



作为天天跟数据库打交道的程序员,咱都知道 Text-to-SQL 这活儿有多香 —— 不用写 SQL,用自然语言就能查数据,非技术同事也能上手。但问题是,市面上绝大多数 Text-to-SQL 基准全是英文的,多语言场景基本是盲区,这对全球化企业来说根本不够用。最近我们团队搞出了个 MultiSpider 2.0,把经典的 Spider 2.0 扩展到了 8 种语言,还保留了原有的复杂结构,结果发现现在最牛的 LLM(比如 DeepSeek-R1、OpenAI o1)纯靠自己推理,执行准确率居然才 4%,对比 MultiSpider 1.0 的 60% 简直是断崖式下跌。后来我们搞了个协作式语言智能体(COLA),让它迭代优化查询,才把准确率拉到 15%。这事儿足以说明,多语言 Text-to-SQL 的坑还深得很,得赶紧找更靠谱的方案才行。对了,基准地址放这了,https://github.com/phkhanhtrinh23/Multilingual_Text_to_SQL,想上手试的直接冲。
作为天天跟数据库打交道的程序员,咱都知道 Text-to-SQL 这活儿有多香 —— 不用写 SQL,用自然语言就能查数据,非技术同事也能上手。但问题是,市面上绝大多数 Text-to-SQL 基准全是英文的,多语言场景基本是盲区,这对全球化企业来说根本不够用。最近我们团队搞出了个 MultiSpider 2.0,把经典的 Spider 2.0 扩展到了 8 种语言,还保留了原有的复杂结构,结果发现现在最牛的 LLM(比如 DeepSeek-R1、OpenAI o1)纯靠自己推理,执行准确率居然才 4%,对比 MultiSpider 1.0 的 60% 简直是断崖式下跌。后来我们搞了个协作式语言智能体(COLA),让它迭代优化查询,才把准确率拉到 15%。这事儿足以说明,多语言 Text-to-SQL 的坑还深得很,得赶紧找更靠谱的方案才行。对了,基准地址放这了,https://github.com/phkhanhtrinh23/Multilingual_Text_to_SQL,想上手试的直接冲。
先聊聊现状吧,Text-to-SQL 这几年靠 LLM 确实进步不少,但绝大多数基准(比如 Spider 1.0/2.0、BIRD、WikiSQL)全是英文的,模型很容易在单语言环境里过拟合,换个语言就歇菜。之前有个 MultiSpider 1.0 算是开了多语言的头,但用的都是 mBART、XLM-R 这种小模型,数据库 schema 也不够企业级,实用性差了点。
所以我们搞了 MultiSpider 2.0,把 Spider 2.0 的企业级复杂度直接搬到 8 种语言上 —— 英语、德语、法语、西班牙语、葡萄牙语、日语、中文、越南语全都覆盖。从下面这个表就能看出来,它不仅保留了大规模跨领域 schema 和嵌套查询这种复杂 SQL 能力,还加了语言和方言差异,完全模拟真实业务场景。结果一测试就傻了眼:最顶尖的推理型 LLM 在这上面的执行准确率才 4%,跟 MultiSpider 1.0 的 60% 比,差得不是一点半点,这多语言的鸿沟也太明显了。
表 1:Text-to-SQL 基准功能对比表

注:表中✓表示完全支持,△表示部分支持 / 有限支持,× 表示不支持;“Enterprise” 代表大规模真实 schema,“Compositional” 代表嵌套 / 子查询和多跳连接,“Dialect” 代表跨语言 / 方言差异,“Diagnostic” 代表细粒度能力划分,“Multilingual” 代表支持非英语语言,括号里的 kL 表示语言数量
