






Zhicong Li 1 { }^{1} 1 Hangyu Mao 2 { }^{2} 2 Jiangjin Yin 3 { }^{3} 3 Mingzhe Xing 2 { }^{2} 2 Zhiwei Xu 4 { }^{4} 4 Yuanxing Zhang 2 { }^{2} 2 Yang Xiao 2 { }^{2} 2
摘要
本文认为,下一代AI智能体(NGENT)应整合跨领域能力,以向人工通用智能(AGI)迈进。尽管当前的AI智能体在机器人技术、角色扮演和工具使用等专门任务中表现出色,但它们仍然局限于狭窄的领域。我们提出未来AI智能体应将这些专门系统的优点综合到一个统一框架中,能够跨越文本、视觉、机器人技术、强化学习、情感智能等领域运行。这种整合不仅可行,而且对于实现人类智能所具有的多样性和适应性至关重要。随着AI各领域的技术融合以及用户对跨领域能力需求的增加,这种整合触手可及。最终,开发这些多功能智能体是实现AGI的关键一步。本文探讨了这一转变的理由以及实现它的潜在途径。
1. 引言
广义上讲,AI智能体是设计用于自主执行任务(采取行动)以追求特定目标的系统,利用从环境中收集的信息。这些智能体的关键组件包括:感知——获取环境信息的过程(例如通过传感器或数据输入);推理与规划——解释此信息并做出决策的能力;行动——通过物理或虚拟手段执行这些决策(例如移动机器人或发送消息);学习——根据反馈或新数据调整行为的能力。
AI智能体的演变大致可分为三个阶段。(1)基于规则的AI智能体:早期智能体是简单的基于规则的系统,旨在执行狭义定义的任务(Franklin, 1997; Castelfranchi, 1998; Alonso, 2002)。著名的例子包括用于国际象棋的Deep Blue系统(Campbell et al., 2002)和用于专门功能(如医疗诊断)的早期专家系统(Shortliffe, 1986)。(2)基于机器学习的AI智能体:相比之下,现代智能体利用机器学习(Mitchell & Mitchell, 1997),特别是深度学习(LeCun et al., 2015),使它们能够处理更复杂的任务,如对话生成(Li et al., 2016)、图像识别(Krizhevsky et al., 2012)和自主导航(Bagnell et al., 2010)。这些智能体比其前辈展现出更大的适应性和灵活性。尽管有这些进步,基于规则和基于学习的智能体通常在特定领域内表现卓越,但在尝试跨不同任务转移知识或技能时面临挑战。(3)基于基础模型的AI智能体:基于大型语言模型(LLM)和大型多模态模型(LMM)的智能体为智能体领域带来了深刻变化(Xi et al., 2023; Wang et al., 2024b)。这些AI智能体配备了嵌入在LLM和LMM中的广泛知识,能够执行比其前辈更广泛的多种任务,从角色扮演(Shao et al., 2023; Chen et al., 2024)、工具使用(Schick et al., 2023; Ruan et al., 2023)和编码开发(Roziere et al., 2023; Li et al., 2024; Zhang et al., 2024b)到计算机控制(Hong et al., 2024; Niu et al., 2024)。
尽管这些AI智能体具备广泛的能力,它们仍受限于特定领域。例如,尽管角色扮演智能体可以以细致的语调生动地描绘不同个性,工具使用智能体可以利用各种工具如天气和地图API,但它们的编码和计算机控制能力往往较差。反之亦然:擅长编码或计算机控制的智能体可能在其他领域任务中挣扎。即使由顶级LLM驱动的智能体如OpenAI O1(Jaech et al., 2024)也存在这一限制。
我们认为,AI发展的下一个飞跃必须专注于克服特定领域的局限性。正如图1所示,类似于GPT-3和GPT-4通过在几乎所有NLP任务中表现出色而革新自然语言处理,我们提出下一代AI智能体应在多个领域展示类似的多样性,从个人助理和角色扮演到编码、工具使用、数学问题解决等。这种整体方法标志着向实现AGI迈出的重要一步。
实现这一愿景需要克服几个关键挑战,包括将不同的专业能力整合到统一架构中、开发多任务学习模型以及在各种用例中保持高性能。我们认为,向这些下一代智能体的转变不仅是可行的,而且对AI领域的持续进步至关重要。在本文中,我们将概述这一转变的理由,并探讨其实现的潜在途径。
2. 支持
我们首先讨论AGI的整体目标和日益增长的用户需求,这强调了下一代AI智能体整合跨领域能力的必要性。然后我们介绍技术融合,突出未来AI智能体实现这种整合的可能性。
2.1. 朝向AGI研究
认知科学表明,真正的智能不是狭隘的专门化,而是跨多个领域的灵活和适应性(Norman, 1980; Sternberg, 1999)。例如,人类不只擅长一项任务;他们不断在角色、上下文和挑战之间切换。
AGI的最终目标是创造一台机器,能够在广泛的任务中理解和学习知识,以一种与人类智能相当的方式进行应用。现有的AI系统(尤其是本文讨论的AI智能体),虽然令人印象深刻,但仍远未达到这一目标。开发整合多种能力的下一代AI智能体是通往AGI的关键步骤。
2.2. 用户对多功能AI系统的需求
多功能、全方位AI系统的需求增加是由消费者和企业需求推动的。目前的个人助手,如Google Assistant和Amazon的Alexa,提供广泛的服务,但其能力仍因缺乏整合而受到限制。需要一种可以在工作场所自动化重复任务,同时提供技术支持和个性化建议的工具的用户,通常必须依赖多个不同的系统。
下一代智能体可以将这些功能整合到单一界面中,简化用户交互。这将在节省时间、提高效率以及以连贯方式处理多步工作流程方面提供实际好处。例如,一个通用目的AI智能体可以在同一背景下自动化技术故障排除、提供创意指导和协助个人管理任务。
2.3. 技术融合
2.3.1. 模型架构融合
对于基于LLM的智能体。很明显,基于Transformer的架构构成了GPT-4的核心基础,它在广泛的NLP任务中表现出色。
建立在像GPT-4这样的模型架构基础上,研究人员开发了各种类型的基于LLM的AI智能体:一些专注于高度智能化的助手,如ChatGPT,在跨领域的解决问题和信息检索方面表现出色;另一些则强调角色扮演智能体,如Character.AI,专注于模拟人性化个性以实现互动交流。此外,还有用于自动化工作流的工具使用智能体(Qu et al., 2024; Ruan et al., 2023; Kong et al., 2024; 2023)和用于软件开发的编码助手(Roziere et al., 2023; Guo et al., 2024; Li et al., 2024; Zhang et al., 2024b)也得到了广泛认可。
