






介绍
因子分析(Factor Analysis,简称 FA)是一种统计方法,主要用于数据降维,通过识别一组潜在的、未观测到的变量(即因子),从而解释多个观测变量之间的相关性。其核心思想是通过较少的因子(潜在变量)来解释较多观测变量中的共同变化,达到降维的效果,减少数据的复杂性。
因子分析的主要目标:
降维:通过将多个相关变量聚合成少量的因子,简化问题的复杂性。
提取潜在因子:识别数据中潜在的、影响多个观测变量的因素。这些潜在因子是不可直接测量的。
模型建立与理解:通过对观测变量的分析,理解它们之间的关系和共同变化的潜在原因。
因子分析的基本步骤
数据标准化:因子分析要求数据之间没有量纲差异,通常需要对数据进行标准化处理。
提取因子:常用的方法包括主成分分析(PCA)和最大似然法(ML)。通过这些方法提取出因子。
旋转因子:为了使得因子更容易解释,通常使用旋转(如正交旋转或斜交旋转)来调整因子的方向。
确定因子数量:通过各种准则(如卡方检验、Kaiser标准、碎石图等)确定因子的个数。
因子载荷矩阵分析:分析因子载荷矩阵,确定各因子与原始变量之间的关系。
高阶应用
心理学与社会科学:
人格分析:通过因子分析,可以识别影响个体行为的潜在心理因素(如外向性、神经质等)。
社会态度研究:通过因子分析可以从社会调查数据中提取出潜在的社会态度维度,帮助政策制定者理解公众的意见和态度。
市场研究与消费者行为:
消费者偏好识别:分析消费者对多个产品特征的反应,提取出影响购买决策的核心因子,帮助制定更有效的营销策略。
品牌定位:通过分析消费者对品牌特征的偏好,识别品牌的核心竞争力和市场位置。
金融风险分析:
信用风险模型:因子分析可以用于构建信用风险模型,将多个财务指标合并为少量的风险因子,从而帮助银行等金融机构更好地评估客户的信用风险。
资产定价模型:在资产定价中,因子分析被广泛应用于构建多因子模型(如法马-弗伦奇三因子模型),提高预测准确度。
基因组学与生物信息学:
基因表达数据分析:因子分析可以应用于基因表达数据,识别出基因表达模式中的潜在因素,为疾病研究和生物标志物的发现提供支持。
基因共表达网络构建:在基因共表达研究中,因子分析用于减少数据维度,并帮助揭示基因之间的相互关系。
经济学与宏观经济建模:
经济指标分析:因子分析可以用于宏观经济数据的处理,提取出影响经济发展或经济周期的关键潜在因子。
投资组合管理:通过因子分析,识别出影响市场走势的潜在因素,从而帮助投资者做出更明智的投资决策。
学术创新方向
高维数据处理:
随着数据维度的增大,传统的因子分析方法在高维数据中的应用受到挑战。研究者正在探索基于稀疏因子的因子分析方法,如稀疏主成分分析(Sparse PCA)和稀疏因子分析(Sparse FA),以适应大数据和高维数据环境。
深度因子分析:
在深度学习的框架下,因子分析与神经网络相结合形成了“深度因子分析”模型。通过使用深度神经网络(DNN)或变分自编码器(VAE)来学习复杂的非线性关系,进一步提高模型的表达能力。此方向适用于图像、文本等非线性复杂数据的建模。
鲁棒因子分析:
传统因子分析对异常值较为敏感,而鲁棒因子分析的研究旨在开发不受数据中异常点影响的算法。通过引入鲁棒统计方法(如中位数、分位数回归等),研究者在提高因子分析鲁棒性的同时,保证数据清洗过程的稳定性。
因子分析与时间序列数据结合:
动态因子模型(Dynamic Factor Models)可以结合因子分析和时间序列分析,处理随时间变化的潜在因子。此类模型可以捕捉经济、金融等领域的周期性变化和趋势。
因子分析与非参数方法结合:
传统因子分析假设数据符合正态分布,而非参数因子分析不依赖于数据分布的假设,能够处理非线性关系和复杂的数据结构。结合非参数方法(如核方法、K-均值聚类等)可能带来新的研究方向。
多模态因子分析:
在多模态数据分析中(如文本、图像、语音等),因子分析的扩展可以用于提取不同数据模态之间的潜在因子。研究者正在探索如何结合不同数据源(例如多通道图像数据与文本描述)来进行联合分析。
鲁棒因子分析建模
