



作为程序员,咱平时玩 Text-to-SQL 或者 RAG 的时候,是不是总遇到一个头疼事儿 —— 系统输出个结果,你问它 “为啥这么判?依据哪条规则?”,它要么支支吾吾说不清楚,要么瞎扯一堆没影的 “证据”。尤其碰到合规场景,比如加拿大反垃圾邮件法(CASL)这种,审计员要逐条核对决策依据,没个清晰的追踪记录,分分钟给你亮红灯。
最近看到一篇挺有意思的论文,里面提出的 ScenarioBench 算是把这个痛点给戳中了。它不是那种只看 “结果对不对” 的普通基准,而是从合规角度出发,要求系统不仅要给出正确决策,还得把 “决策过程” 明明白白列出来,每一步都得有对应的政策条款 ID 撑腰,而且这些条款还必须是系统自己从政策库里捞出来的 —— 这就从根儿上杜绝了 “ hallucination(幻觉输出)”,审计的时候拿日志一看,清清楚楚,谁都挑不出毛病。
先说说这玩意儿到底是啥。ScenarioBench 里每个场景都是用 YAML 写的,配套的 “黄金标准包”(gold-standard package)那叫一个全乎 —— 既有预期的正确决策(比如 “允许”“拒绝”“需要修改”),还有最精简的 “见证追踪”(minimal witness trace),就是告诉你要得出这个决策,必须用到哪几条条款,甚至还有对应的标准 SQL 查询。关键是,判断 SQL 对不对,不看字符串长得一不一样,而是看返回的条款 ID 集合是不是一致,这就很合理了,毕竟咱写 SQL 也常有不同写法实现同一个逻辑的情况。
举个实际例子,比如有个邮件推广场景,邮件里没加退订链接,按 CASL 规定得判 “safe-rewrite(安全修改)”。对应的黄金标准包里,决策是 “safe-rewrite”,追踪记录得包含三条:CASL-IDENT-001(适用这条身份标识规则)、CASL-UNSUB-001(违反了退订要求)、CASL-TRX-EXCEPT-001(不属于交易类邮件例外),SQL 查询则是从 clauses 表里筛选出 domain 为 CASL、topic 包含 “ident” 和 “unsubscribe” 的条款。系统输出的时候,就得照着这个标准来,追踪里的每一个条款 ID 都得是自己从政策库里检索到的,要是敢引用库里没有的,直接算 “幻觉”,日志里明明白白记着。
它的核心逻辑 pipeline 也挺清晰,看下面这张图就懂了。从 YAML 场景开始,先编译成两种格式:一种是 Prolog 事实,用来做确定性的规则执行;另一种是关系型的 Policy_DB,支持检索和 Text-to-SQL。这俩格式里的条款 ID 是一一对应的,比如 clause_id 123,在 Prolog 里是某个谓词,在 Policy_DB 的 clauses 表里也是 id=123,这样就不会出现 “各说各话” 的情况。系统先通过 BM25 或者混合检索(BM25 + 向量)捞出 top-k 条款,再用 NLQ-to-SQL 把自然语言问题转成 SQL 去查库,最后规则引擎结合这些条款给出决策和追踪记录,全程都有日志(JSONL/CSV 格式)记录配置、证据和耗时,审计的时候直接扒日志就行。
