







2.1 声源定位系统总览
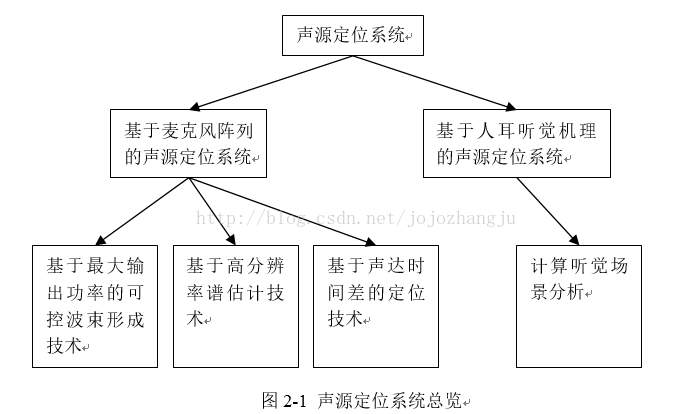
图2-1是声源定位系统的一个总览,声源定位系统分为基于麦克风阵列的声源定位系统和基于人耳听觉机理的声源定位系统。其中,基于麦克风阵列的声源定位系统包括:基于最大输出功率的可控波束形成技术、基于高分辨率谱估计技术、基于声达时间差的定位技术。基于人耳听觉机理的声源定位系统是从人类的听觉生理和心理特性出发,研究人在声音或语音识别过程中的规律,被称作听觉场景分析(auditory scene analysis,ASA),而用计算机模仿人类听觉生理和心理机制建立听觉模型的研究范畴称为计算听觉场景分析。下面将详细地介绍声源定位系统中所涉及的两大系统,以及它们分别包括的主要技术和相关知识。
2.2 基于麦克风阵列的声源定位系统
2.2.1 麦克风阵列语音处理模型特点
麦克风阵列语音处理模型是由传统的阵列信号处理模型的基础上扩展而来。和传统阵列模型相比,麦克风阵列主要有以下特点:
1. 传统的阵列信号处理模型所处理的一般是窄带信号,如通信信号或是雷达信号等,但是麦克风阵列模型所处理的语音信号没有载波,是一个多频宽带信号,其频率分布大部分集中在300~3000Hz之间。
2. 传统的阵列处理技术一般处理的信号为平稳或准平稳信号,而麦克风阵列处理的信号通常为非平稳语音信号。
3. 传统的阵列处理模型一般是远场模型,而麦克风阵列处理模型多半是近场模型。
4. 在传统的阵列处理中,噪声一般白色或是有色的高斯噪声(包括白、色噪声),与信源基本没有相关性。在麦克风阵列处理模型中噪声既有高斯噪声,也有非高斯噪声,例如,空调的噪声,打字的干扰噪声,碎纸机的声音,突然出现的电话铃声等等,这些噪声可能和信源无关,也可能有关。















 6265
6265

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









