8 \mathbf{8 1 . 8} 81.8 | 86.0 | |
| δ c = 0.18 \delta_{c}=0.18 δc=0.18 | 48.3 | 83.1 | 90.5 \mathbf{9 0 . 5} 90.5 | |
| δ c = 0.20 \delta_{c}=0.20 δc=0.20 | 44.9 | 79.1 | 88.7 |
F 失败案例的可视化
我们GrabS中的失败案例主要包括两种类型,如图10所示。第一种是我们的模型错误地分割了形状与目标形状(例如椅子)相似的物体。例如,它可能会错误地将墙壁的一部分作为椅子分割出来。第二种类型是遗漏了一些被遮挡的椅子,主要是因为这些严重被遮挡的椅子很难通过物体中心网络重建。
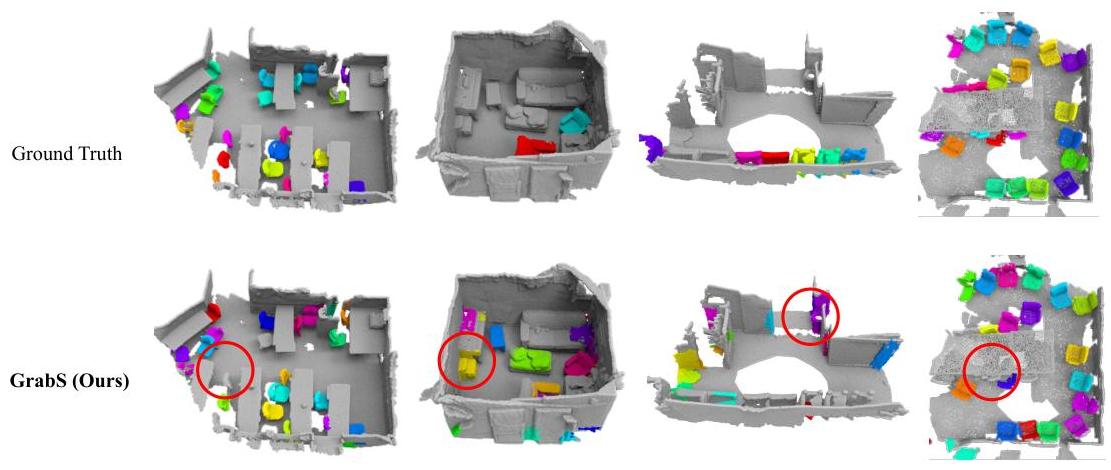
图10:我们在ScanNet验证集上的方法失败案例。
G 已发现掩码对策略网络学习的影响
为了进一步探索先前发现的掩码对策略网络训练的影响,我们分析了物体发现分支(实体代理)在各个epoch中发现的候选掩码的质量和准确性。特别地,我们在ScanNet训练集上进行了分析。如果一个发现的掩码与任何真实标签掩码的IoU大于 50 % 50\% 50%,则认为该掩码是准确的。我们跟踪了新发现掩码的数量,定义为从未在所有先前epoch中识别过的那些。
表11显示了在一定数量的训练epoch中发现掩码的数量和准确性。我们可以看到:1)随着训练的进行,发现掩码的总数增加,且准确性有所提高。然而,新发现掩码的数量随时间减少,表明网络在训练过程中变得更加一致地识别相关掩码。2)新发现掩码的准确性下降,主要是因为容易重建的物体可以在早期epoch中被识别出来。随着训练的进行,模型可能试图发现更难表示的物体,这是有风险且容易出错的。
表11:在一定数量的epoch中发现物体的数量和准确性。注意,某些新发现的掩码可能会相互重叠。本表中的所有数字都是去除重叠掩码后的计数。
| Epoch | 0 | 50 | 100 | 150 | 200 | 250 | 300 | 350 | 400 |
|---|---|---|---|---|---|---|---|---|---|
| 掩码数量 | 920 | 5630 | 6981 | 7421 | 7457 | 7696 | 8133 | 7922 | 7931 |
| 掩码准确性 (%) | 16.5 | 36.2 | 41.0 | 43.5 | 42.0 | 42.2 | 44.0 | 44.7 | 45.5 |
| 新掩码数量 | 920 | 5257 | 4336 | 2404 | 1982 | 1716 | 1576 | 1277 | 870 |
| 新掩码准确性 (%) | 16.5 | 26.7 | 15.3 | 10.2 | 7.4 | 6.0 | 5.1 | 4.3 | 4.3 |
H 在ScanNet和S3DIS上的类别无关评估
按照Unscene3D和Part2Object的方法,我们也对ScanNet和S3DIS进行了类别无关的物体分割评估。具体来说,我们直接使用在第4.3节中训练的ShapeNet六个类别的物体中心网络,然后在ScanNet训练集上训练我们的多物体估计网络。最后,我们的物体检测模型在ScanNet验证集上进行评估,并在S3DIS的Area 5上进行跨数据集评估。所有基线都在相同的训练和测试数据集上进行评估,以确保评估的公平性。