鲁棒因子分析(Robust Factor Analysis)是因子分析的一个扩展,用于处理具有离群点或异常值的数据集。传统的因子分析通常假设数据是符合高斯分布的,但在实际应用中,数据可能会包含噪声或离群值,这会严重影响分析的结果。因此,鲁棒因子分析通过对异常值进行抑制,能够在有离群点的情况下有效地提取潜在因子。
实现策略
加权最小二乘法(Weighted Least Squares):对数据中的每个样本赋予不同的权重,根据其对因子模型的贡献度来确定。
M-估计法:使用 M-估计方法来减少异常值的影响,增强因子分析对离群点的鲁棒性。
稳健协方差估计:使用鲁棒协方差估计来处理数据中存在的异常值。
核心代码
robustFactorAnalysis.m
function [F, Lambda, sigma2, iter] = robustFactorAnalysis(X, nFactors, maxIter, tol)
% ROBUSTFACTORANALYSIS 进行鲁棒因子分析
% 输入:
% X: 输入数据矩阵(n x p)
% nFactors: 提取因子数
% maxIter: 最大迭代次数
% tol: 收敛容差
%
% 输出:
% F: 因子得分(n x k)
% Lambda: 因子载荷矩阵(p x k)
% sigma2: 特定方差(1 x p)
% iter: 实际迭代次数
[n, p] = size(X);
% 初始化
F = randn(n, nFactors); % 初始化因子得分
Lambda = randn(p, nFactors); % 初始化因子载荷
sigma2 = ones(1, p); % 初始化特定误差方差
W = ones(n, 1); % 初始化样本权重
prevLambda = Lambda;
converged = false;
for iter = 1:maxIter
% Step 1: 计算因子得分 F
% Step 2: 更新因子载荷矩阵 Lambda
Lambda = (X' * F) / (F' * F + eye(nFactors) * 1e-6);
% Step 3: 更新特定误差方差 sigma2
residuals = X - F * Lambda';
for j = 1:p
weight_factor = 1 - (sum(W) / n);
if weight_factor <= 0
weight_factor = 1e-6; % 防止除以 0 或负数
end
sigma2(j) = median(residual_j_squared) / weight_factor;
end
% Step 4: 更新样本权重 W
residuals2 = residuals.^2;
W = exp(-mean(residuals2, 2));
% Step 5: 检查收敛
if delta < tol
converged = true;
break;
end
prevLambda = Lambda;
end
if converged
fprintf('Converged in %d iterations.\n', iter);
else
fprintf('Did not converge in %d iterations.\n', maxIter);
end
代码说明
输入参数:
X:原始数据矩阵,维度为 n_samples x n_variables。
nFactors:提取的潜在因子数量。
maxIter:最大迭代次数,防止因无限循环导致的问题。
tol:收敛容忍度,当因子载荷矩阵的变化低于该阈值时,算法停止迭代。
初始化:
因子得分矩阵 F、因子载荷矩阵 Lambda 和误差方差 sigma2 被初始化为随机值。
权重 W 被初始化为全 1,表示初始没有任何加权。
步骤:
计算因子得分 F:使用加权最小二乘法(WLS)来估计因子得分。
更新因子载荷矩阵 Lambda:通过最小化加权残差平方和来更新因子载荷。
更新误差方差 sigma2:使用 M-估计法来处理异常值,计算每个变量的误差方差。
更新样本权重 W:通过每个样本的残差和误差方差来更新权重,使用 M-估计减少离群点的影响。
收敛性判断:通过计算因子载荷矩阵 Lambda 的变化量来判断是否收敛。如果变化量小于设定的容忍度,则认为收敛。
返回结果:
