



作为天天跟数据库打交道的程序员,你肯定知道范式化(1NF/2NF/3NF)是数据库设计的基础操作 —— 减少冗余、保证数据一致性这事儿,教科书里都快把它吹成 “银弹” 了。但你有没有想过,当我们用大模型做 NL2SQL(自然语言转 SQL)时,这堆范式化规则可能会反过来坑你?
最近我们团队做了个事儿:把 8 个主流大模型(GPT-4o、Gemini、Claude 全家桶都测了)拉到 “范式化战场” 上遛了遛,从纯 synthetic(人造)数据到真实学术论文数据集,把 1NF 到 3NF 的各种 schema 都试了个遍。结果挺颠覆认知的 —— 不是说范式化不好,而是没有最优的 schema,只有最适配查询场景的 schema。
先给不熟悉背景的同学补个课:NL2SQL 这东西现在越来越重要了,毕竟不是人人都会写 SQL,但人人都想查数据。之前大家都盯着模型优化,比如怎么调 prompt、怎么 fine-tune,却没人正经研究过 “数据库这边的设计” 对结果的影响。要知道,咱们人类写 SQL 时,复杂的范式化 schema 都能让老手犯迷糊,更别说大模型了。
这次研究的核心就是解决一个问题:不同范式化程度的 schema,到底对大模型生成 SQL 的准确性有啥影响? 为了搞清楚,我们分了三个实验场景,从简单到复杂一步步测,先看理论情况,再看真实世界的表现。
先搞懂实验框架:从人造数据到真实场景
我们没一上来就用复杂数据,而是先搭了个 “可控环境”。核心思路是用 “函数依赖三元组(FDT)”—— 简单说就是三个实体 A、B、C,满足 A→B、B→C 的依赖关系,比如 “学生→课程→院系”,这样就能清晰地拆分 1NF、2NF、3NF 的 schema。
具体分了三个实验场景,表格里列得很清楚,后面所有结果都基于这三个场景来的:

图1:研究动机、研究方法及核心发现(即查询 - 模式偏好)概览。在对 8 个主流大型语言模型(LLMs)的实验中,这些偏好均稳定存在。
对应的范式化 schema 长这样,拿 “学生选课” 举例,1NF 是把所有信息塞一张表,2NF 拆成 “学生 - 课程” 和 “课程 - 院系”,3NF 再拆成 “学生 - 课程”“课程 - 部门”“部门 - 院系”—— 拆得越细,join 操作就越多:
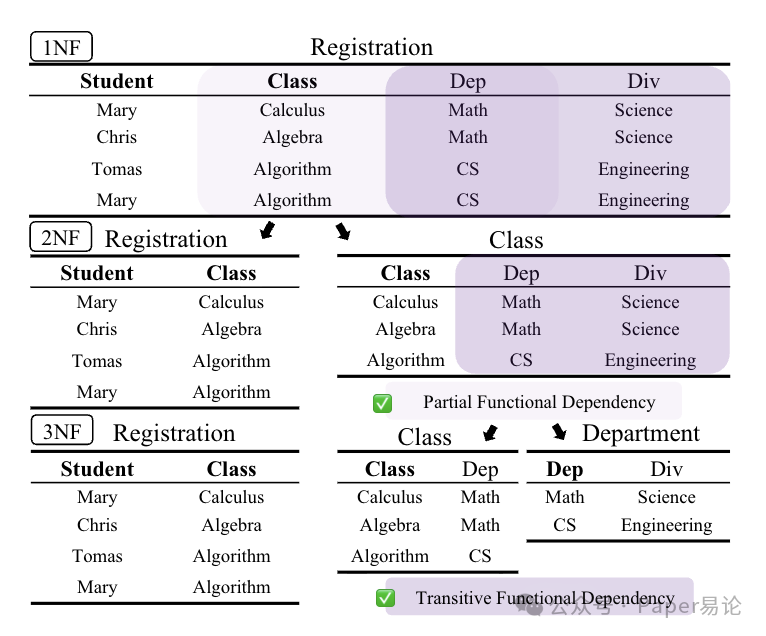