表12展示了定量结果。请注意,基线Part2Object (2D only) 使用预训练的DINOv2 (Oquab等人, 2024) 提供物体先验,Unscene3D (2D+3D) 同时使用DINO (Caron等人, 2021) 和CSC (Hou等人, 2021) 提供物体先验,而Unscene3D (3D only) 只使用CSC提供物体先验。我们可以看到我们的模型超过了Unscene3D (3D only),但在Unscene3D (2D+3D) 和Part2Object (2D only) 上表现稍逊一筹,主要是因为他们利用了来自大规模2D模型如DINO和DINOv2的极其丰富的物体先验,而我们仅使用了ShapeNet数据集中有限的六个类别的物体先验。我们将使用更大规模的2D或3D先验作为未来探索的方向。
表12:ScanNet验证集和S3DIS Area5上的类别无关分割结果。
| AP(%) | AP50(%) | AP25(%) | ||
|---|---|---|---|---|
| ScanNet | Part2Object (Shi等人, 2024) (2D only) | 16.9 | 36.0 | 64.9 |
| Unscene3D (Rozenberszki等人, 2024) (2D+3D) | 15.9 | 32.2 | 58.5 | |
| Unscene3D (Rozenberszki等人, 2024) (3D only) | 13.3 | 26.2 | 52.7 | |
| EFEM (Lei等人, 2023) | 6.4 | 13.7 | 21.5 | |
| GrabS(Ours-VAE) | 14.3 | 27.2 | 41.4 | |
| S3DIS Area5 | Part2Object (Shi等人, 2024) (2D only) | 8.7 | 19.4 | 40.8 |
| Unscene3D (Rozenberszki等人, 2024) (2D+3D) | 8.5 | 16.7 | 35.5 | |
| Unscene3D (Rozenberszki等人, 2024) (3D only) | 8.3 | 15.3 | 32.2 | |
| EFEM (Lei等人, 2023) | 4.6 | 7.3 | 12.3 | |
| GrabS(Ours-VAE) | 8.5 | 13.2 | 20.5 |
I 代理轨迹的可视化
图11展示了代理的三条轨迹,以及每个容器内的候选掩码和恢复的完整形状。
J 内存和时间成本
我们流水线的第一阶段涉及训练方向估计器和生成模型。这分别需要8小时和21小时,GPU内存分别为4GB和8GB。第二阶段需要62小时和20GB GPU内存来训练整个网络。
尽管我们的训练过程比基线更耗时,但我们的推理速度和内存成本与Unscene3D和Part2Object相同。每个场景平均需要0.092秒和5GB内存。这显著快于EFEM,EFEM需要每个场景迭代推理2.3分钟和8GB内存。测试硬件为单个RTX 3090 GPU和AMD R9 5900X CPU。
K 策略学习的详细信息
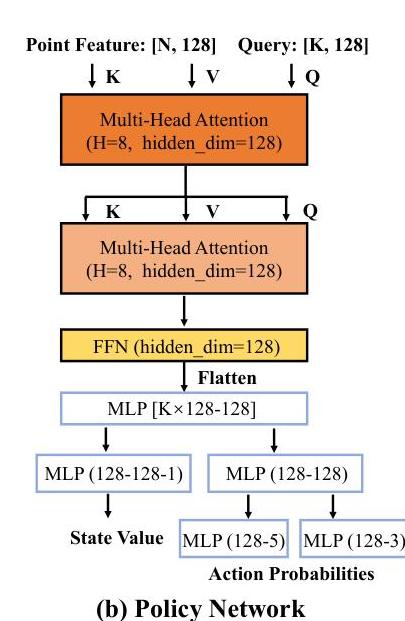
策略网络旨在从输入点特征中推导动作,功能类似于点云块内的目标物体检测机制。为此,我们模仿Mask3D(Schult等人,2023)的分割头构建我们的策略网络。具体而言,如图9(b)所示,我们使用Transformer解码器嵌入容器内目标物体的信息,初始查询数量在所有实验中设为32。随后,我们使用三个MLP层回归状态值,并使用另外三个MLP层预测动作。
我们使用近端策略优化(PPO)算法训练代理。PPO中的参数详情、代理初始化和奖励计算如下。
对于初始化,由于输入到策略网络的是容器内的点,我们用大半径初始化圆柱容器,具体为 C d = 2.0 m C_{d}=2.0 \mathrm{~m} Cd=2.0 m。这个大半径为策略网络提供了较大的感受野,确保其有足够的信息来确定后续动作。
