






孙大春,吕游,李金宁,陈逸卓,王天时,Kimura Tomoyoshi,Tarek Abdelzaher
计算机科学系
伊利诺伊大学厄巴纳-香槟分校,伊利诺伊州厄巴纳市 61801,美国
{dsun18, youlyu2, jinning4, yizhuoc, tianshi3, tkimura4, zaher}@illinois.edu
摘要
本文介绍了SCRAG,这是一个受社交计算启发的预测框架,旨在预测社区对真实或假设社交媒体帖子的响应。SCRAG可以被公共关系专家(例如,用于以避免意外误解的方式撰写信息)或公众人物和影响者(例如,用于预测社会反应)使用,以及其他与公众情绪预测、危机管理和社交情景分析相关的应用。尽管大型语言模型(LLMs)在生成连贯且上下文丰富的文本方面取得了显著成功,但它们对静态训练数据的依赖性和易产生幻觉的特性限制了其在动态社交媒体环境中进行响应预测的有效性。SCRAG通过将LLMs与基于社交计算的检索增强生成(RAG)技术相结合克服了这些挑战。具体来说,我们的框架检索(i)目标社区的历史响应,以捕捉其意识形态、语义和情感构成,以及(ii)来自新闻文章等来源的外部知识,以注入时间敏感的上下文。然后联合使用这些信息来预测目标社区对新帖子或叙事的响应。在 X \mathbb{X} X平台(前身为Twitter)上针对六个场景进行的广泛实验,测试了各种嵌入模型和LLMs,结果表明关键评估指标平均提高了超过 10 % 10 \% 10%。一个具体的例子进一步展示了其在捕捉多样意识形态和细微差别方面的有效性。我们的工作为需要准确且具体洞察社区响应的应用提供了一个社交计算工具。
索引术语—社交媒体响应预测,社交网络,社交计算,意识形态嵌入,大型语言模型,检索增强生成。
I. 引言
在当今高度互联的世界中,社交媒体已演变成一个充满活力的生态系统,人们在此进行实时对话、公开塑造意见并影响各领域的决策,如外交、危机应对和公共关系。公众人物、公共关系专家和社会媒体分析师依赖这些平台传播信息、管理声誉并观察公众反应。准确预测社区对潜在社交媒体叙事的响应有助于防止误解、导航意识形态差异并主动管理社会动态。
最近,大型语言模型(LLMs)如GPT [1] 的发展彻底改变了自然语言处理。LLMs在需要理解、总结和生成文本的任务中表现出色,在从问答到对话生成等一系列应用中取得了显著成功[2]-[4]。然而,尽管具备这些能力,当处理与动态和多面的社会现象相关的生成任务时,它们仍面临挑战。在涉及快速变化情景的苛刻社会应用中,如危机事件、政治发展或新兴趋势,LLMs往往生成过时和幻想化的响应,无法反映不断演变的公众情绪的细微差别。
为解决这些局限性,检索增强生成(RAG)[5]作为一种将LLM输出基于新外部知识的方法应运而生。RAG将LLMs的生成能力与检索上下文的新鲜度和相关性相结合,使它们能够在训练后访问新信息,从而在生成情境敏感响应时提高可靠性。这在动态社交媒体环境中尤为重要,因为相关和准确的上下文至关重要。
基于这些见解,我们提出了SCRAG,这是一种预测框架,用于预测社区对真实或假设社交媒体帖子的响应,反映在如 X \mathbb{X} X(前身为Twitter)等平台上观察到的多样化观点和现实对话动态。我们的框架结合了LLMs与基于社交计算的RAG方法,以实现对多样化、现实且情境相关的响应的预测。具体而言,我们纳入了一个社区感知的历史响应检索器,以语义和意识形态地通知预测。此外,我们检索相关的新闻文章和实体间的关系,以便进行新情景转移和事实依据。
广泛的实验和案例研究使用各种指标评估预测响应的情感丰富性、意识形态多样性和情境相关性(与预测算法未使用的实际响应相比),SCRAG在几乎所有情况下都表现出优越性能。与聚合摘要方法不同,这些细粒度预测支持需要理解社区反应精确表达的应用。我们的贡献总结如下:
-
我们提出了一种新型框架,将LLMs与基于社交计算的RAG技术相结合,以预测多样化、现实且情境相关的响应。
-
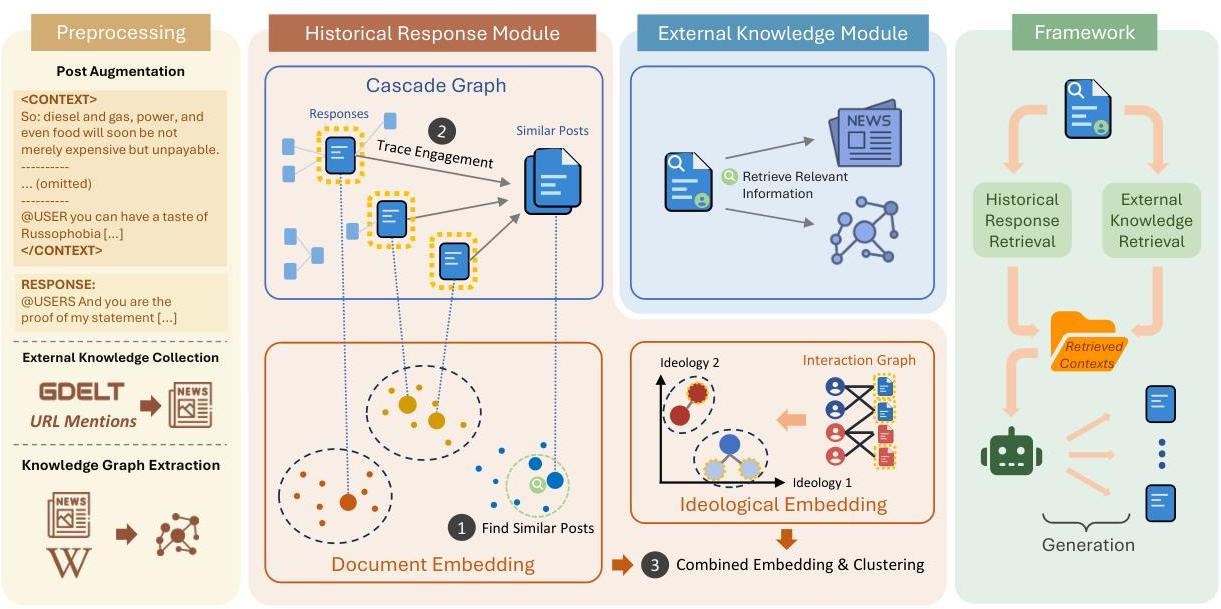
图1:SCRAG的框架架构。 -
我们证明了我们的框架具有高度模块化的特点,可接受各种嵌入模型和LLMs,使其能够适应不同的需求和资源可用性。
-
- 我们通过在多个数据集上的广泛实验评估我们的框架,突出其生成准确且丰富的预测的能力。
-
本文其余部分组织如下。第二节介绍我们的问题陈述。第三节详细说明我们提出的框架,第四节展示实验结果。第五节回顾与响应生成、RAG技术和意识形态嵌入相关的现有工作。最后,第六节总结全文并概述未来研究的方向。
II. 问题定义
本文解决了准确预测社区对选定的真实或假设社交媒体帖子的响应这一挑战。我们的目标是创建一个框架,自动捕捉社区信念的范围,同时适应新的外部信息,提供现实的表达方式,代表意识形态多样性,确保情境相关性,并适应变化的情况。
设 p s p_{s} ps表示社交媒体上的新(真实或假设)帖子,令 D p = { ( p i , R i ) ∣ i = 1 , … , N p } \mathcal{D}_{p}=\left\{\left(p_{i}, \mathcal{R}_{i}\right) \mid i=1, \ldots, N_{p}\right\} Dp={(pi,Ri)∣i=1,…,Np}为一个广泛的历史响应数据集,包含各种主题的先前帖子,其中 p i p_{i} pi是任何带有响应的帖子, R i \mathcal{R}_{i} Ri表示那些响应(回复、引用或评论)的集合。另外,令 D n = { d i ∣ i = 1 , … , N n } \mathcal{D}_{n}=\left\{d_{i} \mid i=1, \ldots, N_{n}\right\} Dn={di∣i=1,…,Nn}表示一个持续更新的新闻数据集。给定 D p \mathcal{D}_{p} Dp和 D n \mathcal{D}_{n} Dn,目标是为帖子 p s p_{s} ps生成一组现实、多样化且情境相关的响应。
III. 方法论
我们引入SCRAG,一种通过基于社交计算的检索增强生成预测社交媒体上社区响应的框架。图1展示了所提框架的概述。我们的方法包括两个主要模块,灵感来源于社交计算:(i)社区感知的历史响应检索,其中检索并聚类类似情景下的过往响应为语义和意识形态一致的组,为响应预测提供社区意识形态识别和写作风格参考;(ii)稀疏检索外部知识以获取最新的相关新闻文章和知识图谱(KG)关系,将响应置于适当的上下文中。
A. 预处理
1)历史帖子增强:在社交媒体上,尤其是在像 X \mathbb{X} X这样的短文本平台上,单个帖子通常无法在没有周围对话背景的情况下完全理解。因此,对于响应链中的每个帖子 p i p_{i} pi,我们追溯其回到根(原始)帖子的路径,并将该路径转换为文本文档。每个增强帖子包括根消息和沿链的少数直接父帖子作为上下文。这种方法保留了重要信息,并提供了理解帖子 p i p_{i} pi所需的必要细节。