对于基于LMM的智能体。当前AI系统在同时处理多种类型输入方面的能力迅速提升。例如,OpenAI的GPT-4o(Hurst et al., 2024)代表了更自然的人机交互的重大进步,因为它可以接受任何组合的文本、音频、图像和视频作为输入,并生成任何组合的文本、音频和图像输出。这种“全合一”模型同样基于Transformer架构,针对不同模态的数据设计了不同的标记器。研究还越来越关注开发能够有效处理多模态任务的统一Transformer模型(Wang et al., 2022)。
对于多模态AI智能体,关键的研究领域是操作系统(OS)智能体,旨在通过移动应用程序(Wang et al., 2024a; Lee et al., 2024; Zhang et al., 2023b)、桌面应用程序(Wu et al., 2024; Hoscilowicz et al., 2024)或网络界面(He et al., 2024; Iong et al., 2024; Koh et al., 2024)来控制计算设备,从而显著提高用户设备交互的效率。此外,还有其他基于LMM的智能体,如用于视觉工具使用的Llava-plus(Liu et al., 2025)以及详细的调查(Xie et al., 2024)。这些智能体的模型架构主要基于“全合一”Transformer。
对于机器人智能体及其他。我们在其他领域观察到类似趋势,即越来越多地依赖基于Transformer的模型。例如,在强化学习(RL)领域,Decision Transformer(Chen et al., 2021)和Trajectory Transformer(Janner et al., 2021)已成为离线RL智能体的主要架构,而原始Transformer已被直接使用或开发其他Transformer架构用于在线RL智能体(Zheng et al., 2022; Mao et al., 2022b; 2023; Zhang et al., 2024a)。在机器人领域,RT-1(Brohan et al., 2022)和RT-2(Brohan et al., 2023)架构是通过对原始Transformer架构进行小修改设计的。
总结。在各种AI智能体中,无论是LLM、LMM、机器人还是RL,都有一个明显的趋势采用和适应基于Transformer的架构。这种融合表明下一代AI智能体有可能被整合到一个统一系统中,能够处理跨领域的任务,包括与文本、视觉、机器人相关的任务等。
2.3.2. 学习算法的进步
显然,多任务学习、迁移学习、自监督学习、元学习和强化学习 1 { }^{1} 1的进步正在汇聚,为下一代AI智能体提供了必要的基础。这些算法创新赋予智能体从大量未标注数据中学习和适应的能力,最终促进将专门能力整合到一个统一、多功能的系统中。
最近,工具学习(Qin et al., 2023a)作为一种强大的技术引起了广泛关注。通过为AI智能体配备各种工具,它们可以应对不同领域的多样化任务。例如,HuggingGPT(Shen et al., 2024)利用来自Hugging Face的各种AI模型来解决一系列复杂的AI相关任务,涵盖语言、视觉、语音等,取得了令人印象深刻的成果。同样,ToolLLM(Qin et al., 2023b)掌握了超过16,000个现实世界API,以解决日常任务,将其能力扩展到超越AI特定问题的范围(例如股票交易、订购食品等)。许多最近的工具学习方法遵循这种方法,例如Toolformer(Schick et al., 2023)、TPTU(Ruan et al., 2023)、TPTU-2(Kong et al., 2024)和Chameleon(Lu et al., 2024),进一步展示了整合工具以增强下一代AI智能体多功能性和能力的潜力。
总结。结合工具学习和多任务学习似乎可以引领真正下一代AI智能体(NGENTs)的发展——也就是说,一个单一的AI智能体可以通过一套涵盖所有任务类型的工具来处理所有任务。
2.3.3. AI智能体组件的融合
AI智能体组件的融合变得越来越明显。如第一部分所述,AI智能体的核心组件包括感知、推理与规划、行动和学习。感知涉及收集环境数据(例如通过传感器或数据输入),而推理与规划使智能体能够解释这些信息并做出决策。行动是执行这些决策,要么是物理上的(例如移动机器人),要么是虚拟上的(例如发送消息)。学习允许AI智能体根据反馈或新数据调整其行为。此外,一些AI智能体集成了其他组件,如短期和长期记忆,这些组件有助于跟踪历史背景、改进决策并减少冗余动作。
这些组件背后是我们在讨论中提到的各种技术,例如使用不同工具进行感知和行动,利用基于Transformer的基础模型进行推理和规划,以及使用各种算法进行学习。
总结。模块化、可扩展的AI智能体的发展使得可以根据手头任务轻松交换或替换组件,提供了极大的灵活性。这种模块化对于创建能够高效执行各种任务的统一AI智能体至关重要。
2.4. 支持总结
AGI的最终目标是开发能够执行广泛任务的AI,类似于人类智能。对多功能系统日益增长的需求要求AI智能体能够将多种功能整合到单一界面中。技术融合正在推动这一进展:基于Transformer的模型在各种AI领域中得到越来越多的应用,而学习算法的进步,如多任务学习和工具学习,使智能体能够处理多样化的任务。此外,模块化的AI组件增强了灵活性和适应性。这些趋势为能够自主学习、适应并在不同领域执行任务的下一代AI智能体铺平了道路。我们主张研究人员应更加关注这种集成方法,推进下一代AI智能体的发展,同时减少对解决孤立领域的第一代AI智能体的碎片化研究。
3. 实现NGENT的可能途径
鉴于上述支持,特别是各种技术的融合,下一代AI智能体的设计和实现看起来既可行又迫在眉睫。实际上,我们相信将这些能力整合到单一AI智能体中是一个近期可能性。
然而,一个关键挑战依然存在:不同任务表现出不同的分布。大多数前面讨论的任务倾向于基于智商(IQ),但也存在一类专注于情商(EQ)的任务。将基于IQ和EQ的任务整合到单一AI智能体中更具挑战性,因为这些任务通常朝着不同的方向发展。一个高IQ的AI智能体通常需要关注抽象推理、效率和事实准确性,而一个高EQ的AI智能体则需要更细致的方法,强调情商、同理心和吸引人的沟通。