关于奖励计算,如果识别掩码内的点可以重建,即它们到提取网格的Chamfer距离小于阈值 δ c \delta_{c} δc,我们将此状态的奖励分数设为10并终止轨迹。否则,分配一个-1的分数。我们方法中的最大步长设为8。
在PPO中,我们约束前一步和当前步动作分布的最大变化比例为 20 % 20 \% 20%,以确保策略分布不会变化过快。我们使用广义优势估计而不是回归原始优势。平衡参数 λ \lambda λ设为0.5,未来回报的折扣权重设为0.9。为了鼓励动作探索,我们在动作分布上应用熵损失。因此,这里有三个损失函数:原始状态值回归损失、PPO-Clip损失以及额外的熵损失,其系数分别为1, 1和0.1。优化器为Adam,在所有训练轮次中学习率为0.0001。
PPO的参数在所有场景数据集上设置相同。在实现中,我们将整个3D场景划分为50个块,并在每个块中初始化一个代理进行并行搜索。块大小设为2.0 m。我们在表13中提供了块大小选择的消融实验。
L 分割分支训练的详细信息
为了训练我们对象估计网络的分割分支,我们基本上遵循Mask3D(Schult等人,2023),为了更高效的训练,我们使用5厘米的体素大小。优化器为AdamW,在所有训练轮次中学习率为0.0001。
选择Custom30M版本的SparseConv(Choy等人,2019)与Transformer解码器作为骨干和分割头。我们简单地使用一个Transformer解码器块以高效
进行训练。在Transformer解码器中,每个初始查询特征将在注意力层后更新,然后作为每个掩码的中心特征。
Mask3D结合了三种损失函数:用于掩码监督的二元交叉熵和骰子损失,以及用于掩码分类的交叉熵损失。这种分类实际上应用于掩码中心特征。我们直接采用这三种损失函数。对于分类损失,我们将能够与伪掩码匹配的掩码视为前景,其他视为背景,所以在我们的设置中这是一个二分类损失。我们采用这三个损失的原始加权组合作为我们的分割损失,即 2 / 5 / 2 2 / 5 / 2 2/5/2。这些损失函数和网络在所有数据集上保持不变。
表13:我们在ScanNet验证集上GrabS消融模型的结果。加粗的设置是我们完整框架中选择的。
| AP(%) | AP50(%) | AP25(%) | RC(%) | RC50(%) | RC25(%) | PR(%) | PR50(%) | PR25(%) | |
|---|---|---|---|---|---|---|---|---|---|
| (1) 块半径 = 1.0 m =1.0 \mathrm{~m} =1.0 m | 42.2 | 61.5 | 73.2 | 47.6 | 65.5 | 76.9 | 50.9 | 74.3 | 82.1 |
| (2) 块半径 = 2.0 m =2.0 \mathrm{~m} =2.0 m | 46.7 \mathbf{4 6 . 7} 46.7 | 71.5 \mathbf{7 1 . 5} 71.5 | 82.9 \mathbf{8 2 . 9} 82.9 | 53.2 \mathbf{5 3 . 2} 53.2 | 74.5 \mathbf{7 4 . 5} 74.5 | 85.2 \mathbf{8 5 . 2} 85.2 | 52.1 | 76.4 | 83.0 |
| (2) 块半径 = 3.0 m =3.0 \mathrm{~m} =3.0 m | 41.1 | 60.4 | 70.9 | 45.8 | 62.5 | 72.5 | 58.0 | 81.4 | 90.7 |
M 我们合成数据集的详细信息
