







 本文探讨了AlphaGo在围棋领域的应用,重点解析了它采用的蒙特卡洛树搜索技术。从围棋的复杂度谈起,阐述了蒙特卡洛树搜索的四大步骤:选择、评估、反传和扩展,并介绍了SL和RL决策网络及RL价值网络的角色。通过神经网络学习,AlphaGo能够模拟人类下棋策略并自我对弈强化学习,提高了棋局评估的准确性。
本文探讨了AlphaGo在围棋领域的应用,重点解析了它采用的蒙特卡洛树搜索技术。从围棋的复杂度谈起,阐述了蒙特卡洛树搜索的四大步骤:选择、评估、反传和扩展,并介绍了SL和RL决策网络及RL价值网络的角色。通过神经网络学习,AlphaGo能够模拟人类下棋策略并自我对弈强化学习,提高了棋局评估的准确性。
对于alphago文章的一点理解
最近要在讨论班上报告alphago在nature发的文章,之前也给导师报告过一次,老师给了很详尽的建议,在此十分感谢于老师给的建议。
从围棋谈起
我们知道围棋棋盘是 19×19 的网格点,黑白双方以空盘开局,黑方先走,轮流落子,以双方占有领地的大小判断胜负。
围棋的状态空间复杂度
每一个网格点上的状态有三种(黑,白,空),那么19路棋盘的总共 3361≈1.74×10172 种状态,这其中包含了一些不合法的状态(没有气的子在不吃提对方的子的情况下需要从棋盘上拿掉),去掉这些不合法的状态,19路棋盘的也有 2.089×10170 个状态,我们称其为状态空间复杂度。围棋的博弈树复杂度
博弈树是一种数据结构,用来表示博弈中不同盘面之间的关系,其节点代表不同的博弈盘面,边代表从一个盘面到另一个盘面的过程。整颗博弈树逐层构造,每个分支都达到终局时,博弈树构造完成。叶子节点未必在同一层,每一个叶子节点状态都能判断胜负。
博弈树的建立过程可如下图所示:对于围棋来说,第一层有361个选择,第二层有360个,第三层359个,以此类推,共有 361! 个状态,我们可以有一个合理的假设:每局的平均手数为150手,每手平均有250个选择,19路围棋的博弈树复杂度为 250150 。
最优价值函数(optimal value function) v(s)
在盘面状态为 s (以下都用s 代替,省略“盘面状态”) 的情况下,双方以最优策略下棋的博弈结果就是最优价值函数。若遍历完整的博弈树,评估每个叶子节点的结果,逐层返回,可以得到为 s 时的最优价值函数。围棋困难点
如果想通过遍历博弈树的方法,评估每一个叶子节点的结果,逐层返回,从而评估每个节点的结果,以现在的计算水平是无法做到的,其原因是因为:
(1)无法存储下所有的状态空间 。
(2)无法在有限时间内完全遍历博弈树。可以通过两条通用的原则减小搜索树的宽度和深度
(1)减少深度的方法:在盘面状态为s 的情况下用近似价值函数 v(s) 估计盘面,而且在s的子树的节点的盘面价值也用 v(s) 代替。
(2)减少宽度的方法:按照先验概率 p(a|s) ,多次模拟搜索。其中 p(a|s) 代表在状态为 s 的情况下,下一步走a 的概率。
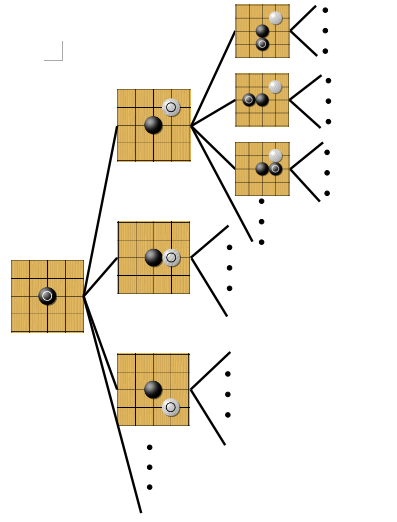
浅谈alphago用到的蒙特卡洛树搜索技术
在这一部分,我们先大体上了解alphago用到的树搜索技术,后面介绍了几个网络后会详细展开。
蒙特卡洛树搜索主要涉及四个部分:
Selection(选择):
搜索在盘面状态为 s 时,博弈树的每条边都有一个价值函数W(s,a) , 它是先验概率 p(a|s) ,访问次数 n(a) ,盘面评估函数 v(s) , 模拟对弈的结果 zt 的函数,所以 W(s,a) 可写为 W(p(a|s),n(a),v(s),zt) 。从根节点开始向下搜索博弈树,每次选择 W(s,a) 值大的边,直到搜索到叶子节点L。Evaluation(评估):
