







Spark作为新一代的云计算框架,他的目的:
for speeding up the Hadoop computational computing software process.
原本spark是hadoop的一个子项目,在2013他成为Apache的基金项目,2014开始成为top level Apache project
spark的三个特性

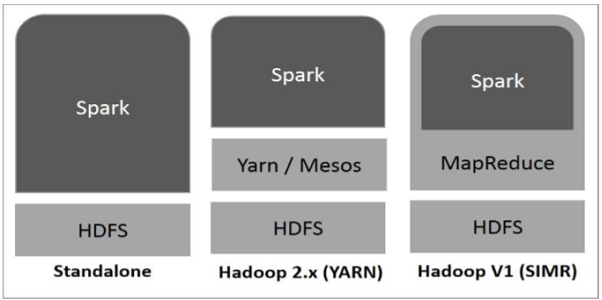
1.学spark总会与hadoop扯上关系,毕竟官方也确实提供了支持hadoop版的spark,hadoop在spark也就是两个作用
@1
最基本的存储数据的功能,他并不是必须的
@2
也可以用hadoop在spark开发中处理数据,他也不是必须的
关系图
2.spark的组件
Apache Spark Core
作为spark的内核引擎部分,主要参与在内存中的计算和引用集群中的数据
Spark SQL
作为RDD部分,提供数据的结构化或者半结构化的功能
Spark Streaming
数据的Streaming处理
MLlib (Machine Learning Library)
MLlib is a distributed machine learning
framework above Spark because of the distributed
memory-based Spark architecture. It is, according to benchmarks,
done by the MLlib developers against the Alternating Least Squares (ALS) implementations.
Spark MLlib is nine times as fast as the Hadoop disk-based version
of Apache Mahout (before Mahout gained a Spark interface).
GraphX
GraphX is a distributed graph-processing
framework on top of Spark.
It provides an API for expressing graph computation that can model
the user-defined graphs by using Pregel abstraction API.
It also provides an optimized runtime for this abstraction.















 2838
2838











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