2)外部知识收集和KG提取:
首先,我们从社交媒体帖子中收集新闻文章提及内容并抓取其内容以创建初始集 D n \mathcal{D}_{n} Dn。为了保持预测框架的最新数据库,我们持续从GDELT项目[6]中收集额外的新闻文章,作为全球事件的外部来源。随着新闻文章的收集,它们经过LLM管道以提取实体和关系,形成知识图谱 G K G_{K} GK的部分。为了便于检索知识图谱关系三元组,我们将 G K G_{K} GK中的节点及其局部邻域转换为文本表示,生成称为 D g \mathcal{D}_{g} Dg的一组文档。如果一个节点有太多邻居,则文本表示分为多个块。如果没有足够的邻居节点,我们暂时忽略该文档,直到它们变得可用。
B. 社区感知的历史响应检索器
给定社交媒体上的新帖子 p s p_{s} ps,我们将检索过去相似情境下的历史响应,并将其聚类为意识形态和语义不同的组,为预测社区如何响应新帖子奠定基础。此模块的目的有两个:(i)通过自动识别不同社区并总结其主导信念的数据来捕获预测中的意识形态和语义构成,(ii)准备每个社区情感和写作风格特征的例子,以预测真实的响应。
1)构建历史响应数据库:此检索器模块依赖于历史响应数据库,我们展示填充它的过程。设 E : doc → \mathcal{E}: \operatorname{doc} \rightarrow E:doc→ R d \mathbb{R}^{d} Rd是一个嵌入模型,它将文档映射到 d d d维向量,如图2所示,并设 V \mathcal{V} V是一个基于向量之间欧几里得距离索引的向量数据库。我们使用 E \mathcal{E} E将 D p \mathcal{D}_{p} Dp中的增强帖子嵌入填充到 V \mathcal{V} V中。
文本嵌入有效地表示了语义信息,这对于检索相似帖子非常重要。然而,语义并不能明确与社区的意识形态或信仰相关联。我们还可以通过用户-帖子交互二部图 G I = ( U ∪ P , E ) G_{I}=(\mathcal{U} \cup \mathcal{P}, E) GI=(U∪P,E)从这些帖子中推导出意识形态嵌入,这是社交网络固有的。意识形态表示学习算法[7],[8]创建用户和帖子的嵌入,确保那些共享相同意识形态的人在潜在空间中位置靠近,通过最小化图结构的重建损失:
P ( ( i → j ) ∈ E ∣ u i , m j ) = σ ( u i T m j ) \mathbb{P}\left((i \rightarrow j) \in E \mid \mathbf{u}_{i}, \mathbf{m}_{j}\right)=\sigma\left(\mathbf{u}_{i}^{T} \mathbf{m}_{j}\right) P((i→j)∈E∣ui,mj)=σ(uiTmj)
其中
u
i
,
m
j
∈
R
d
′
\mathbf{u}_{i}, \mathbf{m}_{j} \in \mathbb{R}^{d^{\prime}}
ui,mj∈Rd′分别是用户
i
i
i和帖子
j
j
j的意识形态嵌入。我们分别计算每个主题的增强帖子嵌入,并带适当填充插入到
V
\mathcal{V}
V中。对于每个主题,默认的意识形态方向为赞成和反对。以下部分将结合文本嵌入使用这些来定义社区。
2)历史响应检索:给定一个新的增强帖子
p
s
p_{s}
ps和
e
s
=
E
(
p
s
)
\mathbf{e}_{s}=\mathcal{E}\left(p_{s}\right)
es=E(ps),我们从向量存储
V
\mathcal{V}
V中检索出
k
p
+
k
Δ
k_{p}+k_{\Delta}
kp+kΔ个相似帖子
P
candidate
\mathcal{P}_{\text {candidate }}
Pcandidate ,按它们与
e
s
\mathbf{e}_{s}
es的距离排序,其中
k
p
k_{p}
kp和
k
Δ
k_{\Delta}
kΔ是根据历史数据库大小和不同意识形态和语义覆盖范围需要调整的超参数。我们进一步通过提示LLM代理来细化候选集,确定每个
p
i
∈
P
candidate
p_{i} \in \mathcal{P}_{\text {candidate }}
pi∈Pcandidate 是否与
p
s
p_{s}
ps在更广类别中相关或表达对这些类别的类似立场。细化后的集
P
similar
\mathcal{P}_{\text {similar }}
Psimilar 随后被追踪以定位历史响应。此步骤的输出是所有
R
i
\mathcal{R}_{i}
Ri的并集,包含被视为与
p
s
p_{s}
ps相似的帖子
p
i
∈
P
similar
p_{i} \in \mathcal{P}_{\text {similar }}
pi∈Psimilar 的历史响应,记为:
R gather = ∪ i { R i ∣ p i ∈ P similar } \mathcal{R}_{\text {gather }}=\cup_{i}\left\{\mathcal{R}_{i} \mid p_{i} \in \mathcal{P}_{\text {similar }}\right\} Rgather =∪i{Ri∣pi∈Psimilar }
3)基于聚类的社区发现:我们尝试基于收集到的文本嵌入和意识形态嵌入的响应进行计算上的社区发现。通过将它们结合起来,聚类算法获得了更多信息,变得语义和意识形态感知。我们通过实验确认了这种方法的有效性。由于文本嵌入的维度要高得多,我们在连接之前先应用UMAP [9]。然后我们应用HDBSCAN [10],一种基于密度的聚类算法,使用组合嵌入对 R gather \mathcal{R}_{\text {gather }} Rgather 进行聚类,形成 N C N_{C} NC个簇。由聚类算法识别为异常值的响应进一步通过意识形态嵌入分成单独的集合,以尊重异常值之间的意识形态差异。最终,我们得到一组发现的社区:
{ C 1 , C 2 , … , C N C , ( C O , 1 , … , C O , d ′ ) } \left\{C_{1}, C_{2}, \ldots, C_{N_{C}},\left(C_{O, 1}, \ldots, C_{O, d^{\prime}}\right)\right\} {C1,C2,…,CNC,(CO,1,…,CO,d′)}
我们从每个簇中选择 k c k_{c} kc个代表性响应供生成模块使用。为了确保最终选择的多样性,我们采用类似于最大边际相关性(MMR)[11]的策略,基于响应与簇中心点的距离及其与已选响应的语义相似性。
C. 稀疏检索外部知识