根据(Song & Yang, 2022),我们生成了包含 4 ∼ 8 4 \sim 8 4∼8个物体的5000个静态场景。每个场景中的地面平面纵横比在0.6到1.0之间均匀采样。对于场景中的每个物体,其尺度设置为1。每个物体被缩放到单位尺寸,其围绕垂直z轴的旋转角度从 − 18 0 ∘ ∼ 18 0 ∘ -180^{\circ} \sim 180^{\circ} −180∘∼180∘随机采样。为了模拟真实的室内环境,场景中创建了墙壁和地面平面。生成的点云仅包含坐标信息而无颜色信息。每个场景包含20000个点。
为了避免物体重叠,物体在每个场景中依次放置。检查每个新放置物体的边界框是否与之前放置物体的边界框重叠。如果检测到重叠,则调整物体的位置,直到找到不重叠的位置或达到最大放置尝试次数。如果无法在最大尝试次数内找到不重叠的位置,我们将丢弃该房间。最大放置尝试次数为1000。
N 在ScanNet上的训练和评估
我们在ScanNet训练集上训练我们的模型450个周期,批量大小为8。变压器解码器中的查询数量在此数据集中设置为50。我们在训练和推理中使用ScanNet提供的超级点。图12提供了在ScanNet验证集上与基线方法更多的定性比较。
O 在S3DIS上的评估
表14至19显示了在S3DIS每个区域上的跨数据集验证结果。图13提供了更多的定性比较。
P 在我们合成数据集上的训练和评估
训练超参数与ScanNet中使用的相同。Mask3D中的查询数量设置为10,因为每个场景中最多有8个物体。我们在这个数据集上以10的批量大小训练模型150个周期。超级点由SPG构建。更多可视化见图14。
表14:我们的方法和基线在S3DIS Area-1上的跨数据集评估结果。
| AP(%) | AP50(%) | AP25(%) | RC(%) | RC50(%) | RC25(%) | PR(%) | PR50(%) | PR25(%) | ||
|---|---|---|---|---|---|---|---|---|---|---|
| 无监督 | Unsenc3D (Rozenberceki et al., 2024) | 33.6 | 63.8 | 85.4 | 44.8 | 70.3 | 88.3 | 13.3 | 21.4 | 26.1 |
| Par2Object (Shi et al., 2024) | 27.1 | 55.4 | 77.5 | 38.8 | 66.4 | 83.2 | 37.8 | 65.2 | 80.6 | |
| EFEM (Lei et al., 2023) | 19.1 | 48.6 | 54.7 | 23.8 | 49.7 | 54.8 | 43.7 | 93.9 | 98.8 | |
| GrahS (Ours-VAE) | 45.5 | 68.6 | 73.2 | 51.3 | 71.0 | 75.5 | 62.7 | 88.0 | 90.7 | |
| GrahS (Ours-Diffusion) | 47.8 | 70.9 | 75.7 | 52.5 | 72.3 | 76.8 | 64.6 | 91.1 | 92.2 |
表15:我们的方法和基线在S3DIS Area-2上的跨数据集评估结果。
| AP(%) | AP50(%) | AP25(%) | RC(%) | RC50(%) | RC25(%) | PR(%) | PR50(%) | PR25(%) | ||
|---|---|---|---|---|---|---|---|---|---|---|
| 无监督 | Unsenc3D (Rozenberceki et al., 2024) | 3.2 | 6.0 | 10.5 | 5.0 | 8.0 | 13.2 | 7.0 | 11.5 | 18.4 |