先说说 MultiSpider 2.0 是怎么造出来的
数据集收集:真・企业级数据,复杂度拉满
MultiSpider 2.0 是在 Spider 2.0 的基础上扩的,我们从 BigQuery 公共数据集、Snowflake Marketplace 这些云市场里挑了真实数据库,还严格遵守 Spider 2.0 的规则 —— 每个数据库至少 200 列,或者得有嵌套 schema。最终凑了 200 个企业级数据库,5056 组 “自然语言 - SQL” 对,8 种语言各占 12.5%(每种语言 632 条),既保证了任务难度,又能支持快速迭代,而且所有拆分数据集都给了标准 SQL,本地就能跑评估。
从下面这个统计表里能看出来,它的复杂度分布特别合理。跟之前的 MultiSpider 比,中等难度(80-160 个 token)占 44.15%,高难度(超过 160 个 token)占 30.54%,简单的才 25.32%,这才是真能测出来模型实力的数据集,不是那种随便考考的 “送分题”。更关键的是,它还覆盖了多种数据库方言,BigQuery(33.86%)、Snowflake(31.33%)、SQLite(34.81%)都有,这对程序员来说太真实了 —— 毕竟实际工作中,今天用 Snowflake 明天切 BigQuery 是常事,模型能不能适应方言差异,直接关系到能不能落地。
表 2:MultiSpider 2.0 任务特征统计
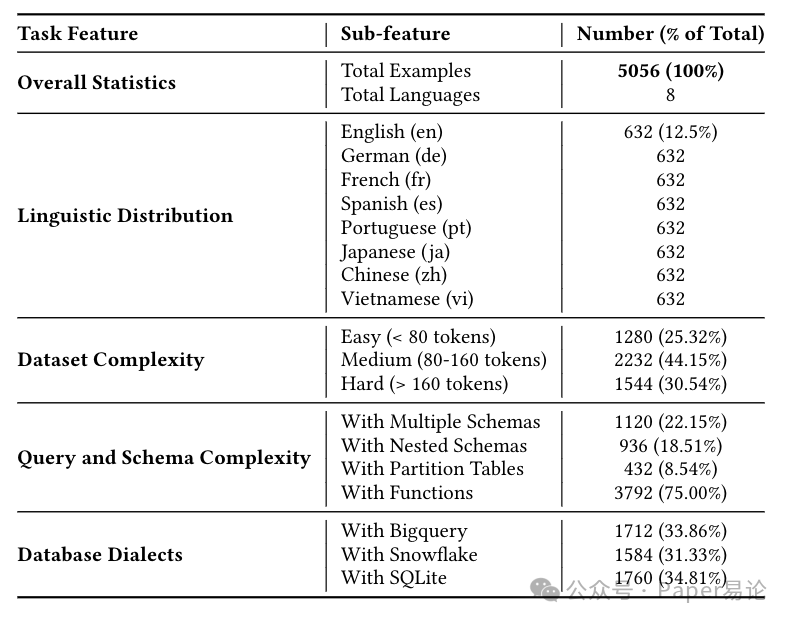
注:表格详细列出了总样本数、各语言分布、难度分级占比、查询与 schema 复杂度特征,以及数据库方言分布,能直观看到数据集的全面
翻译流程:14 个专业译者 + 多轮校验,就怕翻错一个字段
翻译这事儿我们不敢马虎,找了 14 个专业译者,每种非英语语言配 2 个,还有 2 个 NLP 研究员专门盯英语部分。不只是翻自然语言问题,连数据库都做了本地化 —— 每个语言都有独立的 schema 和数值库,跟原文语义完全对齐,避免出现 “字段对应不上” 的坑。
具体流程分了四步:第一步先做双语对齐,检查问题和 schema / 数值字典的对应关系,比如 “device category” 在德语里该对应哪个字段,绝对不能错;第二步给每种语言做本地化数据库快照,表名、列名、枚举值这些都翻,但保留唯一 ID,防止关联失效;第三步找 4 个独立 NLP reviewer 测 SQL 能不能跑,跟本地化 schema 对不对得上;最后还要做跨语言等价性检查,确保每种语言的样本和原文语义一致。
不过翻译过程中也踩了不少坑,总结下来有三类常见问题:一是上下文缺失,比如原文里有 “device category”,翻译时漏了,结果生成 SQL 时少了列约束;二是词汇歧义,比如 “YouTube Men’s Vintage Henley” 这种品牌名,翻错了就会导致字符串匹配失败;三是结构复杂,比如嵌套查询或多跳连接,翻译时逻辑没理顺,SQL 里的运算符或列就对不上了。