除了历史响应外,预测社区响应还需要额外的事实和时间敏感知识,特别是在涉及新事件和实体的新兴情景中,这些事件和实体在历史数据中不存在。为此,我们采用稀疏检索模块从新闻文章和GDELT项目[6]中获取最新的外部知识,这两者在本文中均视为外部知识来源。
稀疏检索因其较低的计算需求和短社交媒体查询与长新闻文章之间的领域转移,语义基础的方法可能不太合适。同时,纯基于术语的检索在我们的应用中可能过于限制,使得SPLADE [12]成为此模块的理想组件,因为它结合了基于术语的匹配与查询扩展,减少了限制并增强了检索性能。
1)新闻文章和KG关系检索:在第III-A2节中准备了 D n \mathcal{D}_{n} Dn和 D g \mathcal{D}_{g} Dg中的文档。我们使用SPLADE模型 E ′ \mathcal{E}^{\prime} E′对其进行嵌入,并将它们插入基于稀疏向量之间稀疏内积索引的独立向量数据库。新收集的文章也按时间类似处理。给定 p s p_{s} ps和 e s ′ = E ′ ( p s ) e_{s}^{\prime}=\mathcal{E}^{\prime}\left(p_{s}\right) es′=E′(ps),我们检索 k n k_{n} kn篇新闻文章片段和 k g k_{g} kg个关系三元组块。
D. 生成模块
我们提示LLM预测 M M M个新响应,尊重已识别的社区和外部知识。在图2中,我们展示了SCRAG的专用提示,它结合了检索到的历史响应、社区的意识形态属性、相关的新闻文章和相关的知识图谱关系三元组。为了还预测每个社区可能不同的活动水平,我们根据识别的社区规模分配 M M M个响应的配额。
M
k
∼
∣
C
k
∣
∑
k
=
1
N
C
∣
C
k
∣
⋅
M
M_{k} \sim \frac{\left|C_{k}\right|}{\sum_{k=1}^{N_{C}}\left|C_{k}\right|} \cdot M
Mk∼∑k=1NC∣Ck∣∣Ck∣⋅M
对于每个簇
C
k
C_{k}
Ck,我们提示LLM生成
M
k
M_{k}
Mk个响应。为了防止生成高度重复的响应,我们的框架可以通过附加指令顺序提示LLM,以阻止类似的表达,或者在解码期间随机化采样种子的同时并行提示。
鉴于社交媒体消息历史和用户在此情境下的
回应,基于情境下的回应表示和聚类文档。
[系统]:您是X(Twitter)用户,浏览特定
内容并喜欢互动。您了解世界新闻和
地缘政治事务,并喜欢与来自您的社区/群体的人在线
交流。您可以阅读多种语言,但您始终用英语书写
帖子。
您将获得新闻文章片段和若干
知识图谱关系作为背景知识,并且您将在您的回复中
写一条新用户提供的帖子的回复推文。您还将
获得示例,说明您所在社区的其他用户如何在类似新帖子的情境下作出回应。
您的写作风格应该类似于Twitter用户。
[用户]:以下是您需要知道的最新信息。
<HEWS_ARTICLE_SNIPPETS>
[片段
1
…
n
1 \ldots n
1…n ]
<
/
</
</ NEWS_ARTICLE_SNIPPETS>
<KNOWLEDGE_GRAPH>[关系 1…n]</KNOWLEDGE_GRAPH>
以下是您所在YOUR
社区的其他用户如何在类似新帖子的情境下作出回应的示例。
<RESPONSE_EXAMPLES>
*[演示 1…n]
</RESPONSE_EXAMPLES>
您的社区是[总结的通用意识形态],
描述为[通用描述]。
给定一个新帖子:[新帖子内容]
作为这个社区的一员,写下您的回应:
图2:专注于响应的嵌入模型的特殊指令,以及SCRAG使用的包含历史响应、意识形态和外部知识的LLM提示。
表一:包括在历史响应数据库中的数据集的级联和交互图的统计(预处理后)。
| 数据集 | 级联图 | 交互图 | |||
|---|---|---|---|---|---|
| #Docs | #Edges | #Assertions | #Users | #Edges | |
| Russophobia | 92,431 | 69,117 | 58,840 | 80,075 | 177,550 |
| US2020 | 109,771 | 89,422 | 66,898 | 130,045 | 172,044 |
| COVID | 67,721 | 63,275 | 43,093 | 108,584 | 113,286 |
| UK | 137,418 | 96,047 | 291,012 | 307,539 | 1,014,606 |
IV. 实验
A. 实验设置
在本节中,我们在 X \mathbb{X} X平台上评估SCRAG框架在六个真实场景中的表现。为了评估预测结果,我们为每个场景设置了30个具有丰富真实响应(30-60个)的测试帖子。SCRAG在大多数场景中使用各种嵌入和LLM模型,在所有四个指标上优于其他基线方法。一个生成示例将直接展示我们框架预测的响应,我们还通过消融研究展示了SCRAG的所有组件的重要性。我们使用公共和自收集的数据集进行四个场景,并根据第III-A1和III-B1节的描述将它们预处理成历史响应数据库。为另外两个场景收集的测试帖子用于通过使用外部知识转移和接地的相似历史响应评估预测,测试我们框架的适应性。SCRAG代码可在https://github.com/dsun9/SCRAG获取。
1)数据集:以下是收集数据的描述:
- Russophobia:从2022年1月至12月使用支持俄罗斯和支持乌克兰的关键词在API过滤器中收集。值得注意的是,它包括“Russophobia”一词的使用,有些人认为这是俄罗斯政府推广的宣传术语。该数据集还包括公共数据集[13]中的样本。
-
- 美国2020年选举(US2020):从2020年12月至2021年1月使用选举关键词和候选人姓名在API过滤器中收集。该数据集还包括公共数据集[14]中的样本。
-
- 新冠肺炎(COVID):从2020年1月至9月收集,正值新冠肺炎爆发初期。该数据集是从公共数据集[15]中抽样而来。
-
- 英国前首相利兹·特拉斯(UK):从2022年6月至11月使用英国前首相“利兹·特拉斯”的名字作为关键词过滤器收集。它包含她当选前和辞职后关于英国前首相的帖子。
-
- 美国2024年选举(US2024):从2024年7月至12月使用与选举相关的关键词过滤器,包括候选人姓名,抽样30个热门测试帖子。
-
- 以色列-哈马斯冲突(加沙地带):从2023年10月至2024年1月使用与冲突相关的关键词过滤器,包括地点和参与冲突的各方名称,抽样30个热门测试帖子。
- 对于前四个数据集,保留每组30个帖子用于测试后,剩余数据被编码到历史响应数据库中。前四个场景与后两个场景的关键区别在于历史响应模块是否可以直接检索匹配情境,还是必须依赖更广泛的语义相似性。我们将后两个称为适应性测试场景,类似于分布外测试,强调外部知识检索模块在从历史响应转移知识和利用外部信息接地预测中的关键作用。