当双方按照Seletion的方式在第L步访问到叶子节点时,用盘面估计函数评估此时的盘面局势好坏 v(sL) ,并在此状态下按照某种策略模拟下棋,直到终局,胜负结果为 zt , 1 为赢,−1 为输。Backup(反传):
在从根节点 s ,向下遍历直到第L步访问到叶子节点时, 访问过的节点的访问次数都加1,对于叶子节点的评估会对每个边的W(⋅) 产生影响,每一个边上的 W(⋅) 值更新。Expansion(扩展):
当某一条变被访问的次数大于一个阈值时,将这个边的继承状态 s′ (也就是 s 状态时,下一步走了a处之后的状态),加入到搜索树中。p(a|s′) 经过计算可得,其他参数的初值都置为0;在进行多次搜索后,我们要选择在盘面状态为 s 的情况下,下一步走棋的选择时,选择根节点
s 下一层节点中,被访问次数最多的。
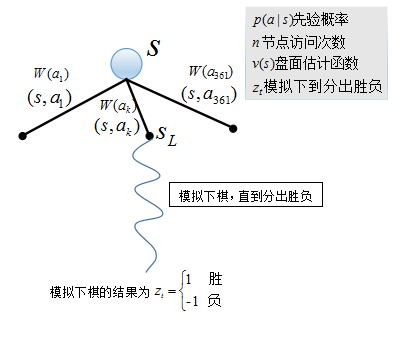
蒙特卡洛树搜索中用到的参数
我们注意到树搜索中用到了:
1. 在盘面状态为 s 时,走盘面上每一步a 的先验概率, p(a|s) .
2. 盘面 s 局势好坏,v(s) .
3. 在某种策略下对局的胜负, zt .
alphago就是通过卷积神经网络的方法建立了:
SL决策网络 pσ(a|s)
通过学习人类的棋谱,按照人类的下棋方式给出在 s 时, 下一步棋走a 的概率。也就是说,SL网络是在预测在盘面状态为 s 的情况下,人类下一步更有可能走哪个位置。rollout快速走子网络
pπ(a|s)
快速走子网络也是学习人类棋谱得到的网络,其参数更少,计算速度快,但是精度低。RL决策网络 pρ(a|s)
pσ(a|s) 能够比较好的预测人在下棋时的选择。我们又通过当前神经网络和对手库中的网络自我对弈,得到 s 下的对弈结果,用对弈结果强化学习,可以理解为:如果选择一个位置,可以导致最终赢得对局,那么选择这个位置的概率变大,如果选择一个位置,导致最终输掉对局,那么选择这个位置的概率变小。RL价值网络
vθ(s)
我们希望能够预测当前的局势好坏,也就是希望能够在最优策略下对弈(上帝视角),得到的对弈结果就是局势好坏。现今的计算力无法完全遍历博弈树,也就是得不到最优策略,所以用我们当前训练的最强的神经网络代替最优策略。也就是我们用 pρ(a|s) 对弈,其结果近似为当前局势的好坏。
但是用神经网络对弈的方式判断局势好坏还是过于复杂,所以通过神经网络构造函数 vθ(s) , 希望 vθ(s) 的计算结果近似等于 pρ(a|s) 对弈的结果。
SL决策网络(policy network) pσ
通过学习人类的棋谱,按照人类的下棋方式给出在 s 时, 下一步棋走
a 的概率。也就是说,SL网络是在预测在盘面状态为 s 的情况下,人类下一步更有可能走哪个位置。
输入和输出
输入:盘面状态
s .
输出:对于盘面上所有合法的落子位置 a ,在盘面状态为s 时,下一步走位置 a ,的概率pσ(at|st) ,其中 σ 为这个概率密度函数的参数,即神经网络的参数,可以通过训练得到。样本数据集
数据集是28.4million个:盘面状态-下一步落子对(board-state next-move pairs): (st,at),t=1,⋯,28.4
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