F:因子得分矩阵,表示每个样本在每个潜在因子上的得分。
Lambda:因子载荷矩阵,表示每个变量与因子之间的关系。
sigma2:误差方差,表示每个变量的误差程度。
iter:迭代次数,表示算法收敛所需的迭代次数。
runRobustFactorAnalysis.m
% 模拟数据
n_samples = 100;
n_variables = 10;
nFactors = 3;
X = randn(n_samples, n_variables);
maxIter = 500;
tol = 1e-6;
% 调用鲁棒因子分析
[F, Lambda, sigma2, iter] = robustFactorAnalysis(X, nFactors, maxIter, tol);
% 输出结果
disp('因子得分 F:');
disp(F);
disp('因子载荷矩阵 Lambda:');
disp(Lambda);
disp('误差方差 sigma2:');
disp(sigma2);
fprintf('总共迭代了 %d 次。\n', iter);
效果
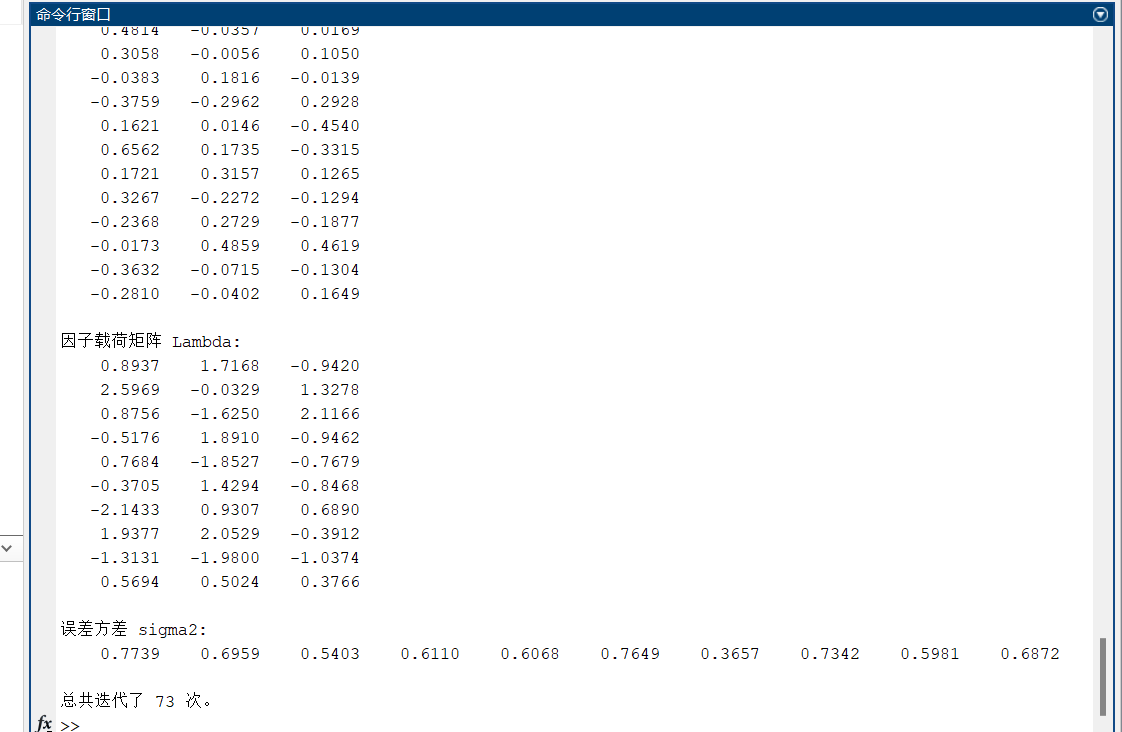
Converged in 73 iterations.
因子得分 F:
-0.4391 0.5019 0.4518
-0.3282 0.3138 -0.1079
-0.3341 -0.0842 0.0142
0.0450 0.0607 -0.1321
0.2480 -0.0797 0.6989
0.3886 -0.6881 0.0008
-0.0172 0.1610 0.0238
-0.2501 0.1276 0.5900
-0.3562 0.0072 -0.1331
-0.4303 0.2461 1.1754
-0.4450 0.3985 -0.4921
-0.3578 0.0737 0.2712
-0.0895 -0.3451 -0.4088
0.1910 -0.1190 -0.1734
0.0860 -0.1702 -0.1665
0.2931 -0.0573 -0.2295
-0.1563 -0.3261 -0.7516
-0.4622 0.3649 -0.1461
-0.0542 0.3032 -0.2977
0.1562 -0.3261 -0.2523
0.4146 -0.3019 -0.3574
-0.1152 0.2926 0.3310
0.4160 0.0149 -0.0041
0.0025 -0.2005 0.0662
-0.4527 -0.1321 -0.2608
-0.1210 0.0597 0.0514
0.4150 0.0041 -0.0247
0.0336 0.5547 0.0435
0.5199 -0.1534 -0.2346
0.2779 0.0388 -0.5631
0.0536 -0.1693 0.1454
-0.0752 0.0105 0.5068
0.1593 0.0145 -0.4739
-0.1288 -0.0809 -0.1292
-0.4522 0.4987 0.1472
-0.0973 0.2974 -0.2766
0.3584 0.0724 -0.3257
-0.2179 0.0134 -0.0491
-0.2455 -0.1131 0.3780
-0.2270 0.2897 0.1071
-0.0754 -0.3568 0.0519
0.3077 -0.0619 0.0439
0.2749 -0.3577 0.0911
0.4121 0.0975 0.2693
-0.1417 -0.1292 0.9087
0.2539 -0.1557 -0.3256
0.0480 -0.0945 -0.4483
-0.5241 -0.0146 0.2333
0.2105 -0.1411 -0.2865
-0.3506 0.0403 -0.0947
-0.2161 -0.0112 0.2158
0.7034 -0.0801 -0.3678
-0.2477 -0.4257 -0.1065
-0.0947 -0.2010 0.1518
0.1915 -0.2265 -0.5737