由于预算限制,我们从三个公共数据集中在特定日期范围内抽样了100,000个帖子。此外,我们检索了属于级联结构的父帖。我们还随机收集了多达200条来自根级联帖子的回复,以创建更全面的数据集。数据集统计摘要见表一。
新闻文章从社交媒体帖子中提到的链接和通过GDELT项目[6]使用地理位置和关键词过滤器搜索收集。最终,我们从著名新闻机构如CNN收集了8,061篇新闻文章
表二:SCRAG与两种其他基线在每种场景下使用不同嵌入模型的评估结果。LLM为Llama3.3-70B,我们报告每种场景下30个测试案例的平均值。粗体条目为表现最佳。指标名称后的箭头表示数值越高或越低越好。
| 嵌入 | 方法 | 情感JSD ↓ \downarrow ↓ | 聚类匹配 (%) ↑ \uparrow ↑ | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Russophobia | US2020 | COVID | UK | US2024 | 加沙地带 | Rus (72) | US20 (82) | COV (87) | UK (60) | US24 (79) | 加沙地带 (75) | ||
| VoyageAI | 直接 | 0.453 | 0.261 | 0.357 | 0.437 | 0.474 | 0.348 | 47.41 | 64.07 | 61.67 | 42.00 | 59.63 | 42.67 |
| 少样本 | 0.315 | 0.275 | 0.287 | 0.285 | 0.362 | 0.245 | 55.19 | 59.26 | 57.78 | 45.67 | 65.56 | 38.67 | |
| SCRAG | 0.223 | 0.214 | 0.265 | 0.223 | 0.283 | 0.212 | 55.56 | 67.04 | 58.33 | 48.67 | 68.89 | 47.67 | |
| OpenAI | 直接 | 0.436 | 0.266 | 0.356 | 0.443 | 0.479 | 0.362 | 45.56 | 64.81 | 60.56 | 45.67 | 57.78 | 41.67 |
| 少样本 | 0.268 | 0.269 | 0.341 | 0.281 | 0.419 | 0.261 | 54.44 | 68.89 | 58.89 | 46.00 | 64.81 | 35.00 | |
| SCRAG | 0.263 | 0.265 | 0.306 | 0.240 | 0.335 | 0.236 | 55.19 | 64.81 | 62.22 | 49.33 | 68.52 | 43.33 | |
| NV-Embed2 | 直接 | 0.430 | 0.285 | 0.375 | 0.456 | 0.477 | 0.384 | 51.48 | 55.19 | 63.33 | 40.67 | 55.56 | 35.67 |
| 少样本 | 0.306 | 0.254 | 0.377 | 0.270 | 0.394 | 0.282 | 50.37 | 62.96 | 56.67 | 45.67 | 64.81 | 46.25 | |
| SCRAG | 0.273 | 0.246 | 0.321 | 0.261 | 0.343 | 0.248 | 53.70 | 71.85 | 52.67 | 52.33 | 68.15 | 49.17 | |
| 嵌入 | 方法 | LLM辨别分数 ↑ \uparrow ↑ | 聚类覆盖率 (%) ↑ \uparrow ↑ | ||||||||||
| Russophobia | US2020 | COVID | UK | US2024 | 加沙地带 | Russophobia | US2020 | COVID | UK | US2024 | 加沙地带 | ||
| VoyageAI | 直接 | 7.822 | 8.559 | 7.033 | 8.077 | 8.037 | 7.957 | 58.52 | 39.81 | 25.00 | 51.33 | 33.15 | 55.83 |
| 少样本 | 8.344 | 8.500 | 7.050 | 8.420 | 8.178 | 8.073 | 59.26 | 58.33 | 26.19 | 54.00 | 46.48 | 59.17 | |
| SCRAG | 8.552 | 8.730 | 7.350 | 8.967 | 8.163 | 8.140 | 77.78 | 63.89 | 37.50 | 66.50 | 60.19 | 62.50 | |
| OpenAI | 直接 | 7.863 | 8.407 | 7.039 | 7.960 | 8.019 | 8.107 | 62.04 | 45.37 | 25.00 | 47.33 | 38.33 | 52.50 |
| 少样本 | 8.385 | 8.567 | 6.678 | 8.587 | 7.889 | 8.003 | 62.22 | 47.22 | 33.33 | 63.17 | 40.56 | 64.17 | |
| SCRAG | 8.430 | 8.526 | 7.172 | 8.660 | 8.144 | 8.133 | 62.96 | 56.48 | 37.00 | 65.17 | 53.52 | 45.83 | |
| NV-Embed2 | 直接 | 7.811 | 8.467 | 6.720 | 7.953 | 8.000 | 7.893 | 51.85 | 39.81 | 27.38 | 50.67 | 35.37 | 37.50 |
| 少样本 | 8.337 | 8.470 | 7.350 | 8.677 | 7.967 | 8.100 | 53.70 | 52.78 | 33.00 | 65.67 | 36.85 | 47.92 | |
| SCRAG | 8.422 | 8.504 | 7.707 | 8.693 | 8.081 | 8.171 | 64.81 | 52.96 | 35.00 | 66.50 | 47.96 | 54.17 |
表三:SCRAG与更多LLM(三种参数数量递增的模型和一个商业模型)的少样本基线在每种场景下的评估结果。嵌入模型为VoyageAI,我们报告每种场景下30个测试案例的平均值。粗体条目为表现最佳。箭头含义与上表相同。
| LLM | 方法 | 情感JSD ↓ \downarrow ↓ | 聚类匹配 (%) ↑ \uparrow ↑ | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Russophobia | US2020 | COVID | UK | US2024 | 加沙地带 | Rus (72) | US20 (82) | COV (87) | UK (60) | US24 (79) | 加沙地带 (75) | ||