图 2:1NF、2NF、3NF 的 schema 拆分示例,加粗列是主键。1NF 里一条记录包含学生、课程、部门、院系,3NF 则拆成 3 张表,每步拆分都解决了一种依赖问题
查询方面也做了设计,比如同样查 “学生选的课程”,1NF 里直接SELECT * FROM 表就行,3NF 里就得写A LEFT JOIN B ON ... LEFT JOIN C ON ...。我们一共设计了 6 种查询类型,覆盖不同实体组合,后面会看到,有些查询类型在高范式化下简直是大模型的 “坑”。
实验 1:纯理论场景(Formal-Basic)—— 低范式化赢麻了
先看最纯粹的情况:数据是人造的,查询也简单,就是要隔离 “范式化” 这个变量的影响。结果一出来,我们都笑了 ——1NF(非范式化)下所有模型都拿了满分(1.0),不管是零样本还是少样本。
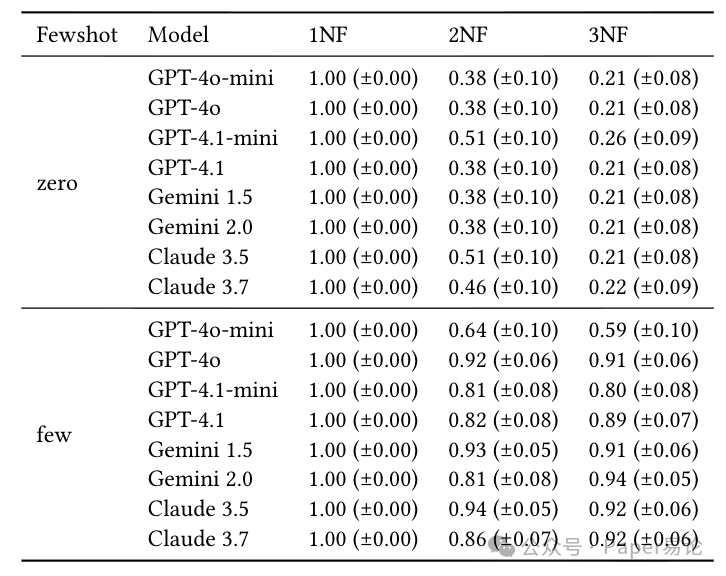
但一到 2NF、3NF,情况就崩了。零样本场景下,多数模型在 2NF 的准确率跌到 0.38,3NF 直接到 0.21;就算加了少样本示例(给 5 个 NL-SQL 对),小模型比如 GPT-4o-mini 还是没救,3NF 准确率也就 0.22 左右。
具体数据看这张表,每个模型的表现都列得明明白白,95% 置信区间也标了,不存在偶然:
表 4:Formal-Basic 场景下的执行准确率,零样本时小模型在高范式化下直接拉胯,少样本能救但救不活小模型
为啥会这样?我们扒了错误日志,发现大模型在高范式化下犯的错特别 “低级”,但也特别典型:
第一个坑是join 类型选错。比如查 “学生 A 选的课程”,3NF 里需要用 LEFT JOIN(因为可能有学生没选课,得保留学生记录),但模型总写成 INNER JOIN,结果把没选课的学生全过滤掉了。就像下面这行 SQL,模型把 LEFT JOIN 写成了 JOIN,直接错了:SELECT ... FROM C JOIN (应该是LEFT JOIN) B ON C.id = B.C_id ...
第二个坑更绝 ——基础表选错。比如要查 “所有课程对应的部门”,正确的应该以 “课程表(B)” 为基础表,但模型总习惯性用 “学生表(A)” 当基础表,写出来的 SQL 从根上就错了:SELECT ... FROM (错:A / 对:B) LEFT JOIN (错:B / 对:A) ON ...