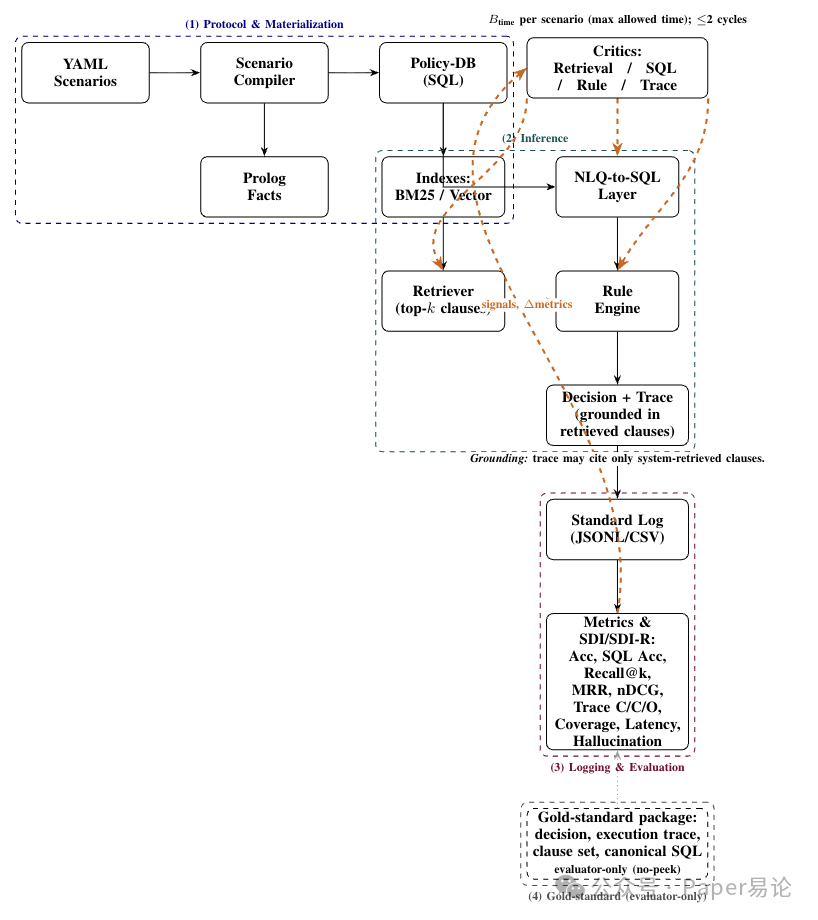
图 1:ScenarioBench 的四阶段流程。决策以检索到的条款为依据;推理过程遵循每个场景的延迟预算B_time
咱再看看它具体怎么评估的。不像 Spider 只看 SQL 对不对,也不像 KILT/RAG 那种没个合规追踪的标准,ScenarioBench 的评估维度特别全,而且都盯着 “合规可审计” 这个核心。比如决策质量看准确率和 macro-F1,追踪质量拆成完整性(黄金条款里有多少被系统用上了)、正确性(系统用的条款里有多少是黄金条款)、顺序一致性(跟黄金追踪的顺序匹配度,用 Kendall-τ 算),还有检索效果(Recall@k、MRR 这些)、SQL 正确性(结果集等价)、政策覆盖率,甚至连耗时和幻觉率都算进去了。
最实用的是它搞了个 “场景难度指数(SDI)”,把决策、追踪、检索这几方面的表现揉成一个数,方便对比不同系统的综合能力。还有个预算版的 SDI-R,会把耗时也考虑进去 —— 毕竟实际场景里不可能无限给系统时间,比如每个场景最多给 12ms,SDI-R 就能算出在这个时间预算下,系统的性价比到底怎么样。
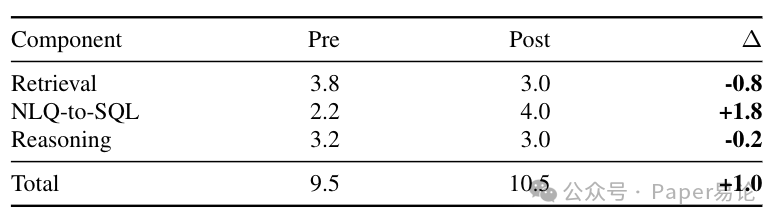
论文里做了个小实验,16 个合成场景,结果还挺有意思。决策准确率和 macro-F1 直接拉满到 1.0,说明系统判得都对,但追踪完整性和政策覆盖率一开始只有 0.541。然后加了个 “预算内反思步骤”—— 就是让系统在规定时间里微调一下检索参数(比如改改 k 值、切换混合检索权重),结果追踪完整性和覆盖率直接飙到 1.0,幻觉率还是 0,耗时也就多了 1ms。你看下面这张表,Hybrid(混合检索)在加了反思步骤后,除了耗时从 9.5ms 变成 10.5ms,其他关键指标全满,这说明当 “结果对不对” 已经不是问题的时候,花点小钱(多 1ms)提升 “解释清楚为什么对” 的能力,性价比超高。
表 3:16 个场景下 Hybrid 基准的 “无反思” vs “1 次反思” 对比

再拆解开看看耗时变化,下表里能看到,反思后检索还快了 0.8ms(可能是用了缓存或者缩小了查询范围),推理时间差不多,主要耗时增加在 NLQ-to-SQL 上,多了 1.8ms—— 估计是系统切换了 SQL 模板,或者重试了一次查询,目的是把追踪需要的条款都查全,这笔开销花得值。
表 4:耗时拆解(ms,后 - 前,数值越小越好)
还有个有意思的对比,就是 BM25 和混合检索(BM25 + 向量,权重 0.6 和 0.4)的较量。从下面的表 5 能看出来,两者的决策准确率、追踪完整性这些核心指标都一样,都是 1.0 的准确率,0.667 的追踪完整性,幻觉率 0,但混合检索的耗时直接从 8.2ms 涨到 17.6ms,快翻倍了。这说明啥?光检索能力强没用,还得有配套的 “追踪构建器” 能把检索到的条款用起来。比如这次实验里,追踪构建器只输出了最精简的两步(退订条款 + 例外条款),没把身份标识条款加进去,导致混合检索捞到的更多条款没派上用场,白瞎了那多花的 9.4ms。