我们针对性做了优化:比如上下文缺失就把隐含字段明说,像越南语里就把 “device.deviceCategory” 直接对应成 “phan loai thiet bi (may tinh, di dong)”(设备分类:电脑、手机);词汇歧义就保留专有名词的原文,比如品牌名不翻译,还把 “排除该产品” 这种逻辑明确写出来;结构复杂就核对标签体系,比如 “motor vehicle theft” 不能简单翻成 “盗窃”,得写成 “trom xe co gioi”(机动车盗窃),确保统计逻辑没错。下面这个表就是具体例子,能清楚看到问题和解决方案。
表 3:英语到越南语翻译的常见问题与解决示例

注:表格列了上下文缺失、词汇歧义、结构复杂三种挑战,每种都给了错误翻译、正确翻译和修复原则,对做多语言本地化的同学很有参考价值
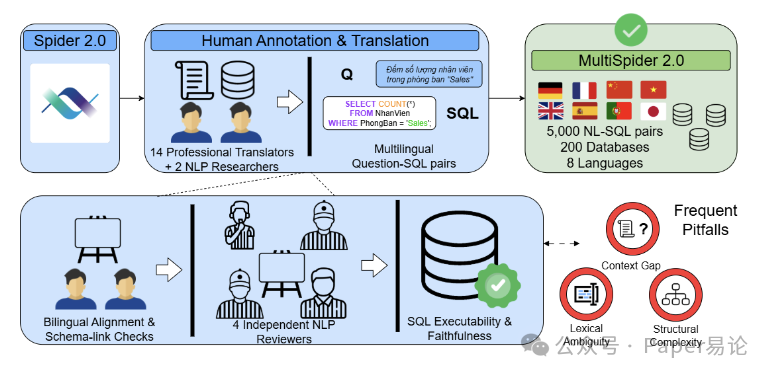
图 1:数据集构建流程
注:图中展示了从 Spider 2.0 人工标注到多语言翻译、数据库本地化的完整流程,能直观看到每个步骤的衔接
三种测试场景:看 LLM 在多语言场景下到底多菜
为了全面测模型,我们设计了三种场景,从直接生成到迭代优化都覆盖了,就想看看不同方法的真实水平。
第一种是 “独立 Text-to-SQL 框架”,就是给模型数据库 schema、自然语言问题和辅助文档,让它直接生成 SQL,然后跑库看对不对。我们测了 DIN-SQL、DAIL-SQL、TAG-Bench 这些主流方法,都用 GPT-4o 当 backbone。其中 DAIL-SQL 表现最好,主要是它对上下文的敏感度高,还能适应 SQL 方言 —— 比如同样是 “取前 10 条”,BigQuery 用 LIMIT 10,Snowflake 也支持,但有些老版本数据库可能用 TOP 10,DAIL-SQL 能根据方言调整,这点比其他方法强。为了公平,我们还给所有方法优化了提示词,加了采样的单元格值、外部文档知识和数据库专属 SQL 约束,尽量让模型发挥出最佳水平。
第二种是 “LLM 驱动的查询优化”,不依赖提示词技巧和辅助文档,纯靠 LLM 自己的推理能力迭代改 SQL。比如先让模型生成初始 SQL,然后它自己检查 schema 一致性、逻辑是否合理,再根据执行反馈调整,直到出最优结果。像 OpenAI o1 和 DeepSeek-R1 就是这么干的,靠 “思维链” 和自我修正来提升准确率。但问题是,这种方法太费时间了,尤其是面对复杂 schema,模型得反复试错,计算成本也高,有点 “看起来美,用起来累” 的意思。
第三种就是我们搞的 “协作式语言智能体(COLA)”,专门解决单 LLM 的瓶颈。核心是把任务拆给三个智能体,各司其职又互相配合:Classifier 负责把大数据库拆成小的相关子库,减少无关信息干扰,比如查 “2023 年销售数据”,就只保留销售相关的表,不用加载用户表、产品表这些冗余数据;Analyzer 把复杂问题拆成结构化子问题,用思维链生成 SQL,比如 “每个地区的 top3 畅销产品”,会先拆成 “按地区分组”“计算每个产品销量”“取每组前 3”,再一步步写 SQL;Corrector 负责执行 SQL,分析反馈,迭代修正错误,比如 SQL 语法错了改语法,逻辑错了(比如把 SUM 写成 COUNT)就调逻辑。
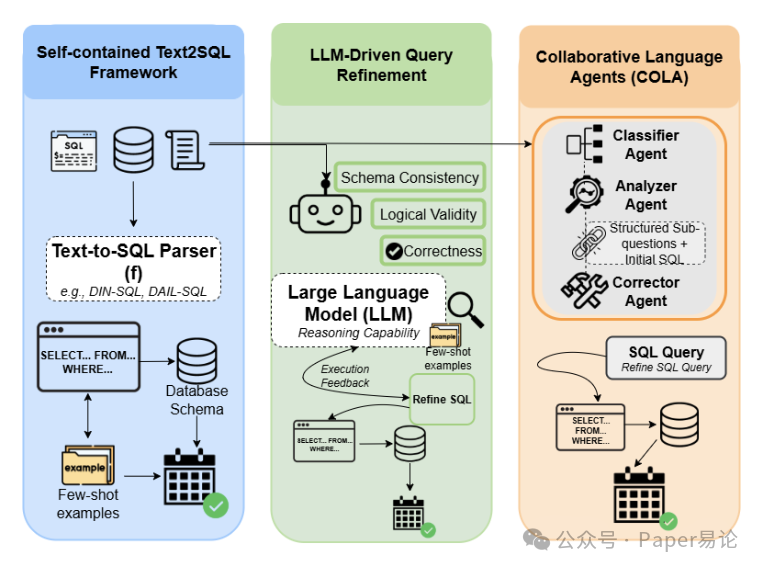
图 2:MultiSpider 2.0 测试场景示意图
注:图中清晰展示了三种测试框架的区别,左边是独立 Text-to-SQL 框架,中间是 LLM 驱动优化,右边是 COLA 协作智能体,能直观看到 COLA 的模块化设计
实验结果:MultiSpider 2.0 有多难?COLA 效果有多好?