这些错误在 1NF 里根本不存在,因为不用 join;但到了 2NF、3NF,哪怕是 GPT-4o 这种强模型,零样本时也会栽跟头,更别说小模型了。
实验 2:模拟真实场景(Formal-Simulated)—— 少样本是救星,但坑还在
纯理论场景太理想了,所以我们加了真实业务背景:航班调度、图书馆借书、学生选课,数据还是人造的,但实体关系更复杂了 —— 比如 “教授” 既可以是 “课程讲师” 也可以是 “学生导师”(多角色实体),“学生和课程” 是多对多关系。
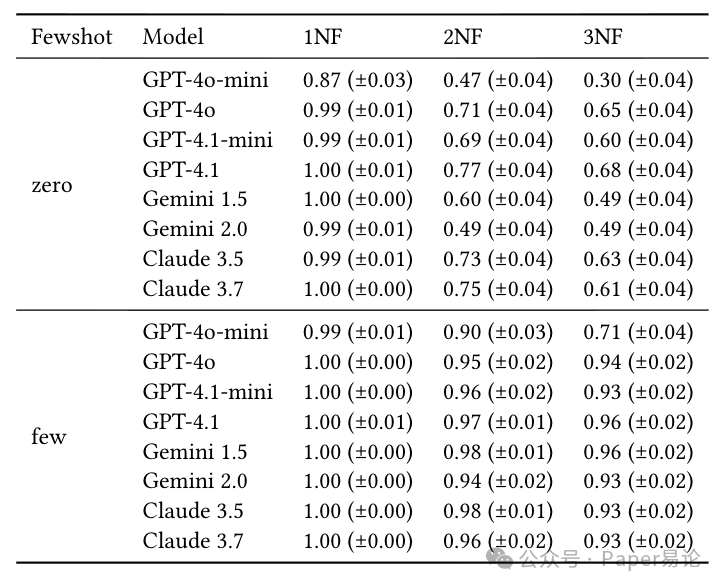
结果比实验 1 有意思:整体准确率比纯理论场景高,但范式化越高,准确率还是越低。比如零样本时,GPT-4.1 在 3NF 的准确率是 0.68,比纯理论场景的 0.21 高多了,但还是比 1NF 的 1.0 低。
更关键的是,少样本在这里发挥了大作用。比如 GPT-4o-mini,零样本时 3NF 准确率只有 0.30,加了少样本直接冲到 0.71;Claude 3.7 更夸张,少样本时 2NF、3NF 准确率都快到 0.95 了。
具体数据看这张表,对比实验 1 就能发现,真实场景的 “语义线索” 帮了模型不少:
表 5:Formal-Simulated 场景下的执行准确率,真实业务语义让模型表现更好,少样本更是直接拉满
但新的坑也出现了 ——实体混淆。比如在图书馆场景里,查询 “书籍的归还日期”,模型会把 “书籍表(books)” 和 “借阅表(borrows)” 搞混,写出这种错 SQL:SELECT b.donated_by, (错:b / 对:br).due_date FROM ... LEFT JOIN borrows br ON ... LEFT JOIN books b ON ...简单说就是把 “借阅表的归还日期” 写成了 “书籍表的归还日期”,而书籍表根本没有 due_date 这个字段,这就是业务语义理解不到位导致的。
不过有意思的是,真实场景里 “空值少” 这个特点,反而掩盖了一部分 join 错误。比如用 INNER JOIN 本该漏数据,但因为测试数据里几乎没有空值,结果居然是对的 —— 这也提醒我们,平时测模型时,数据里得故意加些空值,不然测不出真问题。
实验 3:真实业务场景(Practical-Real)—— 反转!高范式化赢了
前面两个实验都是 “人造数据 + 检索查询”,但真实世界里,数据是脏的(有空值、重复),查询还得有聚合(count、group by)。所以我们拿了 Semantic Scholar 的论文数据 —— 包含论文、作者、引用关系,还有各种脏数据:比如同一个作者有多个机构,“Google” 和 “Google Research” 没合并,空值遍地都是。
schema 也分了三档:LOW(低范式化,尽量少拆表)、MID(中范式化,平衡拆分和简单)、HIGH(高范式化,严格按 3NF 拆)。结果一出,我们都惊了 ——前面实验里的 “低范式化优势” 完全反转了!
