






介绍
自回归模型(Autoregressive Model,简称AR模型)是一种在时间序列分析和预测中常用的统计模型。它假设一个时间序列的当前值可以用其过去的若干值的线性组合来表示。AR模型的广泛应用和理论基础使其成为时域分析方法中的重要工具。接下来,我们将从多个角度深入探讨自回归模型,包括其定义、数学表达式、估计方法、模型阶数选择、应用案例以及扩展和变种
定义数学表达式
AR模型的基本思想是利用时间序列自身的过去值来预测其未来值。具体来说,对于一个时间序列
{𝑋𝑡},AR模型假设:

模型估计
在应用AR模型时,估计模型参数(包括常数项
𝑐和系数𝜙𝑖)是关键步骤。常见的估计方法包括最小二乘法(OLS)和极大似然估计法(MLE)。

模型阶数选择
模型阶数
𝑝 的选择对于AR模型的性能至关重要。常见的阶数选择方法包括赤池信息准则(AIC)、贝叶斯信息准则(BIC)以及交叉验证法

应用案例
AR模型在经济学、金融、气象等领域有广泛应用。以下是几个典型案例:
-
金融时间序列预测
在金融市场中,股票价格、汇率等金融时间序列往往具有较强的自相关性。AR模型可以用来对这些时间序列进行建模和预测。 -
经济指标分析
经济指标(如GDP、失业率等)通常会随着时间变化而变化。利用AR模型可以分析这些指标的变化趋势,并进行预测。 -
气象数据分析
气象数据(如温度、降水量等)也常具有时间相关性。AR模型在气象预报中发挥重要作用。
扩展与变种