先看实验设置:公平是第一原则
我们测了三类模型:第一类是 “独立解析器”,就是刚才说的 DIN-SQL、DAIL-SQL 这些,配 GPT-4o;第二类是 “纯推理 LLM”,比如 Gemini 1.5 Pro、OpenAI o1-1217、DeepSeek-R1 系列,直接让它们从问题和 schema 生成 SQL;第三类是 “COLA+LLM”,把第二类的 LLM 当 backbone,套上 COLA 框架。所有实验都在 MultiSpider 1.0 和 2.0 上跑,用一样的 schema 序列化方式和少样本示例,确保结果能对比。
评估指标用了两个常用的:精确匹配(EM)和执行准确率(EX)。EM 是看生成的 SQL 标准化后和标准 SQL 一不一样,EX 是看执行结果和标准结果一不一样。还测了 Pass@N,就是生成 N 个 SQL,至少一个对就算过。
核心发现 1:MultiSpider 2.0 难到离谱,LLM 直接现原形
最直观的就是性能暴跌。拿 COLA+OpenAI o1-1217 举例,在 MultiSpider 1.0 上,好几门欧洲语言的 EX 能超过 90%,结果到了 2.0,直接掉到 12%-16%,降了 75 个百分点还多。这不是模型不行,是 2.0 的挑战真的大 —— 企业级 schema 本身就复杂,再加上多语言差异和复杂查询,模型根本扛不住。
从下面这两张图能看得更清楚:左边是 EX 对比,右边是 EM 对比,不管哪种指标,2.0 的分数都比 1.0 低一大截。尤其是 EM,说明模型连 SQL 的语法结构都很难完全对齐,更别说复杂逻辑了。
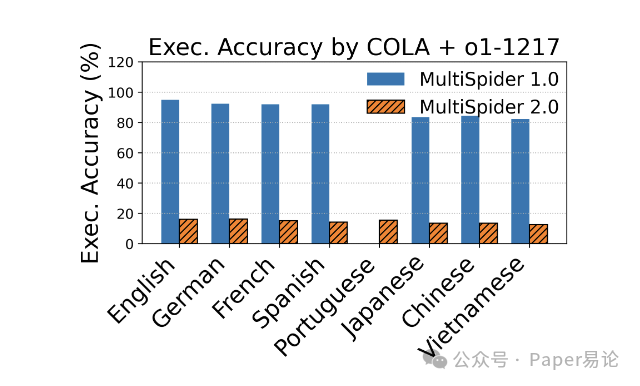
图 3:COLA+OpenAI o1-1217 在 MultiSpider 1.0 和 2.0 上的执行准确率(EX)对比
注:图中横坐标是 8 种语言,纵坐标是 EX 百分比,能明显看到每种语言在 2.0 上的分数都远低于 1.0,差距非常显著