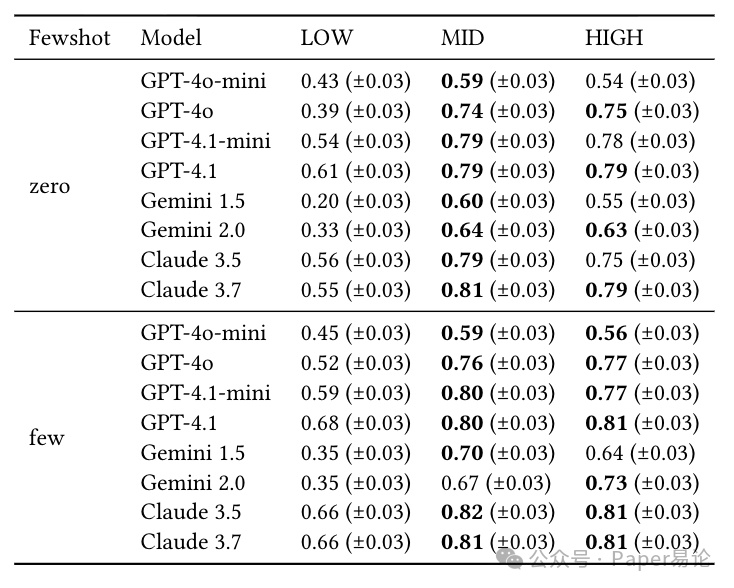
先看整体准确率,所有模型在 MID 和 HIGH 范式化下的表现都比 LOW 好。比如 Claude 3.7,零样本时 LOW 准确率 0.55,MID 直接到 0.81;GPT-4.1 更稳,MID 和 HIGH 都是 0.79,比 LOW 的 0.61 高一大截。而且少样本在这里的提升特别有限,MID 和 HIGH 只涨了 0.02-0.03,远不如前两个实验。
具体数据看这张表,每个模型的表现都很一致:
表 7:Practical-Real 场景下的执行准确率,高范式化 schema 全面反超,少样本提升有限
为啥会反转?我们拆了 “检索查询” 和 “聚合查询” 来看,答案就藏在这里:
- 检索查询
LOW 和 MID/HIGH 的差距不大,平均也就 0.13 分。比如查 “作者 20343 写的论文”,LOW schema 不用多 join,MID 虽然要 join 但模型能搞定,所以差距小。
- 聚合查询
LOW 直接崩了!平均比 MID/HIGH 低 0.3 分。比如 “统计 2023 年每个类别的论文数量”,LOW schema 里因为数据冗余,模型总会犯三个致命错:
第一个错是漏写 DISTINCT。LOW schema 里论文记录有重复,正确统计得用COUNT(DISTINCT p.id),但模型总写成COUNT(*),结果统计出来的数量比实际多一倍多。
第二个错是没过滤空值。比如按 “发表类型” 分组,LOW schema 里有些论文的 publication_type 是空值,模型没加AND p.publication_type IS NOT NULL,结果空值也被算成一个组,完全错了。
第三个错更离谱 ——表关联后重复计数。比如查 “每个机构的作者发了多少论文”,LOW schema 里作者和论文的关联记录有重复,模型没去重,直接把重复的记录也算进去了,结果越算越错。
这些问题在 MID/HIGH 范式化里根本不存在 —— 因为范式化本身就消除了冗余,空值也被合理拆分到不同表,模型不用额外处理去重和过滤,自然不容易错。
放张图更直观,每个模型的检索(R)和聚合(A)表现一目了然,LOW 在聚合查询里的拉垮肉眼可见:
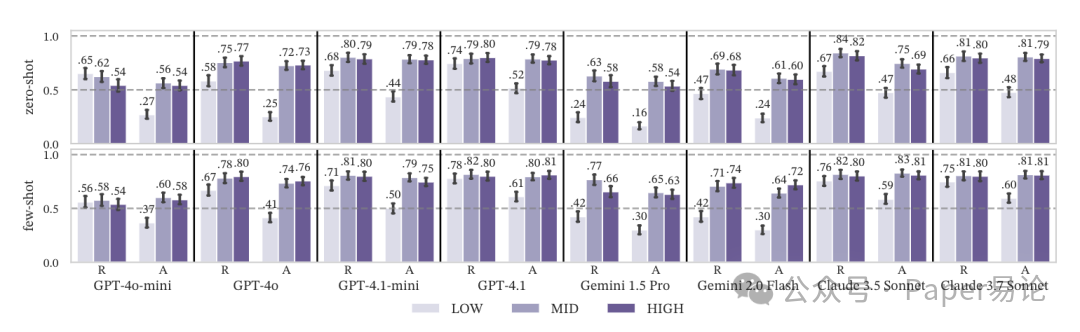
图 4:Practical-Real 场景下,不同范式化程度对检索(R)和聚合(A)查询的影响,LOW 在聚合查询里全面落后
还有两个细节:少样本数量和执行速度
除了准确率,我们还测了两个程序员关心的点:少样本数量的影响,以及不同 schema 的执行速度。
先说少样本数量:越多少样本,对低范式化 schema 越有用。比如 GPT-4o-mini 在 LOW schema 下,少样本从 1 个加到 5 个,检索查询准确率涨了近 20%;但在 MID/HIGH 下,加再多少样本,聚合查询准确率也涨不动 —— 因为范式化带来的结构复杂性,不是靠几个例子就能教会模型的。