| Gemma2-9B | 少样本 | 0.247 | 0.227 | 0.341 | 0.243 | 0.259 | 0.306 | 59.63 | 66.67 | 56.67 | 44.00 | 69.26 | 41.00 |
| SCRAG | 0.220 | 0.225 | 0.290 | 0.207 | 0.252 | 0.234 | 64.81 | 71.11 | 60.44 | 45.00 | 70.74 | 44.33 | |
| Qwen2.5-32B | 少样本 | 0.370 | 0.273 | 0.380 | 0.308 | 0.441 | 0.352 | 63.70 | 60.37 | 62.78 | 46.00 | 68.52 | 43.00 |
| SCRAG | 0.305 | 0.287 | 0.362 | 0.301 | 0.357 | 0.352 | 58.15 | 64.07 | 67.22 | 47.92 | 70.37 | 44.67 | |
| Mistral-Large | 少样本 | 0.228 | 0.221 | 0.320 | 0.236 | 0.306 | 0.261 | 51.85 | 64.81 | 55.56 | 48.67 | 69.26 | 47.33 |
| SCRAG | 0.195 | 0.220 | 0.297 | 0.201 | 0.269 | 0.252 | 62.59 | 71.85 | 61.11 | 48.67 | 72.59 | 44.33 | |
| GPT-4o-mini | 少样本 | 0.326 | 0.289 | 0.360 | 0.287 | 0.376 | 0.393 | 57.41 | 66.30 | 63.89 | 47.33 | 65.93 | 44.67 |
| SCRAG | 0.294 | 0.258 | 0.321 | 0.244 | 0.374 | 0.387 | 63.33 | 70.00 | 60.00 | 48.00 | 68.15 | 49.67 | |
| LLM | 方法 | LLM辨别分数 ↑ \uparrow ↑ | 聚类覆盖率 (%) ↑ \uparrow ↑ | ||||||||||
| Russophobia | US2020 | COVID | UK | US2024 | 加沙地带 | Russophobia | US2020 | COVID | UK | US2024 | 加沙地带 | ||
| Gemma2-9B | 少样本 | 8.167 | 8.100 | 6.994 | 7.947 | 7.722 | 8.020 | 66.67 | 45.37 | 28.33 | 62.33 | 46.48 | 60.19 |
| SCRAG | 7.948 | 8.337 | 7.117 | 8.120 | 7.989 | 7.927 | 68.52 | 53.70 | 40.00 | 69.00 | 50.56 | 55.83 | |
| Qwen2.5-32B | 少样本 | 7.944 | 8.304 | 7.044 | 8.000 | 7.848 | 7.927 | 57.41 | 54.63 | 27.38 | 61.50 | 45.00 | 59.17 |
| SCRAG | 8.022 | 7.900 | 7.611 | 8.057 | 7.941 | 7.990 | 68.33 | 62.04 | 28.33 | 64.81 | 54.26 | 6.393 | |
| GPT-4o-mini | 少样本 | 7.956 | 8.237 | 7.267 | 8.407 | 8.081 | 8.033 | 57.41 | 62.04 | 28.33 | 58.17 | 48.70 | 48.33 |
| SCRAG | 8.119 | 8.326 | 7.511 | 8.447 | 8.133 | 8.053 | 61.11 | 55.56 | 31.67 | 60.67 | 51.67 | 60.83 |
以及《华盛顿邮报》,这些文章根据第III-A2节进行预处理。为了获得有效的评估结果,我们使用时间戳相对于测试帖子屏蔽未来的历史和外部数据。在生产环境中,数据库应仅包含过去的数据,因此这不是问题。
2)基线和指标:为展示SCRAG框架的灵活性,我们使用了多个嵌入模型进行测试,包括VoyageAI(voyage-3-large)、OpenAI(text-embedding-3-large)和开源NV-Embed-2模型[16]。我们还展示了其在各种LLMs上的性能,包括Gemma2-9B [17]、Qwen2.5-32B [18]、
Llama3.3-70B [19],Mistral-Large和GPT-4o-mini,涵盖不同规模的LLMs并包括一个商业模型。我们将我们的框架与以下基线方法进行比较:
- 直接提示:直接用新帖子内容提示LLM,并指示它预测响应,提示生成的是 X \mathbb{X} X平台上的回复。
-
- 少样本提示:类似于直接提示,并最多添加五个从历史响应中检索到的响应示例,按检索顺序排列。
- 外部新闻片段也包含在基线提示中以确保公平比较,特别是在适应性测试场景中。我们使用VoyageAI对文章进行编码,进行常规向量检索,并将它们注入提示中。
- 为了定量评估响应预测的性能,我们使用以下指标:
- 情感JSD:我们让LLM提取预测和真实响应的情感内容[20],归一化后得到两个分布。我们计算它们的Jensen-Shannon Divergence(JSD)以评估预测响应的情感相似性(范围为1)。
-
- LLM辨别分数:我们提示LLM对每个预测响应被另一个真实响应的可能性进行评分,评分为1到10分,在显示10个从真实响应中选出的例子后,按其受欢迎程度和文本长度排序。
-
- 聚类匹配百分比:我们使用第三节-B3描述的相同方法对真实响应进行聚类。将预测响应嵌入到相同空间后,我们计算属于其中一个簇的响应比例(忽略异常值)。更高的匹配表示预测响应更相关。
-
- 聚类覆盖率百分比:类似于前一个指标,在对真实响应进行聚类后,我们计算至少有一个预测响应覆盖的簇的百分比。更高的覆盖率表明预测响应在意识形态和语义上具有更大的多样性。
- 由于生成文本量大且预算有限,我们选择了自动指标。为了确保更可靠的指标,我们对需要LLM的指标平均了Qwen2.5-72B、Llama3.370B和Mistral-Large的结果,对需要嵌入模型进行聚类的指标平均了VoyageAI和OpenAI的结果。由于我们在计算聚类匹配百分比时忽略了异常值,我们在表格中报告了其上限及场景名称。
B. 评估结果