如图2所示,一个有希望的途径是首先通过将智能辅助与友好的用户形象相结合来实现IQ和EQ之间的平衡。虽然这两种范式看似不同,但它们并非完全独立。事实上,有效人物形象管理所需的智能可以视为智能辅助能力的一种延伸,特别是在对话、任务管理和个性化互动方面。
这一见解指向了“1.5代智能体”(1.5-G Agent)的潜力。通过首先开发成功整合智能辅助与友好用户形象的混合模型,我们可以为未来的进化奠定基础。在这个模型中,智能辅助将在核心功能性任务(如编码、数学问题解决和工具使用)中占据主导地位,而人物形象方面将优化为吸引人且人性化的互动。人物形象不会作为一个单独的功能,而是会与智能体的核心智能深度融合,增强用户体验而不损害其功能性。
“1.5代智能体”模型可以作为迈向完整2.0版本的下一代智能体(2.0-G NGENT)的垫脚石,后者能够在没有特定领域专业化的情况下执行广泛的基于IQ和EQ的任务。
最终,尽管实现完全成熟的AGI系统可能仍需时日,但2.0-G NGENT将为实现这一目标提供宝贵的见解。
4. 初步实验
在本节中,我们研究“1.5代智能体”是否可能。我们开发了一个全面的训练管道,包含三个阶段:指令预训练(IPT)、监督微调(SFT)和DPO训练。每个阶段都旨在解决智能体不同能力方面的不同问题,以前一个为基础逐步完善模型在IQ和EQ之间的平衡。
4.1. 指令预训练
传统的继续预训练(CPT)方法涉及进一步训练和优化现有LLM以应用于特定领域。这种方法通常需要更高的计算资源支出和增加的时间成本。因此,我们提出了一种新的IPT方法来替代CPT,该方法仅使用大约1%的训练数据即可取得优异的实验结果。
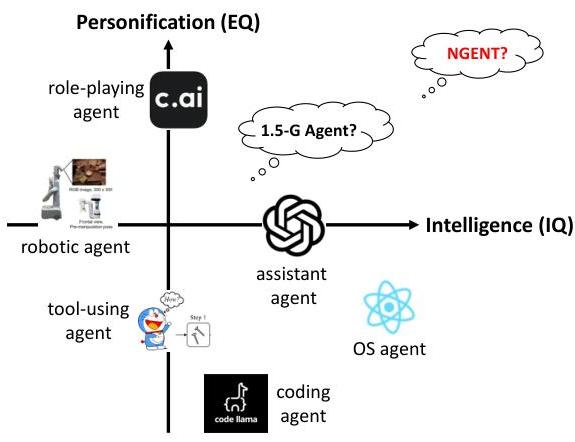
图2. 基于基础模型的AI智能体景观。当前研究主要集中在特定领域,如智能助手(例如ChatGPT)、角色扮演(例如C.AI)、编码(例如CodeLlama(Roziere et al., 2023)和Deepseek-Coder(Guo et al., 2024))、工具使用(例如TPTU(Ruan et al., 2023)和TPTU-2(Kong et al., 2024))、操作系统操作(例如OS-copilot(Wu et al., 2024))或机器人控制(例如RT-1(Brohan et al., 2022)和RT-2(Brohan et al., 2023))。然而,我们认为下一代智能体必须超越个别专长,而是体现旨在实现AGI的一般能力,无缝整合多种技能以在广泛的任务和情境中运行。在本文中,我们提出了实现这一目标的一个步骤,即引入“1.5代智能体”的概念,重点在于整合智能与拟人化的关键挑战,最终为下一代AI智能体(NGENT)的发展铺平道路。
具体来说,在我们的工作中,我们关注智能体在与用户的多轮对话中的人物拟人化能力和智力水平。鉴于大多数基础模型本质上具有高水平的智力但缺乏拟人化,我们在IPT阶段强调引入个性化数据集以解决这一缺陷。具体而言,我们从小说、剧本和社交媒体中收集对话作为我们的数据集。这类数据自然密集,包含广泛的角色设定和现实生活中的对话,使用它可以增强智能体的个性化能力。
正式地,考虑连接
U
=
{
N
,
C
,
D
}
\mathcal{U}=\{\mathcal{N}, \mathcal{C}, \mathcal{D}\}
U={N,C,D},其中
N
\mathcal{N}
N 描述背景叙述,
C
\mathcal{C}
C 表示角色名称,
D
\mathcal{D}
D 指对话。给定第
t
t
t轮之前的标记,IPT目标在数据集
U
\mathcal{U}
U上可以表示如下:
L I P T = − log p ( D ∣ N , C ) = − ∑ t = 1 T D log p ( D t ∣ D < t , N < t , C < t ) \begin{aligned} \mathcal{L}_{I P T} & =-\log p(\mathcal{D} \mid \mathcal{N}, \mathcal{C}) \\ & =-\sum_{t=1}^{T_{\mathcal{D}}} \log p\left(\mathcal{D}_{t} \mid \mathcal{D}_{<t}, \mathcal{N}_{<t}, \mathcal{C}_{<t}\right) \end{aligned} LIPT=−logp(D∣N,C)=−t=1∑TDlogp(Dt∣D<t,N<t,C<t)
其中 T D T_{\mathcal{D}} TD 是 U \mathcal{U} U 的总对话轮次。换句话说,我们计算与角色对话部分相关的损失,同时保留角色名称和背景叙述。这种方法有助于模型理解每个角色的特质,从而有效地学习不同的个性。
4.2. 监督微调
在此阶段,主要目标是激活和增强智能体模拟个性的能力,同时不削弱甚至增强其智力。为了实现这一点,我们提出了一种人格化风格重写器(PSR),并开发了一个依赖少量手动注释种子数据的高质量数据生成过程。此外,引入了一种迭代训练范式,以显著提升智能体在人格化和智力方面的表现。
4.2.1 数据准备
合成个性数据生成。为了防止智能体过度适应单一个性,创建大量的个性角色卡以增强智能体理解和适应各种个性的能力至关重要。我们从各种来源收集了超过10万个个性角色,包括历史人物、电影IP、虚拟角色等。然后根据每个角色的基本信息、特征和对话风格提取个性特征,从而构建对应不同角色的个性档案。
在获得大量个性角色卡后,我们利用这些卡片以及预先准备的种子问题数据集生成并手动精炼一系列高质量的种子数据,通过模仿这些个性。随后,我们使用这些档案和相应的种子数据示例作为少量样本生成大量响应。
尽管这些响应包含了档案中描述的个性特征,但一些现代角色卡片的回复仍然过于正式。为了解决这个问题,我们提出了人格化风格重写器(PSR),以将这些回复转换为更具人性化的响应。
PSR模型训练和响应增强。由于其作为助手的角色,大多数现有的LLM通常保持正式语气,即使被指示模拟人类反应也是如此。这常常使用户明显意识到他们正在与机器人而非人类互动。因此,人格化响应风格对于增强个性属性至关重要。为了训练一个能够实现这种人性化的重写器,有必要构建一个特定的数据集。然而,LLM固有的正式语气构成了一项挑战,因为它阻碍了直接从现有的强大LLM(如GPT-4)合成生成人性化标签。
为克服这一问题,我们采用了相反的策略,利用LLM生成正式响应的优势。我们提示GPT-4重写真实的用户聊天,记为 c c c。重写的结果 c ′ c^{\prime} c′自然表现出正式语气。这些对 ( c ′ , c ) (c^{\prime}, c) (c′,c)被用作训练数据集来开发我们的PSR模型。随后,我们使用PSR进一步精炼现代角色个性的响应,生成最终合成的人格数据集 D p D_{p} Dp。