再说执行速度:低范式化检索快,高范式化聚合快。纯理论场景里,3NF 的 join 多,数据量越大越慢;但真实场景里,LOW schema 的检索查询确实快(不用 join),但聚合查询时,LOW 的去重和过滤逻辑反而比 MID/HIGH 的 join 更费时间 —— 毕竟数据库对 join 的优化比临时去重好太多了。
放张图看看速度对比,左边是少样本数量的影响,右边是执行时间,规律很明显:
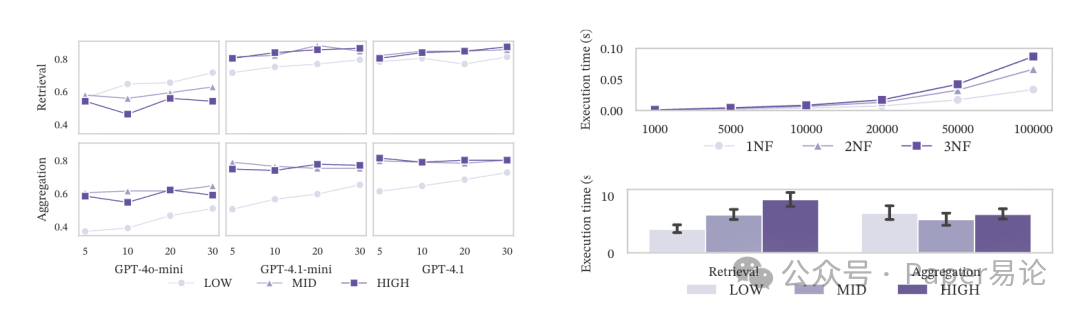
图 5:左图:少样本数量对不同范式化 schema 的影响,LOW 受益更大;右图:执行时间对比,低范式检索快,高范式聚合快
最后聊聊实用建议(不是总结,是干活思路)
测了这么多,最终还是要落地到 “怎么设计 schema”。给咱们程序员的建议就三条,都是从实验里踩坑踩出来的:
-
如果业务以检索为主(查数据多,统计少):用低范式化 schema(比如 1NF/2NF),甚至可以搞点反范式。比如做个 “用户订单明细表”,把用户信息、商品信息都塞进去,大模型写 SQL 时不用 join,准确率高,查询速度也快。之前我们帮运营做的 “活动用户查询工具” 就是这么干的,GPT-4o-mini 零样本准确率都能到 0.95,比拆成 5 张表时的 0.6 高多了。
-
如果业务以聚合为主(统计、报表多):必须上中高范式化(2NF/3NF),别怕 join。比如做 “月度销售报表”,如果把销售数据、产品数据、客户数据混在一张表,大模型统计时肯定会算错重复数据;拆成三张表后,虽然要写 join,但模型不用处理去重,准确率能从 0.5 涨到 0.8 以上,后续维护也方便 —— 毕竟数据一致性比啥都重要。
-
别指望少样本能解决所有问题:小模型在高范式化下,少样本能救但救不活;大模型在真实场景下,少样本提升也有限。最好的办法是 “schema 适配查询类型”,甚至可以搞多 schema 并存 —— 检索用反范式的视图,聚合用范式化的基表,让大模型根据查询意图自动选,这比死磕一个 schema 靠谱多了。
其实这次研究最核心的发现,不是 “范式化好或不好”,而是数据库设计和大模型能力的匹配。之前大家总觉得 “模型够强就行”,但实际干活时才发现,一个好的 schema 设计,比调半天 prompt 管用多了 —— 毕竟大模型再聪明,也架不住你把数据库设计得一塌糊涂。后续我们还会测更多场景,比如分库分表、索引对 NL2SQL 的影响,有兴趣的同学可以关注下,咱们下次接着聊。


















 308
308

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