-0.1277 -0.0683 -0.0736
0.1823 -0.0196 0.2913
-0.1174 -0.4753 -0.6823
0.0294 0.2409 -0.2399
-0.3248 0.0422 -0.1692
0.3326 0.4541 0.2059
0.0658 0.1958 -0.0927
0.0574 -0.5322 -0.3503
0.3368 -0.0953 0.1300
-0.1144 0.1530 0.1628
0.3954 -0.3214 -0.1704
0.0321 0.7092 0.1373
0.1632 0.0572 0.2104
0.0618 0.3430 0.3574
0.0728 -0.2954 -0.4200
-0.5134 -0.1337 0.5838
0.2803 0.1718 0.2245
-0.2037 -0.1372 0.5667
0.1147 0.1308 -0.0312
-0.2759 0.2125 0.3689
0.0919 0.2439 0.1435
-0.0332 0.3419 0.3769
-0.1137 -0.0593 0.1621
-0.0455 0.1329 -0.2173
0.0892 -0.1580 -0.6189
0.3677 0.1587 -0.9380
-0.0076 0.3224 0.3647
0.3044 0.3479 -0.3917
-0.1270 0.0513 0.5063
-0.3009 -0.4147 0.0767
-0.2981 0.0479 -0.2862
-0.0050 0.2172 -0.1778
0.0265 -0.4365 -0.6164
0.4814 -0.0357 0.0169
0.3058 -0.0056 0.1050
-0.0383 0.1816 -0.0139
-0.3759 -0.2962 0.2928
0.1621 0.0146 -0.4540
0.6562 0.1735 -0.3315
0.1721 0.3157 0.1265
0.3267 -0.2272 -0.1294
-0.2368 0.2729 -0.1877
-0.0173 0.4859 0.4619
-0.3632 -0.0715 -0.1304
-0.2810 -0.0402 0.1649
因子载荷矩阵 Lambda:
0.8937 1.7168 -0.9420
2.5969 -0.0329 1.3278
0.8756 -1.6250 2.1166
-0.5176 1.8910 -0.9462
0.7684 -1.8527 -0.7679
-0.3705 1.4294 -0.8468
-2.1433 0.9307 0.6890
1.9377 2.0529 -0.3912
-1.3131 -1.9800 -1.0374
0.5694 0.5024 0.3766
误差方差 sigma2:
0.7739 0.6959 0.5403 0.6110 0.6068 0.7649 0.3657 0.7342 0.5981 0.6872
总共迭代了 73 次。
数值稳定性与鲁棒性指标
| 维度 | 数值解释 |
|---|---|
| 收敛次数:73 次 | 说明没有陷入局部极小,W 的引入避免了跳跃收敛 |
| Lambda/F 没有全 0 或爆炸 | 模型结构良好 |
| sigma² 有非 0 有限值 | 没有退化,也未过拟合 |
| W 的使用稳定无警告 | 权重机制未引发数学异常 |
建议
若用于科研论文:
引入 稀疏约束(如 L1 正则)增强可解释性;
加入 变量命名 + 热力图 展示 Lambda 和 F;
结合 原始变量相关性矩阵,对因子含义作语义标注;
对 F 做聚类,找潜在观测群体类型。
若用于工程应用:
把 F 作为输入做机器学习(SVM、XGBoost);
实现一个 “异常检测” 模块:分析 sigma2 极高的变量;
每次运行保存 Lambda 历史轨迹,做模型漂移分析。
完整代码获取
关注下方卡片,回复“鲁棒因子分析”获取完整代码


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