面向个性的智能对比数据集构建。仅用个性数据集 D p D_{p} Dp训练代理会导致一个重大问题:被赋予特定个性的代理可能会避免回答或假装不知道那些它们本来有能力解决的问题,导致智力感知下降。这是因为个性训练数据集中于角色对话,这些对话包含较少的事实和信息元素。为了解决这个问题,我们提出了一种新颖的面向个性的智能对比数据集构建策略,以增强代理在特定个性情境下的认知能力。
具体来说,对于原始SFT数据集中的每一对数据 ( q i , a i ) (q_{i}, a_{i}) (qi,ai),其中 q i q_{i} qi表示查询, a i a_{i} ai表示答案,我们重新生成一个反映每个个性 p i p_{i} pi的定制响应 a i p a_{i}^{\mathrm{p}} aip。随后,我们将 ( q i , a i ) (q_{i}, a_{i}) (qi,ai)和 ( q i , a i p ) (q_{i}, a_{i}^{\mathrm{p}}) (qi,aip)都纳入我们的数据集中,从而构建一个面向个性的智能对比数据集,记为 D c D_{c} Dc,它与 D p D_{p} Dp结合形成我们全面的最终数据集 D = D p ∪ D c D=D_{p} \cup D_{c} D=Dp∪Dc。因此,在训练阶段,代理不仅保留或增强了其认知能力,还获得了在不同个性配置文件下适当响应的能力。
4.2.2 迭代监督微调
在传统的多轮指令微调中,训练样本通常由 k k k个查询-响应对组成,记为
x = ( q 1 , r 1 , q 2 , r 2 , … , q k , r k ) x=\left(q_{1}, r_{1}, q_{2}, r_{2}, \ldots, q_{k}, r_{k}\right) x=(q1,r1,q2,r2,…,qk,rk)
其中 q i q_{i} qi和 r i r_{i} ri分别指第 i i i轮的查询和响应。模型通过预测响应部分的标记进行训练,这在公式3中进行了表述。
L response = − ∑ i = 1 L log p ( x i ∣ x < i ) , x i ∈ r \mathcal{L}_{\text {response }}=-\sum_{i=1}^{L} \log p\left(x_{i} \mid x_{<i}\right), x_{i} \in r Lresponse =−i=1∑Llogp(xi∣x<i),xi∈r
这里, L L L指的是 x x x的总长度, r r r表示 x x x内的所有响应段。
考虑到人类查询通常是复杂和多样的,单靠数据收集很难全面覆盖。为此,我们引入了实时数据增强方法和迭代SFT训练范式。
具体来说,我们首先微调基础模型 M 0 M_{0} M0以开发一个提问代理 M a s k M_{a s k} Mask,它模拟用户的角色。这种训练方法遵循传统的SFT实践,但对损失函数进行了轻微调整,使得只有查询段内的标记被考虑,详情见公式(4)。同时,在数据集 D D D上,我们根据公式(3)微调 M 0 M_{0} M0以获得 M 1 M_{1} M1。这个代理 M 1 M_{1} M1实时与 M a s k M_{a s k} Mask互动,生成新的单轮和多轮对话数据。这些新生成的数据经过过滤并与原始数据集合并,以重新训练我们的代理 M 0 M_{0} M0在一个迭代循环中。算法1展示了这一过程。
L a s k = − ∑ i = 1 L log p ( x i ∣ x < i ) , x i ∈ q \mathcal{L}_{a s k}=-\sum_{i=1}^{L} \log p\left(x_{i} \mid x_{<i}\right), x_{i} \in q Lask=−i=1∑Llogp(xi∣x<i),xi∈q
算法1 迭代监督微调
输入:数据集
(
D
)
(D)
(D),基础代理
(
M
0
)
(M_{0})
(M0),迭代次数
(
t
)
(t)
(t)
(
M
1
←
M
0
)
(M_{1} \leftarrow M_{0})
(M1←M0) 在
(
D
)
(D)
(D) 上通过公式 (3) 训练
(
M
a
s
k
←
M
0
)
(M_{a s k} \leftarrow M_{0})
(Mask←M0) 在
(
D
)
(D)
(D) 上通过公式 (4) 训练
对
(
i
←
2
)
(i \leftarrow 2)
(i←2) 到
(
t
)
(t)
(t) 执行
(
D
i
←
)
(D_{i} \leftarrow)
(Di←)
(
M
i
−
1
)
(M_{i-1})
(Mi−1) 和
(
M
a
s
k
)
(M_{a s k})
(Mask) 之间的交互
(
D
←
D
∪
D
i
)
(D \leftarrow D \cup D_{i})
(D←D∪Di)
(
M
i
←
M
0
)
(M_{i} \leftarrow M_{0})
(Mi←M0) 在
(
D
)
(D)
(D) 上通过公式 (3) 训练
结束 for
输出:聊天代理
(
M
t
)
(M_{t})
(Mt)
4.3. 直接偏好优化
为进一步提升代理响应的质量,我们额外加入了DPO训练阶段。该阶段旨在平衡准确性、参与度和简洁性,并可根据特定产品目标进行定制。
具体来说,我们从SFT阶段收集了10K个多轮生成数据,并根据既定标准构建了相应的负面响应。这些数据与正面响应一起用于通过DPO算法训练代理。通过这种方法,代理的人性化品质和个性属性得到了显著提升,同时实现了响应中更高的参与度和简洁性。
4.4. 初步结果
数据集。为了评估代理的人物形象,我们使用CharacterEval数据集进行了实验,这是一个专门为多轮角色扮演对话设计的编译数据集。为了评估模型的智力能力,我们从不同领域选择了各种专用数据集,包括MMLU、CMMLU、AlignBench和IFEval,这些数据集评估知识和问题解决能力。此外,我们选择了GSM8K以测试数学背景下的问题解决能力。每个数据集提供了一系列独特的挑战和场景,严格测试代理在不同背景下的角色形象和智力。
指标。对于角色扮演数据集,我们遵循CharacterEval中建立的指标,主要包括三个维度:对话能力、角色扮演吸引力和人物一致性。对于评估智力水平的其他数据集,我们使用准确率作为标准评估措施。