表二和表三展示了使用各种嵌入模型和LLMs选择预测配额为30时SCRAG的详细评估结果。简而言之,与基线方法相比,SCRAG在情感JSD方面平均提高了 10.2 % 10.2 \% 10.2%,在LLM辨别分数方面提高了 1.5 % 1.5 \% 1.5%,在聚类匹配百分比方面提高了 4.1 % 4.1 \% 4.1%,在聚类覆盖率百分比方面提高了 11.8 % 11.8 \% 11.8%。表二特别展示了SCRAG在所有四个指标上优于基线方法。它还说明了我们框架适用于各种嵌入模型的普遍性。表三进一步通过不同的LLMs支持这些观察结果,我们的框架在所有场景中表现良好。情感JSD和聚类覆盖率的显著提高证明了我们框架在生成更好地捕捉情感分布和意识形态多样性的响应方面的高有效性。此外,聚类匹配和辨别分数的提高表明我们的框架可以通过检索信息来促进比仅调用LLMs内部知识更相关和现实的预测。
输入帖子,
p
s
p_{s}
ps
“哈马斯的军事分支发布了场景,显示其成员在加沙城的不同部分与以色列占领部队进行近距离战斗。一些人配有装甲车、防弹背心、火炮、航空设备。其他人则穿着运动服,有些旧运动鞋,手持RPG”
生成的响应
- 支持加沙:
- “我看到你在分享来自加沙的一些激烈画面。目睹资源如此不平等以及平民在这场持续斗争中面临的破坏令人心碎。”
- “这正是冲突残酷不对称的体现。一方拥有先进的军事能力,而另一方则凭借纯粹的意志力和绝望作战。这是加沙悲剧现实的鲜明提醒。”
- “加沙的情况令人心碎且复杂。我们必须记住这场冲突背后的人类代价。”
-
- 反对哈马斯:
- “哈马斯的战术在他们的宣传中可能看起来英雄般,但令人悲伤的现实是无辜生命被困在这场交火中。”
- “看起来哈马斯是在粉饰一幅勇敢的画面,但我们都知道这一切是如何开始的,现实要黑暗得多。”
- “看到这种暴力的美化令人不安。当哈马斯准备战斗时,无辜者却为此付出代价。”
-
- 反对以色列:
- “双方都在受苦,但以色列的运作方式引发了对其真正议程的质疑。#加沙战争 #人权”
- “我能想象他们对他们有多反感,他们已经被虐待了75年。”
- “加沙的苦难难以想象。世界还要无视多久?#立即停火”
C. 响应生成示例
我们在表四中展示了一个来自适应性测试场景(以色列-哈马斯冲突)的具体响应生成示例,以展示我们框架的有效性。预测的响应成功地捕捉到了多样化意识形态视角中的情感。情绪JSD和辨别分数的定量评估结果与这些定性观察一致,显示出与输入帖子的高度相关性。预测响应的语义连贯性、现实性和意识形态多样性确认了我们框架的能力。
D. 消融研究
我们对系统中每个组件的重要性进行了消融研究。我们在所有这些实验中使用VoyageAI和Llama3.3。在表五中,我们观察到当所有组件都存在时性能始终有所改善,随着它们离线逐步下降,表明它们共同作用以实现最佳结果。表现第二好的变体是无KG的SCRAG,这表明知识图谱关系通常更为通用,可以与新闻文章一起进一步告知生成过程。
表五:SCRAG组件单独离线的消融研究评估结果。“Ideo”表示包含用于聚类的意识形态嵌入(组合聚类)。“SP”表示稀疏检索新闻文章而非密集检索。粗体条目为表现最佳,下划线条目为表现第二佳。
| 方法 | 情感JSD ↓ \downarrow ↓ | 聚类匹配 (%) ↑ \uparrow ↑ | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Russophobia | US2020 | COVID | UK | US2024 | 加沙地带 | Rus (72) | US20 (82) | COV (87) | UK (60) | US24 (79) | |
| 完整(SCRAG) | 0.223 | 0.214 | 0.265 | 0.223 | 0.283 | 0.212 | 55.56 | 67.04 | 58.33 | 48.67 | 68.89 |
| 无KG | 0.263 | 0.246 | 0.310 | 0.246 | 0.295 | 0.228 | 54.81 | 66.67 | 57.33 | 45.00 | 67.04 |
| 无KG & Ideo | 0.253 | 0.252 | 0.298 | 0.252 | 0.299 | 0.238 | 52.96 | 66.30 | 56.67 | 42.33 | 72.22 |
| 无KG & Ideo & SP | 0.270 | 0.275 | 0.305 | 0.262 | 0.318 | 0.234 | 48.15 | 62.22 | 56.67 | 43.67 | 64.07 |
| 方法 | LLM辨别分数 ↑ \uparrow ↑ | 聚类覆盖率 (%) ↑ \uparrow ↑ | |||||||||
| Russophobia | US2020 | COVID | UK | US2024 | 加沙地带 | Russophobia | US2020 | COVID | UK | US2024 | |
| 完整(SCRAG) | 8.552 | 8.730 | 7.350 | 8.967 | 8.163 | 8.140 | 77.78 | 63.89 | 37.50 | 66.50 | 60.19 |
| 无KG | 8.515 | 8.570 | 7.244 | 8.830 | 8.130 | 8.117 | 75.93 | 68.52 | 36.67 | 65.17 | 61.30 |
| 无KG & Ideo | 8.433 | 8.656 | 7.228 | 8.717 | 8.096 | 8.107 | 70.37 | 55.56 | 33.33 | 63.17 | 49.81 |
| 无KG & Ideo & SP | 8.419 | 8.644 | 7.150 | 8.770 | 8.067 | 8.097 | 62.96 | 58.33 | 25.00 | 62.96 | 44.26 |
表六:SCRAG两种设计选择的消融研究评估结果。粗体条目为表现最佳,下划线条目为表现第二佳。
| 方法 | 情感JSD ↓ \downarrow ↓ | LLM辨别分数 ↑ \uparrow ↑ | 聚类匹配 (%) ↑ \uparrow ↑ | 聚类覆盖率 (%) ↑ \uparrow ↑ | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Russophobia | UK | US2024 | Russophobia | UK | US2024 | Rus (72) | UK (60) | US24 (79) | Russophobia | UK | US2024 | |
| 完整(SCRAG) | 0.223 | 0.223 | 0.283 | 8.552 | 8.967 | 8.163 | 55.56 | 48.67 | 68.89 | 77.78 | 66.50 | 60.19 |