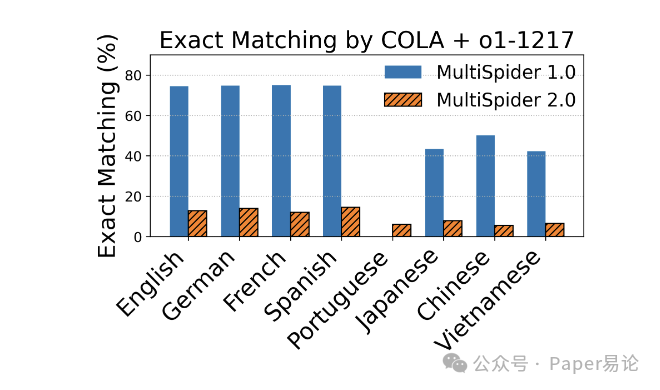
图 4:COLA+OpenAI o1-1217 在 MultiSpider 1.0 和 2.0 上的精确匹配(EM)对比
注:和 EX 趋势一致,EM 在 2.0 上也大幅下降,说明多语言复杂场景下,模型连 SQL 的句法正确性都很难保证
核心发现 2:COLA 是真能救场,不管配哪个 LLM 都能提分
虽然整体难度大,但 COLA 框架确实管用。比如 OpenAI o1-1217 和 Gemini 1.5 Pro 纯靠自己,在 2.0 上的 EX 才 4%-5%,套上 COLA 之后,直接涨到 13%-16%。这说明结构化的迭代优化,比单 LLM 的 “一刀切” 推理管用多了 ——Classifier 减噪声,Analyzer 拆难题,Corrector 改错误,三步下来,准确率自然就上去了。
下面这张散点图更直观,横坐标是 EM,纵坐标是 EX,几乎所有点都在 y=x 线上方,说明模型经常生成 “语义对但语法不对” 的 SQL,这也印证了 EX 比 EM 更实用(毕竟实际工作中,能查出正确结果比 SQL 和标准写法一毛一样更重要)。而且 COLA 相关的点(方块、菱形、十字)都比纯推理 LLM 的点(蓝色圆圈)高,明显更优。
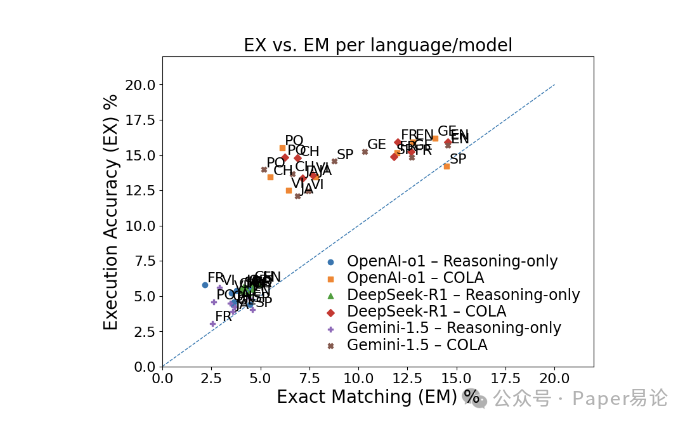
图 5:各语言 / 模型的执行准确率(EX)与精确匹配(EM)对比
注:图中每个点代表一个模型在某语言上的表现,COLA 系列模型的点普遍位于上方,说明其性能优势;y=x 线以上的点居多,体现了 EX 比 EM 更能反映实际效用
核心发现 3:非英语语言是重灾区,错误大多出在语义理解
从表格里能看出来,模型在英语上的表现明显比其他语言好,尤其是日语、中文、越南语,分数掉得特别厉害。比如 COLA+OpenAI o1-1217 在 1.0 上的 EM,英语是 74.46%,日语直接降到 43.4%,中文 50.18%。