基线。为了建立强有力的比较,我们使用了各种模型作为我们的基线,涵盖了通用聊天模型和专门为角色扮演设计的模型。(1)对于聊天模型,我们的选择包括ChatGLM3-6B、XVERSE-7B/13B、Baichuan27B/13B、Qwen-14B、InternLM-7B/20B,以及闭源模型GPT-3.5和GPT-4。(2)对于角色扮演模型,我们采用了CharacterGLM、Xingchen、MiniMax和BC-NPC-Turbo,每个模型都经过工程设计,擅长角色特定的对话和互动。
结果。主要结果如表1和表2所示,证明了我们的方法可以在基于IQ的任务和基于EQ的任务之间实现更好的平衡。
5. 替代观点
虽然我们提倡开发超越领域专业化的下一代AI智能体,但重要的是要承认可能挑战或完善我们立场的替代观点。
5.1. 专业化和领域特定卓越
一种反对意见认为,专业化是最大化特定领域表现的关键。许多专家认为AI系统应专注于特定任务,优化其在这些领域的功能至无与伦比的程度。这种观点得到了像DeepMind的AlphaGo(Silver et al., 2017)这样的专门代理的成功支持,它只在围棋这一特定领域表现出色。类似地,专注于有限任务范围的AI代理可以达到通用目的代理难以匹敌的表现水平。
虽然专业化可以在定义的区域内实现最佳表现,但AI发展的下一个前沿是将多种能力整合到单一代理中。通用目的AI无需牺牲任何单一领域的表现;随着架构、多任务学习和迁移学习的进步,我们相信通用目的代理可以既高度胜任又灵活适应。此外,如问题解决、决策制定和工具使用等AI任务的融合,将需要向更集成的系统转变。
5.2. 过度泛化的风险和安全顾虑
另一种反对意见是推动AI代理更加泛化可能存在潜在风险。一个高度灵活的系统可能缺乏执行专门任务所需的知识深度或能力。此外,一个更加通用的AI可能会引发关于控制、责任和安全的伦理问题。随着AI系统能够处理更广泛的任务,确保它们以安全和可预测的方式运行的复杂性增加。
与通用目的AI相关的风险是有效的,但不应阻止进步。我们认为,仔细关注安全机制、透明度和稳健的训练范式可以减轻这些风险。此外,就社会影响、效率和可访问性而言,更广泛潜在的好处证明了投资于下一代通用目的代理是合理的。通过早期的研究和合作解决这些问题,我们可以确保这些系统负责任地发展。
5.3. AI代理的渐进演化
与其追求向通用目的代理的激进转变,有些人提倡一种渐进的方法,AI代理逐渐演化,每个新系统结合更多的专门能力。这种方法允许更受控的发展,并确保模型在其擅长特定领域的能力上保持根基。
表1. 主要人物形象评估结果。最佳结果以粗体突出显示,次优结果以下划线标出。
| 对话能力 | 吸引力 | 角色一致性 | 总体 | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 流畅性 | 协调性 | 一致性 | 平均值 | 高亮 | 角色塑造 | 故事性 | 共情 | 平均值 | 个性化 | 角色理解 | 平均值 | |||
| ChatGLM3-6B | 3.269 | 3.647 | 3.283 | 3.399 | 3.064 | 2.932 | 1.969 | 2.993 | 2.739 | 2.455 | 2.812 | 2.633 | 2.935 | |
| XVERSE-7B | 3.393 | 3.752 | 3.518 | 3.554 | 3.395 | 2.743 | 2.013 | 2.936 | 2.772 | 2.564 | 2.887 | 2.726 | 3.022 | |
| Baichuan2-7B | 3.551 | 3.894 | 3.827 | 3.757 | 3.670 | 2.728 | 2.115 | 2.984 | 2.874 | 2.830 | 3.081 | 2.956 | 3.187 | |
| Qwen-7B | 3.187 | 3.564 | 3.229 | 3.327 | 3.036 | 2.791 | 2.052 | 2.838 | 2.679 | 2.605 | 2.780 | 2.693 | 2.898 | |
| InternLM-7B | 3.527 | 3.823 | 3.744 | 3.698 | 3.546 | 2.622 | 2.070 | 2.897 | 2.784 | 2.719 | 3.016 | 2.867 | 3.107 | |
| XVERSE-13B | 3.444 | 3.811 | 3.559 | 3.605 | 3.319 | 2.939 | 2.045 | 3.018 | 2.830 | 2.579 | 2.915 | 2.747 | 3.070 | |
| Baichuan2-13B | 3.596 | 3.924 | 3.864 | 3.795 | 3.700 | 2.703 | 2.136 | 3.021 | 2.890 | 2.808 | 3.081 | 2.944 | 3.204 | |
| Qwen-14B | 3.351 | 3.765 | 3.510 | 3.542 | 3.354 | 2.871 | 2.237 | 2.970 | 2.858 | 2.744 | 2.900 | 2.822 | 3.078 | |
| InternLM-20B | 3.576 | 3.943 | 3.717 | 3.745 | 3.582 | 2.885 | 2.132 | 3.047 | 2.911 | 2.753 | 3.041 | 2.897 | 3.186 | |
| CharacterGLM | 3.414 | 3.717 | 3.737 | 3.623 | 3.738 | 2.265 | 1.966 | 2.812 | 2.695 | 2.301 | 2.969 | 2.635 | 2.991 | |
| Xingchen | 3.378 | 3.807 | 3.754 | 3.646 | 3.757 | 2.272 | 2.100 | 2.799 | 2.732 | 2.772 | 3.055 | 2.913 | 3.077 | |
| MiniMax | 3.609 | 3.932 | 3.811 | 3.784 | 3.768 | 2.672 | 2.150 | 3.017 | 2.902 | 2.774 | 3.125 | 2.950 | 3.207 | |
| BC-NPC-Turbo | 3.578 | 3.898 | 3.916 | 3.798 | 3.836 | 2.643 | 2.336 | 2.971 | 2.946 | 2.910 | 3.151 | 3.031 | 3.249 | |