| 无UMAP | 0.264 | 0.245 | 0.317 | 8.326 | 8.763 | 8.133 | 54.81 | 47.33 | 70.00 | 72.22 | 63.17 | 59.07 |
| 无Inst | 0.273 | 0.239 | 0.345 | 8.544 | 8.700 | 8.152 | 51.85 | 46.00 | 68.52 | 72.22 | 62.96 | 54.26 |
| 无Inst & UMAP | 0.284 | 0.246 | 0.350 | 8.230 | 8.810 | 8.126 | 51.33 | 45.00 | 65.93 | 64.81 | 62.33 | 49.81 |
当意识形态嵌入和稀疏检索组件禁用时,性能略高于基线方法。这表明意识形态信息对于社区识别至关重要,而新闻文章的稀疏检索在我们的设置中是一个更好的选择,其中输入帖子通常是短文本。
在表六中,我们展示了两种设计选择的有效性:语义嵌入的UMAP降维和嵌入模型的特殊指令。由于篇幅限制,我们仅展示了三个数据集的结果,但结论相同。在大多数情况下,带有UMAP的变体优于没有它的变体,关于特殊嵌入指令可以得出类似的结论。这一结果是可以预期的,因为没有UMAP,意识形态嵌入会减弱,因为其维度远小于原始语义嵌入。特殊指令是必不可少的,因为重点应该放在增强帖子的响应上,而不是忽视其结构。
V. 相关工作
预测社交媒体上的响应因其非正式和动态的性质具有挑战性。数据驱动的方法[21]通过利用大型数据集学习响应模式开创了社交媒体响应生成的先河。为了提高相关性,TA-Seq2Seq[22],一种主题感知神经响应生成模型,结合了主题信息。另一种响应生成方法是基于上下文的原型编辑[23],模型通过编辑现有原型生成响应,依据对话上下文。最后,CGRG[24]开发了一种可控的基于事实的响应生成模型,允许对响应进行更精确的控制。尽管先前的工作探索了信息检索技术,
情境感知生成和事实依据,但他们尚未研究LLMs的潜力。他们的应用通常限于自动补全或聊天机器人,而我们的目标是开发一个预测社区响应的框架,从而实现各种社会应用。
RAG将检索机制与生成模型相结合,以改进知识密集型任务。REALM[25]引入了检索增强语言模型预训练,利用外部知识改进语言理解。这种方法在[5]中进一步发展,用于知识密集型NLP任务,将检索直接集成到生成过程中。有调查[26],[27]提供了RAG方法及其应用的全面概述。尽管这些应用,标准RAG方法在高度动态的环境中如社交媒体面临挑战,主要是由于计算成本高昂。结果,历史响应数据库更新频率较低。与密集检索方法相比,稀疏检索技术如TF-IDF和BM25[28]计算成本更低,但依赖术语匹配,导致准确性较低。SPLADE[12]通过采用查询扩展技术改进检索准确性以解决术语匹配问题,使其适合我们的目标,即基于较短的社交媒体帖子搜索较长的新闻文章。受社交计算启发,我们的框架采用结合密集和稀疏检索的RAG方法以满足不同需求。
开发了各种表示学习技术以编码社交实体。用户与帖子之间的交互封装了他们的信仰和偏好,可以用来提取用户的意识形态嵌入和帖子的嵌入。现有研究通常将交互历史建模为图以导出社交表示。
变分图自编码器(VGAE)[29]引入了一个框架,其中包括基于GCN的编码器和内积解码器,将用户和消息映射到一个正态分布变量的潜在空间。InfoVGAE [7] 和 SGVGAE [8] 提出了非负VGAE模型,能够捕捉用户和消息的意识形态,将其编码到一个可解释的空间。我们利用这些技术来增强语义嵌入和聚类。
VI. 结论
本文介绍了SCRAG,这是一个框架,它通过整合基于社交计算的RAG方法与LLMs来预测社区对真实或假设社交媒体帖子的响应。通过对 X \mathbb{X} X平台上六个真实场景的广泛实验评估,我们证明SCRAG始终优于基线方法,生成现实、多样化且情境相关的预测。使用各种嵌入模型和LLMs的进一步实验确认了SCRAG的模块化和鲁棒性。一个响应生成示例展示了框架在准确捕捉反映真实社区动态的意识形态和情感细微差别的有效性。消融研究突显了SCRAG中每个组件的贡献,强调了社区感知历史响应模块和外部知识模块在实现最佳性能方面的重要性。总体而言,SCRAG为公共情绪预测和社会假设分析等社交计算应用提供了一个强大的工具。
展望未来,我们计划通过添加多模态功能扩展我们的框架,将多媒体数据与文本输入相结合,以进一步提高预测准确性,这将提供对不断演变的社会对话更深的洞察。
致谢
本论文所述研究部分由DEVCOM ARL根据合作协定W911NF-1720196、NSF CNS 20-38817和波音公司资助。该研究还部分得到了ACE的支持,ACE是JUMP 2.0中的七个中心之一,这是一个由DARPA资助的Semiconductor Research Corporation (SRC)项目。本文件中包含的观点和结论仅代表作者的观点,不应解释为代表陆军研究实验室或美国政府的官方政策,无论是明示还是暗示。美国政府有权为政府目的复制和分发重印本,无论此处是否有版权注释。
参考文献
[1] T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell 等,“语言模型是少样本学习者”,Advances in NIPS,卷33,页1877-1901,2020年。
[2] J. Wei, Y. Tay, R. Bommasani, C. Raffel, B. Zoph, S. Borgeaud, D. Yogatama, M. Bosma, D. Zhou, D. Metzler 等,“大型语言模型的新兴能力”,arXiv预印本arXiv:2206.07682,2022年。
[3] J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat 等,“Opt-4 技术报告”,arXiv预印本arXiv:2303.08774,2023年。
[4] T. Zhang, F. Ladhak, E. Durmus, P. Liang, K. McKeown, 和 T. B. Hashimoto,“大型语言模型在新闻摘要中的基准测试”,ACL Transactions,卷12,页39-57,2024年。
[5] P. Lewis, E. Perez, A. Piktus, F. Petroni, V. Karpukhin, N. Goyal 等,“检索增强生成用于知识密集型NLP任务”,Advances in NIPS,卷33,页9459-9474,2020年。
[6] “GDELT项目。” [在线]. 可用:https://www.gdeltproject.org/