总结
自回归模型作为时域方法中的重要工具,以其简单直观的思想和强大的建模能力,广泛应用于各个领域。从基础的AR模型,到包含更多成分的ARMA、ARIMA和SARIMA模型,时间序列分析方法不断发展和完善。随着数据科学和计算技术的进步,AR模型的应用前景将更加广阔。
未来,AR模型可能在以下几个方面进一步发展:
与机器学习结合:将AR模型与机器学习算法相结合,提高时间序列预测的精度。
大数据时代的应用:在处理大规模、高频率的数据时,如何高效地应用AR模型。
非线性时间序列分析:针对复杂非线性时间序列,开发更为有效的AR模型变种。
本文代码
我们可以结合AR模型和非线性方法。这里,我们选择一种常见的非线性方法:核函数(Kernel Functions)与支持向量机(Support Vector Machines, SVM)结合的核回归方法来构建非线性自回归模型
实现步骤
核自回归模型(Kernel Autoregressive Model, Kernel AR)
核自回归模型的基本思想是利用核函数将原始时间序列数据映射到高维空间,然后在高维空间中进行线性自回归。具体来说,我们将使用支持向量回归(SVR)来实现这一过程。
核函数选择
常用的核函数包括线性核、多项式核、高斯径向基函数(Gaussian RBF)等。我们在这里选择高斯径向基函数作为核函数。
核心代码
% 核自回归模型(Kernel AR Model)用于非线性时间序列分析
% 使用高斯径向基函数和支持向量回归(SVR)
% 清理工作区
clear;
clc;
% 生成或导入时间序列数据
% 在这里我们生成一个示例时间序列数据
t = (1:1000)';
y = sin(0.01*t) + 0.5*sin(0.03*t) + 0.3*randn(size(t));
% 设置自回归模型阶数
p = 10;
% 准备训练数据
X = zeros(length(y)-p, p);
Y = y(p+1:end);
for i = 1:p
X(:, i) = y(p+1-i:end-i);
end
% 划分训练集和测试集
train_size = floor(0.8 * length(Y));
X_train = X(1:train_size, :);
Y_train = Y(1:train_size);
X_test = X(train_size+1:end, :);
Y_test = Y(train_size+1:end);
% 构建支持向量回归模型(使用高斯核函数)
% 选择核函数和相关参数
kernel_function = 'gaussian';
box_constraint = 1;
epsilon = 0.1;
sigma = 0.5;
% 绘制结果
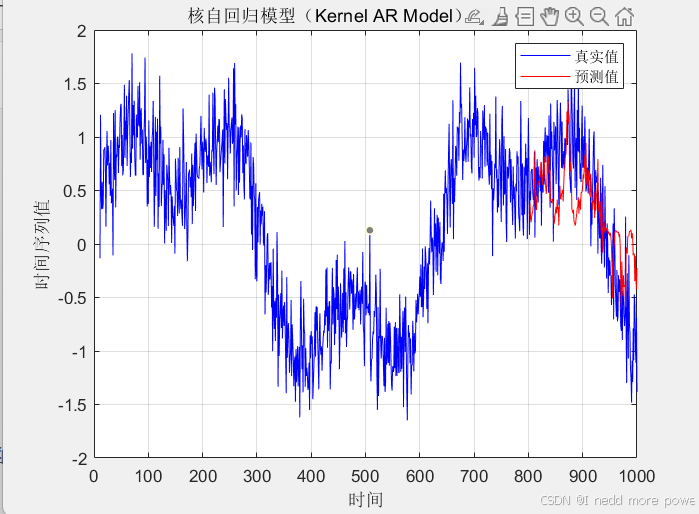
figure;
plot(t(p+1:end), Y, 'b', 'DisplayName', '真实值');
hold on;
plot(t(train_size+p+1:end), Y_pred, 'r', 'DisplayName', '预测值');
xlabel('时间');
ylabel('时间序列值');
title('核自回归模型(Kernel AR Model)预测结果');
legend('show');
grid on;
% 绘制误差图
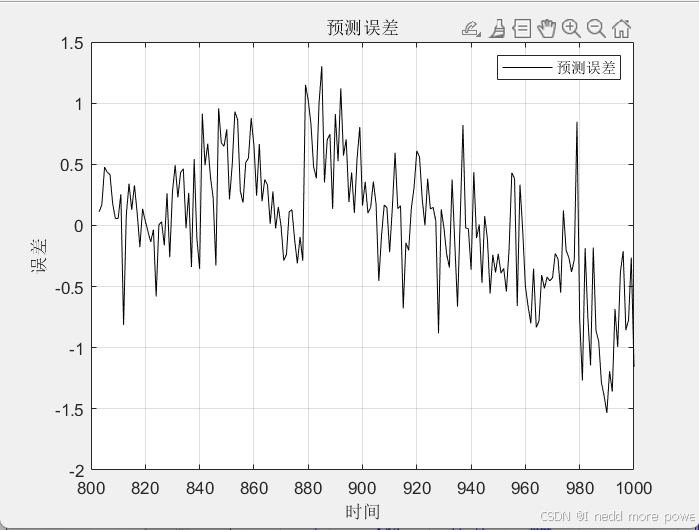
figure;
plot(t(train_size+p+1:end), Y_test - Y_pred, 'k', 'DisplayName', '预测误差');
xlabel('时间');
ylabel('误差');
title('预测误差');
legend('show');
grid on;
说明
数据生成:
生成一个示例时间序列数据,包含1000个数据点,包含一些正弦信号和随机噪声。
准备训练数据:
将时间序列数据转换为训练集和测试集。
自回归模型阶数
𝑝 设置为10。
训练支持向量回归模型:
使用 fitrsvm 函数来训练支持向量回归模型。选择高斯径向基函数作为核函数,并设置相关参数(BoxConstraint、Epsilon 和 KernelScale)。
预测和评价:
使用训练好的SVR模型对测试集进行预测,并计算均方误差(MSE)。
绘制预测结果与真实值的对比图和预测误差图。
效果
扩展
扩展与调整
核函数选择:可以尝试其他类型的核函数,如多项式核函数,调整核函数参数来优化模型性能。
模型阶数调整:根据具体问题调整自回归模型的阶数
𝑝
p。
参数调优:通过交叉验证或网格搜索来优化SVR模型的参数(如 BoxConstraint、Epsilon 和 KernelScale)。
数据预处理:在实际应用中,对数据进行适当的预处理(如标准化、去趋势等)可能会提高模型的预测性能。
完整代码获取
微信扫一扫,回复"自回归模型"获取完整代码


















 3104
3104

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