| GPT-3.5 | 2.629 | 2.917 | 2.700 | 2.749 | 2.565 | 2.422 | 1.660 | 2.526 | 2.293 | 1.921 | 2.316 | 2.119 | 2.740 | |
| GPT-4 | 3.332 | 3.669 | 3.343 | 3.448 | 3.143 | 3.184 | 2.153 | 3.010 | 2.873 | 2.721 | 2.873 | 2.797 | 3.048 | |
| NGENT(我们的) | 3.794 | 4.1 | ||||||||||||
| 3.923 | 3.944 | 3.736 | 3.453 | 3.100 | 3.361 | 3.413 | 3.518 | 3.307 | 3.113 | 3.523 |
表2. IQ评估结果。
| 数据集 | 简单方法 | 简单方法+SFT | NGENT(我们的) |
|---|---|---|---|
| MMLU | 68.27 | 70.83 | 69.96 |
| CMMLU | 68.00 | 71.47 | 70.37 |
| GSM8K | 68.46 | 70.81 | 74.00 |
| IFEVAL | 53.12 | 61.27 | 61.75 |
| AlignBENCH | 5.26 | 5.45 | 6.50 |
| 平均值 | 52.62 | 55.97 | 56.52 |
2023a; Ruan et al., 2024).
专门代理之间的协作无疑是一种有前景的方法,我们同意多代理系统在某些场景中有可能提升性能。然而,多个代理之间的协调和通信开销可能会引入效率低下,并可能阻碍系统在新情境中的整体适应性(Mao et al., 2020b)。一旦通用目的代理在各个领域达到高水平的竞争力,它可能提供一种更简化的解决方案,能够灵活调整以适应新情况,而无需在不同代理之间进行显式协调。从长远来看,我们设想通用目的代理作为协作框架的自然延伸。
6. 结论
本文倡导AI智能体的发展超越其当前领域的模型,提出下一代AI智能体(NGENTs)应采用一种通用设计,能够在多个领域整合多样功能。这种转变不仅对于向真正的AGI迈进至关重要,而且也满足了对多功能、智能系统日益增长的需求,这些系统可以解决广泛的用户需求。通过关注无缝整合、增强架构框架并优先考虑安全性和伦理考量,我们可以创建具有潜力改变行业、解决全球挑战并改善日常生活的AI智能体。尽管仍存在挑战,但下一步AI发展的需求是紧迫的,现在正是推动这一愿景前进的时候。
参考文献
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. Gpt-4技术报告. arXiv预印本arXiv:2303.08774, 2023.
Alonso, E. AI与代理:现状. AI Magazine, 23 (3):25-25, 2002.
Bagnell, J. A., Bradley, D., Silver, D., Sofman, B., 和 Stentz, A. 自主导航学习. IEEE Robotics & Automation Magazine, 17(2):74-84, 2010.
Brohan, A., Brown, N., Carbajal, J., Chebotar, Y., Dabis, J., Finn, C., Gopalakrishnan, K., Hausman, K., Herzog, A., Hsu, J., et al. RT-1:大规模真实世界控制的机器人变压器. arXiv预印本arXiv:2212.06817, 2022.
Brohan, A., Brown, N., Carbajal, J., Chebotar, Y., Chen, X., Choromanski, K., Ding, T., Driess, D., Dubey, A., Finn, C., et al. RT-2:视觉-语言-行动模型将网络知识转移到机器人控制. arXiv预印本arXiv:2307.15818, 2023.
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al. 语言模型是少量样本学习者. Advances in neural information processing systems, 33: 1877-1901, 2020.
Busoniu, L., Babuska, R., 和 De Schutter, B. 多智能体强化学习的全面调查. IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews), 38(2):156-172, 2008.
Campbell, M., Hoane Jr, A. J., 和 Hsu, F.-h. 深蓝. Artificial intelligence, 134(1-2):57-83, 2002.
Castelfranchi, C. 建模社会行为以供AI代理使用. Artificial intelligence, 103(1-2):157-182, 1998.
Chen, J., Wang, X., Xu, R., Yuan, S., Zhang, Y., Shi, W., Xie, J., Li, S., Yang, R., Zhu, T., et al. 从人物到个性化:角色扮演语言代理的综述. arXiv预印本arXiv:2404.18231, 2024.
Chen, L., Lu, K., Rajeswaran, A., Lee, K., Grover, A., Laskin, M., Abbeel, P., Srinivas, A., 和 Mordatch, I. 决策变压器:通过序列建模实现强化学习. Advances in neural information processing systems, 34:15084-15097, 2021.
Chen, Y., Mao, H., Zhang, T., Wu, S., Zhang, B., Hao, J., Li, D., Wang, B., 和 Chang, H. PTDE:多智能体强化学习的个性化训练与执行蒸馏. arXiv预印本arXiv:2210.08872, 2022.
Franklin, S. 自主代理作为具身AI. Cybernetics & Systems, 28(6):499-520, 1997.