[7] J. Li, H. Shao, D. Sun, R. Wang, Y. Yan, J. Li, S. Liu, H. Tong, 和 T. Abdelzaher,“使用信息理论变分图自编码器的无监督信念表示学习”,Proceedings of the 45th International ACM SIGIR Conference,2022年,页1728-1738。
[8] J. Li, R. Han, C. Sun, D. Sun, R. Wang, J. Zeng 等,“大型语言模型引导的极化社交图解纠缠信念表示学习”,33rd ICCCN. IEEE,2024年,页1-9。
[9] L. McInnes, J. Healy, 和 J. Melville,“UMAP:统一流形逼近和投影用于降维”,arXiv预印本arXiv:1802.03426,2018年。
[10] L. McInnes, J. Healy, S. Astels 等,“HDBSCAN:基于层次密度的聚类”。J. Open Source Softw., 卷2,号11,页205,2017年。
[11] J. Carbonell 和 J. Goldstein,“MMR、基于多样性的重新排序在文档重新排序和摘要生成中的应用”,Proceedings of the 21st annual international ACM SIGIR conference,1998年,页335-336。
[12] T. Formal, B. Piwowarski, 和 S. Clinchant,“SPLADE:稀疏词汇和扩展模型用于第一阶段排名”,Proceedings of the 44th International ACM SIGIR Conference,2021年,页2288-2292。
[13] E. Chen 和 E. Ferrara,“冲突时期推文:追踪乌克兰与俄罗斯战争的Twitter讨论的公共数据集”,Proceedings of the 17th ICWSM,卷17,2023年,页1006-1013。
[14] E. Chen, A. Deb, 和 E. Ferrara,“#election2020:2020年美国总统选举的第一个公共Twitter数据集”,Journal of Computational Social Science,页1-18,2022年。
[15] E. Chen, K. Lerman, 和 E. Ferrara,“跟踪社交媒体关于新冠疫情的讨论:公共冠状病毒Twitter数据集的开发”,JMIR Public Health and Surveillance,卷6,号2,页e19273,2020年。
[16] C. Lee, R. Roy, M. Xu, J. Raiman, M. Shoeybi, B. Catanzaro, 和 W. Ping,“NV-Embed:改进作为通用嵌入模型训练LLMs的技术”,arXiv预印本arXiv:2405.17428,2024年。
[17] G. Team, M. Riviere, S. Pathak, P. G. Sessa, C. Hardin, S. Bhupatirajn, L. Hussenot 等,“Gemma 2:在实用规模上改进开放语言模型”,arXiv预印本arXiv:2408.00118,2024年。
[18] A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Li, D. Liu, F. Huang, H. Wei 等,“Qwen2.5 技术报告”,arXiv预印本arXiv:2412.15115,2024年。
[19] A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Yang, A. Fan 等,“Llama 3 模型群”,arXiv预印本arXiv:2407.21783,2024年。
[20] R. Plutchik,“测量情绪及其衍生品”,The measurement of emotions. Elsevier,1989年,页1-35。
[21] A. Ritter, C. Cherry, 和 B. Dolan,“社交媒体中的数据驱动响应生成”,EMNLP,2011年。
[22] C. Xing, W. Wu, Y. Wu, J. Liu, Y. Huang, M. Zhou, 和 W.-Y. Ma,“话题感知神经响应生成”,Proceedings of the AAAI Conference,卷31,号1,2017年。
[23] Y. Wu, F. Wei, S. Huang, Y. Wang, Z. Li, 和 M. Zhou,“基于上下文感知原型编辑的响应生成”,Proceedings of the AAAI Conference,卷33,号01,2019年,页7281-7288。
[24] Z. Wu, M. Galley, C. Brockett, Y. Zhang, X. Gao, C. Quirk, R. KoncelKedziorski, J. Gao, H. Hajishirzi, M. Ostendorf 等,“基于事实的响应生成的可控模型”,Proceedings of the AAAI Conference,卷35,号16,2021年,页14 085-14 093。
[25] K. Guu, K. Lee, Z. Tung, P. Pasupat, 和 M. Chang,“检索增强语言模型预训练”,International conference on machine learning. PMLR,2020年,页3929-3938。
[26] H. Li, Y. Su, D. Cai, Y. Wang, 和 L. Liu,“检索增强文本生成综述”,arXiv预印本arXiv:2202.01110,2022年。
[27] Y. Gao, Y. Xiong, X. Gao, K. Jia, J. Pun, Y. Bi, Y. Dai, J. Sun, 和 H. Wang,“大型语言模型的检索增强生成:综述”,arXiv预印本arXiv:2312.10997,2023年。
[28] S. Robertson, H. Zaragoza 等,“概率相关框架:BM25 及其超越”,Foundations and Trends® in Information Retrieval,卷3,号4,页333-389,2009年。
[29] T. N. Kipf 和 M. Welling,“变分图自编码器”,arXiv预印本arXiv:1611.07308,2016年。
参考论文:https://arxiv.org/pdf/2504.16947


















 15万+
15万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