| Par2Object (Shi et al., 2024) | 2.8 | 6.2 | 8.8 | 4.9 | 7.9 | 10.6 | 30.4 | 50.0 | 69.0 | |
| EFEM (Lei et al., 2023) | 1.1 | 2.9 | 9.2 | 1.6 | 3.5 | 9.2 | 17.7 | 40.4 | 100.0 | |
| GrahS (Ours-VAE) | 6.4 | 10.2 | 17.2 | 8.0 | 11.7 | 18.5 | 35.2 | 53.8 | 78.9 | |
| GrahS (Ours-Diffusion) | 5.3 | 8.1 | 13.3 | 6.2 | 8.8 | 14.5 | 28.9 | 43.6 | 67.5 |
表16:我们的方法和基线在S3DIS Area-3上的跨数据集评估结果。
| AP(%) | AP50(%) | AP25(%) | RC(%) | RC50(%) | RC25(%) | PR(%) | PR50(%) | PR25(%) | ||
|---|---|---|---|---|---|---|---|---|---|---|
| 无监督 | Unsenc3D (Rozenberceki et al., 2024) | 37.6 | 58.2 | 83.6 | 51.0 | 68.6 | 88.0 | 16.2 | 22.3 | 26.4 |
| Par2Object (Shi et al., 2024) | 38.9 | 63.5 | 81.4 | 49.9 | 73.1 | 86.5 | 43.6 | 65.3 | 78.4 | |
| EFEM (Lei et al., 2023) | 29.0 | 58.3 | 64.2 | 35.8 | 59.7 | 64.2 | 55.4 | 95.2 | 100.0 | |
| GrahS (Ours-VAE) | 59.5 | 78.8 | 80.2 | 62.9 | 79.1 | 80.6 | 73.4 | 93.0 | 94.7 | |
| GrahS (Ours-Diffusion) | 51.4 | 67.0 | 67.0 | 52.7 | 67.2 | 67.2 | 76.7 | 97.8 | 97.8 |
表17:我们的方法和基线在S3DIS Area-4上的跨数据集评估结果。
| AP(%) | AP50(%) | AP25(%) | RC(%) | RC50(%) | RC25(%) | PR(%) | PR50(%) | PR25(%) | ||
|---|---|---|---|---|---|---|---|---|---|---|
| 无监督 | Unsenc3D (Rozenberceki et al., 2024) | 23.9 | 49.1 | 70.8 | 35.8 | 60.3 | 76.7 | 11.6 | 19.9 | 24.9 |
| Par2Object (Shi et al., 2024) | 26.8 | 57.4 | 75.3 | 38.7 | 67.3 | 79.8 | 38.2 | 66.5 | 80.3 | |
| EFEM (Lei et al., 2023) | 15.1 | 36.5 | 49.1 | 19.9 | 37.7 | 49.1 | 42.7 | 90.9 | 100.0 | |
| GrahS (Ours-VAE) | 39.2 | 66.4 | 73.4 | 45.1 | 67.9 | 74.8 | 53.9 | 81.8 | 86.2 | |