Guo, D., Zhu, Q., Yang, D., Xie, Z., Dong, K., Zhang, W., Chen, G., Bi, X., Wu, Y., Li, Y., et al. Deepseek-coder:当大型语言模型遇到编程——代码智能的兴起. arXiv预印本arXiv:2401.14196, 2024.
He, H., Yao, W., Ma, K., Yu, W., Dai, Y., Zhang, H., Lan, Z., 和 Yu, D. Webvoyager:使用大型多模态模型构建端到端Web代理. arXiv预印本arXiv:2401.13919, 2024.
Hong, W., Wang, W., Lv, Q., Xu, J., Yu, W., Ji, J., Wang, Y., Wang, Z., Dong, Y., Ding, M., et al. Cogagent:用于GUI代理的视觉语言模型. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 14281-14290, 2024.
Hoscilowicz, J., Maj, B., Kozakiewicz, B., Tymoshchuk, O., 和 Janicki, A. Clickagent:增强自主代理的UI定位能力. arXiv预印本arXiv:2410.11872, 2024.
Hurst, A., Lerer, A., Goucher, A. P., Perelman, A., Ramesh, A., Clark, A., Ostrow, A., Welihinda, A., Hayes, A., Radford, A., et al. GPT-4O系统卡. arXiv预印本arXiv:2410.21276, 2024.
Iong, I. L., Liu, X., Chen, Y., Lai, H., Yao, S., Shen, P., Yu, H., Dong, Y., 和 Tang, J. Openwebagent:一个开放工具包,使大型语言模型具备Web代理功能. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations), pp. 72-81, 2024.
Jaech, A., Kalai, A., Lerer, A., Richardson, A., El-Kishky, A., Low, A., Helyar, A., Madry, A., Beutel, A., Carney, A., et al. OpenAI O1系统卡. arXiv预印本arXiv:2412.16720, 2024.
Janner, M., Li, Q., 和 Levine, S. 离线强化学习作为一个大序列建模问题. Advances in neural information processing systems, 34: 1273-1286, 2021.
Koh, J. Y., Lo, R., Jang, L., Duvvur, V., Lim, M. C., Huang, P.-Y., Neubig, G., Zhou, S., Salakhutdinov, R., 和 Fried, D. Visualwebarena:在现实的视觉Web任务上评估多模态代理. arXiv预印本arXiv:2401.13649, 2024.
Kong, Y., Ruan, J., Chen, Y., Zhang, B., Bao, T., Shi, S., Du, G., Hu, X., Mao, H., Li, Z., et al. TPTU-v2:在现实世界系统中提升基于大型语言模型的代理的任务规划和工具使用能力. arXiv预印本arXiv:2311.11315, 2023.
Kong, Y., Ruan, J., Chen, Y., Zhang, B., Bao, T., Shiwei, S., Qing, D., Hu, X., Mao, H., Li, Z., et al. TPTU-v2:在现实世界工业系统中提升基于大型语言模型的代理的任务规划和工具使用能力. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track, pp. 371-385, 2024.
Krizhevsky, A., Sutskever, I., 和 Hinton, G. E. 使用深度卷积神经网络进行ImageNet分类. Advances in neural information processing systems, 25, 2012.
LeCun, Y., Bengio, Y., 和 Hinton, G. 深度学习. nature, 521(7553):436-444, 2015.
Lee, S., Choi, J., Lee, J., Wasi, M. H., Choi, H., Ko, S., Oh, S., 和 Shin, I. MobileGPT:用人类般的应用记忆增强LLM以实现移动任务自动化. In Proceedings of the 30th Annual International Conference on Mobile Computing and Networking, pp. 1119-1133, 2024.
Li, J., Monroe, W., Ritter, A., Galley, M., Gao, J., 和 Jurafsky, D. 对话生成的深度强化学习. arXiv预印本arXiv:1606.01541, 2016.
Li, Z., Wang, X., Zhao, J., Yang, S., Du, G., Hu, X., Zhang, B., Ye, Y., Li, Z., Zhao, R., et al. PET-SQL:带交叉一致性的提示增强两阶段文本到SQL框架. arXiv预印本arXiv:2403.09732, 2024.
Liu, S., Cheng, H., Liu, H., Zhang, H., Li, F., Ren, T., Zou, X., Yang, J., Su, H., Zhu, J., et al. LLAVA-PLUS:学习使用工具创建多模态代理. In European Conference on Computer Vision, pp. 126-142. Springer, 2025.
Lu, P., Peng, B., Cheng, H., Galley, M., Chang, K.-W., Wu, Y. N., Zhu, S.-C., 和 Gao, J. Chameleon:带有大型语言模型的插件式组合推理. Advances in Neural Information Processing Systems, 36, 2024.
Mao, H., Liu, W., Hao, J., Luo, J., Li, D., Zhang, Z., Wang, J., 和 Xiao, Z. 邻域认知一致的多智能体强化学习. In Proceedings of the AAAI conference on artificial intelligence, volume 34, pp. 72197226, 2020a.
Mao, H., Zhang, Z., Xiao, Z., Gong, Z., 和 Ni, Y. 在有限带宽下通过消息修剪学习智能体通信. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pp. 5142-5149, 2020b.
Mao, H., Wang, C., Hao, X., Mao, Y., Lu, Y., Wu, C., Hao, J., Li, D., 和 Tang, P. SEIHAI:Minerl竞赛中的高效样本分层AI. In Distributed
Artificial Intelligence: Third International Conference, DAI 2021, Shanghai, China, December 17-18, 2021, Proceedings 3, pp. 38-51. Springer, 2022a.
Mao, H., Zhao, R., Chen, H., Hao, J., Chen, Y., Li, D., Zhang, J., 和 Xiao, Z. Transformer in Transformer作为深度强化学习的骨干. arXiv预印本arXiv:2212.14538, 2022b.
Mao, H., Zhao, R., Li, Z., Xu, Z., Chen, H., Chen, Y., Zhang, B., Xiao, Z., Zhang, J., 和 Yin, J. EDIT:深度强化学习中感知和决策的交织转换器. arXiv预印本arXiv:2312.15863, 2023.
Mitchell, T. M. 和 Mitchell, T. M. 机器学习,第1卷. McGraw-hill New York, 1997.