原因也很明显:一是数据少,LLM 预训练数据里英语占比高,对其他语言的句法、语法理解不够;二是语言结构差异,比如中文、日语没有空格,分词难度大,模型容易把 “机动车盗窃” 拆成 “机动 / 车盗窃”,导致字段匹配错;三是代码混用,数据库里的字段名常是英文(比如 deviceCategory),自然语言问题是中文,模型很难把 “设备分类” 和 “deviceCategory” 对应上,这就是所谓的 “代码切换” 难题。
我们还分析了错误类型,发现 80% 以上的错都不是语法问题,而是语义理解错了。从下面这张图能看到,“错误 schema 链接” 占 33%,就是把自然语言短语和数据库字段对应错了,比如把 “用户注册时间” 对应到 “user_login_time” 而不是 “user_register_time”;“错误分析” 占 20%,就是没理解查询约束,比如 “排除 2023 年数据” 写成了 “包含 2023 年数据”;“错误规划” 占 18%,比如多跳连接时少连了一张表,导致数据查不全。这些问题都不是改改 SQL 语法能解决的,得从语义理解入手。
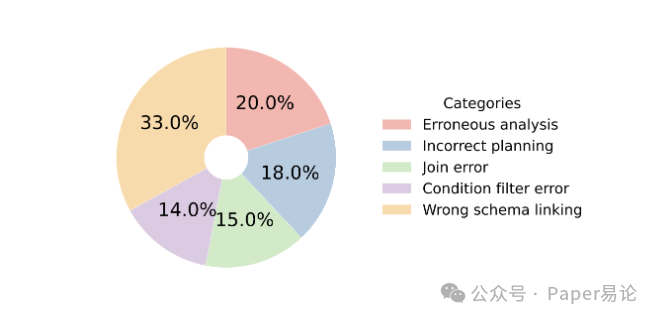
图 6:MultiSpider 2.0 开发集上的错误类型分布
注:图中展示了错误分析、错误规划、错误 schema 链接等类别占比,其中错误 schema 链接占比最高,说明语义层面的字段匹配是核心难点
核心发现 4:就算给 20 次机会,模型也很难做对
Pass@N 分数更能说明问题,就算让模型生成 20 个 SQL(Pass@20),最牛的 COLA+OpenAI o1-1217 也才对 14.88%,其他模型更差。这说明 “多生成几个碰运气” 的思路根本不管用,模型缺的是真正的推理能力,不是生成数量。不过 COLA 的 Pass@N 曲线还是比纯推理 LLM 好,说明它的结构化方法更高效,能少走弯路。
表 4:各方法在 MultiSpider 2.0 上的执行准确率(EX)