表 5:消融实验 1(检索方式):BM25 vs 混合检索(向量权重 0.6)

下面这张图更直观,追踪完整性和覆盖率两者完全重合,都是 0.667,但归一化后的耗时,BM25 才 0.466,混合检索直接到 1.0,性价比高下立判。要是后续能优化一下追踪构建器,比如让它自动把检索到的身份标识条款加进追踪里,混合检索的优势才能真正发挥出来。
还有个关键点是 “无偷看(no-peek)” 原则 —— 系统在推理的时候,完全接触不到黄金标准包的内容,只能靠自己检索和分析。这就保证了评估的公平性,不会出现系统 “作弊” 的情况。比如前面提到的邮件退订场景,系统一开始可能判成 “block(拒绝)”,因为没考虑到 “安全修改” 的选项,也没把身份标识条款加进追踪;但经过一次反思,调整了检索参数,把该有的条款都捞出来了,最终改成 “safe-rewrite”,追踪也补全了,整个过程没碰过黄金标准包,全靠自己优化。
下面这张图里,左边的混淆矩阵是完美对角的,说明所有场景的决策都判对了;右边的 SDI 和 SDI-R 对比,能看到反思后 SDI 提升了(因为追踪更完整了),而 SDI-R 虽然因为耗时增加有所下降,但整体还是在合理范围内,毕竟多花 1ms 换来了 100% 的追踪完整性,对于合规场景来说,这太值了。
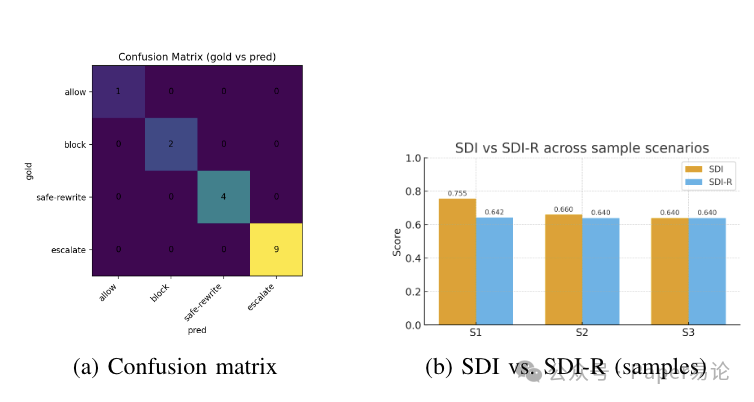
图 2:子图说明:(a)完全对角化的决策表明标签完全匹配;(b)反思通过补全追踪记录提高了场景难度指数(SDI),而预算版场景难度指数(SDI-R)则在每个场景的延迟预算下,对同等增益进行成本量化。
最后再聊聊实际用起来怎么样。论文里给了个最小化的演示包,里面有个 Policy_DB 快照、一个 YAML 场景文件,还有几个 Python 脚本,不用装复杂的依赖,也不用 API 密钥,跑个python scripts\quick_log.py就能看到结果。输出里会明确写着决策是 “safe-rewrite”,追踪包含哪些条款 ID,检索到的 top-10 条款是啥,甚至还有 SQL 的哈希值和耗时,日志存在 out 目录下,后续要统计指标或者审计,直接读日志就行,对程序员来说特别友好。
当然,这玩意儿现在也有局限,比如场景是合成的,才 16 个,而且主要针对加拿大的政策,后续肯定要扩展到更多地区、更多场景,还得加些真实数据进去。另外,Prolog 和 SQL 两种格式的同步也得注意,万一条款 ID 对不上就麻烦了,不过论文里说有验证器来保证一致性,问题应该不大。
总的来说,ScenarioBench 给 Text-to-SQL 和 RAG 的合规评估提供了一个新思路 —— 不光要 “做对”,更要 “说清楚为什么做对”,而且这个 “说清楚” 还得可审计、无幻觉。对咱做企业级应用的程序员来说,这东西太实用了,以后再碰到合规场景,不用再手动写一堆追踪逻辑,直接用它的框架来评估和优化系统,省不少事儿。


















 22万+
22万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