Niu, R., Li, J., Wang, S., Fu, Y., Hu, X., Leng, X., Kong, H., Chang, Y., 和 Wang, Q. ScreenAgent:由视觉语言模型驱动的计算机控制代理. arXiv预印本arXiv:2402.07945, 2024.
Norman, D. A. 认知科学的十二个问题. Cognitive science, 4(1):1-32, 1980.
Qin, Y., Hu, S., Lin, Y., Chen, W., Ding, N., Cui, G., Zeng, Z., Huang, Y., Xiao, C., Han, C., et al. 工具学习与基础模型. arXiv预印本arXiv:2304.08354, 2023a.
Qin, Y., Liang, S., Ye, Y., Zhu, K., Yan, L., Lu, Y., Lin, Y., Cong, X., Tang, X., Qian, B., et al. ToolLLM:帮助大型语言模型掌握16000+真实世界API. arXiv预印本arXiv:2307.16789, 2023b.
Qu, C., Dai, S., Wei, X., Cai, H., Wang, S., Yin, D., Xu, J., 和 Wen, J.-R. 大型语言模型的工具学习:综述. arXiv预印本arXiv:2405.17935, 2024.
Roziere, B., Gehring, J., Gloeckle, F., Sootla, S., Gat, I., Tan, X. E., Adi, Y., Liu, J., Sauvestre, R., Remez, T., et al. Code Llama:开源代码基础模型. arXiv预印本arXiv:2308.12950, 2023.
Ruan, J., Chen, Y., Zhang, B., Xu, Z., Bao, T., Mao, H., Li, Z., Zeng, X., Zhao, R., et al. TPTU:基于大型语言模型的AI代理的任务规划和工具使用. In NeurIPS 2023 Foundation Models for Decision Making Workshop, 2023.
Ruan, J., Li, Z., Wei, H., Jiang, H., Lu, J., Xiong, X., Mao, H., 和 Zhao, R. CosLight:协同优化合作者选择和决策制定以增强交通信号控制. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pp. 2500-2511, 2024.
Schick, T., Dwivedi-Yu, J., Dessì, R., Raileanu, R., Lomeli, M., Hambro, E., Zettlemoyer, L., Cancedda, N., 和 Scialom, T. ToolFormer:语言模型可以教会自己使用工具. Advances in Neural Information Processing Systems, 36:68539-68551, 2023.
Shao, Y., Li, L., Dai, J., 和 Qiu, X. Character-LLM:可训练的角色扮演代理. arXiv预印本arXiv:2310.10158, 2023.
Shen, Y., Song, K., Tan, X., Li, D., Lu, W., 和 Zhuang, Y. HuggingGPT:用ChatGPT及其朋友在Hugging Face解决AI任务. Advances in Neural Information Processing Systems, 36, 2024.
Shortliffe, E. H. 医疗专家系统——医生的知识工具. Western Journal of Medicine, 145(6):830, 1986.
Silver, D., Schrittwieser, J., Simonyan, K., Antonoglou, I., Huang, A., Guez, A., Hubert, T., Baker, L., Lai, M., Bolton, A., et al. 不依赖人类知识掌握围棋游戏. nature, 550(7676):354-359, 2017.
Sternberg, R. J. 成功智力理论. Review of General psychology, 3(4):292-316, 1999.
Wang, J., Xu, H., Ye, J., Yan, M., Shen, W., Zhang, J., Huang, F., 和 Sang, J. Mobile-Agent:具有视觉感知的自主多模态移动设备代理. arXiv预印本arXiv:2401.16158, 2024a.
Wang, L., Ma, C., Feng, X., Zhang, Z., Yang, H., Zhang, J., Chen, Z., Tang, J., Chen, X., Lin, Y., et al. 基于大型语言模型的自主代理综述. Frontiers of Computer Science, 18(6):186345, 2024b.
Wang, P., Yang, A., Men, R., Lin, J., Bai, S., Li, Z., Ma, J., Zhou, C., Zhou, J., 和 Yang, H. OFA:通过简单的序列到序列学习框架统一架构、任务和模态. In International conference on machine learning, pp. 23318-23340. PMLR, 2022.
Wu, Z., Han, C., Ding, Z., Weng, Z., Liu, Z., Yao, S., Yu, T., 和 Kong, L. OS-Copilot:迈向具有自我改进能力的通用计算机代理. arXiv预印本arXiv:2402.07456, 2024.
Xi, Z., Chen, W., Guo, X., He, W., Ding, Y., Hong, B., Zhang, M., Wang, J., Jin, S., Zhou, E., et al. 基于大型语言模型的代理的崛起与潜力:综述. arXiv预印本arXiv:2309.07864, 2023.
Xie, J., Chen, Z., Zhang, R., Wan, X., 和 Li, G. 大型多模态代理:综述. arXiv预印本arXiv:2402.15116, 2024.
Xing, M., Mao, H., Yin, S., Pan, L., Zhang, Z., Xiao, Z., 和 Long, J. 通过强化学习在公共云上调度分布式深度学习作业的双代理调度器. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pp. 2776-2788, 2023.
Zhang, B., Mao, H., Ruan, J., Wen, Y., Li, Y., Zhang, S., Xu, Z., Li, D., Li, Z., Zhao, R., et al. 控制基于大型语言模型的代理进行大规模决策:演员-评论家方法. arXiv预印本arXiv:2311.13884, 2023a.
Zhang, B., Mao, H., Li, L., Xu, Z., Li, D., Zhao, R., 和 Fan, G. 多智能体系统中的顺序异步动作协调:Stackelberg决策转换器方法. In 第四十一届国际机器学习会议, 2024a.
Zhang, C., Yang, Z., Liu, J., Han, Y., Chen, X., Huang, Z., Fu, B., 和 Yu, G. AppAgent:作为智能手机用户的多模态代理. arXiv预印本arXiv:2312.13771, 2023b.
Zhang, Y., Pan, Y., Wang, Y., 和 Cai, J. PyBench:评估LLM代理在各种实际编码任务中的表现. arXiv预印本arXiv:2407.16732, 2024b.
Zheng, Q., Zhang, A., 和 Grover, A. 在线决策转换器. In 国际机器学习会议, pp. 27042-27059. PMLR, 2022.
参考论文:https://arxiv.org/pdf/2504.21433


















 187
187

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