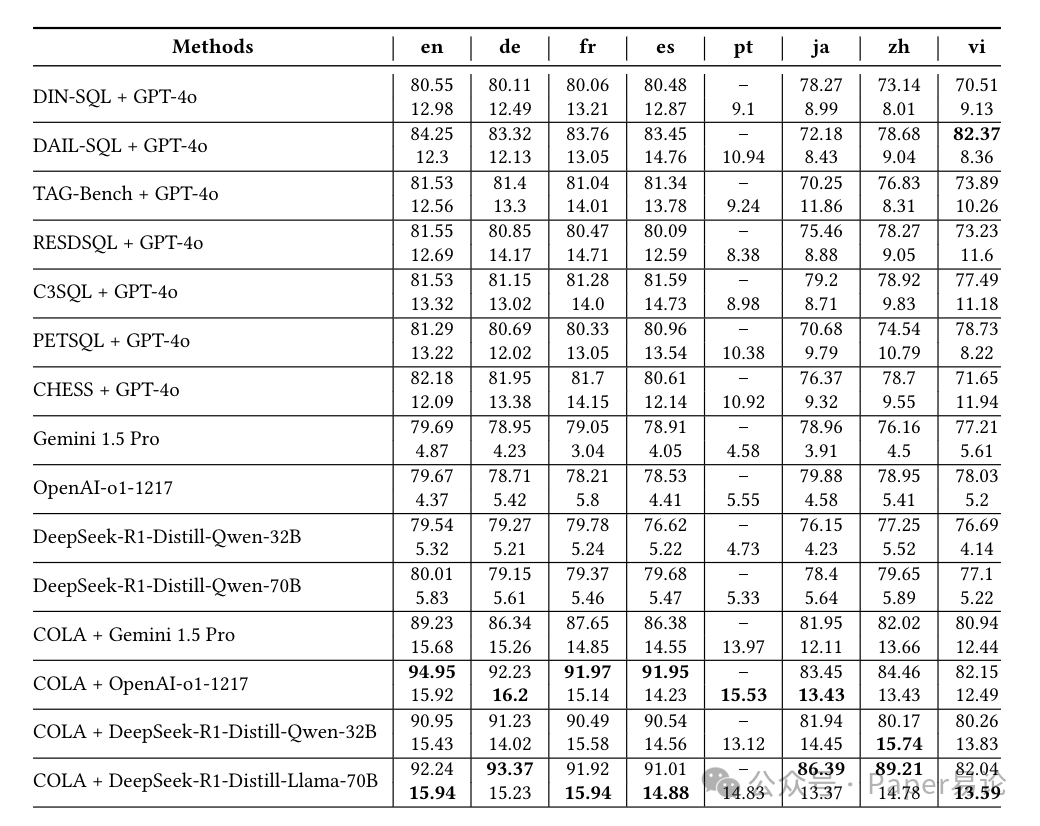
注:表格中每种方法分两行,上行是 MultiSpider 1.0 的结果,下行是 2.0 的结果,能清晰看到所有方法在 2.0 上的分数都大幅下降,且 COLA 系列明显优于纯 LLM
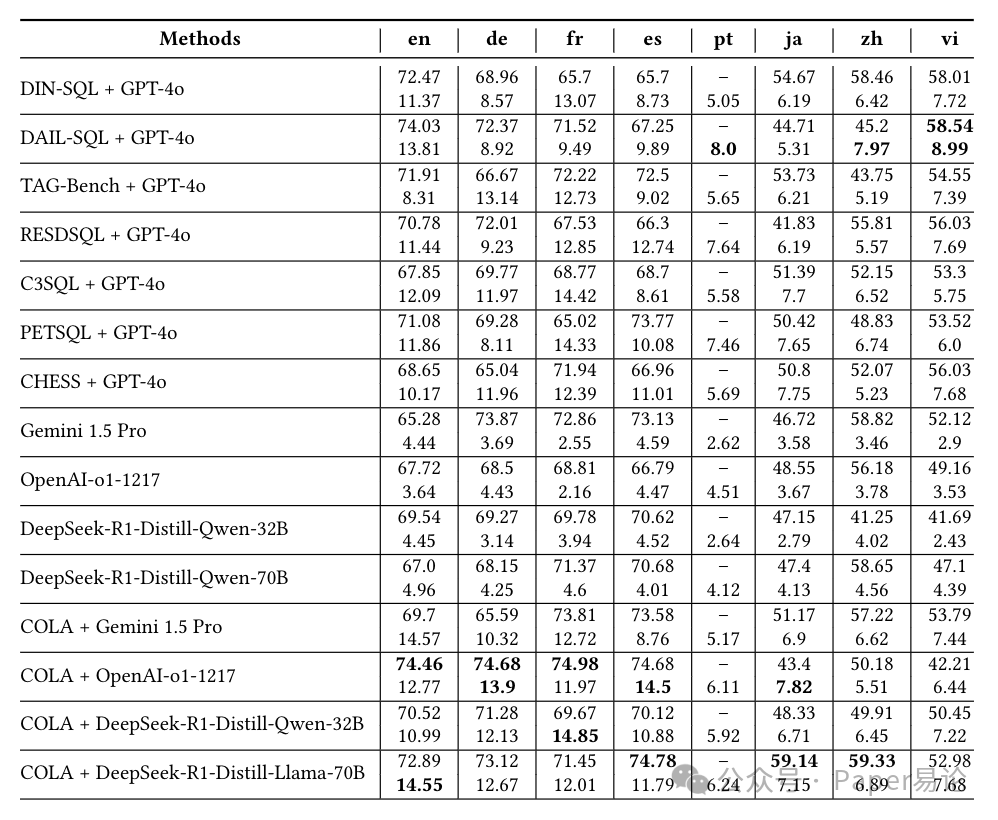
表 5:各方法在 MultiSpider 2.0 上的精确匹配(EM)
注:趋势和 EX 一致,COLA 系列在各语言上的 EM 均高于纯推理 LLM,且英语表现优于非英语语言
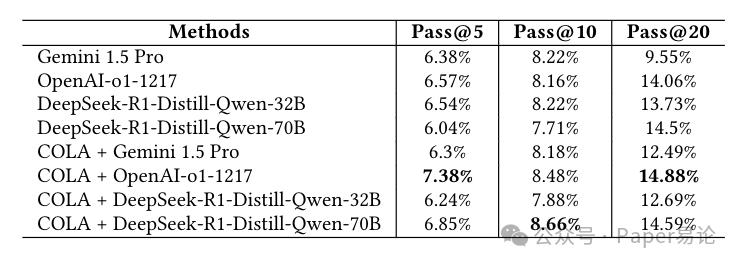
表 6:MultiSpider 2.0 上的 Pass@N 分数(N=5,10,20)
注:表格显示即使 N=20,最高准确率也仅 14.88%,体现了任务难度;COLA+OpenAI o1-1217 在各 N 值下均为最优
核心发现 5:COLA 的三个模块,Corrector 最管用
我们还做了消融实验,看每个模块的贡献。从下面这张瀑布图能看到,纯 LLM 的 baseline 是 5.6%,加了 Classifier 之后涨了 2.4%(到 8.0%),因为拆了子库,噪声少了;再加 Analyzer 涨 3.6%(到 11.6%),因为拆了复杂问题,逻辑更清晰;最后加 Corrector 涨 3.8%(到 15.4%),直接把准确率拉到最高。这说明 “执行反馈 + 迭代修正” 是最关键的 —— 毕竟 SQL 是要跑库的,只有拿到执行结果,才能知道错在哪,比如 “查不到数据” 可能是表名错了,“数据太多” 可能是少了过滤条件,这些都得靠 Corrector 来调整。
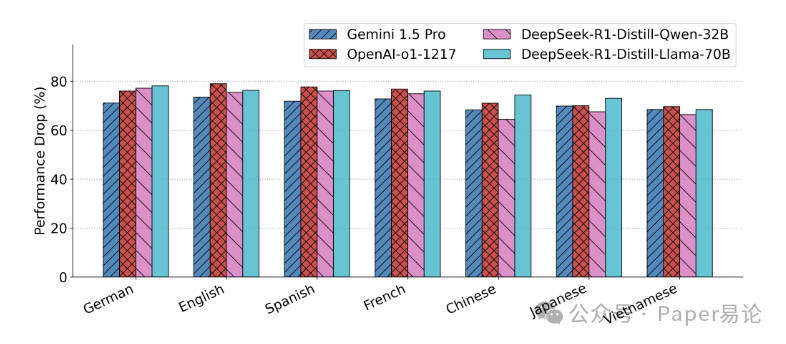
图 7:四种 COLA + 模型在 MultiSpider 2.0 上的性能下降幅度
注:图中量化了各模型从 1.0 到 2.0 的性能下降比例,所有模型均下降 65%-80%,且东亚语言下降幅度看似小,实则是基线本身就低