| GrahS (Ours-Diffusion) | 39.4 | 64.8 | 68.0 | 46.1 | 66.0 | 69.2 | 63.9 | 92.9 | 94.8 |
表18:我们的方法和基线在S3DIS Area-5上的跨数据集评估结果。
| AP(%) | AP50(%) | AP25(%) | RC(%) | RC50(%) | RC25(%) | PR(%) | PR50(%) | PR25(%) | ||
|---|---|---|---|---|---|---|---|---|---|---|
| 无监督 | Unsenc3D (Rozenberceki et al., 2024) | 42.6 | 63.4 | 80.3 | 51.9 | 68.6 | 83.3 | 17.4 | 23.5 | 27.7 |
| Par2Object (Shi et al., 2024) | 30.0 | 50.5 | 76.4 | 45.2 | 64.7 | 82.6 | 43.5 | 62.5 | 80.1 | |
| EFEM (Lei et al., 2023) | 14.9 | 35.7 | 45.3 | 18.6 | 36.0 | 45.3 | 43.6 | 92.1 | 100.0 | |
| GrahS (Ours-VAE) | 46.4 | 66.2 | 73.8 | 51.0 | 67.1 | 74.0 | 68.5 | 91.5 | 97.0 | |
| GrahS (Ours-Diffusion) | 44.2 | 58.0 | 62.6 | 45.7 | 58.9 | 63.2 | 70.8 | 91.6 | 96.4 |
表19:我们的方法和基线在S3DIS Area-6上的跨数据集评估结果。
| AP(%) | AP50(%) | AP25(%) | RC(%) | RC50(%) | RC25(%) | PR(%) | PR50(%) | PR25(%) | ||
|---|---|---|---|---|---|---|---|---|---|---|
| 无监督 | Unsenc3D (Rozenberceki et al., 2024) | 41.3 | 70.9 | 92.3 | 51.6 | 75.9 | 94.4 | 12.8 | 19.6 | 23.6 |
| Par2Object (Shi et al., 2024) | 26.5 | 57.4 | 83.0 | 43.0 | 74.9 | 91.1 | 33.6 | 58.8 | 71.5 | |
| EFEM (Lei et al., 2023) | 18.3 | 45.2 | 53.1 | 23.6 | 45.8 | 53.1 | 46.1 | 94.3 | 99.0 | |
| GrahS (Ours-VAE) | 52.1 | 80.4 | 84.3 | 57.3 | 80.4 | 84.4 | 66.6 | 96.0 | 96.8 | |
| GrahS (Ours-Diffusion) | 47.1 | 74.5 | 76.2 | 52.2 | 76.0 | 77.7 | 65.6 | 96.5 | 97.9 | |
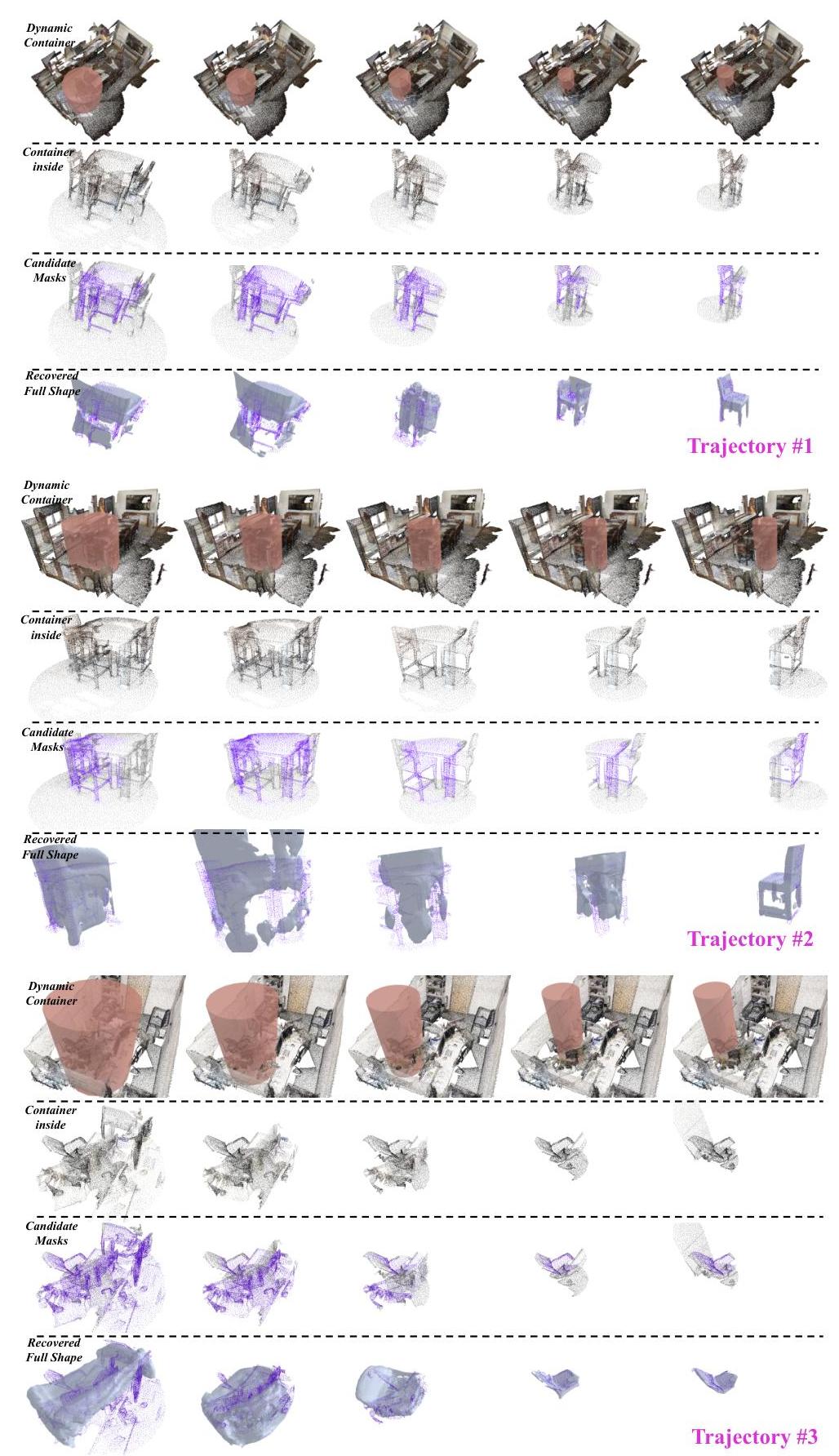 |
图11:代理的样本轨迹。

图12:在ScanNet验证集上与基线方法更多的定性比较。

图13:在S3DIS上更多的定性比较。

图14:在我们合成数据集测试集上的更多定性结果。
参考论文:https://arxiv.org/pdf/2504.11754



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