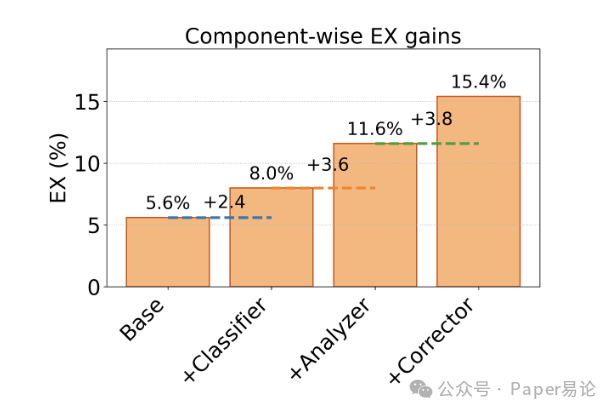
图 8:COLA 各模块对执行准确率(EX)的贡献
注:瀑布图展示了从基线到加 Classifier、Analyzer、Corrector 的逐步提分过程,Corrector 的贡献最大,验证了迭代修正的重要性
最后聊聊未来该往哪走
MultiSpider 2.0 算是把多语言 Text-to-SQL 的坑都暴露出来了:企业级 schema 复杂、语言差异大、SQL 逻辑深,现有方法根本不够用。COLA 虽然提了分,但离落地还有距离,接下来得从这几个方向发力:
首先是 “schema 关联规划”,得让模型早点把实体和关系绑定,比如先确定 “用户表” 和 “订单表” 通过 “user_id” 关联,再生成 SQL,避免多跳连接时漏表;其次是 “方言感知归一化”,比如 “日期格式” 在不同数据库里不一样(YYYY-MM-DD vs MM/DD/YYYY),模型得能自动转换,还有 “代码切换” 问题,得把 “设备分类” 和 “deviceCategory” 这种对应关系学明白;然后是 “执行驱动学习”,用执行反馈来优化模型,比如 RLHF(基于人类反馈的强化学习),让模型从错误中学习;最后是 “多语言数据增强”,多搞点 paraphrase(同义改写)、方言变体数据,比如 “查销量” 在中文里还能说 “看销售额”“统计卖出数量”,让模型适应不同表达方式。
总的来说,MultiSpider 2.0 给多语言 Text-to-SQL 立了个更高的标杆,也让我们看到了现有方法的不足。未来只有把语言理解、schema 推理、执行反馈捏合到一起,才能搞出真正能落地的方案。对我们程序员来说,这既是挑战也是机会 —— 毕竟全球化业务越来越多,多语言 Text-to-SQL 做好了,能解决太多实际问题了。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











